BELIEF: Structured Evidence Modeling and Uncertainty-Aware Fusion for Biomedical Question Answering
Pith reviewed 2026-05-20 13:09 UTC · model grok-4.3
The pith
BELIEF converts retrieved documents into structured evidence to improve biomedical question answering by fusing symbolic and neural reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BELIEF structures retrieved literature into evidence objects that record clinical attributes, source quality, question relevance, support strength, and the associated candidate hypothesis. These objects enable reliability-weighted basic probability assignments via Dempster-Shafer theory for symbolic evidence fusion to estimate belief and residual uncertainty, while the same objects support LLM-based semantic inference; a reliability-aware arbitration module then reconciles the two outputs according to belief strength, uncertainty, evidence reliability, and semantic consistency.
What carries the argument
Structured evidence objects that provide a shared basis for symbolic Dempster-Shafer fusion and neural semantic inference, reconciled by a reliability-aware arbitration module.
If this is right
- Evidence reliability becomes an explicit factor in the final answer selection.
- The system can quantify and report residual uncertainty in its decisions.
- Performance gains appear across different general-purpose LLM backbones without domain-specific pretraining.
- Retrieved evidence is utilized more effectively by making structure, disagreement, and uncertainty explicit.
Where Pith is reading between the lines
- This method could be adapted to other fields where evidence quality varies, such as legal document analysis or scientific hypothesis testing.
- Integrating this with retrieval systems that prioritize high-reliability sources might further enhance results.
- Testing the framework on questions requiring multi-hop reasoning across documents would reveal its limits in handling complex evidence chains.
Load-bearing premise
Retrieved documents can be reliably converted into structured evidence objects that accurately record clinical attributes, source quality, question relevance, and support strength without introducing new errors or biases.
What would settle it
An experiment showing that errors introduced during the structuring of evidence lead to overall performance worse than using unstructured text as context.
Figures





read the original abstract
Biomedical question answering often requires decisions from retrieved literature whose relevance, quality, and support for candidate answers are uneven. Most retrieval-augmented large language model (LLM) methods feed this literature to the model as flat text, leaving evidence reliability and remaining uncertainty largely implicit. We propose BELIEF, a structured evidence modeling and uncertainty-aware fusion framework for closed-set biomedical question answering. Rather than treating retrieved documents as undifferentiated context, BELIEF converts them into evidence objects that record clinical attributes, source quality, question relevance, support strength, and the associated candidate hypothesis. These evidence objects provide a shared basis for two complementary reasoning paths. The symbolic path constructs reliability-weighted basic probability assignments based on Dempster--Shafer (D-S) theory over a finite answer space and performs uncertainty-aware symbolic evidence fusion to estimate belief and residual uncertainty. The neural path uses the same structured evidence for LLM-based semantic inference, while a reliability-aware arbitration module reconciles the symbolic and neural outputs according to belief strength, uncertainty, evidence reliability, and semantic consistency. Experiments on PubMedQA, MedQA, and MedMCQA with five general-purpose LLM backbones show that BELIEF obtains the best result in 25 of 30 backbone--dataset--metric settings. Comparisons with biomedical-domain models indicate that BELIEF is competitive on MedQA and MedMCQA, while specialized biomedical pretraining remains advantageous on PubMedQA. Ablation, complementarity, uncertainty-stratified, and cost analyses further show that BELIEF improves retrieved-evidence utilization by making evidence structure, path disagreement, and decision uncertainty explicit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BELIEF, a structured evidence modeling and uncertainty-aware fusion framework for closed-set biomedical question answering. Retrieved documents are converted into evidence objects recording clinical attributes, source quality, relevance, support strength, and candidate hypothesis. These support a symbolic path using Dempster-Shafer theory for belief and uncertainty estimation, and a neural path with LLM semantic inference. An arbitration module reconciles the two based on belief, uncertainty, reliability, and consistency. Empirical results on PubMedQA, MedQA, and MedMCQA with five LLMs show superiority in 25 of 30 settings, with ablations and analyses supporting improved evidence utilization.
Significance. The integration of symbolic uncertainty modeling with neural inference in a biomedical QA setting addresses a key challenge in retrieval-augmented generation where evidence quality varies. The extensive evaluation across datasets and backbones, along with uncertainty-stratified analysis, provides a solid basis for assessing the approach. If the evidence structuring proves reliable, this could influence future work on hybrid reasoning systems. The lack of quantitative validation for the structuring step, however, limits the current assessment of its broader impact.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The headline result that BELIEF obtains the best result in 25 of 30 backbone--dataset--metric settings is presented without error bars, confidence intervals, or statistical significance tests. This makes it difficult to determine whether the observed improvements are robust or could be due to variance in LLM outputs or evaluation choices.
- [Method] Method section (evidence object construction): The conversion of retrieved documents into structured evidence objects is described as recording clinical attributes, source quality, question relevance, and support strength, but no quantitative validation (e.g., human agreement rates, error analysis, or bias audit) is provided. Since this step feeds both the D-S BPA construction and the neural path, unmeasured errors here could confound the attribution of gains to the uncertainty-aware fusion and arbitration.
minor comments (2)
- [Related Work] Related Work: Consider adding references to recent works on uncertainty estimation in LLMs for QA to better contextualize the contribution.
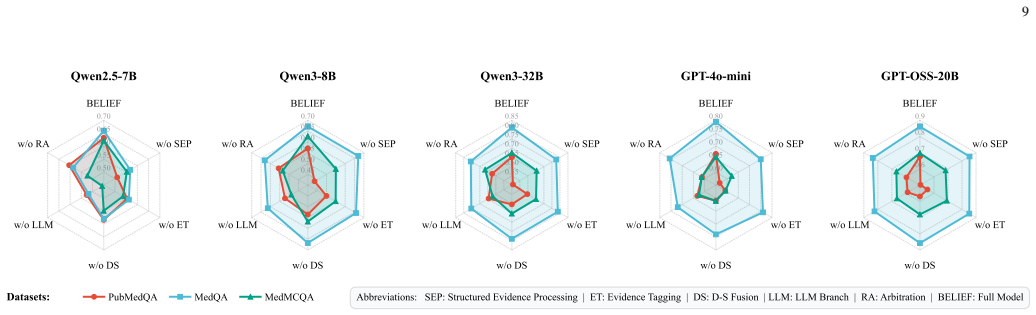
- [Figure 1] Figure 1: The overview figure would benefit from annotations indicating the flow from evidence objects to symbolic and neural paths.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of result presentation and methodological validation. We address each major comment below and have made targeted revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The headline result that BELIEF obtains the best result in 25 of 30 backbone--dataset--metric settings is presented without error bars, confidence intervals, or statistical significance tests. This makes it difficult to determine whether the observed improvements are robust or could be due to variance in LLM outputs or evaluation choices.
Authors: We agree that error bars and statistical tests would better demonstrate robustness against LLM output variance. In the revised manuscript we have added standard deviations computed over three independent runs to the main result tables and included McNemar's tests for pairwise significance between BELIEF and baselines, with p-values reported in the Experiments section. revision: yes
-
Referee: [Method] Method section (evidence object construction): The conversion of retrieved documents into structured evidence objects is described as recording clinical attributes, source quality, question relevance, and support strength, but no quantitative validation (e.g., human agreement rates, error analysis, or bias audit) is provided. Since this step feeds both the D-S BPA construction and the neural path, unmeasured errors here could confound the attribution of gains to the uncertainty-aware fusion and arbitration.
Authors: The referee correctly notes the absence of quantitative validation for evidence structuring. We have added a human evaluation subsection reporting inter-annotator agreement (Cohen's kappa = 0.76) on a 200-instance sample in the revised Experiments section. A comprehensive bias audit remains outside the current scope and is listed as future work in the Discussion. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces an empirical framework that converts retrieved documents into structured evidence objects, applies standard Dempster-Shafer theory for symbolic belief fusion on one path, performs LLM semantic inference on a parallel neural path, and reconciles outputs via a reliability-aware arbitration module. All reported gains are measured through external experiments on PubMedQA, MedQA, and MedMCQA using five independent LLM backbones, with no closed-form derivation or equation chain that reduces the final performance numbers to fitted parameters or self-referential definitions by construction. The symbolic component invokes established D-S operations on externally supplied evidence attributes rather than deriving those attributes from the fusion result itself, rendering the approach self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retrieved documents can be converted into evidence objects that faithfully record relevance, quality, and support without substantial information loss or bias.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BELIEF converts retrieved documents into evidence objects that record clinical attributes, source quality, question relevance, support strength... constructs reliability-weighted basic probability assignments based on Dempster–Shafer (D-S) theory... reliability-aware arbitration module
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on PubMedQA, MedQA, and MedMCQA with five general-purpose LLM backbones
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[2]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
work page 2020
-
[4]
Retrieval-augmented generation for large language models: A survey,
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” 2024
work page 2024
-
[5]
Self-rag: Learning to retrieve, generate, and critique through self-reflection,
A. Asai, Z. Wu, Y . Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[6]
Evidence based medicine: what it is and what it isn’t,
D. L. Sackett, W. M. Rosenberg, J. M. Gray, R. B. Haynes, and W. S. Richardson, “Evidence based medicine: what it is and what it isn’t,” pp. 71–72, 1996
work page 1996
-
[7]
Grade guidelines: 1. introduction—grade evidence profiles and summary of findings tables,
G. Guyatt, A. D. Oxman, E. A. Akl, R. Kunz, G. Vist, J. Brozek, S. Nor- ris, Y . Falck-Ytter, P. Glasziou, H. DeBeeret al., “Grade guidelines: 1. introduction—grade evidence profiles and summary of findings tables,” Journal of clinical epidemiology, vol. 64, no. 4, pp. 383–394, 2011
work page 2011
-
[8]
Available: https://arxiv.org/abs/2503.05777
Y . Kim, H. Jeong, S. Chen, S. S. Li, C. Park, M. Lu, K. Al- hamoud, J. Mun, C. Grau, M. Junget al., “Medical hallucinations in foundation models and their impact on healthcare,”arXiv preprint arXiv:2503.05777, 2025
-
[9]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
work page 2025
-
[10]
Are large lan- guage models really good logical reasoners? a comprehensive evaluation and beyond,
F. Xu, Q. Lin, J. Han, T. Zhao, J. Liu, and E. Cambria, “Are large lan- guage models really good logical reasoners? a comprehensive evaluation and beyond,”IEEE Transactions on Knowledge and Data Engineering, vol. 37, no. 4, pp. 1620–1634, 2025
work page 2025
-
[11]
Final: Combining first-order logic with natural logic for question answering,
J. Shi, X. Ding, S. C. Hui, Y . Yan, H. Zhao, T. Liu, and B. Qin, “Final: Combining first-order logic with natural logic for question answering,” IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[12]
Generalized divergence-based deci- sion making method with an application to pattern classification,
F. Xiao, J. Wen, and W. Pedrycz, “Generalized divergence-based deci- sion making method with an application to pattern classification,”IEEE transactions on knowledge and data engineering, vol. 35, no. 7, pp. 6941–6956, 2022
work page 2022
-
[13]
Upper and lower probabilities induced by a multivalued mapping,
A. P. Dempster, “Upper and lower probabilities induced by a multivalued mapping,” inClassic works of the Dempster-Shafer theory of belief functions. Springer, 2008, pp. 57–72
work page 2008
-
[14]
Shafer,A Mathematical Theory of Evidence
G. Shafer,A Mathematical Theory of Evidence. Princeton University Press, 1976
work page 1976
-
[15]
Knowledge graph neural network with spatial-aware capsule for drug-drug inter- action prediction,
X. Su, B. Zhao, G. Li, J. Zhang, P. Hu, Z. You, and L. Hu, “Knowledge graph neural network with spatial-aware capsule for drug-drug inter- action prediction,”IEEE journal of biomedical and health informatics, vol. 29, no. 3, pp. 1771–1781, 2024
work page 2024
-
[16]
Biomedical question answering: a survey of approaches and challenges,
Q. Jin, Z. Yuan, G. Xiong, Q. Yu, H. Ying, C. Tan, M. Chen, S. Huang, X. Liu, and S. Yu, “Biomedical question answering: a survey of approaches and challenges,”ACM Computing Surveys (CSUR), vol. 55, no. 2, pp. 1–36, 2022
work page 2022
-
[17]
Pubmedqa: A dataset for biomedical research question answering,
Q. Jin, B. Dhingra, Z. Liu, W. Cohen, and X. Lu, “Pubmedqa: A dataset for biomedical research question answering,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 2567–2577
work page 2019
-
[18]
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? a large-scale open domain question answering dataset from medical exams,”Applied Sciences, vol. 11, no. 14, p. 6421, 2021
work page 2021
-
[19]
Medmcqa: A large- scale multi-subject multi-choice dataset for medical domain question answering,
A. Pal, L. K. Umapathi, and M. Sankarasubbu, “Medmcqa: A large- scale multi-subject multi-choice dataset for medical domain question answering,” inConference on health, inference, and learning. PMLR, 2022, pp. 248–260
work page 2022
-
[20]
Biomistral: A collection of open-source pretrained large language models for medical domains,
Y . Labrak, A. Bazoge, E. Morin, P.-A. Gourraud, M. Rouvier, and R. Dufour, “Biomistral: A collection of open-source pretrained large language models for medical domains,” inFindings of the association for computational linguistics: acl 2024, 2024, pp. 5848–5864
work page 2024
-
[21]
Meditron-70b: Scaling medical pretraining for large language models,
Z. Chen, A. H. Cano, A. Romanou, A. Bonnet, K. Matoba, F. Salvi, M. Pagliardini, S. Fan, A. K ¨opf, A. Mohtashamiet al., “Meditron-70b: Scaling medical pretraining for large language models,” 2023
work page 2023
-
[22]
Toward expert- level medical question answering with large language models,
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, M. Amin, L. Hou, K. Clark, S. R. Pfohl, H. Cole-Lewiset al., “Toward expert- level medical question answering with large language models,”Nature medicine, vol. 31, no. 3, pp. 943–950, 2025
work page 2025
-
[23]
A survey on rag meeting llms: Towards retrieval-augmented large language models,
W. Fan, Y . Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, and Q. Li, “A survey on rag meeting llms: Towards retrieval-augmented large language models,” inProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, 2024, pp. 6491–6501
work page 2024
-
[24]
Z. Wang, A. Liu, H. Lin, J. Li, X. Ma, and Y . Liang, “RAT: Retrieval augmented thoughts elicit context-aware reasoning and verification in long-horizon generation,” inNeurIPS 2024 Workshop on Open-World Agents, 2024. [Online]. Available: https: //openreview.net/forum?id=5QtKMjNkjL
work page 2024
-
[25]
Corrective Retrieval Augmented Generation
S.-Q. Yan, J.-C. Gu, Y . Zhu, and Z.-H. Ling, “Corrective retrieval augmented generation,”arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Enhancing large language models reasoning via multi-path optimization on knowledge graph,
J. Liao, C. Liu, Y . Ding, H. Wang, Z. Tang, K. Li, and K. Li, “Enhancing large language models reasoning via multi-path optimization on knowledge graph,”IEEE Transactions on Knowledge and Data Engineering, 2026
work page 2026
-
[27]
A framework of knowledge graph-enhanced large language model based on global planning,
Y . Li, D. Song, Y . Tian, H. Wang, C. Zhou, and S. Zhang, “A framework of knowledge graph-enhanced large language model based on global planning,”IEEE Transactions on Knowledge and Data Engineering, vol. 38, no. 2, pp. 736–748, 2025
work page 2025
-
[28]
The prisma 2020 statement: an updated guideline for reporting systematic reviews,
M. J. Page, J. E. McKenzie, P. M. Bossuyt, I. Boutron, T. C. Hoffmann, C. D. Mulrow, L. Shamseer, J. M. Tetzlaff, E. A. Akl, S. E. Brennan, R. Chou, J. Glanville, J. M. Grimshaw, A. Hr ´objartsson, M. M. Lalu, T. Li, E. W. Loder, E. Mayo-Wilson, S. McDonald, L. A. McGuinness, L. A. Stewart, J. Thomas, A. C. Tricco, V . A. Welch, P. Whiting, and D. Moher, ...
work page 2020
-
[29]
The well-built clinical question: a key to evidence-based decisions
W. S. Richardson, M. C. Wilson, J. Nishikawa, and R. S. Hayward, “The well-built clinical question: a key to evidence-based decisions.” ACP journal club, vol. 123, no. 3, pp. A12–3, 1995
work page 1995
-
[30]
B. Nye, J. J. Li, R. Patel, Y . Yang, I. Marshall, A. Nenkova, and B. C. Wallace, “A corpus with multi-level annotations of patients, interventions and outcomes to support language processing for medical literature,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018, pp. 197–207
work page 2018
-
[31]
Evaluation of pico as a knowledge representation for clinical questions,
X. Huang, J. Lin, and D. Demner-Fushman, “Evaluation of pico as a knowledge representation for clinical questions,” inAMIA annual symposium proceedings, vol. 2006, 2006, p. 359
work page 2006
-
[32]
Inferring which medical treatments work from reports of clinical trials,
E. Lehman, J. DeYoung, R. Barzilay, and B. C. Wallace, “Inferring which medical treatments work from reports of clinical trials,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 3705–3717
work page 2019
-
[33]
Robotreviewer: evaluation of a system for automatically assessing bias in clinical trials,
I. J. Marshall, J. Kuiper, and B. C. Wallace, “Robotreviewer: evaluation of a system for automatically assessing bias in clinical trials,”Journal of the American Medical Informatics Association, vol. 23, no. 1, pp. 193–201, 2016
work page 2016
-
[34]
Tri- alstreamer: A living, automatically updated database of clinical trial reports,
I. J. Marshall, B. Nye, J. Kuiper, A. Noel-Storr, R. Marshall, R. Maclean, F. Soboczenski, A. Nenkova, J. Thomas, and B. C. Wallace, “Tri- alstreamer: A living, automatically updated database of clinical trial reports,”Journal of the American Medical Informatics Association, vol. 27, no. 12, pp. 1903–1912, 2020
work page 1903
-
[35]
P. Pradeep, M. Caro-Mart ´ınez, and A. Wijekoon, “Empowering ex- plainable artificial intelligence through case-based reasoning: A com- prehensive exploration,”IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[36]
Combination of evidence in dempster-shafer theory,
K. Sentz and S. Ferson, “Combination of evidence in dempster-shafer theory,” Sandia National Laboratories, Tech. Rep., 2002. 14
work page 2002
-
[37]
S. Li, H. Xu, J. Xu, X. Li, Y . Wang, J. Zeng, J. Li, X. Li, Y . Li, and W. Ai, “Inconsistency elimination of multi-source information fusion in smart home using the dempster-shafer evidence theory,”Information Processing & Management, vol. 61, no. 4, p. 103723, 2024
work page 2024
-
[38]
Neural-symbolic learning and reasoning: Contributions and challenges
A. S. d. Garcez, T. R. Besold, L. De Raedt, P. F¨oldiak, P. Hitzler, T. Icard, K.-U. K ¨uhnberger, L. C. Lamb, R. Miikkulainen, and D. L. Silver, “Neural-symbolic learning and reasoning: Contributions and challenges.” inAAAI Spring Symposia, 2015, pp. 18–21
work page 2015
-
[39]
Neurosymbolic ai: The 3rd wave,
A. d. Garcez and L. C. Lamb, “Neurosymbolic ai: The 3rd wave,” Artificial Intelligence Review, vol. 56, no. 11, pp. 12 387–12 406, 2023
work page 2023
-
[40]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 24 824–24 837
work page 2022
-
[41]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdh- ery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[42]
Re- flexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Re- flexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
work page 2023
-
[43]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Gpt-4o mini: Advancing cost-efficient intelligence,
OpenAI, “Gpt-4o mini: Advancing cost-efficient intelligence,” https: //openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/, 2024
work page 2024
-
[46]
gpt-oss-120b & gpt-oss-20b Model Card
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Baoet al., “gpt-oss-120b & gpt-oss-20b model card,”arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
M. Jeong, J. Sohn, M. Sung, and J. Kang, “Improving medical reason- ing through retrieval and self-reflection with retrieval-augmented large language models,”Bioinformatics, vol. 40, no. Supplement 1, pp. i119– i129, 2024
work page 2024
-
[48]
Ultramedical: Building specialized generalists in biomedicine,
K. Zhang, S. Zeng, E. Hua, N. Ding, Z.-R. Chen, Z. Ma, H. Li, G. Cui, B. Qi, X. Zhuet al., “Ultramedical: Building specialized generalists in biomedicine,”Advances in Neural Information Processing Systems, vol. 37, pp. 26 045–26 081, 2024
work page 2024
-
[49]
Towards medical complex reasoning with LLMs through medical verifiable problems,
J. Chen, Z. Cai, K. Ji, X. Wang, W. Liu, R. Wang, and B. Wang, “Towards medical complex reasoning with LLMs through medical verifiable problems,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 14 552–14 573
work page 2025
-
[50]
Llama-3-meditron: An open-weight suite of medical llms based on llama-3.1,
A. Sallinen, A.-J. Solergibert, M. Zhang, G. Boy ´e, M. Dupont-Roc, X. Theimer-Lienhard, E. Boisson, B. Bernath, H. Hadhri, A. Tranet al., “Llama-3-meditron: An open-weight suite of medical llms based on llama-3.1,” inWorkshop on Large Language Models and Generative AI for Health at AAAI 2025, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.