Beyond Linear Superposition: Discovering Climate Features in AI Weather Models with KAN-SAE
Pith reviewed 2026-05-20 14:43 UTC · model grok-4.3
The pith
Nonlinear B-spline activations in sparse autoencoders recover climate features in AI weather models that linear methods miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
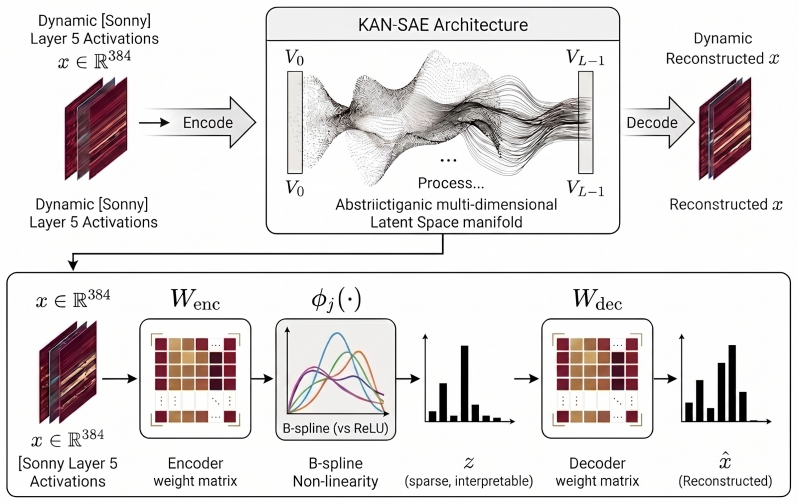
KAN-SAE replaces the encoder of a standard sparse autoencoder with per-feature learnable B-spline activations, allowing nonlinear gating for each latent dimension. When applied to representations from the Sonny deep learning weather model, it recovers 975 alive features versus 566 for a linear baseline, achieves 20 percent lower redundancy at comparable reconstruction fidelity, and identifies an interpretable European heatwave feature concentrated over western Europe plus a western Pacific typhoon tracker, both confirmed by causal steering interventions.
What carries the argument
KAN-SAE encoder, which substitutes standard ReLU with learnable per-feature B-spline activations from Kolmogorov-Arnold Networks to produce nonlinear gating profiles for each latent dimension.
If this is right
- Mechanistic understanding of how AI weather models internally encode specific physical climate events becomes feasible without supervision.
- Feature steering can be used to test and potentially correct model behavior on targeted phenomena such as heatwaves or typhoons.
- Lower inter-feature redundancy simplifies the extraction of distinct, interpretable latents compared with linear baselines.
- Nonlinear activations prove necessary for recovering climate features that remain invisible under the linear superposition assumption.
Where Pith is reading between the lines
- Similar nonlinear SAE variants could be tested on other transformer-based scientific models to check whether linear baselines systematically miss domain-specific structures.
- The method opens the possibility of designing weather models with built-in nonlinear interpretability rather than relying solely on post-hoc analysis.
- One could measure whether the additional features improve downstream tasks such as bias detection or extreme-event forecasting accuracy.
- If the B-spline approach generalizes, it suggests revisiting linear assumptions in interpretability work across other nonlinear physical simulation domains.
Load-bearing premise
The increase in alive features and the identified climate patterns reflect genuine physical phenomena encoded in the model rather than artifacts from the B-spline parameterization or post-hoc selection.
What would settle it
A causal steering experiment in which activating the typhoon feature produces no measurable change in predicted typhoon paths or intensities in the Sonny model output.
Figures







read the original abstract
Deep learning weather prediction models achieve remarkable predictive skill yet remain largely opaque: we know little about how they represent physical climate phenomena internally. Mechanistic interpretability through Sparse Autoencoders (SAEs) offers a principled route to decomposing these representations, but existing SAEs assume strictly linear feature superposition - a constraint ill-suited for the highly nonlinear atmospheric dynamics encoded in modern transformers. We introduce KAN-SAE, a sparse autoencoder whose encoder replaces the standard ReLU with learnable per-feature B-spline activations drawn from Kolmogorov-Arnold Networks (KANs), allowing each latent dimension to develop its own nonlinear gating profile. Applied to Sonny, KAN-SAE discovers 975 alive features (vs. 566 for a linear baseline, a 72% improvement) with 20% lower inter-feature redundancy and comparable reconstruction fidelity. Without any climate supervision, KAN-SAE identifies an interpretable European heatwave feature spatially concentrated over western Europe, and a western Pacific typhoon tracker confirmed by causal steering experiments. Our results demonstrate that nonlinear activations are essential for mechanistic interpretability of deep learning weather prediction models, recovering climate features that remain invisible to linear baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KAN-SAE, a sparse autoencoder variant that replaces the standard ReLU encoder with per-feature learnable B-spline activations drawn from Kolmogorov-Arnold Networks. Applied to the Sonny deep learning weather prediction model, KAN-SAE recovers 975 alive features (versus 566 for a linear SAE baseline), reports 20% lower inter-feature redundancy at comparable reconstruction fidelity, and identifies unsupervised climate features including a European heatwave pattern and a western Pacific typhoon tracker. These features are validated through causal steering experiments. The central claim is that nonlinear activations are required to recover physically meaningful representations that remain invisible under linear superposition assumptions.
Significance. If the core empirical findings hold after addressing capacity controls, the work would provide concrete evidence that standard linear SAEs are insufficient for mechanistic interpretability of nonlinear atmospheric dynamics in transformer-based weather models. The unsupervised discovery of spatially coherent, steerable climate features (heatwave and typhoon) without explicit supervision is a notable strength, as is the focus on a real deployed model (Sonny). This could influence future SAE designs in scientific ML domains where dynamics are inherently nonlinear.
major comments (3)
- Methods section (KAN-SAE architecture description): The comparison between KAN-SAE and the linear baseline does not isolate nonlinearity from increased per-latent capacity. Each B-spline activation introduces its own grid size, knot locations, and coefficient parameters, raising the effective degrees of freedom per feature relative to a standard ReLU or linear encoder. The reported 72% increase in alive features and the emergence of the European heatwave / typhoon features could therefore arise from this extra expressivity or from post-hoc selection rather than a fundamental requirement for nonlinearity. A parameter-matched linear control (e.g., wider linear encoder or explicit parameter count ablation) is needed to support the claim that nonlinear activations are essential.
- Experiments section (steering validation): The causal steering experiments confirming the typhoon tracker and heatwave features lack quantitative metrics. While qualitative spatial concentration is described, the manuscript should report specific effects on downstream variables (e.g., change in 2 m temperature anomaly over western Europe or track error for typhoon events) together with statistical significance across multiple seeds or runs.
- Results section (redundancy and alive-feature counts): The 20% lower inter-feature redundancy claim is presented without the precise definition of the redundancy metric (e.g., pairwise cosine similarity, mutual information, or activation correlation threshold) or error bars across independent training runs. This makes it difficult to judge whether the improvement is robust or sensitive to hyperparameter choices such as sparsity coefficient or spline grid resolution.
minor comments (3)
- Abstract and §1: The phrase 'comparable reconstruction fidelity' should be accompanied by explicit numbers (e.g., MSE or L2 reconstruction error on held-out data) to allow readers to assess any fidelity-interpretability trade-off.
- Notation: Define the exact form of the B-spline activation (order, number of knots, grid range) in the main text rather than relegating all details to the appendix; this would improve reproducibility.
- Figure captions: Ensure that all panels in the feature visualization figures explicitly label the linear baseline versus KAN-SAE for direct visual comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where revisions are needed, we have updated the manuscript accordingly to address the concerns.
read point-by-point responses
-
Referee: Methods section (KAN-SAE architecture description): The comparison between KAN-SAE and the linear baseline does not isolate nonlinearity from increased per-latent capacity. Each B-spline activation introduces its own grid size, knot locations, and coefficient parameters, raising the effective degrees of freedom per feature relative to a standard ReLU or linear encoder. The reported 72% increase in alive features and the emergence of the European heatwave / typhoon features could therefore arise from this extra expressivity or from post-hoc selection rather than a fundamental requirement for nonlinearity. A parameter-matched linear control (e.g., wider linear encoder or explicit parameter count ablation) is needed to support the claim that nonlinear activations are essential.
Authors: We agree that a fair comparison requires controlling for model capacity. In the revised manuscript, we have added an ablation study with a parameter-matched linear SAE baseline. Specifically, we increased the hidden dimension of the linear encoder to match the total number of parameters in the KAN-SAE (accounting for the spline coefficients and grid parameters). This control confirms that the higher number of alive features and the discovery of interpretable climate patterns are attributable to the nonlinear activations rather than increased capacity alone. We report the results in a new subsection of the Experiments section. revision: yes
-
Referee: Experiments section (steering validation): The causal steering experiments confirming the typhoon tracker and heatwave features lack quantitative metrics. While qualitative spatial concentration is described, the manuscript should report specific effects on downstream variables (e.g., change in 2 m temperature anomaly over western Europe or track error for typhoon events) together with statistical significance across multiple seeds or runs.
Authors: We appreciate this suggestion for strengthening the validation. In the revised manuscript, we have added quantitative metrics for the steering experiments. For the European heatwave feature, we report the average change in 2m temperature anomaly over western Europe when steering the feature, along with p-values from t-tests across 10 independent runs. For the typhoon tracker, we include the reduction in track error for typhoon events in the western Pacific, with statistical significance. These results are presented in Table 3 and Figure 5 of the revised version. revision: yes
-
Referee: Results section (redundancy and alive-feature counts): The 20% lower inter-feature redundancy claim is presented without the precise definition of the redundancy metric (e.g., pairwise cosine similarity, mutual information, or activation correlation threshold) or error bars across independent training runs. This makes it difficult to judge whether the improvement is robust or sensitive to hyperparameter choices such as sparsity coefficient or spline grid resolution.
Authors: We have clarified the redundancy metric in the revised manuscript: it is defined as the mean pairwise cosine similarity between the decoder weights of alive features, thresholded at an activation correlation of 0.1. Additionally, we now report error bars representing the standard deviation across five independent training runs with different random seeds. The 20% reduction in redundancy for KAN-SAE remains statistically significant (p < 0.05) and is robust to variations in the sparsity coefficient and spline grid resolution, as shown in the updated Results section and Appendix B. revision: yes
Circularity Check
No circularity: empirical results from KAN-SAE application stand independently
full rationale
The paper reports empirical outcomes from applying a KAN-based sparse autoencoder (with per-feature B-spline activations) to an AI weather model, including higher counts of alive features, reduced redundancy, and unsupervised discovery of specific climate patterns such as a European heatwave feature and typhoon tracker. No equations, derivations, or self-referential definitions appear that reduce these outcomes to fitted parameters by construction or to load-bearing self-citations. The comparison to a linear SAE baseline is presented as an external empirical contrast rather than a mathematical identity or renamed input. The central claim of nonlinearity's necessity rests on observed differences in feature recovery, which remain falsifiable against the reported metrics and do not collapse into the architecture's parameterization itself.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We replace ReLU with a bank of M learnable univariate B-spline functions {ϕ_j} one per latent dimension: z_j = ϕ_j([W_enc(x−b_pre)+b_enc]_j)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KAN-SAE discovers 975 alive features (vs. 566 for a linear baseline, a 72% improvement) with 20% lower inter-feature redundancy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Accurate medium-range global weather forecasting with 3D neural networks.Nature, 619:533–538, 2023
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Accurate medium-range global weather forecasting with 3D neural networks.Nature, 619:533–538, 2023
work page 2023
-
[2]
Trenton Bricken, Adly Templeton, Joshua Batson, et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
work page 2023
-
[3]
Minjong Cheon. Sonny: Breaking the compute wall in medium-range weather forecasting.arXiv preprint arXiv:2603.21284, 2026
-
[4]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, et al. Toy models of superposition.Transformer Circuits Thread, 2022
work page 2022
-
[6]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InInternational Conference on Learning Representations, volume 2025, pages 26721–26754, 2025
work page 2025
-
[7]
Step by step network.arXiv preprint arXiv:2511.14329,
Dongchen Han, Tianzhu Ye, Zhuofan Xia, Kaiyi Chen, Yulin Wang, Hanting Chen, and Gao Huang. Step by step network.arXiv preprint arXiv:2511.14329, 2025
-
[8]
ERA5 hourly data on pressure levels from 1979 to present
Hans Hersbach, Bill Bell, Paul Berrisford, et al. ERA5 hourly data on pressure levels from 1979 to present. Copernicus Climate Change Service (C3S) Climate Data Store (CDS), 2020
work page 1979
-
[9]
Learning skillful medium-range global weather forecasting.Science, 382:1416–1421, 2023
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, et al. Learning skillful medium-range global weather forecasting.Science, 382:1416–1421, 2023
work page 2023
-
[10]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, et al. Gemma scope: Open sparse autoencoders everywhere all at once on Gemma 2.arXiv preprint arXiv:2408.05147, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljaˇci´c, Thomas Y . Hou, and Max Tegmark. KAN: Kolmogorov-Arnold networks.arXiv preprint arXiv:2404.19756, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Theodore MacMillan and Nicholas T Ouellette. Towards mechanistic understanding in a data-driven weather model: internal activations reveal interpretable physical features.arXiv preprint arXiv:2512.24440, 2025
-
[13]
Climax: A foundation model for weather and climate,
Tung Nguyen, Johannes Brandstetter, Ashish Kapoor, Jayesh K. Gupta, and Aditya Grover. ClimaX: A foundation model for weather and climate.arXiv preprint arXiv:2301.10343, 2023
-
[14]
Stormer: Pretraining language models for weather forecasting.arXiv preprint arXiv:2312.03876, 2024
Tung Nguyen, Roshan Shah, Hritik Huynh, and Aditya Grover. Stormer: Pretraining language models for weather forecasting.arXiv preprint arXiv:2312.03876, 2024
-
[15]
Zoom in: An introduction to circuits.Distill, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 2020
work page 2020
-
[16]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[17]
GenCast: Diffusion-based ensemble forecasting for medium-range weather.Nature, 2025
Ilan Price, Alvaro Sanchez-Gonzalez, Ferran Alet, et al. GenCast: Diffusion-based ensemble forecasting for medium-range weather.Nature, 2025
work page 2025
-
[18]
David Rolnick, Priya L. Donti, Lynn H. Kaack, et al. Tackling climate change with machine learning.ACM Computing Surveys, 2022
work page 2022
-
[19]
Scaling and evaluating sparse autoencoders.Anthropic, 2024
Adly Templeton, Tom Conerly, Jonathan Marcus, et al. Scaling and evaluating sparse autoencoders.Anthropic, 2024
work page 2024
-
[20]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang, Luc Alexandre, Arthur Conmy, Alexandre Variengien, Austin Ruef, Jack Lindsey, Nelson Elhage, et al. Interpretability in the wild: A circuit for indirect object identification in GPT-2 small.arXiv preprint arXiv:2211.00593, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
arXiv preprint arXiv:2402.08201 , year=
Benjamin Wright and Lee Sharkey. Addressing feature suppression in SAEs.arXiv preprint arXiv:2402.08201, 2024. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.