Mono-Hydra++: Real-Time Monocular Scene Graph Construction with Multi-Task Learning for 3D Indoor Mapping
Pith reviewed 2026-05-20 12:02 UTC · model grok-4.3
The pith
Mono-Hydra++ builds real-time 3D scene graphs from monocular RGB and IMU data alone while matching or beating RGB-D trajectory accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
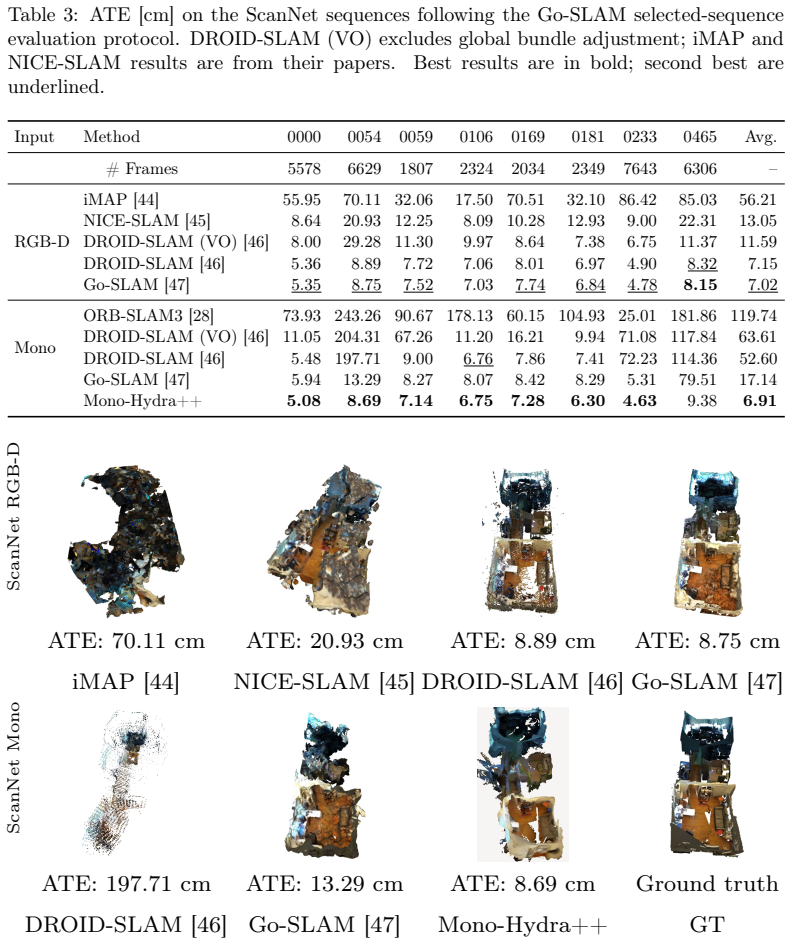
Mono-Hydra++ demonstrates that a DINOv3-based multi-task model for depth and semantics, combined with deep feature VIO, sparse predicted depth constraints in the pose graph, semantic masking for dynamic regions, and pose-aware temporal alignment before volumetric fusion, produces real-time monocular metric semantic maps and 3D scene graphs that achieve 1.6 percent lower average trajectory error than the strongest RGB-D baseline on the Go-SLAM ScanNet evaluation subset and 29.8 percent improvement over the strongest competing calibrated baseline on 7-Scenes.
What carries the argument
M2H-MX multi-task model supplying depth and semantic predictions that serve as sparse constraints inside the VIO-derived pose graph.
Load-bearing premise
The depth and semantic predictions from the multi-task model remain accurate enough to act as useful constraints in the pose graph without increasing overall trajectory error.
What would settle it
A measurement on the Go-SLAM ScanNet subset showing average trajectory error higher than the strongest RGB-D baseline would indicate that the added depth constraints do not deliver the claimed accuracy benefit.
Figures













read the original abstract
Autonomous agile robots need more than metric geometry: they must understand objects, rooms, places, and spatial relations for search, inspection, exploration, and human robot interaction. Conventional metric maps support localization and collision avoidance, but do not provide this semantic and relational structure. 3D scene graphs address this gap by connecting geometry with object level and room level understanding. Building such representations on agile platforms remains difficult because aerial and lightweight robots operate under strict payload, power, and compute limits, making RGB-D cameras and LiDAR sensors impractical for many onboard settings. We present Mono-Hydra++, a real time monocular RGB plus IMU pipeline for indoor metric semantic mapping and hierarchical 3D scene graph construction. The system combines M2H-MX, a DINOv3 based multi-task model for depth and semantics, with a deep feature visual inertial odometry front end, sparse predicted depth constraints in the VIO derived pose graph, semantic masking for dynamic regions, and pose aware temporal alignment before volumetric fusion in the Mono-Hydra backend. On the Go-SLAM ScanNet evaluation subset, Mono-Hydra++ achieves 1.6% lower average trajectory error than the strongest RGB-D baseline in our comparison, while using only monocular RGB plus IMU input. On calibrated 7-Scenes, it improves average ATE by 29.8% over the strongest competing calibrated baseline. We further validate Mono-Hydra++ in a real ITC building deployment using RealSense RGB plus IMU and demonstrate embedded feasibility by deploying the ONNX/TensorRT FP16 M2H-MX-L perception model at 25.53 FPS on a Jetson Orin NX 16GB. These results show that Mono-Hydra++ can provide real time metric semantic mapping and scene graph construction for resource constrained robotic platforms without relying on active depth sensors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Mono-Hydra++, a real-time monocular RGB+IMU pipeline for indoor metric semantic mapping and hierarchical 3D scene graph construction. It integrates M2H-MX, a DINOv3-based multi-task model for depth and semantics, with a deep-feature VIO front-end, sparse predicted depth constraints in the VIO pose graph, semantic masking for dynamic regions, and pose-aware temporal alignment prior to volumetric fusion in the Mono-Hydra backend. The central claims are 1.6% lower average trajectory error than the strongest RGB-D baseline on the Go-SLAM ScanNet evaluation subset and 29.8% ATE improvement over the strongest competing calibrated baseline on 7-Scenes, plus real-time embedded feasibility at 25.53 FPS on Jetson Orin NX and validation in a real ITC building deployment.
Significance. If the results hold, the work would be significant for enabling semantic and relational scene understanding on payload- and power-constrained agile robots without active depth sensors. Credit is given for the embedded ONNX/TensorRT deployment results and the real-world building validation, which directly address practical constraints in robotics. The approach bridges metric VIO with multi-task perception for scene graphs, which is a relevant direction for indoor mapping applications.
major comments (2)
- Abstract: The headline claim of 1.6% lower ATE than the strongest RGB-D baseline on Go-SLAM ScanNet (and 29.8% on 7-Scenes) depends on sparse depth predictions from M2H-MX serving as useful constraints in the VIO-derived pose graph. No ablation isolating the depth constraints' contribution, no depth error statistics on the evaluation subsets, and no pose-graph residual comparisons with versus without the predictions are provided, so it remains unclear whether the observed gains originate from the depth output, semantic masking, temporal alignment, or the deep-feature VIO front-end.
- Evaluation section: The weakest assumption—that DINOv3-based depth predictions are accurate enough to act as useful constraints without introducing scale or bias errors that degrade trajectory accuracy—is not directly tested. Systematic monocular depth errors typical in indoor scenes could be down-weighted to near zero or actively harm the optimization; without reported depth metrics or controlled experiments on the ScanNet and 7-Scenes subsets, the source of the ATE improvements cannot be verified.
minor comments (1)
- Abstract: The system description would benefit from explicit cross-references to the full manuscript sections describing the M2H-MX architecture, the exact formulation of the sparse depth constraints in the pose graph, and the volumetric fusion backend.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the validation of our depth constraint contributions. We address each major comment below and will incorporate the suggested analyses into the revised manuscript to strengthen the evaluation.
read point-by-point responses
-
Referee: Abstract: The headline claim of 1.6% lower ATE than the strongest RGB-D baseline on Go-SLAM ScanNet (and 29.8% on 7-Scenes) depends on sparse depth predictions from M2H-MX serving as useful constraints in the VIO-derived pose graph. No ablation isolating the depth constraints' contribution, no depth error statistics on the evaluation subsets, and no pose-graph residual comparisons with versus without the predictions are provided, so it remains unclear whether the observed gains originate from the depth output, semantic masking, temporal alignment, or the deep-feature VIO front-end.
Authors: We agree that isolating the contribution of the sparse depth constraints is important for substantiating the headline claims. The current results reflect the integrated Mono-Hydra++ pipeline, but to directly address the source of the ATE gains, the revised manuscript will add: depth prediction error statistics (RMSE, AbsRel, etc.) on the Go-SLAM ScanNet and 7-Scenes subsets; an ablation study that removes the depth constraints from the VIO pose graph while keeping other components fixed and reports the resulting ATE; and a comparison of pose-graph residuals with versus without the predicted depth terms. These additions will clarify the role of the depth output relative to semantic masking and the deep-feature front-end. revision: yes
-
Referee: Evaluation section: The weakest assumption—that DINOv3-based depth predictions are accurate enough to act as useful constraints without introducing scale or bias errors that degrade trajectory accuracy—is not directly tested. Systematic monocular depth errors typical in indoor scenes could be down-weighted to near zero or actively harm the optimization; without reported depth metrics or controlled experiments on the ScanNet and 7-Scenes subsets, the source of the ATE improvements cannot be verified.
Authors: We acknowledge that the assumption regarding depth prediction accuracy requires direct testing. The manuscript currently emphasizes end-to-end trajectory and mapping results, but to verify that the predictions act as useful constraints without harmful bias or scale drift, we will include the depth error metrics and controlled ablation experiments described in the response to the first comment. These will be added to the evaluation section, allowing readers to assess whether the monocular depth outputs improve or degrade the optimization on the reported datasets. revision: yes
Circularity Check
No significant circularity; system evaluation relies on external baselines and datasets
full rationale
The paper describes a composite pipeline (M2H-MX depth/semantics model + deep-feature VIO + sparse depth constraints + semantic masking + volumetric fusion) evaluated on ScanNet and 7-Scenes subsets against external RGB-D and calibrated baselines. No equations, fitted parameters, or self-citations are shown that would make the reported ATE improvements equivalent to internal definitions or prior author results by construction. The central claims remain falsifiable via the cited public datasets and competing methods.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On the Go-SLAM ScanNet evaluation subset, Mono-Hydra++ achieves 1.6% lower average trajectory error than the strongest RGB-D baseline while using only monocular RGB plus IMU input
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
I. Armeni, Z.-Y. He, J. Gwak, A. R. Zamir, M. Fischer, J. Malik, S. Savarese, 3d scene graph: A structure for unified semantics, 3d space, and camera, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5664–5673
work page 2019
-
[2]
A. Rosinol, M. Abate, Y. Chang, L. Carlone, Kimera: an open-source library for real-time metric-semantic localization and mapping, in: 2020 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2020, pp. 1689–1696
work page 2020
- [3]
-
[4]
A. Rosinol, A. Violette, M. Abate, N. Hughes, Y. Chang, J. Shi, A. Gupta, L. Carlone, Kimera: From slam to spatial perception with 3d dynamic scene graphs, The International Journal of Robotics Research 40 (2021) 1510–1546
work page 2021
- [5]
-
[6]
Z. Huai, G. Huang, Robocentric visual–inertial odometry, The Interna- tional Journal of Robotics Research 41 (2022) 667–689
work page 2022
- [7]
-
[8]
D. Xu, W. Ouyang, X. Wang, N. Sebe, Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 675–684
work page 2018
-
[9]
S. Vandenhende, S. Georgoulis, L. Van Gool, Mti-net: Multi-scale task interaction networks for multi-task learning, in: European conference on computer vision, Springer, 2020, pp. 527–543. 44
work page 2020
-
[10]
H. Ye, D. Xu, Inverted pyramid multi-task transformer for dense scene understanding, in: European Conference on Computer Vision, Springer, 2022, pp. 514–530
work page 2022
-
[11]
X. Xu, H. Zhao, V. Vineet, S.-N. Lim, A. Torralba, Mtformer: Multi- task learning via transformer and cross-task reasoning, in: European Conference on Computer Vision, Springer, 2022, pp. 304–321
work page 2022
-
[12]
U. Udugama, G. Vosselman, F. Nex, Mono-hydra real-time 3d scene graph construction from monocular camera input with imu, ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences 1 (2023) 439–445
work page 2023
-
[13]
U. Udugama, G. Vosselman, F. Nex, M2h: Multi-task learning with efficient window-based cross-task attention for monocular spatial per- ception, arXiv preprint arXiv:2510.17363 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
A. R. Zamir, A. Sax, W. Shen, L. J. Guibas, J. Malik, S. Savarese, Taskonomy: Disentangling task transfer learning, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3712–3722
work page 2018
-
[16]
I. Lopes, T.-H. Vu, R. de Charette, Densemtl: Cross-task at- tention mechanism for dense multi-task learning, arXiv preprint arXiv:2206.08927 (2022)
- [17]
-
[18]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, H. Zhao, Depth anything: Unleashing the power of large-scale unlabeled data, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 10371–10381. 45
work page 2024
-
[19]
S. F. Bhat, R. Birkl, D. Wofk, P. Wonka, M. Müller, Zoedepth: Zero- shot transfer by combining relative and metric depth, arXiv preprint arXiv:2302.12288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
D. Brüggemann, M. Kanakis, A. Obukhov, S. Georgoulis, L. Van Gool, Exploring relational context for multi-task dense prediction, in: Pro- ceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15869–15878
work page 2021
-
[21]
Y. Yang, P.-T. Jiang, Q. Hou, H. Zhang, J. Chen, B. Li, Multi-task dense prediction via mixture of low-rank experts, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 27927–27937
work page 2024
-
[22]
B. Lin, W. Jiang, P. Chen, Y. Zhang, S. Liu, Y.-C. Chen, Mtmamba: Enhancing multi-task dense scene understanding by mamba-based de- coders, in: European Conference on Computer Vision, Springer, 2024, pp. 314–330
work page 2024
-
[23]
B. Lin, W. Jiang, P. Chen, S. Liu, Y.-C. Chen, Mtmamba++: Enhanc- ing multi-task dense scene understanding via mamba-based decoders, IEEETransactionsonPatternAnalysisandMachineIntelligence(2025)
work page 2025
-
[24]
L. Bao, B. Wu, W. Liu, Cnn in mrf: Video object segmentation via inference in a cnn-based higher-order spatio-temporal mrf, in: Proceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5977–5986
work page 2018
-
[25]
A. Tarvainen, H. Valpola, Mean teachers are better role models: Weight- averaged consistency targets improve semi-supervised deep learning re- sults, Advances in neural information processing systems 30 (2017)
work page 2017
- [26]
- [27]
- [28]
-
[29]
T. Qin, P. Li, S. Shen, Vins-mono: A robust and versatile monocular visual-inertial state estimator, IEEE transactions on robotics 34 (2018) 1004–1020
work page 2018
-
[30]
Z. Huai, G. Huang, Square-root robocentric visual-inertial odometry with online spatiotemporal calibration, IEEE Robotics and Automation Letters 7 (2022) 9961–9968
work page 2022
-
[31]
L. Han, Y. Lin, G. Du, S. Lian, Deepvio: Self-supervised deep learning of monocular visual inertial odometry using 3d geometric constraints, in: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2019, pp. 6906–6913
work page 2019
-
[32]
S. Fei, J. Li, L. Li, J. Liang, J. Hu, D. Zhang, J. Han, Transformer based visual inertial odometry, in: International Conference on Guidance, Navigation and Control, Springer, 2024, pp. 567–575
work page 2024
-
[33]
Y. Pan, W. Zhou, Y. Cao, H. Zha, Adaptive vio: Deep visual-inertial odometry with online continual learning, in: 2024 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2024, pp. 18019–18028
work page 2024
- [34]
- [35]
- [36]
-
[37]
A. Rosinol, J. J. Leonard, L. Carlone, Nerf-slam: Real-time dense monocular slam with neural radiance fields, in: 2023 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), IEEE, 2023, pp. 3437–3444
work page 2023
-
[38]
Z. Zhu, S. Peng, V. Larsson, Z. Cui, M. R. Oswald, A. Geiger, M. Polle- feys, Nicer-slam: Neural implicit scene encoding for rgb slam, in: 2024 International Conference on 3D Vision (3DV), IEEE, 2024, pp. 42–52
work page 2024
-
[39]
X. Yang, H. Li, H. Zhai, Y. Ming, Y. Liu, G. Zhang, Vox-fusion: Dense tracking and mapping with voxel-based neural implicit representation, in: 2022 IEEE International Symposium on Mixed and Augmented Re- ality (ISMAR), IEEE, 2022, pp. 499–507
work page 2022
-
[40]
M. M. Johari, C. Carta, F. Fleuret, Eslam: Efficient dense slam system based on hybrid representation of signed distance fields, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, 2023, pp. 17408–17419
work page 2023
-
[41]
Z. Hong, B. Wang, H. Duan, Y. Huang, X. Li, Z. Wen, X. Wu, W. Xiang, Y. Zheng, Sp-slam: Neural real-time dense slam with scene priors, IEEE Transactions on Circuits and Systems for Video Technology (2025)
work page 2025
-
[42]
Gaussian-slam: Photo-realistic dense slam with gaussian splatting,
V. Yugay, Y. Li, T. Gevers, M. R. Oswald, Gaussian-slam: Photo- realistic dense slam with gaussian splatting, 2024. URL:https:// arxiv.org/abs/2312.10070.arXiv:2312.10070
-
[43]
E. Sandström, K. Tateno, M. Oechsle, M. Niemeyer, L. Van Gool, M. R. Oswald, F. Tombari, Splat-slam: Globally optimized rgb-only slam with 3d gaussians, arXiv preprint arXiv:2405.16544 (2024)
- [44]
-
[45]
Z. Zhu, S. Peng, V. Larsson, W. Xu, H. Bao, Z. Cui, M. R. Oswald, M. Pollefeys, Nice-slam: Neural implicit scalable encoding for slam, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 12786–12796. 48
work page 2022
-
[46]
Z. Teed, J. Deng, DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, andRGB-DCameras, Advancesinneuralinformationprocessing systems (2021)
work page 2021
- [47]
-
[48]
O. Siméoni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haz- iza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. Jégou, P. Labatut, P. Bojanowski, DINOv3, 2025. URL:https: //arxiv.org/abs/2508.1...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
A. Gu, T. Dao, Mamba: Linear-time sequence modeling with selective state spaces, arXiv preprint arXiv:2312.00752 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Derf: Decomposed radiance fields,
S. Farooq Bhat, I. Alhashim, P. Wonka, Adabins: Depth estimation using adaptive bins, in: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2021, pp. 4008–4017. URL:http://dx.doi.org/10.1109/CVPR46437.2021.00400. doi:10. 1109/CVPR46437.2021.00400
-
[51]
A. Kendall, Y. Gal, R. Cipolla, Multi-task learning using uncertainty to weigh losses for scene geometry and semantics, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7482–7491
work page 2018
- [52]
-
[53]
N. Silberman, D. Hoiem, P. Kohli, R. Fergus, Indoor segmentation and support inference from rgbd images, in: European Conference on Computer Vision, 2012, pp. 746–760
work page 2012
- [54]
-
[55]
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, M. Nießner, Scannet: Richly-annotated 3d reconstructions of indoor scenes, in: Pro- ceedings of the IEEE conference on computer vision and pattern recog- nition, 2017, pp. 5828–5839
work page 2017
-
[56]
J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, A. Fitzgibbon, Scene coordinate regression forests for camera relocalization in rgb-d images, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 2930–2937
work page 2013
-
[57]
H. Ye, D. Xu, Taskprompter: Spatial-channel multi-task prompting for dense scene understanding, The Eleventh International Conference on Learning Representations, 2023. URL:https://openreview.net/ forum?id=-CwPopPJda
work page 2023
-
[58]
P. Taghavi, R. Langari, G. Pandey, Swinmtl: A shared architecture for simultaneous depth estimation and semantic segmentation from monoc- ular camera images, in: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2024, pp. 4957–4964
work page 2024
-
[59]
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y. Qiao, W. Ouyang, T. He, H. Zhao, Point transformer v3: Simpler, faster, stronger, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 4840–4851
work page 2024
-
[60]
K. Knaebel, K. Yilmaz, D. de Geus, A. Hermans, D. Adrian, T. Lin- der, B. Leibe, Dino in the room: Leveraging 2d foundation models for 3d segmentation, International Conference on 3D Vision (3DV), 2026. arXiv:2503.18944. 50
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.