Enhancing the Code Reasoning Capabilities of LLMs via Consistency-based Reinforcement Learning
Pith reviewed 2026-05-20 13:09 UTC · model grok-4.3
The pith
Consistency checks across reasoning steps improve how well LLMs predict program outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
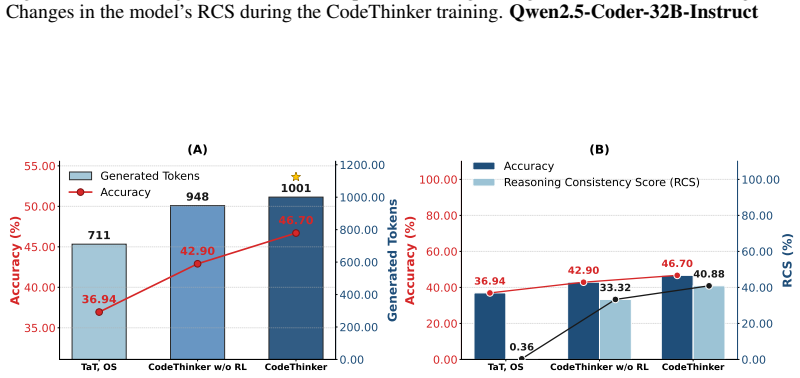
CodeThinker is a consistency-driven reinforcement learning framework with three parts: a stepwise reasoning-aware training module that uses a consistency tracing paradigm to synthesize data capturing the step-by-step process, a dynamic beam sampling strategy that improves output quality under fixed budgets, and a consistency reward that reduces hacking. When applied to multiple base models, the framework reaches state-of-the-art accuracy on code reasoning benchmarks and delivers average gains of 5.33 points on mathematical reasoning and 3.11 points on code tasks spanning 17 languages, all without additional training.
What carries the argument
The consistency tracing paradigm, which acts as a template to generate training examples that record aligned intermediate reasoning steps for predicting a program's output given its code and inputs.
Load-bearing premise
The consistency tracing method produces synthetic training data that correctly reflects the true step-by-step reasoning process without adding systematic errors or biases.
What would settle it
A clear test would be to check whether models trained under the consistency reward show no accuracy gain, or even lower accuracy, on a fresh set of programs where each intermediate reasoning step can be verified independently against actual execution traces.
Figures






















read the original abstract
Code reasoning refers to the task of predicting the output of a program given its source code and specific inputs. It can measure the reasoning capability of large language models (LLMs) and also benefit downstream tasks such as code generation and mathematical reasoning. Existing work has verified the effectiveness of reinforcement learning on the task. However, these methods design rewards solely based on final outputs or coarse-grained signals, and neglect the inherent consistency of the stepwise reasoning process in the task. Therefore, these methods often result in sparse reward or reward hacking, which limits the full play of enhanced learning capabilities. To alleviate these issues, we propose CodeThinker, a consistency-driven reinforcement learning framework for code reasoning. Specifically, CodeThinker has three key components: (1) a stepwise reasoning-aware model training module, which utilizes a consistency tracing paradigm as a template to synthesize training data that captures the stepwise reasoning process; (2) a dynamic beam sampling strategy, which aims to improve the quality of sampled outputs under a fixed sampling budget; and (3) a consistency reward mechanism that can effectively alleviate reward hacking. Experiments on three popular benchmarks show that CodeThinker achieves state-of-the-art performance across multiple LLMs. For instance, it outperforms the strongest baseline by 4.3% in accuracy when deployed on Qwen2.5-Coder-7B-Instruct. We also validate the effectiveness of CodeThinker on downstream tasks. Results show that, without additional training, CodeThinker obtains average accuracy gains of 5.33 and 3.11 percentage points on mathematical reasoning and code reasoning tasks covering 17 programming languages, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CodeThinker, a consistency-driven reinforcement learning framework to enhance LLMs' code reasoning. It comprises three components: (1) a stepwise reasoning-aware training module that uses a consistency tracing paradigm to synthesize training trajectories capturing intermediate reasoning steps; (2) a dynamic beam sampling strategy to improve output quality under fixed compute; and (3) a consistency reward mechanism intended to mitigate sparse rewards and reward hacking. Experiments on three benchmarks report state-of-the-art results across multiple LLMs, including a 4.3% accuracy gain over the strongest baseline on Qwen2.5-Coder-7B-Instruct, plus downstream gains of 5.33 and 3.11 percentage points on mathematical reasoning and multi-language code tasks without further training.
Significance. If the reported gains prove robust and the consistency signal is shown to be independent of base-model biases, the work would meaningfully advance RL-based reasoning methods by moving beyond final-answer rewards. The downstream transfer results without additional training would be a notable strength, as would any machine-checked or reproducible elements in the experimental pipeline.
major comments (3)
- [§3.1] §3.1 (consistency tracing paradigm): The synthesis procedure is described as prompting an LLM to generate stepwise trajectories followed by consistency filtering, but no ablation or diagnostic experiment is presented to test whether the resulting trajectories are independent of the generator model's own reasoning artifacts. This directly bears on whether the consistency reward in component (3) supplies a corrective signal or merely reinforces self-consistent but potentially incorrect patterns, undermining the central claim that the 4.3% gain reflects genuine capability improvement rather than self-reinforcement.
- [§4] §4 (experimental results): The 4.3% accuracy improvement on Qwen2.5-Coder-7B-Instruct and the downstream gains are reported without specifying the exact set of baselines, number of random seeds or evaluation runs, data splits, or statistical significance tests. These omissions make it impossible to assess whether the gains are load-bearing evidence for the framework or could be explained by variance or baseline selection.
- [§3.3] §3.3 (consistency reward): The reward is defined to penalize inconsistency across sampled trajectories, yet the manuscript provides no analysis of how this interacts with the dynamic beam sampling in §3.2 under the same sampling budget; if the two components are correlated by construction, the claimed alleviation of reward hacking may be overstated.
minor comments (2)
- [§3] Notation for the consistency score and beam width parameters is introduced without a consolidated table of symbols, making it harder to follow the reward formulation across sections.
- [Figure 2] Figure 2 (training curves) lacks error bars or shading for multiple runs, reducing clarity on stability of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below with honest responses, proposing specific revisions to the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [§3.1] §3.1 (consistency tracing paradigm): The synthesis procedure is described as prompting an LLM to generate stepwise trajectories followed by consistency filtering, but no ablation or diagnostic experiment is presented to test whether the resulting trajectories are independent of the generator model's own reasoning artifacts. This directly bears on whether the consistency reward in component (3) supplies a corrective signal or merely reinforces self-consistent but potentially incorrect patterns, undermining the central claim that the 4.3% gain reflects genuine capability improvement rather than self-reinforcement.
Authors: We agree this diagnostic is important for validating the core claim. The consistency tracing paradigm uses multiple independent generations followed by filtering to favor trajectories with internal agreement, which we designed to reduce error reinforcement. However, without an explicit test against generator artifacts, the distinction remains unproven. In the revised manuscript we will add a new ablation subsection that (i) regenerates trajectories using a different base LLM, (ii) measures overlap and step-level accuracy against a small set of human-annotated reasoning traces, and (iii) compares downstream RL performance with and without cross-model filtering. This will directly test whether the consistency signal supplies a corrective effect beyond self-reinforcement. revision: yes
-
Referee: [§4] §4 (experimental results): The 4.3% accuracy improvement on Qwen2.5-Coder-7B-Instruct and the downstream gains are reported without specifying the exact set of baselines, number of random seeds or evaluation runs, data splits, or statistical significance tests. These omissions make it impossible to assess whether the gains are load-bearing evidence for the framework or could be explained by variance or baseline selection.
Authors: We acknowledge that the current experimental reporting lacks the necessary rigor and transparency. In the revised version we will expand Section 4 and add an appendix that explicitly lists every baseline with citations and hyper-parameters, reports all main results as means and standard deviations over three independent random seeds, details the precise train/validation/test splits for each benchmark, and includes statistical significance tests (paired t-tests on per-instance accuracy) with p-values for the key comparisons. These additions will allow readers to evaluate the robustness of the reported gains. revision: yes
-
Referee: [§3.3] §3.3 (consistency reward): The reward is defined to penalize inconsistency across sampled trajectories, yet the manuscript provides no analysis of how this interacts with the dynamic beam sampling in §3.2 under the same sampling budget; if the two components are correlated by construction, the claimed alleviation of reward hacking may be overstated.
Authors: We recognize that the interaction between dynamic beam sampling and the consistency reward was not analyzed, leaving open the possibility that their benefits are not fully independent. Although the two components address different stages (exploration efficiency versus reward density), we will add a dedicated analysis subsection in the revision. This will include controlled experiments that fix the sampling budget while toggling dynamic versus uniform beam sampling, then measure reward hacking indicators (e.g., divergence between consistency reward and final-answer correctness) and final task accuracy. The results will clarify whether the claimed mitigation of reward hacking holds when the sampling strategy is held constant. revision: yes
Circularity Check
No circularity: empirical RL framework evaluated on external benchmarks
full rationale
The paper presents CodeThinker as a three-component empirical method (consistency tracing for data synthesis, dynamic beam sampling, consistency reward) whose central claims are validated through accuracy gains on three independent benchmarks and downstream tasks across 17 languages. No equations, derivations, or first-principles results are shown to reduce by construction to fitted parameters or self-generated inputs; the consistency reward is applied to improve upon baseline RL rather than tautologically re-deriving the synthesis process. External benchmark evaluation provides independent falsifiability, keeping the work self-contained without load-bearing self-citation chains or renamed empirical patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL training hyperparameters (learning rate, beam width, reward scaling)
axioms (1)
- domain assumption Consistency across reasoning steps is a valid proxy for genuine reasoning quality and reduces reward hacking
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the overall reward as R(y) = α Rproc(y) + I[Rproc(y)=2]·Rres(y) ... Rproc(y) = 2 δfmt(y) · (∑ wt ∏j≤t δj(y)) / (∑ wt) ... once an error occurs in the previous reasoning process, it blocks the rewards of subsequent reasoning processes
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
consistency tracing paradigm ... dynamic beam sampling strategy ... consistency reward mechanism
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alfred V . Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman.Compilers: Principles, Techniques, and Tools (2nd Edition). Addison-Wesley Longman Publishing Co., Inc., USA,
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. URLhttps://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D C, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, B. Ashok, and Shashank Shet. Codeplan: Repository-level coding using llms and planning, 2023. URLhttps://arxiv.org/abs/2309.12499
-
[4]
Reasoning runtime behavior of a program with llm: How far are we?, 2024
Junkai Chen, Zhiyuan Pan, Xing Hu, Zhenhao Li, Ge Li, and Xin Xia. Reasoning runtime behavior of a program with llm: How far are we?, 2024. URL https://arxiv.org/abs/ 2403.16437
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, Nicholas Schiefer, Ryan Soklaski, Alex Tamkin, Jared Kaplan, Buck Shlegeris, Samuel R. Bowman, Ethan Perez, and Evan Hubinger. Sycophancy to subterfuge: Inves- tigating reward-tampering in large language models, 2024. URL https://arxiv.org/abs/ 2406.10162
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Min, Gail Kaiser, Junfeng Yang, and Baishakhi Ray
Yangruibo Ding, Jinjun Peng, Marcus J. Min, Gail Kaiser, Junfeng Yang, and Baishakhi Ray. Semcoder: Training code language models with comprehensive semantics reasoning, 2024. URLhttps://arxiv.org/abs/2406.01006
-
[9]
Abstract syntax and variable binding
Marcelo Fiore, Gordon Plotkin, and Daniele Turi. Abstract syntax and variable binding. In Proceedings of the 14th Annual IEEE Symposium on Logic in Computer Science, LICS ’99, page 193, USA, 1999. IEEE Computer Society. ISBN 0769501583
work page 1999
-
[10]
PAL: Program-aided Language Models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models, 2023. URL https://arxiv.org/ abs/2211.10435
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Ryan Greenblatt, Carson Denison, Benjamin Wright, Fabien Roger, Monte MacDiarmid, Sam Marks, Johannes Treutlein, Tim Belonax, Jack Chen, David Duvenaud, Akbir Khan, Julian Michael, Sören Mindermann, Ethan Perez, Linda Petrini, Jonathan Uesato, Jared Kaplan, Buck Shlegeris, Samuel R. Bowman, and Evan Hubinger. Alignment faking in large language models,
-
[13]
URLhttps://arxiv.org/abs/2412.14093
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. Wang. Cruxeval: A benchmark for code reasoning, understanding and execution, 2024. URLhttps://arxiv.org/abs/2401.03065
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y . Wu, Y . K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming – the rise of code intelligence, 2024. URL https://arxiv.org/abs/2401.14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Measuring mathematical problem solving with the math dataset,
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset,
-
[17]
URLhttps://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report, 2024. URL https: //arxiv.org/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024. URL https://arxiv.org/abs/ 2403.07974. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention, 2023. URL https://arxiv.org/abs/2309. 06180
work page 2023
-
[22]
Codei/o: Condensing reasoning patterns via code input-output prediction, 2025
Junlong Li, Daya Guo, Dejian Yang, Runxin Xu, Yu Wu, and Junxian He. Codei/o: Condensing reasoning patterns via code input-output prediction, 2025. URL https://arxiv.org/abs/ 2502.07316
-
[23]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023. URL https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation, 2023. URLhttps://arxiv.org/abs/2305.01210
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Reposcope: Leveraging call chain-aware multi-view context for repository-level code generation, 2025
Yang Liu, Li Zhang, Fang Liu, Zhuohang Wang, Donglin Wei, Zhishuo Yang, Kechi Zhang, Jia Li, and Lin Shi. Reposcope: Leveraging call chain-aware multi-view context for repository-level code generation, 2025. URLhttps://arxiv.org/abs/2507.14791
-
[26]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective, 2025. URL https: //arxiv.org/abs/2503.20783
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Natural emergent misalignment from reward hacking in production rl, 2025
Monte MacDiarmid, Benjamin Wright, Jonathan Uesato, Joe Benton, Jon Kutasov, Sara Price, Naia Bouscal, Sam Bowman, Trenton Bricken, Alex Cloud, Carson Denison, Johannes Gasteiger, Ryan Greenblatt, Jan Leike, Jack Lindsey, Vlad Mikulik, Ethan Perez, Alex Rodrigues, Drake Thomas, Albert Webson, Daniel Ziegler, and Evan Hubinger. Natural emergent misalignmen...
-
[28]
Thomas J. McCabe. A complexity measure. InProceedings of the 2nd International Conference on Software Engineering, ICSE ’76, page 407, Washington, DC, USA, 1976. IEEE Computer Society Press
work page 1976
-
[29]
Catcoder: Repository-level code generation with relevant code and type context, 2025
Zhiyuan Pan, Xing Hu, Xin Xia, and Xiaohu Yang. Catcoder: Repository-level code generation with relevant code and type context, 2025. URLhttps://arxiv.org/abs/2406.03283
-
[30]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297. ACM, Mar 2025. doi: 10.1145/3689031.3696075. URL http://dx.doi.org/ 10.1145/3689031.3696075
-
[33]
Codereasoner: Enhancing the code reasoning ability with reinforcement learning, 2025
Lingxiao Tang, He Ye, Zhongxin Liu, Xiaoxue Ren, and Lingfeng Bao. Codereasoner: Enhancing the code reasoning ability with reinforcement learning, 2025. URL https: //arxiv.org/abs/2507.17548
-
[34]
Execverify: White-box rl with verifiable stepwise rewards for code execution reasoning,
Lingxiao Tang, He Ye, Zhaoyang Chu, Muyang Ye, Zhongxin Liu, Xiaoxue Ren, and Lingfeng Bao. Execverify: White-box rl with verifiable stepwise rewards for code execution reasoning,
- [35]
-
[36]
School of reward hacks: Hacking harmless tasks generalizes to misaligned behavior in llms, 2025
Mia Taylor, James Chua, Jan Betley, Johannes Treutlein, and Owain Evans. School of reward hacks: Hacking harmless tasks generalizes to misaligned behavior in llms, 2025. URL https: //arxiv.org/abs/2508.17511. 13
-
[37]
FAIR CodeGen team, Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, David Zhang, Kunhao Zheng, Jordi Armengol-Estapé, Pedram Bashiri, Maximilian Beck, Pierre Chambon, Abhishek Charnalia, Chris Cummins, Juliette Decugis, Zacharias V . Fisches, François Fleuret, Fabi...
- [38]
-
[39]
Rui Wu and Ruixiang Tang. When reward hacking rebounds: Understanding and mitigating it with representation-level signals, 2026. URLhttps://arxiv.org/abs/2604.01476
-
[40]
Leetcodedataset: A temporal dataset for robust evaluation and efficient training of code llms, 2025
Yunhui Xia, Wei Shen, Yan Wang, Jason Klein Liu, Huifeng Sun, Siyue Wu, Jian Hu, and Xiaolong Xu. Leetcodedataset: A temporal dataset for robust evaluation and efficient training of code llms, 2025. URLhttps://arxiv.org/abs/2504.14655
-
[41]
Cruxeval-x: A benchmark for multilingual code reasoning, understanding and execution, 2025
Ruiyang Xu, Jialun Cao, Yaojie Lu, Ming Wen, Hongyu Lin, Xianpei Han, Ben He, Shing-Chi Cheung, and Le Sun. Cruxeval-x: A benchmark for multilingual code reasoning, understanding and execution, 2025. URLhttps://arxiv.org/abs/2408.13001
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Repocoder: Repository-level code completion through iterative retrieval and generation, 2023
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. Repocoder: Repository-level code completion through iterative retrieval and generation, 2023. URLhttps://arxiv.org/abs/2303.12570
-
[45]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models, 2024. URLhttps://arxiv.org/abs/2403.13372. 14 A Related Work A.1 Evaluating LLMs on Code Execution Reasoning Task CRUXEval [13]CRUXEval introduces 800 short, self-contained Python functions...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Function f is called with s ='abc'and t ='a'
-
[47]
Calculate lengths: n = len(s) = 3, m = len(t) = 1
-
[48]
Initialize indices: i = 0, j = 0
-
[49]
Initialize rem = False
-
[50]
Enter the while loop (i < n and j < m): - First iteration: - i = 0, j = 0 - Check if s[i] != t[j]:'a'!='a'-> False - Since they are equal, execute`else`block: j += 1 -> j = 1 - i += 1 -> i = 1 - Second iteration: - Check if i < n (1 < 3) and j < m (1 < 1) -> False - Exit the loop
-
[51]
Return j, which is 1. [/THOUGHT] [ANSWER] assert f('abc','a') == 1 [/ANSWER] Figure 12: Case 1: a CodeReasoner GRPO rollout. 26 Case 2: an ExecVerify GRPO rollout. Input (abridged): [SYSTEM_PROMPT] ... [/SYSTEM_PROMPT] [INSTRUCTION] ... [/INSTRUCTION] Here is the code content: 1 def f(money, children): 2 if money < children: 3 return -1 4 if money > 8 * c...
-
[52]
- Include index 0 in the result list
**First iteration (i=0, w='abc')**: - Check if'a'in'abc'-> True. - Include index 0 in the result list
-
[53]
**Second iteration (i=1, w='bcd')**: - Check if'a'in'bcd'-> False. - Exclude index 1
-
[54]
- Include index 2 in the result list
**Third iteration (i=2, w='aaaa')**: - Check if'a'in'aaaa'-> True. - Include index 2 in the result list
-
[55]
**Fourth iteration (i=3, w='cbc')**: - Check if'a'in'cbc'-> False. - Exclude index 3. The final result list is [0, 2]. Local variables now include i=3 and w='cbc' (from the last iteration). [/THOUGHT] [LOCALS] {'words': ['abc','bcd','aaaa','cbc'],'x':'a','i': 3,'w':'cbc'} [/LOCALS] [RETURN] assert f(['abc','bcd','aaaa','cbc'],'a') == [0, 2] [/RETURN] [/TR...
-
[56]
Replace the "# THINKING" marker with your detailed step-by-step execution reasoning
- [57]
-
[58]
Output ONLY the completed result enclosed in "[COT]" and "[/COT]" tags. Do NOT output any other extra information outside the specified tags. Your reasoning in "[THOUGHT]" should: - Execute the code line by line with the given input values. - Track how variables change at each step. - For loops, trace each iteration explicitly. - For conditionals, explain...
-
[59]
The function f is called with nums = [1, -2, 3, -4, 5, -6]
- [60]
-
[61]
Loop over each element x in nums: - x = 1: 1 > 0 is True, so ans[0] = 1, i = 2. ans = [1, 0, 0, 0, 0, 0]. - x = -2: -2 > 0 is False, so ans[1] = -2, j = 3. ans = [1, -2, 0, 0, 0, 0]. - x = 3: 3 > 0 is True, so ans[2] = 3, i = 4. ans = [1, -2, 3, 0, 0, 0]. - x = -4: -4 > 0 is False, so ans[3] = -4, j = 5. ans = [1, -2, 3, -4, 0, 0]. - x = 5: 5 > 0 is True,...
-
[62]
The function returns ans = [1, -2, 3, -4, 5, -6]
The loop ends. The function returns ans = [1, -2, 3, -4, 5, -6]. [/THOUGHT] [ANSWER] assert f([1, -2, 3, -4, 5, -6]) == [1, -2, 3, -4, 5, -6] [/ANSWER] [/COT] Figure 21: An example of extracting vanilla tracing. 35 An example of the code reasoning of CodeReasoner. Input: [SYSTEM_PROMPT] ... [/SYSTEM_PROMPT] [INSTRUCTION] ... [/INSTRUCTION] [PYTHON] def f(...
-
[63]
**Function Call**:`f(['leet','code'],'e')`
-
[64]
**Initialization**: -`words = ['leet','code']` -`x ='e'` -`res = []`
-
[65]
- Append`i`(0) to`res`:`res = [0]`
**Loop Iteration**: - **First Iteration** (`i=0`,`w='leet'`): - Check if`x`('e') is in`w`('leet'):`'e'in'leet'`evaluates to `True`. - Append`i`(0) to`res`:`res = [0]`. - **Second Iteration** (`i=1`,`w='code'`): - Check if`x`('e') is in`w`('code'):`'e'in'code'`evaluates to `True`. - Append`i`(1) to`res`:`res = [0, 1]`
-
[66]
**Return Statement**: After processing all elements, return`res = [0, 1]`. [ANSWER] assert f(['leet','code'],'e') == [0, 1] [/ANSWER] Figure 22: An example of the code reasoning of CodeReasoner.[correct] 36 An example of the code reasoning of ExecVerify. Input: [SYSTEM_PROMPT] ... [/SYSTEM_PROMPT] [INSTRUCTION] ... [/INSTRUCTION] [PYTHON] def f(words, x):...
-
[67]
Function`f`is called with`words = ['leet','code']`and`x ='e'`
-
[68]
Since`'e'`is in `'leet'`, append`0`to`l`
Iterate over`range(len(words))`, which is`range(2)`(indices 0 and 1): - **Iteration 1 (i = 0)**: - Check if`'e'in words[0]`:`words[0]`is`'leet'`. Since`'e'`is in `'leet'`, append`0`to`l`. Now`l = [0]`. - **Iteration 2 (i = 1)**: - Check if`'e'in words[1]`:`words[1]`is`'code'`. Since`'e'`is in `'code'`, append`1`to`l`. Now`l = [0, 1]`
-
[69]
Return`l`, which is`[0, 1]`. [ANSWER] assert f(['leet','code'],'e') == [0, 1] [/ANSWER] Figure 23: An example of the code reasoning of ExecVerify.[correct] 37 An example of the code reasoning of CWM. Input: <|begin_of_text|><|trace_context_start|> def f(words, x): res = [] for i, w in enumerate(words): if x in w: res.append(i) return res def main(): # << ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.