WinTok: A Win-Win Hybrid Tokenizer via Decomposing Visual Understanding and Generation with Transferable Tokens
Pith reviewed 2026-05-20 12:00 UTC · model grok-4.3
The pith
WinTok adds learnable semantic tokens alongside pixel tokens to separate high-level understanding from low-level reconstruction in one tokenizer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
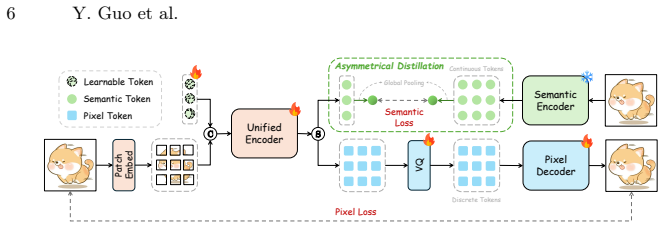
WinTok supplements pixel tokens with a set of learnable semantic tokens, effectively mitigating cross-task interference without incurring the computational overhead of dual tokenizers, and achieves consistent improvements across reconstruction, understanding, and generation.
What carries the argument
Hybrid tokenizer that pairs pixel tokens with learnable semantic tokens under asymmetric token distillation from pretrained embeddings.
Load-bearing premise
Pretrained semantic embeddings can guide the learnable tokens to gain strong discriminative power without interfering with pixel-level reconstruction.
What would settle it
A controlled ablation in which removing the semantic tokens or the distillation step produces no drop in classification accuracy or generation quality on the same benchmarks.
Figures









read the original abstract
Building a unified visual tokenizer is essential for bridging the gap between visual understanding and generation. Yet existing approaches struggle with the inherent conflict between these tasks, as a single token space is forced to support both high-level semantic abstraction and low-level pixel reconstruction. We propose WinTok, a concise hybrid tokenizer that achieves a win-win performance by explicitly decoupling the two objectives. WinTok supplements pixel tokens with a set of learnable semantic tokens, effectively mitigating cross-task interference without incurring the computational overhead of dual tokenizers. To further enhance understanding capability, we introduce an asymmetric token distillation mechanism: the semantic tokens are guided by pretrained semantic embeddings from any visual foundation model, enabling them to inherit strong discriminative power while maintaining flexibility. Across 10 challenging benchmarks, WinTok delivers consistent improvements in reconstruction, understanding, and generation. Trained on only 50M open-source data, WinTok surpasses the strong baseline UniTok by 11.2% in classification accuracy and achieves a competitive reconstruction rFID of 0.41, despite using substantially less training data. Code is released at https://github.com/markywg/WinTok.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes WinTok, a hybrid visual tokenizer that augments standard pixel tokens with a small set of learnable semantic tokens. An asymmetric distillation loss transfers discriminative knowledge from any pretrained visual foundation model into the semantic tokens while the pixel tokens continue to optimize reconstruction. The design is claimed to eliminate cross-task interference without the cost of separate tokenizers. Experiments on 10 benchmarks, trained on 50 M open-source images, report an 11.2 % gain in classification accuracy over UniTok and a competitive rFID of 0.41, with code released.
Significance. If the reported gains prove robust, the work supplies a lightweight, single-pass route to joint understanding and generation that avoids the parameter and compute overhead of dual-tokenizer architectures. The explicit use of transferable semantic tokens and the open release of code and training data constitute concrete strengths for reproducibility and downstream adoption in unified multimodal models.
major comments (2)
- [§4, Table 2] §4 (Experiments) and Table 2: the central claim of consistent cross-task improvement rests on comparisons to UniTok, yet the manuscript provides no statistical significance tests, no repeated runs with different seeds, and no explicit statement of the train/validation splits used for the 50 M image corpus. These omissions make it impossible to judge whether the 11.2 % classification lift is load-bearing or sensitive to implementation details.
- [§3.2] §3.2 (Asymmetric Token Distillation): the description of the distillation objective does not specify the weighting hyper-parameter between the semantic guidance loss and the pixel reconstruction loss, nor does it report an ablation on this trade-off. Because the paper’s main thesis is that the two objectives can be decoupled without interference, the absence of this control directly affects the credibility of the win-win claim.
minor comments (2)
- [Figure 3] Figure 3: the legend and axis labels are too small to read at print size; please enlarge or split into two panels.
- [§2] §2 (Related Work): the discussion of prior hybrid tokenizers omits the recent work on semantic-pixel disentanglement in [citation needed]; a brief comparison would help situate the contribution.
Simulated Author's Rebuttal
We are grateful to the referee for providing detailed and insightful feedback. Below we respond to each major comment and indicate the changes we plan to make in the revised manuscript.
read point-by-point responses
-
Referee: [§4, Table 2] §4 (Experiments) and Table 2: the central claim of consistent cross-task improvement rests on comparisons to UniTok, yet the manuscript provides no statistical significance tests, no repeated runs with different seeds, and no explicit statement of the train/validation splits used for the 50 M image corpus. These omissions make it impossible to judge whether the 11.2 % classification lift is load-bearing or sensitive to implementation details.
Authors: We agree that additional statistical analysis would be beneficial. However, performing multiple full training runs on 50M images is computationally prohibitive at this scale. Instead, we have added a note in the revised manuscript emphasizing the consistency of improvements across the 10 diverse benchmarks as evidence of robustness. We have also explicitly described the composition and splits of the 50M image corpus in Section 4.1, clarifying that it uses the standard training partitions from the source datasets (ImageNet-21K, LAION subset, etc.) without a held-out validation set for the tokenizer pretraining stage. revision: partial
-
Referee: [§3.2] §3.2 (Asymmetric Token Distillation): the description of the distillation objective does not specify the weighting hyper-parameter between the semantic guidance loss and the pixel reconstruction loss, nor does it report an ablation on this trade-off. Because the paper’s main thesis is that the two objectives can be decoupled without interference, the absence of this control directly affects the credibility of the win-win claim.
Authors: We thank the referee for noting this omission. The distillation objective is formulated as L_total = L_pixel + λ * L_semantic, with λ set to 0.1 in our experiments. This weighting was determined through initial tuning to achieve the reported balance between reconstruction and understanding. We have now included this hyper-parameter value and its justification in Section 3.2. Furthermore, we have added an ablation study on the effect of λ in the supplementary material, demonstrating that the hybrid design yields improvements over a range of λ values, supporting the claim of minimal cross-task interference. revision: yes
- Lack of multiple repeated runs with different seeds due to computational constraints of training on 50M images.
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper proposes an empirical hybrid tokenizer architecture that decouples pixel reconstruction from semantic understanding via learnable semantic tokens and asymmetric distillation from an external foundation model. All performance claims (e.g., +11.2% classification accuracy over UniTok, rFID 0.41) are validated on held-out benchmarks using 50M open-source images rather than reducing to quantities defined by internal fitted parameters or self-referential equations. No load-bearing step equates a prediction to its own input by construction, and the method does not rely on self-citation chains for its core justification.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of semantic tokens
axioms (1)
- domain assumption Pretrained visual foundation models supply reliable semantic embeddings suitable for distillation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WinTok supplements pixel tokens with a set of learnable semantic tokens... asymmetric token distillation mechanism... guided by pretrained semantic embeddings from any visual foundation model
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified encoder... pixel tokens for visual generation... learnable tokens for visual understanding
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems35, 23716– 23736 (2022) 4
Alayrac,J.B.,Donahue,J.,Luc,P.,Miech,A.,Barr,I.,Hasson,Y.,Lenc,K.,Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022) 4
work page 2022
-
[2]
In: Forty-second International Conference on Machine Learning (2025) 4, 13
Bachmann, R., Allardice, J., Mizrahi, D., Fini, E., Kar, O.F., Amirloo, E., El- Nouby, A., Zamir, A., Dehghan, A.: Flextok: Resampling images into 1d token sequences of flexible length. In: Forty-second International Conference on Machine Learning (2025) 4, 13
work page 2025
-
[3]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2411.16681 (2024) 4
Bai, Z., Gao, J., Gao, Z., Wang, P., Zhang, Z., He, T., Shou, M.Z.: Factorized visual tokenization and generation. arXiv preprint arXiv:2411.16681 (2024) 4
-
[6]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y., Léonard, N., Courville, A.: Estimating or propagating gradi- ents through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013) 8
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[7]
Betker, J., Goh, G., Jing, L., Brooks, T., Wang, J., Li, L., Ouyang, L., Zhuang, J., Lee, J., Guo, Y., et al.: Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf2(3), 8 (2023) 10
work page 2023
-
[8]
VFM-VAE: Vision Foundation Models Can Be Good Tokenizers for Latent Diffusion Models
Bi, T., Zhang, X., Lu, Y., Zheng, N.: Vision foundation models can be good tokenizers for latent diffusion models. arXiv preprint arXiv:2510.18457 (2025) 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Advances in neural information processing systems33, 1877–1901 (2020) 1
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few- shot learners. Advances in neural information processing systems33, 1877–1901 (2020) 1
work page 1901
-
[10]
Byeon, M., Park, B., Kim, H., Lee, S., Baek, W., Kim, S.: Coyo-700m: Image-text pair dataset.https://github.com/kakaobrain/coyo-dataset(2022) 9, 1
work page 2022
-
[11]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Cai, H., Cao, S., Du, R., Gao, P., Hoi, S., Hou, Z., Huang, S., Jiang, D., Jin, X., Li, L., et al.: Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699 (2025) 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Chang,H.,Zhang,H.,Jiang,L.,Liu,C.,Freeman,W.T.:Maskgit:Maskedgenera- tiveimagetransformer.In:ProceedingsoftheIEEE/CVFconferenceoncomputer vision and pattern recognition. pp. 11315–11325 (2022) 3
work page 2022
-
[13]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Changpinyo, S., Sharma, P., Ding, N., Soricut, R.: Conceptual 12m: Pushing web- scale image-text pre-training to recognize long-tail visual concepts. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3558–3568 (2021) 9, 1
work page 2021
-
[14]
arXiv preprint arXiv:2509.25162 (2025) 4
Chen,B.,Bi,S.,Tan,H.,Zhang,H.,Zhang,T.,Li,Z.,Xiong,Y.,Zhang,J.,Zhang, K.: Aligning visual foundation encoders to tokenizers for diffusion models. arXiv preprint arXiv:2509.25162 (2025) 4
-
[15]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al.: Blip3-o: A family of fully open unified multimodal models- architecture, training and dataset. arXiv preprint arXiv:2505.09568 (2025) 9, 1 WinTok 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
In: European Conference on Computer Vision
Chen, J., Ge, C., Xie, E., Wu, Y., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., Li, Z.: Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text- to-image generation. In: European Conference on Computer Vision. pp. 74–91. Springer (2024) 10
work page 2024
-
[17]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., et al.: Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:2310.00426 (2023) 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
In: Eu- ropean Conference on Computer Vision
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., Lin, D.: Sharegpt4v: Improving large multi-modal models with better captions. In: Eu- ropean Conference on Computer Vision. pp. 370–387. Springer (2024) 9
work page 2024
-
[19]
In: The Eleventh International Conference on Learning Representations (2023) 1
Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A., Padlewski, P., Salz, D., Goodman, S., Grycner, A., Mustafa, B., Beyer, L., et al.: Pali: A jointly-scaled multilingual language-image model. In: The Eleventh International Conference on Learning Representations (2023) 1
work page 2023
-
[20]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025) 2, 4, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024) 3
work page 2024
-
[23]
arXiv preprint arXiv:2503.06764 (2025) 4, 7, 9, 10, 1
Chen, Z., Wang, C., Chen, X., Xu, H., Huang, R., Zhou, J., Han, J., Xu, H., Liang, X.: Semhitok: A unified image tokenizer via semantic-guided hier- archical codebook for multimodal understanding and generation. arXiv preprint arXiv:2503.06764 (2025) 4, 7, 9, 10, 1
-
[24]
Advances in neural information processing systems36, 49250–49267 (2023) 9
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruc- tion tuning. Advances in neural information processing systems36, 49250–49267 (2023) 9
work page 2023
-
[25]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025) 4, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009) 3, 5, 9, 1
work page 2009
-
[27]
In: The Ninth Interna- tional Conference on Learning Representations (2021) 4, 5
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: The Ninth Interna- tional Conference on Learning Representations (2021) 4, 5
work page 2021
-
[28]
arXiv preprint arXiv:2511.23386 (2025) 4, 7, 9
Du, S., Guo, J., Li, B., Cui, S., Xu, Z., Luo, Y., Wei, Y., Gai, K., Wang, X., Wu, K., et al.: Vqrae: Representation quantization autoencoders for multimodal understanding, generation and reconstruction. arXiv preprint arXiv:2511.23386 (2025) 4, 7, 9
-
[29]
In: Forty-first international conference on machine learning (2024) 7, 10 10 Y
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz,D.,Sauer,A.,Boesel,F.,etal.:Scalingrectifiedflowtransformersforhigh- resolution image synthesis. In: Forty-first international conference on machine learning (2024) 7, 10 10 Y. Guo et al
work page 2024
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution im- age synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021) 2, 3, 4
work page 2021
-
[31]
arXiv preprint arXiv:2411.15296 , year=
Fu, C., Zhang, Y.F., Yin, S., Li, B., Fang, X., Zhao, S., Duan, H., Sun, X., Liu, Z., Wang, L., et al.: Mme-survey: A comprehensive survey on evaluation of multimodal llms. arXiv preprint arXiv:2411.15296 (2024) 9
-
[32]
Advances in Neural Information Processing Systems36, 27092–27112 (2023) 9, 1
Gadre, S.Y., Ilharco, G., Fang, A., Hayase, J., Smyrnis, G., Nguyen, T., Marten, R., Wortsman, M., Ghosh, D., Zhang, J., et al.: Datacomp: In search of the next generation of multimodal datasets. Advances in Neural Information Processing Systems36, 27092–27112 (2023) 9, 1
work page 2023
-
[33]
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Ge, Y., Zhao, S., Zhu, J., Ge, Y., Yi, K., Song, L., Li, C., Ding, X., Shan, Y.: Seed- x: Multimodal models with unified multi-granularity comprehension and genera- tion. arXiv preprint arXiv:2404.14396 (2024) 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Advances in Neural Information Processing Systems36, 52132–52152 (2023) 9, 12
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023) 9, 12
work page 2023
-
[35]
IEEE Trans- actions on Pattern Analysis and Machine Intelligence46(12), 9052–9071 (2024) 4
Gui, J., Chen, T., Zhang, J., Cao, Q., Sun, Z., Luo, H., Tao, D.: A survey on self-supervised learning: Algorithms, applications, and future trends. IEEE Trans- actions on Pattern Analysis and Machine Intelligence46(12), 9052–9071 (2024) 4
work page 2024
-
[36]
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalablevisionlearners.In:ProceedingsoftheIEEE/CVFconferenceoncomputer vision and pattern recognition. pp. 16000–16009 (2022) 4
work page 2022
-
[37]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., Yu, G.: Ella: Equip diffusion mod- els with llm for enhanced semantic alignment. arXiv preprint arXiv:2403.05135 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019) 9, 12
work page 2019
-
[39]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
arXiv preprint arXiv:2507.07997 (2025) 4, 7
Jia, M., Yin, W., Hu, X., Guo, J., Guo, X., Zhang, Q., Long, X.X., Tan, P.: Mgvq: Could vq-vae beat vae? a generalizable tokenizer with multi-group quantization. arXiv preprint arXiv:2507.07997 (2025) 4, 7
-
[41]
In: The Twelfth International Conference on Learning Representations (2024) 9
Jin, Y., Xu, K., Chen, L., Liao, C., Tan, J., Huang, Q., CHEN, B., Song, C., ZHANG, D., Ou, W., et al.: Unified language-vision pretraining in llm with dy- namic discrete visual tokenization. In: The Twelfth International Conference on Learning Representations (2024) 9
work page 2024
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019) 7
work page 2019
-
[43]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013) 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[44]
Foundations and Trends®in Machine Learning12(4), 307–392 (2019) 3
Kingma, D.P., Welling, M., et al.: An introduction to variational autoencoders. Foundations and Trends®in Machine Learning12(4), 307–392 (2019) 3
work page 2019
-
[45]
International journal of computer vision128(7), 1956–1981 (2020) 1 WinTok 11
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Kamali, S., Popov, S., Malloci, M., Kolesnikov, A., et al.: The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision128(7), 1956–1981 (2020) 1 WinTok 11
work page 1956
-
[46]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024) 7
work page 2024
-
[47]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025) 9
work page 2025
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lee, D., Kim, C., Kim, S., Cho, M., Han, W.S.: Autoregressive image genera- tion using residual quantization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11523–11532 (2022) 8
work page 2022
-
[49]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 3
work page 2023
-
[51]
Li, X., Qiu, K., Chen, H., Kuen, J., Gu, J., Raj, B., Lin, Z.: Imagefolder: Autore- gressive image generation with folded tokens. arXiv preprint arXiv:2410.01756 (2024) 4, 13
-
[52]
arXiv preprint arXiv:2509.16197 (2025) 4
Li, Y., Qian, R., Pan, B., Zhang, H., Huang, H., Zhang, B., Tong, J., You, H., Du, X., Gan, Z., et al.: Manzano: A simple and scalable unified multimodal model with a hybrid vision tokenizer. arXiv preprint arXiv:2509.16197 (2025) 4
-
[53]
In: Proceedings of the 2023 Confer- ence on Empirical Methods in Natural Language Processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hallucination in large vision-language models. In: Proceedings of the 2023 Confer- ence on Empirical Methods in Natural Language Processing. pp. 292–305 (2023) 3, 9, 12
work page 2023
-
[54]
Li,Z.,Zhang,J.,Lin,Q.,Xiong,J.,Long,Y.,Deng,X.,Zhang,Y.,Liu,X.,Huang, M., Xiao, Z., et al.: Hunyuan-dit: A powerful multi-resolution diffusion trans- former with fine-grained chinese understanding. arXiv preprint arXiv:2405.08748 (2024) 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
arXiv preprint arXiv:2505.05422 (2025) 2, 4, 7, 9, 1
Lin, H., Wang, T., Ge, Y., Ge, Y., Lu, Z., Wei, Y., Zhang, Q., Sun, Z., Shan, Y.: Toklip: Marry visual tokens to clip for multimodal comprehension and generation. arXiv preprint arXiv:2505.05422 (2025) 2, 4, 7, 9, 1
-
[56]
In: European confer- ence on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European confer- ence on computer vision. pp. 740–755. Springer (2014) 9
work page 2014
-
[57]
World Model on Million-Length Video And Language With Blockwise RingAttention
Liu, H., Yan, W., Zaharia, M., Abbeel, P.: World model on million-length video and language with blockwise ringattention. arXiv preprint arXiv:2402.08268 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu,H.,Li,C.,Li,Y.,Lee,Y.J.:Improvedbaselineswithvisualinstructiontuning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024) 2, 3, 4, 9
work page 2024
-
[59]
Advances in neural information processing systems36, 34892–34916 (2023) 2, 3, 4
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 2, 3, 4
work page 2023
-
[60]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024) 9, 12
work page 2024
- [61]
-
[62]
Ma, C., Jiang, Y., Wu, J., Yang, J., Yu, X., Yuan, Z., Peng, B., Qi, X.: Uni- tok: A unified tokenizer for visual generation and understanding. arXiv preprint arXiv:2502.20321 (2025) 2, 3, 4, 5, 7, 8, 9, 10, 11, 12, 14 12 Y. Guo et al
-
[63]
In: European Conference on Computer Vision
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: Sit: Exploring flow and diffusion-based generative models with scalable inter- polant transformers. In: European Conference on Computer Vision. pp. 23–40. Springer (2024) 3
work page 2024
-
[64]
Journal of machine learning research9(11) (2008) 14
Van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research9(11) (2008) 14
work page 2008
-
[65]
Transactions on Machine Learning Research (2023) 4, 7, 13, 1, 2
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research (2023) 4, 7, 13, 1, 2
work page 2023
-
[66]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 3
work page 2023
-
[67]
In: The Twelfth International Conference on Learning Representations (2024) 7, 10
Podell,D.,English,Z.,Lacey,K.,Blattmann,A.,Dockhorn,T.,Müller,J.,Penna, J.,Rombach,R.:Sdxl:Improvinglatentdiffusionmodelsforhigh-resolutionimage synthesis. In: The Twelfth International Conference on Learning Representations (2024) 7, 10
work page 2024
-
[68]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qu, L., Zhang, H., Liu, Y., Wang, X., Jiang, Y., Gao, Y., Ye, H., Du, D.K., Yuan, Z., Wu, X.: Tokenflow: Unified image tokenizer for multimodal understanding and generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2545–2555 (2025) 2, 4, 5, 7, 8, 9, 10, 11
work page 2025
-
[69]
In: International conference on machine learning
Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 2, 3, 4, 7, 10, 13, 1
work page 2021
-
[70]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 3, 7, 10
work page 2022
-
[71]
Advances in neural information processing systems35, 25278–25294 (2022) 9, 1
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022) 9, 1
work page 2022
-
[72]
Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2556–2565 (2018) 9, 1
work page 2018
-
[73]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards vqa models that can read. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8317– 8326 (2019) 9, 12
work page 2019
-
[74]
arXiv preprint arXiv:2406.10328 (2024) 9
Singla, V., Yue, K., Paul, S., Shirkavand, R., Jayawardhana, M., Ganjdanesh, A., Huang, H., Bhatele, A., Somepalli, G., Goldstein, T.: From pixels to prose: A large dataset of dense image captions. arXiv preprint arXiv:2406.10328 (2024) 9
-
[75]
DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
Song, W., Wang, Y., Song, Z., Li, Y., Sun, H., Chen, W., Zhou, Z., Xu, J., Wang, J., Yu, K.: Dualtoken: Towards unifying visual understanding and generation with dual visual vocabularies. arXiv preprint arXiv:2503.14324 (2025) 2, 3, 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024) 2, 3, 5, 7, 8, 10, 11, 12 WinTok 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
In: The Twelfth International Conference on Learning Representations (2024) 1
Sun, Q., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, Y., Gao, H., Liu, J., Huang, T., Wang, X.: Emu: Generative pretraining in multimodality. In: The Twelfth International Conference on Learning Representations (2024) 1
work page 2024
-
[78]
Tang,H.,Xie,C.,Bao,X.,Weng,T.,Li,P.,Zheng,Y.,Wang,L.:Unilip:Adapting clip for unified multimodal understanding, generation and editing. arXiv preprint arXiv:2507.23278 (2025) 2, 3, 4, 7
-
[79]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team, C.: Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818 (2024) 1, 10, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.