Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
Pith reviewed 2026-05-20 10:52 UTC · model grok-4.3
The pith
MIGA uses two-stage noise alignment and dual frame consistency to let foundation video models generate arbitrarily long coherent videos without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
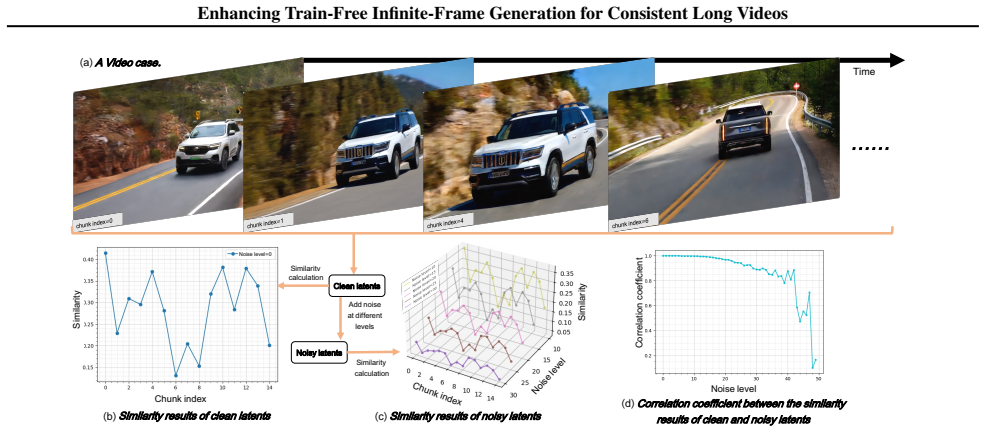
MIGA mitigates the training-inference gap by reducing excessive noise span through a two-stage alignment mechanism. It then applies a dual consistency enhancement in which self-reflection corrects early high-noise frames and long-range guidance from later low-noise frames steers the generation process, jointly raising temporal consistency and yielding state-of-the-art results on VBench and NarrLV.
What carries the argument
The two-stage alignment mechanism that reduces the noise span presented to the model, combined with the dual consistency enhancement of self-reflection on early frames and long-range guidance from later frames.
If this is right
- Foundation video models can generate videos of unlimited length while using constant memory.
- Temporal consistency holds across extended sequences without additional training.
- The approach delivers higher scores than prior train-free methods on standard long-video benchmarks.
- Pretrained models become directly usable for applications needing sustained frame-to-frame coherence.
Where Pith is reading between the lines
- Noise-range alignment strategies could transfer to other autoregressive tasks such as long audio or text generation where training contexts are short.
- The combination of local self-correction and global guidance might generalize to hybrid control methods in other generative domains.
- Applying the same alignment steps to newer base models would test how dependent the gains are on the underlying architecture.
Load-bearing premise
The assumption that the two-stage alignment and dual consistency mechanisms will reliably bridge the train-inference mismatch without introducing new inconsistencies or artifacts.
What would settle it
Running MIGA and baseline methods such as FIFO-diffusion on the same long-sequence prompts and checking whether MIGA's temporal consistency scores on VBench stay measurably higher across repeated trials would confirm or refute the claimed improvement.
Figures





read the original abstract
Without incurring significant computational overhead, train-free long video generation aims to enable foundation video generation models to produce longer videos. Frame-level autoregressive frameworks, e.g., FIFO-diffusion, offer the advantage of generating infinitely long videos with constant memory consumption. However, the mismatch between training and inference, coupled with the challenge of maintaining long-term consistency, limits the effective utilization of foundation models. To mitigate these concerns, we propose \textbf{MIGA}, a novel infinite-frame long video generation method. Firstly, we propose an effective two-stage alignment mechanism that mitigates the training-inference gap by reducing the excessive noise span fed to the model. We then introduce an innovative dual consistency enhancement mechanism, where the self-reflection approach corrects early high-noise frames and the long-range frame guidance approach leverages later low-noise frames with broad coverage to steer generation, jointly improving temporal consistency. Extensive experiments on VBench and NarrLV demonstrate the state-of-the-art performance of MIGA. Our project page is available at https://xiaokunfeng.github.io/miga_homepage/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MIGA, a novel method for train-free infinite-frame long video generation. It addresses the training-inference mismatch with a two-stage alignment mechanism that reduces excessive noise span, and improves temporal consistency through a dual consistency enhancement mechanism involving self-reflection on early high-noise frames and long-range guidance from later low-noise frames. Experiments on VBench and NarrLV show state-of-the-art performance.
Significance. This work has the potential to enable more consistent and longer video generations using existing foundation models without additional training, which is significant for applications requiring extended video content. The constant memory consumption for infinite frames is a key strength if the consistency mechanisms can be implemented without compromising the autoregressive nature.
major comments (2)
- [Dual Consistency Enhancement Mechanism] The long-range frame guidance uses later low-noise frames with broad coverage to steer generation. However, in an autoregressive generation process, later frames are not available when generating earlier ones. The paper needs to clarify how this is achieved without lookahead, buffering that increases memory, or a second pass, as this is critical to maintaining the constant-memory infinite-frame claim.
- [Experimental Results] While SOTA performance is claimed on VBench and NarrLV, the manuscript text does not provide specific quantitative results, baseline comparisons, or ablation studies. Including these details is necessary to substantiate the central claims about improved consistency and performance.
minor comments (1)
- [Abstract] Consider adding a sentence on the specific improvements observed to give readers a quick sense of the gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of MIGA to enable consistent infinite-frame video generation without training. We address the major comments point by point below and will update the manuscript to improve clarity and substantiation of results.
read point-by-point responses
-
Referee: [Dual Consistency Enhancement Mechanism] The long-range frame guidance uses later low-noise frames with broad coverage to steer generation. However, in an autoregressive generation process, later frames are not available when generating earlier ones. The paper needs to clarify how this is achieved without lookahead, buffering that increases memory, or a second pass, as this is critical to maintaining the constant-memory infinite-frame claim.
Authors: We thank the referee for highlighting this critical point. The long-range frame guidance operates strictly within the autoregressive pipeline by drawing on a fixed-size buffer of the most recently generated frames (which have received more denoising iterations and thus exhibit lower noise levels). These serve as reference frames with broad temporal coverage for the current frame being denoised. No future frames are accessed, no second pass is performed, and memory remains constant because the buffer size is fixed and independent of video length. We will revise the method description and add a detailed figure with pseudocode to explicitly demonstrate this implementation and reaffirm the constant-memory property. revision: yes
-
Referee: [Experimental Results] While SOTA performance is claimed on VBench and NarrLV, the manuscript text does not provide specific quantitative results, baseline comparisons, or ablation studies. Including these details is necessary to substantiate the central claims about improved consistency and performance.
Authors: We appreciate the referee's emphasis on clear evidence. The current manuscript contains quantitative tables in the experiments section comparing MIGA against baselines such as FIFO-Diffusion on VBench and NarrLV, along with ablations isolating the two-stage alignment and dual consistency components. To address the concern that these may not be sufficiently prominent, we will expand the main text with additional metric breakdowns, more explicit baseline numbers, and further ablation results in the revised version. revision: partial
Circularity Check
No circularity: method proposes independent mechanisms on foundation models
full rationale
The paper describes a two-stage alignment to reduce noise span and a dual consistency mechanism (self-reflection on early frames plus long-range guidance from later frames) as new algorithmic contributions. No equations, fitted parameters, or derivations are presented that reduce by construction to the inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the abstract or method outline. The approach is built atop existing video foundation models rather than re-deriving results from its own fitted values or prior self-referential claims. This is the common case of an honest engineering proposal with no detectable circularity in its derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation video diffusion models can be adapted for autoregressive infinite-frame generation by adjusting noise input spans and adding consistency corrections.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage training-inference alignment mechanism that mitigates the training-inference gap by reducing the excessive noise span
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual consistency enhancement mechanism... self-reflection approach corrects early high-noise frames and the long-range frame guidance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., and Shou, M. Z. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Bansal, H., Lin, Z., Xie, T., Zong, Z., Yarom, M., Bitton, Y ., Jiang, C., Sun, Y ., Chang, K.-W., and Grover, A. 9 Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520,
work page internal anchor Pith review arXiv
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2508.21058 (2025) 3
Cai, S., Yang, C., Zhang, L., Guo, Y ., Xiao, J., Yang, Z., Xu, Y ., Yang, Z., Yuille, A., Guibas, L., et al. Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058,
-
[6]
Chen, B., Mart ´ı Mons´o, D., Du, Y ., Simchowitz, M., Tedrake, R., and Sitzmann, V . Diffusion forcing: Next- token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081– 24125, 2024a. Chen, C., Hu, S., Zhu, J., Wu, M., Chen, J., Li, Y ., Huang, N., Fang, C., Wu, J., Chu, X., et al. Taming prefer- ence mode ...
-
[7]
D., Zheng, S., Zheng, J., Lee, L.- H., Kim, T.-H., Hong, C
Cho, J., Puspitasari, F. D., Zheng, S., Zheng, J., Lee, L.- H., Kim, T.-H., Hong, C. S., and Zhang, C. Sora as an agi world model? a complete survey on text-to-video generation.arXiv preprint arXiv:2403.05131,
-
[8]
Chu, Z., Zhang, L., Sun, Y ., Xue, S., Wang, Z., Qin, Z., and Ren, K. Sora detector: A unified hallucination de- tection for large text-to-video models.arXiv preprint arXiv:2405.04180,
-
[9]
Autoregressive Video Generation without Vector Quantization
Deng, H., Pan, T., Diao, H., Luo, Z., Cui, Y ., Lu, H., Shan, S., Qi, Y ., and Wang, X. Autoregressive video generation without vector quantization.arXiv preprint arXiv:2412.14169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Feng, X., Hu, S., Li, X., Zhang, D., Wu, M., Zhang, J., Chen, X., and Huang, K. Atctrack: Aligning target- context cues with dynamic target states for robust vision- language tracking. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pp. 19850– 19861, 2025a. Feng, X., Yu, H., Wu, M., Hu, S., Chen, J., Zhu, C., Wu, J., Chu, X., ...
-
[11]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., and Shechtman, E. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
How Far is Video Generation from World Model: A Physical Law Perspective
Kang, B., Yue, Y ., Lu, R., Lin, Z., Zhao, Y ., Wang, K., Huang, G., and Feng, J. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385,
work page internal anchor Pith review arXiv
-
[14]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al. Hunyuan- video: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Lin, M., Wang, X., Wang, Y ., Wang, S., Dai, F., Ding, P., Wang, C., Zuo, Z., Sang, N., Huang, S., et al. Exploring the evolution of physics cognition in video generation: A survey.arXiv preprint arXiv:2503.21765,
-
[17]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Video-t1: Test-time scaling for video generation.arXiv preprint arXiv:2503.18942, 2025a
Liu, F., Wang, H., Cai, Y ., Zhang, K., Zhan, X., and Duan, Y . Video-t1: Test-time scaling for video generation.arXiv preprint arXiv:2503.18942, 2025a. Liu, Y ., Ren, Y ., Artola, A., Hu, Y ., Cun, X., Zhao, X., Zhao, A., Chan, R. H., Zhang, S., Liu, R., et al. Pusa v1. 0: Surpassing wan-i2v with $500 training cost by vectorized timestep adaptation.arXiv...
-
[19]
Lu, Y ., Zeng, Y ., Li, H., Ouyang, H., Wang, Q., Cheng, K. L., Zhu, J., Cao, H., Zhang, Z., Zhu, X., et al. Reward forcing: Efficient streaming video generation with re- warded distribution matching distillation.arXiv preprint arXiv:2512.04678,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Ma, N., Tong, S., Jia, H., Hu, H., Su, Y .-C., Zhang, M., Yang, X., Li, Y ., Jaakkola, T., Jia, X., et al. Inference-time scaling for diffusion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732,
work page internal anchor Pith review arXiv
-
[21]
arXiv preprint arXiv:2310.15169 , year=
Qiu, H., Xia, M., Zhang, Y ., He, Y ., Wang, X., Shan, Y ., and Liu, Z. Freenoise: Tuning-free longer video diffusion via noise rescheduling.arXiv preprint arXiv:2310.15169,
-
[22]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
MAGI-1: Autoregressive Video Generation at Scale
Teng, H., Jia, H., Sun, L., Li, L., Li, M., Tang, M., Han, S., Zhang, T., Zhang, W., Luo, W., et al. Magi-1: Au- toregressive video generation at scale.arXiv preprint arXiv:2505.13211,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Wang, F.-Y ., Chen, W., Song, G., Ye, H.-J., Liu, Y ., and Li, H. Gen-l-video: Multi-text to long video generation via temporal co-denoising.arXiv preprint arXiv:2305.18264,
-
[26]
Waseem, F. and Shahzad, M. Video is worth a thousand im- ages: Exploring the latest trends in long video generation. arXiv preprint arXiv:2412.18688,
-
[27]
Wu, M., Zhu, J., Feng, X., Chen, C., Zhu, C., Song, B., Mao, F., Wu, J., Chu, X., and Huang, K. Imagery- search: Adaptive test-time search for video generation beyond semantic dependency constraints.arXiv preprint arXiv:2510.14847,
-
[28]
Captain cinema: Towards short movie generation.arXiv preprint arXiv:2507.18634,
Xiao, J., Yang, C., Zhang, L., Cai, S., Zhao, Y ., Guo, Y ., Wetzstein, G., Agrawala, M., Yuille, A., and Jiang, L. Captain cinema: Towards short movie generation.arXiv preprint arXiv:2507.18634,
-
[29]
Yang, H., Tang, F., Hu, M., Yin, Q., Li, Y ., Liu, Y ., Peng, Z., Gao, P., He, J., Ge, Z., et al. Scalingnoise: Scaling inference-time search for generating infinite videos.arXiv preprint arXiv:2503.16400, 2025a. Yang, S., Huang, W., Chu, R., Xiao, Y ., Zhao, Y ., Wang, X., Li, M., Xie, E., Chen, Y ., Lu, Y ., et al. Longlive: Real- time interactive long ...
- [30]
-
[31]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Zhang, Q., Lyu, F., Sun, Z., Wang, L., Zhang, W., Hua, W., Wu, H., Guo, Z., Wang, Y ., Muennighoff, N., et al. A survey on test-time scaling in large language mod- els: What, how, where, and how well?arXiv preprint arXiv:2503.24235,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Zhao, M., He, G., Chen, Y ., Zhu, H., Li, C., and Zhu, J. Riflex: A free lunch for length extrapolation in video diffusion transformers.arXiv preprint arXiv:2502.15894,
-
[33]
uses the initial latents to initialize the last f0 queue latents; the sampler (Ho et al., 2020; Lipman et al.,
work page 2020
-
[34]
Analysis of Framework Unification In Sec
A.2. Analysis of Framework Unification In Sec. 3 and Sec. A.1, we present the methodology and pseudocode implementations of the proposed TTA and DCE mechanisms, respectively. It is important to emphasize that TTA and DCE are not independent modules. In this subsection, we clarify their interdependence and integrated design within the adopted frame-level a...
work page 2023
-
[35]
as its default sampler, which requires higher-order computations. Consequently, both ϵθ(·)andϕ(·)need to store and utilize information from previous steps during each operation. Discussion on the Generalizability of Our Method.The frame-level autoregressive generation framework we adopt inherently requires models to handle latents with noise levels varyin...
work page 2024
-
[36]
based on the MMDiT architecture (Esser et al., 2024). The main reason is that these models concatenate text and video features, and jointly interact with the noise timestep condition. To guide latents of different frames with distinct noise levels, it is necessary to introduce noise conditions with varying timesteps. However, since text features cannot be...
work page 2024
-
[37]
Fig. 6 illustrates the impact of varying the number of stage 2 denoising steps on model performance, highlighting the overall score metric across different settings. The detailed results for each individual metric under these settings are presented in Tab. A1. For the baseline setting (e= 1 ), we report the performance of FIFO-Diffusion on this evaluation...
work page 2023
-
[38]
Values in parentheses indicate the relative memory increase compared to VideoCrafter2
For reference, we also report the memory footprint of the foundation model (VideoCrafter2) during short-term inference, which is 9919 MiB. Values in parentheses indicate the relative memory increase compared to VideoCrafter2. The results indicate that: (i) introducing Stage 2 does not affect memory overhead across different frame counts; and (ii) memory u...
work page 2000
-
[39]
dynamically adjusts sink frames and introduces the reward signals, effectively alleviating content repetition and reduced dynamics associated with sink frames. As shown in Tab. A5, we adopt the same evaluation settings as in Sec. 4.1 to compare these train-based methods. Despite not performing large-scale training, MIGA still achieves comparable performan...
work page 2024
-
[40]
of the video generation model, or as evidence of the lack of underlying physical knowledge (Lin et al., 2025; Bansal et al., 2024). Such issues are not only specific to long video generation tasks but also represent a major challenge for the entire field of video generation (Kang et al., 2024). In future work, we aim to incorporate additional conditioning...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.