Forecasting Downstream Performance of LLMs With Proxy Metrics
Pith reviewed 2026-05-20 10:26 UTC · model grok-4.3
The pith
Proxy metrics from token statistics on expert solutions forecast LLM downstream performance more reliably than loss or compute baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
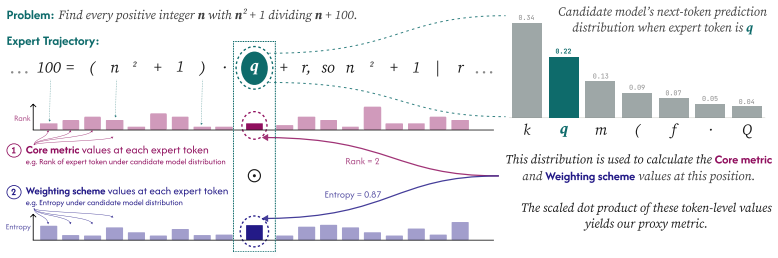
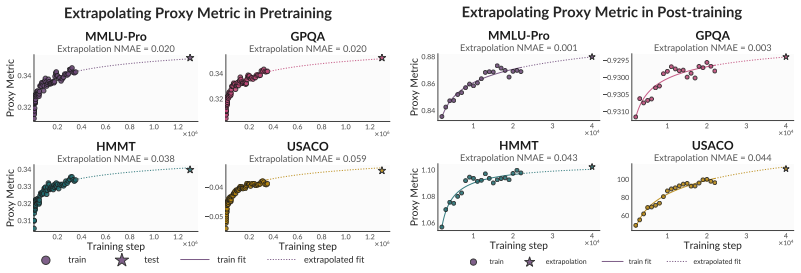
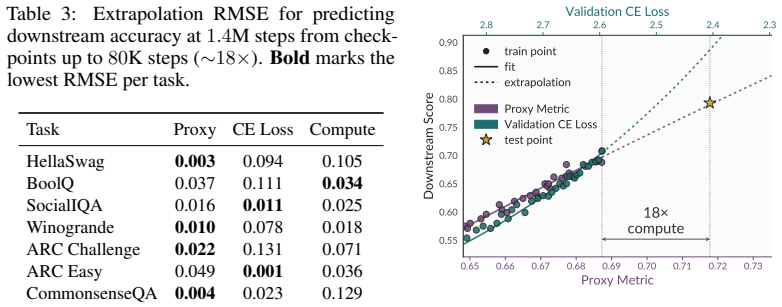
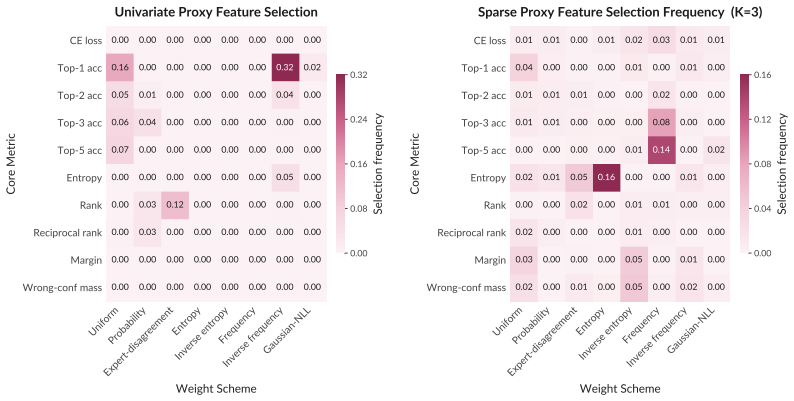
Proxy metrics built by aggregating token-level statistics such as entropy, top-k accuracy, and expert token rank from a candidate model's next-token distribution over expert-written solutions provide more accurate forecasts of downstream performance than loss- or compute-based alternatives. This holds for ranking heterogeneous reasoning models, selecting among pretraining corpora at greatly reduced cost, and extrapolating accuracy over extended training horizons.
What carries the argument
Proxy metrics formed by aggregating entropy, top-k accuracy, and expert token rank computed from next-token predictions over expert-written solutions.
If this is right
- Different model families can be ranked for reasoning capability with substantially higher correlation to actual downstream results.
- Pretraining corpora can be screened for a target model using far less compute than direct evaluation while still identifying strong candidates.
- Downstream accuracy trends can be projected over large increases in training compute with lower error than prior methods.
- Model development decisions become feasible at earlier training stages or with smaller evaluation budgets.
Where Pith is reading between the lines
- If the proxies prove stable across more domains, they could reduce reliance on full downstream benchmarks for routine model comparisons.
- The same token statistics might be adapted to forecast performance in non-language settings such as code generation or multimodal tasks.
- Layering these proxies with existing signals like loss curves could produce even tighter forecasts for very early training stages.
Load-bearing premise
Token-level statistics on expert-written solutions are representative enough of target downstream tasks that their aggregation reveals capability differences missed by loss.
What would settle it
Running the proxies on a fresh collection of models and tasks and finding Spearman correlations no higher than those from loss, or observing large errors when extrapolating across long training runs.
Figures

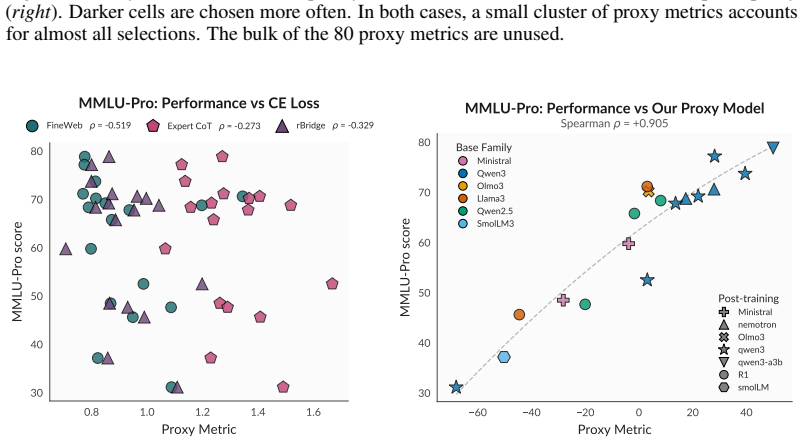
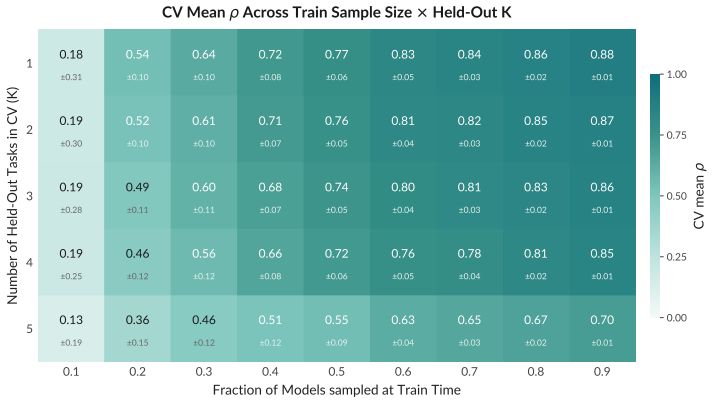
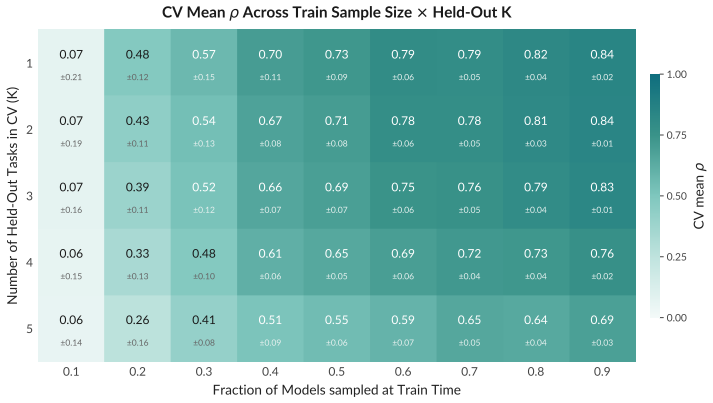
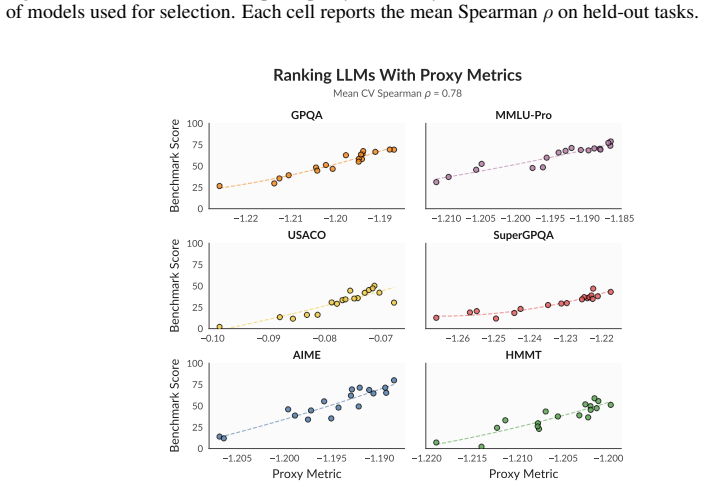






read the original abstract
Progress in language model development is often driven by comparative decisions: which architecture to adopt, which pretraining corpus to use, or which training recipe to apply. Making these decisions well requires reliable performance forecasts, yet the two commonly used signals are fundamentally limited. Cross-entropy loss is poorly aligned with downstream capabilities, and direct downstream evaluation is expensive, sparse, and often uninformative at early training stages. Instead, we propose to construct proxy metrics by aggregating token-level statistics, such as entropy, top-k accuracy, and expert token rank, from a candidate model's next token distribution over expert-written solutions. Across three settings, our proxies consistently outperform loss- and compute-based baselines: 1) For cross-family model selection, they rank a heterogeneous population of reasoning models with mean Spearman Rho = 0.81 (vs. Rho = 0.36 for cross-entropy loss); 2) For pretraining data selection, they reliably rank 25 candidate corpora for a target model at roughly $10{,}000\times$ less compute than direct evaluation, pushing the Pareto frontier beyond existing methods; and 3) for training-time forecasting, they extrapolate downstream accuracy across an $18\times$ compute horizon with roughly half the error of existing alternatives. Together, these results suggest that expert trajectories are a broadly useful source of signal for assessing model capabilities, enabling reliable performance forecasting throughout the model development life cycle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes constructing proxy metrics by aggregating token-level statistics (entropy, top-k accuracy, expert token rank) from a candidate model's next-token distribution over expert-written solutions. It evaluates these proxies across three settings, claiming they outperform loss- and compute-based baselines: mean Spearman ρ = 0.81 (vs. 0.36 for loss) for ranking heterogeneous reasoning models; reliable ranking of 25 pretraining corpora at ~10,000× lower compute than direct evaluation; and extrapolation of downstream accuracy over an 18× compute horizon with roughly half the error of alternatives.
Significance. If the empirical results hold under broader validation, the work could meaningfully advance efficient LLM development by reducing reliance on expensive downstream evaluations or unaligned loss signals. The concrete quantitative gains across model selection, data selection, and training forecasting, together with the focus on expert trajectories as an information source, represent a practical contribution that could influence workflows if the proxies prove robust beyond the reported settings.
major comments (2)
- [§3] §3 (Proxy construction): The central claim requires that the aggregated token statistics capture capability differences orthogonal to cross-entropy loss. The manuscript provides no ablation or partial-correlation analysis showing that the combination of entropy, top-k accuracy, and expert token rank supplies signal independent of loss when both are computed on the same expert solutions; without this, the reported outperformance in all three settings could reduce to distributional matching rather than genuine capability forecasting.
- [§4.1] §4.1 (Cross-family model selection): The mean Spearman ρ = 0.81 result is load-bearing for the first claim. The description does not specify the exact number of models, the precise downstream tasks used for ground-truth ranking, or any statistical significance test against the loss baseline of ρ = 0.36, making it impossible to judge whether the improvement generalizes or is tied to the particular expert-solution distribution.
minor comments (2)
- [Abstract] Abstract: The phrases 'roughly $10,000× less compute' and 'roughly half the error' would benefit from exact values, confidence intervals, or ranges to allow precise comparison with baselines.
- [§3] Notation: The aggregation function combining entropy, top-k accuracy, and expert token rank is described only in prose; an explicit equation in §3 would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to improve clarity and strengthen the claims.
read point-by-point responses
-
Referee: [§3] §3 (Proxy construction): The central claim requires that the aggregated token statistics capture capability differences orthogonal to cross-entropy loss. The manuscript provides no ablation or partial-correlation analysis showing that the combination of entropy, top-k accuracy, and expert token rank supplies signal independent of loss when both are computed on the same expert solutions; without this, the reported outperformance in all three settings could reduce to distributional matching rather than genuine capability forecasting.
Authors: We agree that an explicit analysis demonstrating signal independent of loss would better support the claim that the proxies capture capability differences beyond distributional matching. While the token-level statistics (entropy, top-k accuracy, expert token rank) are constructed to reflect properties such as uncertainty and alignment with expert choices that are not directly captured by aggregate cross-entropy loss, the manuscript does not include a partial-correlation or ablation study on the same expert solutions. We will add this analysis in the revision, including partial Spearman correlations between the proxy scores and downstream performance while controlling for loss, as well as an ablation comparing the combined proxy against loss alone. This will help substantiate that the reported gains reflect orthogonal signal. revision: yes
-
Referee: [§4.1] §4.1 (Cross-family model selection): The mean Spearman ρ = 0.81 result is load-bearing for the first claim. The description does not specify the exact number of models, the precise downstream tasks used for ground-truth ranking, or any statistical significance test against the loss baseline of ρ = 0.36, making it impossible to judge whether the improvement generalizes or is tied to the particular expert-solution distribution.
Authors: We acknowledge that the description in §4.1 omits key experimental details needed to fully evaluate the result. In the revised manuscript we will explicitly state the number of models evaluated, list the precise downstream tasks used to establish the ground-truth rankings, and report a statistical significance test (such as bootstrap resampling) comparing the proxy correlation to the loss baseline. These additions will allow readers to better assess generalizability. revision: yes
Circularity Check
No significant circularity; empirical comparisons to external baselines
full rationale
The paper constructs proxy metrics from token-level statistics (entropy, top-k accuracy, expert token rank) aggregated over expert-written solutions and evaluates them empirically against loss- and compute-based baselines in three distinct settings: cross-family model ranking, pretraining data selection, and training-time forecasting. Reported gains (Spearman rho of 0.81 vs. 0.36, 10,000x compute reduction, halved extrapolation error) are obtained via direct measurement on separate evaluations rather than any fitted parameter being renamed as a prediction or any equation reducing to its own inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing justifications for the central claims. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-written solutions provide a representative basis for computing token-level statistics that correlate with downstream task performance.
Reference graph
Works this paper leans on
-
[1]
Forty-second International Conference on Machine Learning , year=
DataDecide: How to Predict Best Pretraining Data with Small Experiments , author=. Forty-second International Conference on Machine Learning , year=
-
[2]
The Fourteenth International Conference on Learning Representations , year=
Revisiting the Scaling Properties of Downstream Metrics in Large Language Model Training , author=. The Fourteenth International Conference on Learning Representations , year=
-
[3]
The Thirteenth International Conference on Learning Representations , year=
Scaling Laws for Downstream Task Performance in Machine Translation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
Woosung Koh and Juyoung Suk and Sungjun Han and Se-Young Yun and Jay Shin , booktitle=. Predicting. 2026 , url=
work page 2026
-
[5]
Transactions on Machine Learning Research , issn=
Loss-to-Loss Prediction: Scaling Laws for All Datasets , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
work page 2025
-
[6]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Observational Scaling Laws and the Predictability of Langauge Model Performance , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[7]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Understanding Emergent Abilities of Language Models from the Loss Perspective , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[8]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Are Emergent Abilities of Large Language Models a Mirage? , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[9]
The Thirteenth International Conference on Learning Representations , year=
Language models scale reliably with over-training and on downstream tasks , author=. The Thirteenth International Conference on Learning Representations , year=
-
[10]
Why Has Predicting Downstream Capabilities of Frontier
Rylan Schaeffer and Hailey Schoelkopf and Brando Miranda and Gabriel Mukobi and Varun Madan and Adam Ibrahim and Herbie Bradley and Stella Biderman and Sanmi Koyejo , booktitle=. Why Has Predicting Downstream Capabilities of Frontier. 2025 , url=
work page 2025
-
[11]
The Art of Scaling Reinforcement Learning Compute for
Fnu Devvrit and Lovish Madaan and Rishabh Tiwari and Rachit Bansal and Sai Surya Duvvuri and Manzil Zaheer and Inderjit S Dhillon and David Brandfonbrener and Rishabh Agarwal , booktitle=. The Art of Scaling Reinforcement Learning Compute for. 2026 , url=
work page 2026
-
[12]
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
work page 2024
-
[13]
LiveCodeBench Pro: How Do Olympiad Medalists Judge
Zihan Zheng and Zerui Cheng and Zeyu Shen and Shang Zhou and Kaiyuan Liu and Hansen He and Dongruixuan Li and Stanley Wei and Hangyi Hao and Jianzhu Yao and Peiyao Sheng and Zixuan Wang and Wenhao Chai and Aleksandra Korolova and Peter Henderson and Sanjeev Arora and Pramod Viswanath and Jingbo Shang and Saining Xie , booktitle=. LiveCodeBench Pro: How Do...
work page 2025
-
[14]
First Conference on Language Modeling , year=
Can Language Models Solve Olympiad Programming? , author=. First Conference on Language Modeling , year=
-
[15]
Tejal Patwardhan and Rachel Dias and Elizabeth Proehl and Grace Kim and Michele Wang and Olivia Watkins and Simon Posada Fishman and Marwan Aljubeh and Phoebe Thacker and Laurance Fauconnet and Natalie S. Kim and Samuel Miserendino and Gildas Chabot and David Li and Patrick Chao and Michael Sharman and Alexandra Barr and Amelia Glaese and Jerry Tworek , b...
work page 2026
-
[16]
International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations (ICLR) , year=
-
[17]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
work page 2022
-
[18]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[19]
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah Goodman , booktitle=. 2022 , url=
work page 2022
-
[20]
Mislav Balunovic and Jasper Dekoninck and Ivo Petrov and Nikola Jovanovi. MathArena: Evaluating. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[21]
Large Margin Rank Boundaries for Ordinal Regression , booktitle =
Herbrich, Ralf and Graepel, Thore and Obermayer, Klaus , editor =. Large Margin Rank Boundaries for Ordinal Regression , booktitle =. 2000 , month =. doi:10.7551/mitpress/1113.003.0010 , url =
-
[22]
Advances in Neural Information Processing Systems , editor=
An empirical analysis of compute-optimal large language model training , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
work page 2022
- [23]
-
[24]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
work page 2022
-
[25]
The Eleventh International Conference on Learning Representations , year=
Broken Neural Scaling Laws , author=. The Eleventh International Conference on Learning Representations , year=
-
[26]
Advances in Neural Information Processing Systems , editor=
Beyond neural scaling laws: beating power law scaling via data pruning , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
work page 2022
-
[27]
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
work page 2022
-
[28]
International Conference on Learning Representations , year=
Uncertainty Estimation in Autoregressive Structured Prediction , author=. International Conference on Learning Representations , year=
-
[29]
The Eleventh International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[30]
Farquhar, Sebastian and Kossen, Jannik and Kuhn, Lorenz and Gal, Yarin , date =. Detecting hallucinations in large language models using semantic entropy , url =. Nature , number =. 2024 , bdsk-url-1 =. doi:10.1038/s41586-024-07421-0 , id =
-
[31]
Forty-second International Conference on Machine Learning , year=
Free Process Rewards without Process Labels , author=. Forty-second International Conference on Machine Learning , year=
- [32]
-
[33]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Scaling Data-Constrained Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[34]
Forty-second International Conference on Machine Learning , year=
A Hitchhiker's Guide to Scaling Law Estimation , author=. Forty-second International Conference on Machine Learning , year=
- [35]
-
[36]
Resolving Discrepancies in Compute-Optimal Scaling of Language Models , author=. 2nd Workshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (WANT@ICML 2024) , year=
work page 2024
-
[37]
Second Conference on Language Modeling , year=
Establishing Task Scaling Laws via Compute-Efficient Model Ladders , author=. Second Conference on Language Modeling , year=
-
[38]
Scaling Laws for Predicting Downstream Performance in
Yangyi Chen and Binxuan Huang and Yifan Gao and Zhengyang Wang and Jingfeng Yang and Heng Ji , journal=. Scaling Laws for Predicting Downstream Performance in. 2025 , url=
work page 2025
-
[39]
Lourie, Nicholas and Hu, Michael Y. and Cho, Kyunghyun. Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.877
-
[40]
Proceedings of the 40th International Conference on Machine Learning , pages =
Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[41]
Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
Tay, Yi and Dehghani, Mostafa and Abnar, Samira and Chung, Hyung and Fedus, William and Rao, Jinfeng and Narang, Sharan and Tran, Vinh and Yogatama, Dani and Metzler, Donald. Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.fin...
-
[42]
The Twelfth International Conference on Learning Representations , year=
Predicting Emergent Abilities with Infinite Resolution Evaluation , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
First Conference on Language Modeling , year=
Predicting Emergent Capabilities by Finetuning , author=. First Conference on Language Modeling , year=
-
[44]
Forty-second International Conference on Machine Learning , year=
Prasanna Mayilvahanan and Thadd. Forty-second International Conference on Machine Learning , year=
-
[45]
First Conference on Language Modeling , year=
Compression Represents Intelligence Linearly , author=. First Conference on Language Modeling , year=
-
[46]
The Thirteenth International Conference on Learning Representations , year=
What is Wrong with Perplexity for Long-context Language Modeling? , author=. The Thirteenth International Conference on Learning Representations , year=
-
[47]
The Thirteenth International Conference on Learning Representations , year=
Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[48]
Demystifying Prompts in Language Models via Perplexity Estimation
Gonen, Hila and Iyer, Srini and Blevins, Terra and Smith, Noah and Zettlemoyer, Luke. Demystifying Prompts in Language Models via Perplexity Estimation. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.679
-
[49]
The Thirteenth International Conference on Learning Representations , year=
Improving Pretraining Data Using Perplexity Correlations , author=. The Thirteenth International Conference on Learning Representations , year=
-
[50]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[51]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang. Math-Shepherd: Verify and Reinforce LLM s Step-by-step without Human Annotations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.510
-
[52]
Process Reinforcement through Implicit Rewards , author=. 2025 , eprint=
work page 2025
-
[53]
Reasoning with language model is planning with world model
Hao, Shibo and Gu, Yi and Ma, Haodi and Hong, Joshua and Wang, Zhen and Wang, Daisy and Hu, Zhiting. Reasoning with Language Model is Planning with World Model. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.507
-
[54]
Felipe Maia Polo and Lucas Weber and Leshem Choshen and Yuekai Sun and Gongjun Xu and Mikhail Yurochkin , booktitle=. tinyBenchmarks: evaluating. 2024 , url=
work page 2024
-
[55]
Anchor Points: Benchmarking Models with Much Fewer Examples
Vivek, Rajan and Ethayarajh, Kawin and Yang, Diyi and Kiela, Douwe. Anchor Points: Benchmarking Models with Much Fewer Examples. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.95
-
[56]
The Thirteenth International Conference on Learning Representations , year=
metabench - A Sparse Benchmark of Reasoning and Knowledge in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[57]
Second Conference on Language Modeling , year=
Fluid Language Model Benchmarking , author=. Second Conference on Language Modeling , year=
-
[58]
Training Trajectories of Language Models Across Scales
Xia, Mengzhou and Artetxe, Mikel and Zhou, Chunting and Lin, Xi Victoria and Pasunuru, Ramakanth and Chen, Danqi and Zettlemoyer, Luke and Stoyanov, Veselin. Training Trajectories of Language Models Across Scales. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl...
-
[59]
and Tu, Zhuowen and Bergen, Benjamin K
Chang, Tyler A. and Tu, Zhuowen and Bergen, Benjamin K. Characterizing Learning Curves During Language Model Pre-Training: Learning, Forgetting, and Stability. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00708
-
[60]
How predictable is language model benchmark performance? , author=. 2024 , eprint=
work page 2024
-
[61]
Felipe Maia Polo and Seamus Somerstep and Leshem Choshen and Yuekai Sun and Mikhail Yurochkin , booktitle=. Sloth: scaling laws for. 2026 , url=
work page 2026
-
[62]
Paloma: A Benchmark for Evaluating Language Model Fit , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[63]
The Twelfth International Conference on Learning Representations , year=
Small-scale proxies for large-scale Transformer training instabilities , author=. The Twelfth International Conference on Learning Representations , year=
-
[64]
Advances in Neural Information Processing Systems , editor=
Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
work page 2021
-
[65]
Thirty-seventh Conference on Neural Information Processing Systems , year=
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[66]
The Thirteenth International Conference on Learning Representations , year=
RegMix: Data Mixture as Regression for Language Model Pre-training , author=. The Thirteenth International Conference on Learning Representations , year=
-
[67]
Eric Zelikman and Georges Raif Harik and Yijia Shao and Varuna Jayasiri and Nick Haber and Noah Goodman , booktitle=. Quiet-. 2024 , url=
work page 2024
-
[68]
Solving math word problems with process- and outcome-based feedback , author=. 2022 , eprint=
work page 2022
-
[69]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision , author=. 2024 , eprint=
work page 2024
-
[70]
Forty-first International Conference on Machine Learning , year=
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws , author=. Forty-first International Conference on Machine Learning , year=
-
[71]
Scaling Laws Under the Microscope: Predicting Transformer Performance from Small Scale Experiments , author=. 2022 , eprint=
work page 2022
-
[72]
Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , pages =
Ganguli, Deep and Hernandez, Danny and Lovitt, Liane and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and Dassarma, Nova and Drain, Dawn and Elhage, Nelson and El Showk, Sheer and Fort, Stanislav and Hatfield-Dodds, Zac and Henighan, Tom and Johnston, Scott and Jones, Andy and Joseph, Nicholas and Kernian, Jackson and Kravec, Shauna and ...
-
[73]
Unveiling Downstream Performance Scaling of
Chengyin Xu and Kaiyuan Chen and Xiao Li and Ke Shen and Chenggang Li , booktitle=. Unveiling Downstream Performance Scaling of. 2026 , url=
work page 2026
-
[74]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Data Selection for Language Models via Importance Resampling , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[75]
Phan, Long and Gatti, Alice and Li, Nathaniel and Khoja, Adam and Kim, Ryan and Ren, Richard and Hausenloy, Jason and Zhang, Oliver and Mazeika, Mantas and Hendrycks, Dan and Han, Ziwen and Hu, Josephina and Zhang, Hugh and Zhang, Chen Bo Calvin and Shaaban, Mohamed and Ling, John and Shi, Sean and Choi, Michael and Agrawal, Anish and Chopra, Arnav and Na...
work page internal anchor Pith review doi:10.1038/s41586-025-09962-4 2026
-
[76]
Hjalmar Wijk and Tao Roa Lin and Joel Becker and Sami Jawhar and Neev Parikh and Thomas Broadley and Lawrence Chan and Michael Chen and Joshua M Clymer and Jai Dhyani and Elena Ericheva and Katharyn Garcia and Brian Goodrich and Nikola Jurkovic and Megan Kinniment and Aron Lajko and Seraphina Nix and Lucas Jun Koba Sato and William Saunders and Maksym Tar...
work page 2025
-
[77]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[78]
American Invitational Mathematics Examination (AIME) 2025 , author=
work page 2025
-
[79]
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
work page 2024
-
[80]
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.