Query-Conditioned Graph Retrieval for Contextualized LLM Reasoning in Personalized Wearable Data
Pith reviewed 2026-05-21 09:44 UTC · model grok-4.3
The pith
Organizing wearable data into personalized graphs and retrieving query-specific subgraphs lets LLMs analyze long-term sensor records more effectively than standard retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
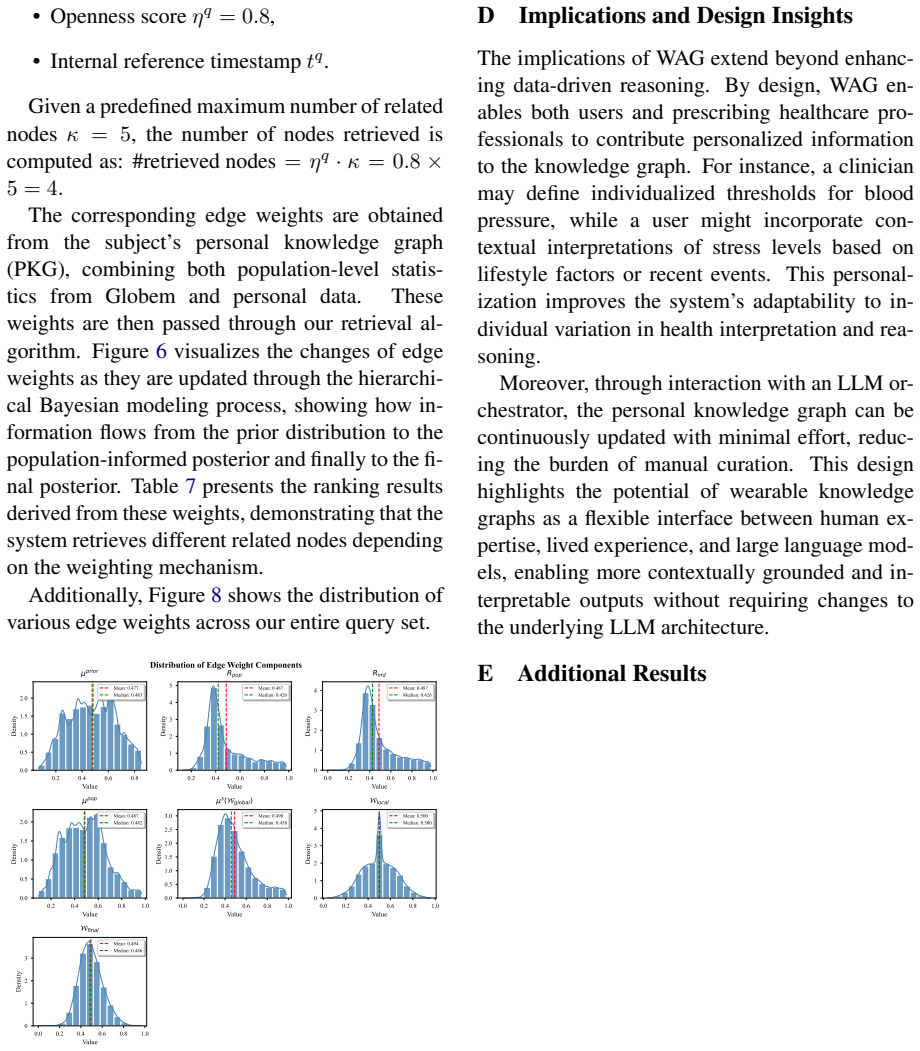
WAG organizes wearable metrics and user-specific signals into a personalized knowledge graph, then retrieves a query-conditioned subgraph that integrates global relationships captured by hierarchical Bayesian modeling of population- and individual-level patterns with local relationships reflecting short-term signal deviations. A query openness signal regulates retrieval breadth. This query-adaptive subgraph supplies context for downstream LLM generation on wearable data analysis.
What carries the argument
The query-conditioned subgraph retrieval that combines hierarchical Bayesian global patterns with local short-term deviations inside a personalized wearable knowledge graph.
If this is right
- LLMs can process extended multimodal wearable records without context overload or quality loss during generation.
- Personalized health insights become more reliable by automatically weighting both population norms and individual deviations.
- Context selection for sensor data analysis shifts from static or exhaustive inclusion to query-driven subgraph extraction.
- Downstream tasks such as activity recognition or anomaly detection gain structured, adaptive support from the graph representation.
Where Pith is reading between the lines
- The same graph-plus-query mechanism could apply to other longitudinal personal datasets such as continuous glucose monitoring or sleep logs.
- Extending the local deviation layer to handle streaming updates might allow near-real-time subgraph refresh for ongoing LLM queries.
- Graph-based conditioning may reduce the chance of LLMs fabricating details when reasoning over sparse or noisy personal sensor histories.
- Similar retrieval structures could help align LLM outputs more closely with user-specific baselines in multi-user health platforms.
Load-bearing premise
The hierarchical Bayesian modeling of population- and individual-level patterns together with local signal deviations will reliably yield a subgraph that gives the LLM sufficient unbiased context without missing key short-term or user-specific signals.
What would settle it
An evaluation set of time-sensitive queries where WAG's retrieved subgraph leads to LLM outputs that overlook documented short-term health events captured in the full raw data, resulting in win rates dropping below 50 percent against full-context baselines.
Figures






read the original abstract
Large language models (LLMs) are increasingly applied to analyzing wearable sensing data, which are long-term, multimodal, and highly personalized. A key challenge is context selection: providing insufficient context limits reasoning, while including all available data leads to inefficiency and degraded generation quality. We propose Wearable As Graph (WAG), a graph-based context retrieval framework that enables query-adaptive reasoning over wearable data with LLMs. WAG organizes wearable metrics and user-specific signals into a personalized knowledge graph, and retrieves a query-conditioned subgraph to support downstream generation. The retrieval process integrates global relationships, capturing prior knowledge and population- and individual-level patterns via hierarchical Bayesian modeling, with local relationships that reflect short-term signal deviations. A query openness signal further controls retrieval breadth. We evaluate WAG on over 10,000 data-grounded queries from real-world wearable datasets. Across LLM-based and human evaluations, WAG achieves an approximately 70% win rate over baseline and standard RAG methods, demonstrating the effectiveness of structured, query-adaptive context retrieval for LLM-driven analysis of wearable data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Wearable As Graph (WAG), a graph-based context retrieval framework for LLM reasoning over personalized wearable sensing data. Wearable metrics and user-specific signals are organized into a personalized knowledge graph; a query-conditioned subgraph is retrieved by combining hierarchical Bayesian modeling of global population- and individual-level patterns with local short-term signal deviations, with retrieval breadth controlled by a query openness signal. The central empirical claim is an approximately 70% win rate over baseline and standard RAG methods across LLM-based and human evaluations on more than 10,000 data-grounded queries from real-world wearable datasets.
Significance. If the evaluation is sound and the subgraph retrieval reliably surfaces query-relevant local deviations, the work would offer a principled, structured alternative to naive context stuffing or standard RAG for long-term multimodal personal health data. The explicit integration of hierarchical Bayesian priors with local deviations and an openness control is a clear methodological contribution that could generalize beyond wearables to other personalized time-series domains.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the reported ~70% win rate is presented without any description of the exact baselines, statistical significance tests, data splits, query sampling procedure, or controls for confounds such as query difficulty or LLM temperature. This information is load-bearing for the central claim that the query-conditioned subgraph improves downstream LLM generation quality.
- [Methods] Methods (hierarchical Bayesian modeling and retrieval): no quantitative ablation or diagnostic is supplied showing that short-term local signal deviations are retained in the retrieved subgraph when they are query-relevant. The skeptic concern is therefore live: if the openness-controlled retrieval systematically drops these deviations, the subgraph can be unbiased on average yet still omit critical user-specific signals, directly weakening the sufficiency argument for the reported win rate.
minor comments (2)
- [Abstract] Abstract: replace the vague phrase 'approximately 70% win rate' with the exact figure, confidence interval, and number of LLM vs. human judgments.
- [Methods] Notation: define the query openness signal and its functional form explicitly (e.g., as a hyperparameter or learned variable) rather than leaving it as a descriptive term.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which help strengthen the presentation of our work on WAG. We appreciate the recognition of its potential as a structured alternative for context retrieval in personalized wearable data. We address each major comment below and commit to revisions that directly respond to the concerns while preserving the core contributions of the manuscript.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the reported ~70% win rate is presented without any description of the exact baselines, statistical significance tests, data splits, query sampling procedure, or controls for confounds such as query difficulty or LLM temperature. This information is load-bearing for the central claim that the query-conditioned subgraph improves downstream LLM generation quality.
Authors: We agree that additional details are necessary to fully substantiate the central empirical claim. The current manuscript provides high-level descriptions of the evaluation protocol and baselines in the Evaluation section, but we acknowledge that explicit enumeration of all elements (specific baseline implementations, statistical tests with p-values, precise data splits and query sampling strategy, and confound controls such as query difficulty stratification and temperature settings) would improve clarity and reproducibility. In the revised manuscript we will expand the Evaluation section with these specifics, add a dedicated paragraph on statistical analysis, and include a concise summary of the evaluation protocol in the abstract. These changes will directly address the load-bearing nature of the ~70% win rate result. revision: yes
-
Referee: [Methods] Methods (hierarchical Bayesian modeling and retrieval): no quantitative ablation or diagnostic is supplied showing that short-term local signal deviations are retained in the retrieved subgraph when they are query-relevant. The skeptic concern is therefore live: if the openness-controlled retrieval systematically drops these deviations, the subgraph can be unbiased on average yet still omit critical user-specific signals, directly weakening the sufficiency argument for the reported win rate.
Authors: We recognize the validity of this concern and the importance of demonstrating retention of query-relevant local deviations. The manuscript describes the hierarchical Bayesian component for global patterns and the explicit inclusion of local short-term deviations, along with qualitative examples of retrieved subgraphs. However, we agree that a quantitative diagnostic would more rigorously address the skeptic concern about potential omission of critical signals. In the revision we will add a new ablation/diagnostic subsection that reports retention metrics (e.g., overlap with ground-truth relevant local signals or comparative retrieval performance with and without the local deviation term) specifically conditioned on query relevance. This will provide direct evidence supporting the sufficiency of the retrieved subgraphs for the observed performance gains. revision: yes
Circularity Check
No significant circularity; derivation relies on standard components
full rationale
The paper presents WAG as a graph-based retrieval method that organizes wearable data into a personalized knowledge graph and retrieves query-conditioned subgraphs by integrating hierarchical Bayesian modeling for global/individual patterns with local signal deviations, controlled by a query openness signal. The central result (approximately 70% win rate) is obtained from external LLM-based and human evaluations on over 10,000 real-world queries, not from any internal reduction, fitted parameter renamed as prediction, or self-referential definition. No equations, uniqueness theorems, or ansatzes are shown that collapse the claimed effectiveness back to the inputs by construction. The framework uses established graph and Bayesian techniques without load-bearing self-citations or renamings that would indicate circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GLOBEM dataset: multi-year datasets for longitudinal human behavior modeling generaliza- tion.Advances in neural information processing systems, pages 24655–24692. Vajira Thambawita, Steven Alexander Hicks, Hanna Borgli, Håkon Kvale Stensland, Debesh Jha, Martin Kristoffer Svensen, Svein-Arne Pettersen, Dag Jo- hansen, Håvard Dagenborg Johansen, Susann Da...
work page 2020
-
[2]
LifeSnaps, a 4-month multi-modal dataset capturing unobtrusive snapshots of our lives in the wild.Scientific Data, pages 663. Mike A Merrill, Akshay Paruchuri, Naghmeh Rezaei, Geza Kovacs, Javier Perez, Yun Liu, Erik Schenck, Nova Hammerquist, Jake Sunshine, Shyam Tailor, and others. 2024. Transforming wearable data into health insights using large langua...
-
[3]
Knowledge-Centric Hallucination Detection
Navigator: A gen-ai system for discovery of factual and predictive insights on domain-specific tabular datasets.Proceedings of the 7th Joint In- ternational Conference on Data Science & Manage- ment of Data (11th ACM IKDD CODS and 29th CO- MAD), pages 528–532. Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang. 2024. DS-Agent: Au- toma...
-
[4]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Multimodal data matters: language model pre-training over structured and unstructured elec- tronic health records.IEEE Journal of Biomedical and Health Informatics, pages 504–514. Hao Fei, Yafeng Ren, Yue Zhang, Donghong Ji, and Xiaohui Liang. 2021. Enriching contextualized lan- guage model from knowledge graph for biomedical information extraction.Briefi...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
doi:10.1162/tacl_a_00638. Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. 2022. Fedformer: Fre- quency enhanced decomposed transformer for long- term series forecasting.International conference on machine learning, pages 27268–27286. Nimeesha Chan, Felix Parker, William Bennett, Tianyi Wu, Mung Yao Jia, James Fackler, and Kimia Ghob...
-
[6]
LaMDA: Language Models for Dialog Applications
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Pro- cessing Systems, pages 46595–46623. Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, and others. 2022. Lamda: Language models for dia- log applications.arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2022
-
[7]
Evaluation Metrics in the Era of GPT-4: Re- liably Evaluating Large Language Models on Se- quence to Sequence Tasks.Proceedings of the 2023 Conference on Empirical Methods in Natu- ral Language Processing, pages 8776–8788. doi: 10.18653/v1/2023.emnlp-main.543. A Dataset and Queryset Stats A.1 Dataset IFH Affect(Labbaf et al., 2024): A longitudinal dataset...
-
[8]
These walks typically lasted 20-40 minutes with moderate intensity (average heart rate 92-159 bpm)
**Walking** (11 sessions) - This was your dominant activity, with multiple daily walks logged both as auto-detected and tracker-recorded sessions. These walks typically lasted 20-40 minutes with moderate intensity (average heart rate 92-159 bpm)
-
[9]
**Treadmill** (1 session on Novem- ber 19) - A single 26-minute vigorous session with higher intensity (average HR 154 bpm)
-
[10]
**General Workout** (1 session on November 19) - A 44-minute mixed-intensity session logged as "Workout" with strength training characteristics (lower step count but elevated HR zones). Key observations: - Walking accounted for 85% of all logged exercises - No exercise was recorded on November 16 - The treadmill session was your most intense cardiovascula...
work page 2019
-
[11]
The walks typically lasted 20-40 minutes with moderate intensity (average heart rate 97-115 bpm)
**Walking** (11 sessions) - This was your dominant activity, appearing nearly every day with multiple sessions. The walks typically lasted 20-40 minutes with moderate intensity (average heart rate 97-115 bpm)
-
[12]
**Treadmill** (1 session on Nov 19) - A single 26-minute vigorous session with higher heart rate (154 bpm average)
-
[13]
**General Workout** (1 session on Nov 19) - A 44-minute mixed-intensity session combining cardio and strength elements. Key observations: - Walking accounted for 85% of your recorded exercise sessions - No strength training or flexibility exercises were logged in this period - November 16 showed no recorded exercise activity The data suggests a focus on c...
work page 2019
-
[14]
The walks typically lasted 20-30 minutes with moderate intensity (average heart rate 97-115 bpm)
**Walking** (9 instances) - This was your dominant activity, appearing nearly every day with multiple sessions. The walks typically lasted 20-30 minutes with moderate intensity (average heart rate 97-115 bpm)
-
[15]
**Treadmill** (1 instance on Nov 19) - A single 26-minute vigorous session with higher intensity (average HR 154 bpm)
-
[16]
**General Workout** (1 instance on Nov 19) - A 44-minute mixed-intensity session logged as "Workout" (average HR 133 bpm). Key observations: - Walking accounted for 82% of your logged exercise sessions - No exercise was recorded on November 16 - Your most active day was November 19 with 4 separate exercise sessions - Exercise intensity varied from light (...
work page 2021
-
[17]
Examples: 2021-12-08 (HRV: 62.585, Steps: 11,727, Light activity: 156 min)
**General Trends**: - Extreme step counts (>20,000) often cor- - Higher HRV RMSSD (indicating better recovery/stress resilience) tends to coincide with days of moderate step counts (10,000-17,000 steps) and lightly active time (150-200 minutes). Examples: 2021-12-08 (HRV: 62.585, Steps: 11,727, Light activity: 156 min). - Extreme step counts (>20,000) oft...
work page 2021
-
[18]
**Notable Exceptions**: - Some high-activity days maintained good HRV (e.g., 2021-12-17: 20,005 steps, 262 min light activity, HRV 50.73). - The lowest HRV values (e.g., 2021-12-26: 34.656) occurred after consecutive high-activity days, suggesting possible cumulative fatigue. ... [truncated] Rag(Rank-2) – Context Matched nodes: HRV RMSSD : description: He...
work page 2021
-
[19]
**General Relationship**: - HRV RMSSD (a marker of parasympathet- ic/vagal activity) typically shows an inverted-U relationship with physical activity: ... [truncated]
-
[20]
**Data Observations** (Nov 2021-Jan 2022): - On high step days (>15,000 steps) with substantial lightly active time (>200 min): - HRV often remained stable (e.g., Dec 17: 20,005 steps, 262 min LAT -> HRV 50.73 ms) - Some high-activity days showed HRV dips (Dec 25: 16,722 steps -> HRV 38.93 ms) - Lower activity days (<5,000 steps) showed variable HRV: - So...
work page 2021
-
[21]
**Key Patterns**: - No strict linear correlation exists in this dataset - HRV appears more sensitive to recovery factors (sleep, stress) than to activity volume alone - The individual maintains mid-range HRV (45-55ms) across most activity levels, suggesting good autonomic resilience ... [truncated] W AG(Rank-1) – Context Matched nodes: HRV RMSSD : descrip...
-
[22]
**General Trends**: - Higher HRV RMSSD (indicating better recov- ery/stress resilience) tends to coincide with days of moderate step counts (10,000-15,000 steps) and balanced lightly active time (150-200 min- utes). - Extreme activity days (e.g., Dec 31: 27,943 steps) often correlate with lower HRV the follow- ing day (Jan 1: 37.97 ms), suggesting potenti...
-
[23]
**Optimal Range Observations**: - The highest HRV readings (Dec 8-10: 62-64 ms) occurred with: ... [truncated] - This suggests a "sweet spot" where substantial but not excessive movement supports autonomic balance
-
[24]
**Recovery Dynamics**: - Days with<8,000 steps and<120 light activ- ity minutes (e.g., Dec 3, Dec 12) often preceded HRV rebounds, indicating these may function as recovery days
-
[25]
**Notable Exceptions**: - December 25-26 shows an inverse pattern where high steps (16,722-10,128) coincided with very low HRV (38.93-34.66 ms), possibly indicating holiday stress or sleep disruption overriding ac- tivity benefits. **Key Insight**: Moderate daily movement (10,000-15,000 steps with 150-200 light activity minutes) appears most supportive of...
-
[26]
**Engagement Metrics**: Tracked behaviors (e.g., workout consistency, task completion rates)
-
[27]
**Correlative Data**: Sleep quality, stress markers (HRV), or activity logs for the past 7 days Without this baseline, I recommend: - Enabling granular tracking for engagement- related metrics - Checking device/sensor connectivity to ensure data collection Specify any available proxies (e.g., screen time, step count) for alternative assessment. *(Limitati...
work page 2020
-
[28]
**Physical Activity Patterns**: - Your step count showed significant variation (284 to 30,406 steps/day) ... [truncated]
-
[29]
**Energy Expenditure**: - Caloric burn ranged from 1,997-5,012 kcal/day (+1.30σdeviation), with ... [truncated]
-
[30]
**Mental Fatigue**: - Your self-reported fatigue scores showed inverse patterns to activity levels. Notably, your lowest fatigue score (1) coincided with your highest activity day, while higher fatigue (4) occurred during less active periods. **Key Observations**: - The data suggests a strong temporal association between physical activity metrics (steps, ...
work page 2020
-
[31]
**Pattern Analysis**: - 40% of bedtimes occurred after midnight - Only 20% fell within a consistent 30-minute window of your median bedtime (22:53)
-
[32]
**Guideline Comparison**: - Your variability is 3x greater than the recommended threshold - Late bedtimes (post-23:30) correlate with documented circadian rhythm disruption risks
-
[33]
Consider implementing a 30-minute pre-bed routine to reinforce circadian cues
**Data Limitations**: - 1 missing data point (2020-03-03) - No baseline comparison available Recommendation: Gradually adjust bedtime toward a consistent target (e.g., 22:30-23:00) to align with chronobiology research showing improved sleep quality with regular schedules. Consider implementing a 30-minute pre-bed routine to reinforce circadian cues. Rag(R...
work page 2020
-
[34]
**Variability Pattern**: - Bedtimes range widely from 21:26 to 01:26 (a 4-hour window) - Frequent late bedtimes (past midnight on 8 occasions) - No consistent pattern emerges from the data
-
[35]
**Guideline Comparison**: - Sleep hygiene emphasizes consistency (+/- 30 minutes is ideal) - Your variability exceeds this by 8x the recommended threshold - Late bedtimes may indicate circadian rhythm disruption
-
[36]
[truncated] W AG(Rank-1) – Context Matched nodes: Bedtime start time : description: Bedtime Start
**Data Observations**: - 27% of nights had bedtimes after midnight - Only 3 nights fell within a 1-hour window (22:30-23:30) - One missing data point (2020-03-03) ... [truncated] W AG(Rank-1) – Context Matched nodes: Bedtime start time : description: Bedtime Start ... [truncated] Nodes related to matched nodes which might be helpful: Bedtime end time : de...
work page 2020
-
[37]
recommended 8pm-12am window for adults)
**Variability Pattern**: - Bedtime ranges from 21:26 to 01:26 (4-hour window), with frequent 1-hour day-to-day shifts - 40% of nights had bedtimes after midnight (vs. recommended 8pm-12am window for adults)
-
[38]
- Mood data (where available) shows better scores (4/5) on days following earlier bedtimes
**Impact on Sleep Metrics**: - Later bedtimes correlate with shorter sleep du- ration (e.g., 01:26 bedtime -> 5.4h sleep vs 21:26 -> 9h sleep). - Mood data (where available) shows better scores (4/5) on days following earlier bedtimes
-
[39]
**Guideline Comparison**: - Sleep hygiene recommends <30min variability in bedtime - Your average variability exceeds 90min, with 7 instances of 2-hour differences between consecutive nights ... [truncated] Example 5:A case where incorporating additional metrics provides deeper insights beyond the primary data, enabling a more comprehensive understanding ...
work page 2020
- [40]
-
[41]
**Pattern**: - 3 days at normal baseline (score 3) - 2 days with elevated fatigue (score 4) - 2 days with below-normal reports (score 2)
-
[42]
**Notable Peaks**: - March 5th and 7th showed elevated fatigue (score 4), indicating days of significantly increased mental tiredness
-
[43]
**Comparison**: - This variation falls within your normal range (no statistical abnormality detected) The alternating pattern suggests possible workload variability or recovery periods between demanding cognitive activities. The two elevated fatigue days may warrant examination of specific activities or stressors occurring on March 5th and 7th. Recommenda...
work page 2019
-
[44]
**Data Gap**: No measurable health data was captured for 6 out of 7 days, limiting trend analysis
-
[45]
**Recommendations:** - Verify sensor functionality to ensure future data collection
**Injury Context**: The minor injuries on 2019-11-13 may warrant monitoring for recovery (e.g., pain duration, mobility changes), but no follow-up data is available. **Recommendations:** - Verify sensor functionality to ensure future data collection. - Log additional details about injuries (e.g., cause, symptoms) to assess impact. - If injuries persist be...
work page 2019
-
[46]
**Data Gaps**: The lifelog contains mostly empty entries (‘nan‘), suggesting inconsistent data collection or potential device/sensor issues
-
[47]
**Injury Record**: The minor injuries logged on 2019-11-13 may warrant monitoring for recovery progress, but no follow-up data is available
work page 2019
-
[48]
### Recommendations: - Verify device/sensor functionality to ensure continuous data capture
**No Abnormalities**: The system detected no deviations from your baseline, but this assessment is limited due to sparse data. ### Recommendations: - Verify device/sensor functionality to ensure continuous data capture. - Expand tracked metrics (e.g., activity levels, sleep, HRV) for more actionable insights. - Log updates on injury recovery if symptoms p...
work page 2019
-
[49]
This may correlate with the observed fluctuations in sleep and activity metrics
**Injury Event**: On 2019-11-13, you reported minor injuries to your left elbow and right shoulder. This may correlate with the observed fluctuations in sleep and activity metrics
work page 2019
-
[50]
The 7-day average deviates +1.18 SD from your baseline, suggesting unusual instability
**Sleep Patterns**: - **Deep Sleep**: Varied significantly (4-76 minutes), with a notable drop to just 4 minutes on 2019-11-12. The 7-day average deviates +1.18 SD from your baseline, suggesting unusual instability. - **Total Sleep Duration**: Ranged from 220-478 minutes (~3.7-8 hours), with the shortest duration coinciding with the day of lowest deep sle...
work page 2019
-
[51]
The 7-day average is 0.83 SD above your baseline
**Activity Levels**: - Moderately active time showed a progressive increase (14-49 minutes/day), peaking on the injury reporting day (2019-11-13). The 7-day average is 0.83 SD above your baseline
work page 2019
-
[52]
- The most extreme sleep disruption (2019-11-
**Critical Observations**: - The injury date (2019-11-13) coincided with both your highest activity level (49 minutes) and suboptimal deep sleep (28 minutes). - The most extreme sleep disruption (2019-11-
work page 2019
-
[53]
preceded the injury report, suggesting possi- ble fatigue as a contributing factor. ... [truncated] J Prompts 1""" 2Generate clinically relevant questions from wearable data, with each question containing 2-3 metrics. 3 4INPUT FORMAT (Array of metric objects): 5[ 6{ 7"id": "<unique_id>", 8"metrics":[ 9{ 10"name": "<metric_name_1>", # The health metric bei...
-
[54]
Does [metric1] relate to [metric2] trends for the past 30 days?
**Metric Relationships ** (Openness: 0.4-0.6) 36- Example: "Does [metric1] relate to [metric2] trends for the past 30 days?" 37
-
[55]
Do [metric1] spikes follow days with high [metric2]?
**Contextual Queries ** (Openness: 0.5-0.7) 39- Example: "Do [metric1] spikes follow days with high [metric2]?" "Is there a pattern in my [metric1] on days I have a higher [metric2] for the past week?" 40 41GENERATION RULES:
-
[56]
Time binding: 43- Map granularity to natural terms: 44- 1 -> "today" 45- 7 -> "past 7 days" 46- 14 -> "past 14 days" 47- 30 -> "past 30 days" 48- all -> "overall"
-
[57]
Each question must reference metrics from the input list
-
[58]
Exactly 1 output question per input group 51EXAMPLES: 52INPUT: 53[ 54{ 55"id": "001", 56"metrics": [ 57{ 58"name": "resting_heart_rate", 59"description": "Beats per minute at complete rest" 60}, 61{ 62"name": "sleep_duration", 63"description": "Total minutes of sleep per night" 64} 65], 66"date": "2023-11-15", 67"time_granularity": "30" 68} 69] 70OUTPUT: ...
work page 2023
-
[59]
Name: 34- Use standardized medical terminology 35- Keep concise but clear 36- Include common abbreviation if applicable 37
-
[60]
Description (Required): 39- What is being measured 40- How it’s measured 41- Clinical significance 42- Relationship to health outcomes 43
-
[61]
gesture recognized does not have a range) 49
Range (if applicable): 45- Normal ranges for different demographics 46- Units of measurement 47- Alert thresholds 48- Output "None" if not applicable(e.g. gesture recognized does not have a range) 49
-
[62]
Recommendations (if applicable): 51- Evidence-based 52- Actionable 53- Context-aware 54- Output "None" if not applicable (e.g. there is not such a recommendation for improvement for the entity, like gesture) 55 56-Examples- 57Example 1: 58Input: 59{ 60"entity_name": "Energy expenditure", 61"provided_description": "Energy consumption caused by the physical...
-
[63]
Semantic Analysis: 7- Look beyond exact text matches 8- Consider medical synonyms and related terms 9- Evaluate contextual meaning in healthcare 10
-
[64]
Description Analysis: 12- Identify overlapping concepts 13- Consider complementary information 14- Evaluate scope and specificity 15
-
[65]
Scoring Criteria: 170.0-0.3: Clearly different concepts 180.4-0.6: Related but distinct 190.7-0.8: Highly similar 200.9-1.0: Virtually identical 21
-
[66]
Only return the node if you think it is a duplicate of an existing node. 23 24INPUT FORMAT: 25{ 26"input_name": "new node name", 27"input_description": "new node description", 28"references": [ 29{ 30"name": "existing node 1 name", 31"description": "existing node 1 description" 32}, 33{ 34"name": "existing node 2 name", 35"description": "existing node 2 d...
-
[67]
**QUERY DECOMPOSITION ** 8- **Key Entities **: Identify health metrics (e.g., HRV, heart rate) 9- **Temporal Scope **: 10- Default: Past 7 days 11- Explicitly stated periods override default 12
-
[68]
15- Contextual Filtering: Apply time-based constraints
**KNOWLEDGE RETRIEVAL ** 14- Primary Entity Matching: Fetch data for core health metric. 15- Contextual Filtering: Apply time-based constraints. 16
-
[69]
19- Highlight trends, anomalies, or gaps
**ANALYSIS** 18- Cross-reference data with medical best practices. 19- Highlight trends, anomalies, or gaps. 20
-
[70]
**RESPONSE GENERATION ** 22- Requirements: 23- Ground all claims in evidence 24- Acknowledge data limitations 25- For unanswerable queries: Specify missing data 26 27## OUTPUT FORMAT 28Answer: Concise response with integrated insights. 29""" Prompt 6: Query_base 1""" 2## CORE OBJECTIVE 3Analyze health queries through structured function calls to external ...
-
[71]
**QUERY DECOMPOSITION ** 8- **Key Entities **: Identify primary subjects/measurements (e.g., HRV, heart rate) 9- **Temporal Scope **: 10- Default: Past 7 days 11- Explicitly stated periods override default 12- **Openness Score ** (0.0-1.0): 13| Score Range | Search Strategy | Examples | 14|--------------|---------------------------------|-----------------...
-
[72]
**GRAPH TRAVERSAL ** 20- Primary entity matching 21- Relationship expansion proportional to openness score 22- Contextual data retrieval with temporal filtering 23
-
[73]
**MULTIMODAL ANALYSIS ** 25- Cross-reference data types: 26 * Physiological (HRV, HR) 27 * Environmental (sleep, activity) 28 * Subjective (user notes) 29- Identify: 30- Consistent corroborating evidence 31- Conflicting indicators 32- Temporal patterns 33
-
[74]
**RESPONSE GENERATION ** 35- Requirements: 36- Ground all claims in evidence 37- Acknowledge data limitations 38- For unanswerable queries: Specify missing data 39- Prioritize: 40- Direct correlations > inferred relationships 41- User-specific context > general knowledge 42 43## OUTPUT FORMAT 44Answer: Concise response with integrated insights. 45""" Prom...
-
[75]
**Insightfulness(most important) **: Does the response offer meaningful, actionable insights beyond the obvious?
-
[76]
**Relevance**: Is the response relevant and does it include novel information?
-
[77]
**Groundedness**: Are factual claims well-supported by the provided content or trusted sources?
-
[78]
**Personalization**: Does the response meaningfully incorporate the user’s context (e.g., wearable data)?
-
[79]
**Clarity**: Is the response clearly written, logically structured, and easy to understand for a non- expert?
-
[80]
**Absence_of_harmful_content**: Is the response free from misleading, unsafe, or inappropriate information? 30 31Important Notes: 32 33Do not assign the same rank to multiple methods unless they are truly indistinguishable in that dimension . 34 35Rank relative to each other within the batch, not by absolute standards. 36 37Lower rank numbers are better (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.