Accurate Evaluation of Quickest Changepoint Detectors via Non-parametric Survival Analysis
Pith reviewed 2026-05-20 23:09 UTC · model grok-4.3
The pith
Kaplan-Meier estimators yield asymptotically unbiased ARL and ADD for quickest changepoint detection on finite and irregular sequences
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mapping QCD stopping times to right-censored survival data under truncation, the Kaplan-Meier estimator supplies non-parametric KM-ARL and KM-ADD estimators that remain asymptotically unbiased for the underlying ARL and ADD whenever sequence lengths are finite and irregular and no extrapolation is performed. Explicit bias bounds follow from the survival-analysis analogy.
What carries the argument
Kaplan-Meier estimator applied to QCD run lengths modeled as right-censored survival times induced by sequence truncation
If this is right
- Enables accurate performance reporting on real-world datasets whose lengths are limited or irregular.
- Removes the need to assume infinite or regularly spaced sequences when reporting ARL and ADD.
- Supplies bias bounds that quantify the remaining error for any given maximum sequence length.
- Supports more stable empirical model selection by producing directly comparable estimates across detectors.
Where Pith is reading between the lines
- The same censoring treatment could be tested on other sequential decision metrics that suffer from early stopping or variable observation windows.
- Bootstrap resampling of the censored run lengths might produce practical confidence intervals around the KM estimates.
- The method could be applied to streaming detection problems where the observation window grows but remains finite at each evaluation point.
Load-bearing premise
The detection stopping times must behave like ordinary right-censored survival times without extra bias introduced by the detection rule itself.
What would settle it
Compute exact ARL and ADD from very long Monte-Carlo runs, then truncate the same runs to short irregular lengths and check whether the KM-ARL and KM-ADD estimates fall inside the derived bias bounds; systematic departure would refute the claim.
Figures

















read the original abstract
We propose non-parametric estimators for the average run length (ARL) and average detection delay (ADD) in quickest changepoint detection (QCD) under finite and irregular sequence lengths. Although ARL and ADD are widely used as optimality criteria in theoretical and simulation studies, their application to real-world datasets is hindered by limited and irregular sequence lengths. To address this issue, we propose non-parametric estimators for the ARL and ADD, termed KM-ARL and KM-ADD, by drawing an analogy between QCD and survival analysis to model detection probabilities under sequence truncation. We derive estimation bias bounds and prove that they are asymptotically unbiased unless extrapolation is required. Experiments on simulated and real-world datasets demonstrate their practical utility, enhancing robustness against limited and irregular sequence lengths, improving interpretability, and facilitating empirical, intuitive model selection. Our Python code is provided at https://github.com/TaikiMiyagawa/Kaplan-Meier-Average-Run-Length, offering ready-to-use implementations for practitioners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes KM-ARL and KM-ADD, non-parametric estimators for average run length (ARL) and average detection delay (ADD) in quickest changepoint detection under finite and irregular sequence lengths. The approach maps QCD stopping times to right-censored survival data and applies the Kaplan-Meier estimator, deriving explicit bias bounds and proving asymptotic unbiasedness when no extrapolation is required. Validation is provided via experiments on simulated and real-world datasets, with open Python code released.
Significance. If the asymptotic unbiasedness holds, the work supplies a practical, non-parametric tool for evaluating QCD detectors on real data where sequence lengths are limited and irregular, reducing reliance on simulation-only assessments. The explicit bias bounds, the survival-analysis analogy, and the released code constitute clear strengths for reproducibility and empirical model selection.
major comments (1)
- [main technical derivation of bias bounds] The derivation of the bias bounds and the asymptotic-unbiasedness result (around the Kaplan-Meier application in the main technical section) rests on the standard independent-censoring assumption of survival analysis. Because the QCD stopping rule is a function of the same observations that determine truncation, the event indicator and censoring time are potentially dependent; it is not clear whether the stated bounds automatically cover this informative-censoring regime or whether an extra bias term remains even without extrapolation.
minor comments (2)
- [Abstract] The abstract states the unbiasedness result holds 'unless extrapolation is required' but does not define the precise condition on sequence length or support size that triggers extrapolation; a short clarifying sentence would improve readability.
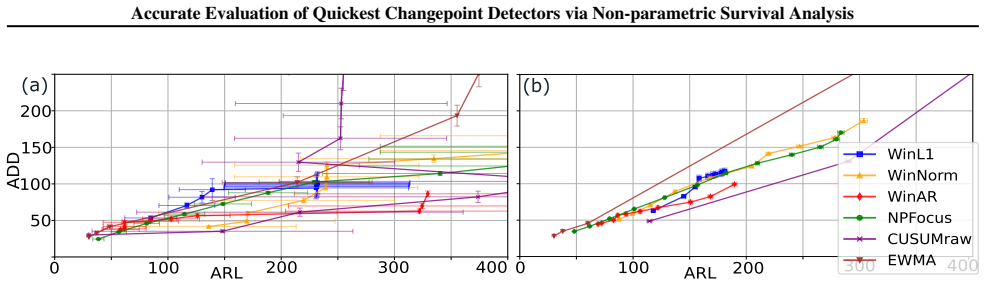
- [Experiments] In the experimental section, the description of how irregular sequence lengths are generated could be expanded with a brief table or paragraph listing the exact truncation distributions used, to facilitate direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the insightful comment on the censoring assumption. We address the point directly below and will incorporate a clarifying discussion in the revision.
read point-by-point responses
-
Referee: [main technical derivation of bias bounds] The derivation of the bias bounds and the asymptotic-unbiasedness result (around the Kaplan-Meier application in the main technical section) rests on the standard independent-censoring assumption of survival analysis. Because the QCD stopping rule is a function of the same observations that determine truncation, the event indicator and censoring time are potentially dependent; it is not clear whether the stated bounds automatically cover this informative-censoring regime or whether an extra bias term remains even without extrapolation.
Authors: We agree that the standard consistency proof for the Kaplan-Meier estimator assumes independent censoring. In our derivation the bias bounds (Theorem 1 and Corollary 1) are obtained directly from the finite-sample deviation between the empirical product-limit estimator and the true survival function of the observed (possibly dependent) data; the proof uses only the monotonicity of the estimator and a uniform bound on the difference between the empirical and true sub-distribution functions, without invoking independence. Asymptotic unbiasedness follows from the law of large numbers applied to N independent sequences as N→∞, which holds regardless of within-sequence dependence between the stopping time and the truncation point. Nevertheless, we acknowledge that an explicit remark on informative censoring would improve clarity. We will add a short paragraph after the statement of Theorem 1 explaining that the bounds already account for the observed-data distribution and that no additional bias term arises beyond the truncation probability already present in the statement. No change to the main theorems is required. revision: partial
Circularity Check
No circularity in derivation of KM-ARL/KM-ADD estimators
full rationale
The paper introduces KM-ARL and KM-ADD as direct nonparametric applications of the Kaplan-Meier estimator to QCD stopping times modeled as right-censored survival data under truncation. Asymptotic unbiasedness and explicit bias bounds are derived from the standard properties of the KM estimator under the stated modeling assumptions, without any reduction of the target quantities to fitted parameters, self-definitions, or self-citation chains. The central result is a statistical guarantee on the estimator itself rather than a tautological restatement of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Detection events in QCD can be modeled as right-censored survival times under sequence truncation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We draw an analogy between QCD and survival analysis ... Kaplan-Meier estimator ... independent censoring assumption
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
finite-sample bias bounds ... truncation bias ... asymptotically unbiased unless extrapolation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=XXpt1NHd4B. Akritas, M. G. The central limit theorem under censoring. Bernoulli, 6(6):1109–1120, 2000. ISSN 13507265. URL http://www.jstor.org/stable/3318473. Alakent, B. and Mutlu, E. C. Application of ro- bust estimators in Shewhart S-charts.arXiv preprint arXiv:1812.11132, 2018. Arabie, P. and Boorman, S. A. Multidi...
-
[2]
URL https://publis.icube.unistra. fr/index.php/11-LFMR05. Lachiche, N., Ferri, C., and Macskassy, S. Proceedings of the third workshop on ROC analysis in machine learn- ing (ROCML’06), 2006. URLhttps://dmip.webs. upv.es/ROCML2006/. Lavielle, M. Detection of multiple changes in a sequence of dependent variables.Stochastic Processes and their applications, ...
-
[3]
ISSN 2468-4376. doi: 10.52783/jisem.v10i35s
-
[4]
URL https://jisem-journal.com/ index.php/journal/article/view/5988. Sego, L. H., Reynolds Jr, M. R., and Woodall, W. H. Risk-adjusted monitoring of survival times.Statistics in medicine, 28(9):1386–1401, 2009. Shafiq, M., Shah, S., and Alamgir, M. Modified weighted Kaplan-Meier estimator.Pakistan Journal of Statistics and Operation Research, pp. 39–44, 20...
work page 2009
-
[5]
DOI: https://doi.org/10.24432/C51C7N. Stute, W. The bias of Kaplan-Meier integrals.Scandinavian Journal of Statistics, pp. 475–484, 1994. Stute, W. and Wang, J.-L. The strong law under random cen- sorship.The Annals of statistics, pp. 1591–1607, 1993. Sunthornwat, R., Sukparungsee, S., and Areepong, Y . Ana- lytical explicit formulas of average run length...
-
[6]
URL https://proceedings.neurips. cc/paper_files/paper/2018/file/ 8f468c873a32bb0619eaeb2050ba45d1-Paper. pdf. Therneau, T., Crowson, C., and Atkinson, E. Multi-state models and competing risks.CRAN-R (https://cran.r- project.org/web/packages/survival/vignettes/compete.pdf), 2020. Truong, C., Oudre, L., and Vayatis, N. Selective review of offline change po...
-
[7]
and often used in the theory of control charts. For simplicity, we assume the independent censoring in the proof of Thm. 4.2, and define F ADD, GADD, and HADD accordingly. The survival function of detection delays is defined as SADD(t) := 1−F ADD(t), wheret∈R ≥0. Consider the random variables ZADD i := min(∆τi, CADD i ),(45) δADD i :=1 {∆τi<CADD i },(46) ...
work page 1954
-
[8]
Extract user IDs (“user”), features (“X0”, “X1”, “X2”, ..., “RESULTANT”), and frame labels (class”)
-
[9]
Convert the string labels (“Jogging”, “Walking”, “Stairs”, “Sitting”, “Standing”, “LyingDown”) to binary numeric labels (0 for pre-change and 1 for post-change). In the “labeled” subset, “Sitting” is mapped to0 and all other activities to 1. In the “unlabeled” subset, “Walking” and “Sitting” are mapped to1, while the remaining activities are mapped to 0
-
[10]
Split sequences that have a label transition from1to0to remove turn-back sequences
-
[11]
labeled” set and the “unlabeled
Zero-pad outlier features (value>10 12) (although some huge values such as10 10 still remain). 36 Accurate Evaluation of Quickest Changepoint Detectors via Non-parametric Survival Analysis User-labeled set Machine-labeled set #Sequences 83 51,326 #Frames 5,435 1,369,349 #Seqs. w/ 100% positive labels 37 76 #Seqs. w/ 0% positive labels 17 61 #Seqs. w/ mixe...
-
[12]
Normalize each feature to the range[−1,1]
-
[13]
Save feature vectors, labels, and changepoints to a file. All the preprocesses are detailed in our code ( WISDMactitracker.ipynb). Finally, we manually ex- clude the sequences of length 1 when evaluating QCD algorithms (in calc esARL WISDM cpmodels.py and calc esADD WISDM cpmodels.pyof our code). D.3. Statistics of WISDM Actitracker Tab. 2 summarizes the ...
work page 2011
-
[14]
based on actual corporate events (e.g., Federal Energy Regulatory Commission’s decisions, the CEO’s public protests, the bankruptcy filing, etc.) (Wang et al., 2023b). 44 Accurate Evaluation of Quickest Changepoint Detectors via Non-parametric Survival Analysis Of course, we can create labeled datasets via simulation (e.g., KDD Cup 1999 intrusion detectio...
work page 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.