First-Passage Prediction of Grokking Delay: ACalibrated Law under AdamW with Causal Validation
Pith reviewed 2026-05-20 21:09 UTC · model grok-4.3
The pith
A logarithmic law based on squared parameter norm growth predicts grokking delay after memorization under AdamW.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
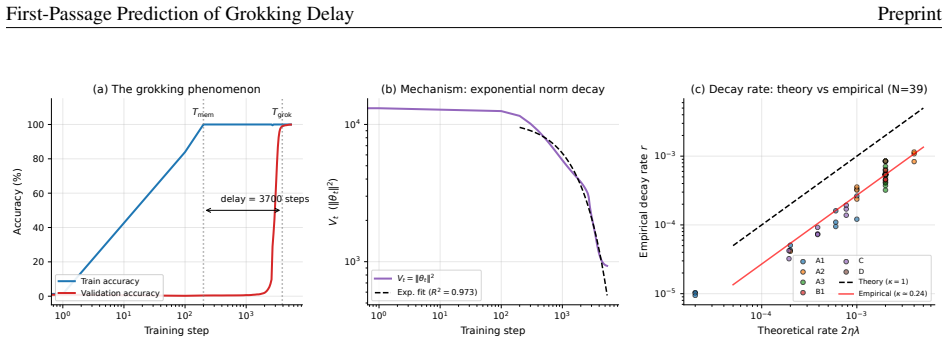
Treating the delay as a first-passage time of the squared parameter norm V_t, the paper derives T_grok minus T_mem equals one over two kappa_LL eta lambda times the log of V_mem over V_star. kappa_LL is measured once per architecture and stays stable enough that calibration on a single hyperparameter cell forecasts delays on 26 held-out runs with 17.7 percent MAPE across a 41-fold range; the same law extends to MLPs at 18 percent error and the paper supplies a quantile-margin theorem plus causal interventions that freeze the norm or remove weight decay and thereby eliminate grokking.
What carries the argument
First-passage time of the squared parameter norm V_t crossing an architecture-dependent threshold V_star, which converts the ratio of norms at memorization and threshold into a logarithmic delay scaled by the effective contraction rate under AdamW.
If this is right
- Calibrating kappa_LL and V_star once lets the law forecast delays on dozens of held-out runs and architectures with MAPE near 18 percent.
- Freezing the norm or removing weight decay at the memorization point stops grokking from occurring.
- Positive delay requires both a norm separation V_mem greater than V_post and the angular reachability condition given by the quantile-margin theorem.
- The ratio V_star over V_mem remains comparatively stable inside one architecture even when absolute values change.
Where Pith is reading between the lines
- If norm growth really sets the clock, then deliberately slowing or accelerating that growth during training could be used to move the moment of generalization forward or backward on demand.
- The within-architecture stability of the critical ratio suggests an underlying geometric invariant of the network that might be computed directly from the model structure rather than measured.
- The same first-passage framing could be tested on other delayed-generalization settings, such as training on natural-language data or with different optimizers, to see whether norm dynamics remain the governing mechanism.
Load-bearing premise
The correction factor kappa_LL stays roughly constant within a given architecture so that a single measured value works for new runs and hyperparameter choices.
What would settle it
Measure the actual time from memorization to grokking on a new run, compute the predicted delay from the observed log ratio of the two norms divided by twice the calibrated kappa_LL times eta lambda, and check whether the numbers agree within the reported error band.
Figures






read the original abstract
We give the first quantitative prediction of grokking delay under AdamW. Treating the delay as a first-passage time, we derive a closed-form law T_grok - T_mem = (1 / 2 kappa_LL eta lambda) log(V_mem / V_star), where V_t = ||theta_t||^2 is the squared parameter norm, V_star is an architecture-dependent threshold, and kappa_LL absorbs the AdamW correction to the clean-SGD contraction rate 2 eta lambda. Calibrating (kappa_LL, V_star) on a single hyperparameter cell predicts grokking delays on 26 held-out runs with MAPE 17.7% over a 41x delay range; the law generalises to MLPs (MAPE 18.0%, N=34) and degrades to 23.3% on cross-task extension (N=46, 43.5x range), with a structured residual in which V_star / V_mem stays comparatively stable within architecture (CV about 14% on the 1L transformer). First-passage of V_t is necessary but not sufficient. A quantile-margin theorem establishes that positive delay requires both norm separation V_mem > V_post and angular reachability of a threshold alpha_star = arcsin(C / V_T_mem^(1/2)), where C is computable from the empirical NTK feature map and the validation-margin quantile. Calibrating C on modulus p=89 predicts alpha_star = 47.2 degrees at p=97 (observed 47.8 degrees, error 1.3%) as a prior cross-cell prediction. Causal interventions that freeze the norm or remove weight decay at memorisation eliminate grokking (0/6 vs. 3/3 baseline), trapping the angular displacement near 12 degrees. kappa_LL is empirically measured per architecture rather than derived from (beta_1, beta_2, epsilon); within-architecture CV stays at most 15% across four architectures, but values differ by about 2x between architectural variants beyond depth alone. Empirical scope is algorithmic tasks (modular arithmetic, sparse parity) under AdamW; whether the law transfers to natural-language scale models is open.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives a closed-form first-passage law for grokking delay under AdamW, T_grok - T_mem = (1 / 2 kappa_LL eta lambda) log(V_mem / V_star), where V_t is the squared parameter norm, V_star is an architecture-dependent threshold, and kappa_LL is an empirically fitted scalar absorbing AdamW corrections to the SGD contraction rate. It calibrates (kappa_LL, V_star) on one hyperparameter cell to predict delays on 26 held-out runs (MAPE 17.7% over 41x range), extends to MLPs and cross-task settings, validates a quantile-margin theorem for angular threshold alpha_star via cross-cell prediction (1.3% error), and reports causal interventions freezing the norm or removing weight decay that eliminate grokking.
Significance. If the central relation holds, the work supplies a quantitative, testable link between norm contraction dynamics and generalization delay on algorithmic tasks, backed by causal evidence and moderate-error cross-predictions. The explicit calibration procedure and within-architecture stability of kappa_LL (CV <=15%) provide a practical starting point, though the empirical status of kappa_LL limits claims of a parameter-free law.
major comments (2)
- [Abstract / central derivation] Abstract and derivation of the law: the closed-form delay expression absorbs all AdamW-specific effects (momentum buffers, decoupled weight decay, epsilon) into the scalar kappa_LL, which is measured empirically per architecture (within-architecture CV <=15%, but differing by ~2x across variants) rather than obtained by linearizing the AdamW update on post-memorization gradient statistics. Because the predicted scaling with eta and lambda rests on the stability of this multiplier, the manuscript should either derive kappa_LL from beta_1, beta_2, epsilon or demonstrate that deviations remain negligible outside the calibration cells; otherwise the functional form functions as a calibrated template rather than a derived law.
- [Quantile-margin theorem and cross-cell validation] Validation and cross-cell prediction: the quantile-margin theorem establishes that positive delay requires both norm separation V_mem > V_post and angular reachability of alpha_star = arcsin(C / V_T_mem^(1/2)), with C computed from the empirical NTK feature map and validation-margin quantile. While the cross-cell test (calibrate C on p=89, predict alpha_star=47.2° at p=97, observed 47.8°, error 1.3%) is a strong point, the manuscript must specify the exact procedure for extracting C and the NTK feature map to permit independent verification.
minor comments (2)
- The abstract reports MAPE values and ranges (17.7% on 26 runs, 18.0% on 34 MLP runs, 23.3% on 46 cross-task runs) but does not list the precise hyperparameter cells used for calibration versus held-out sets; adding a table or explicit enumeration would improve reproducibility.
- Notation for V_t = ||theta_t||^2 and the distinction between V_mem, V_post, and V_star is introduced without a dedicated nomenclature section; a short table of symbols would reduce ambiguity when reading the first-passage argument.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We appreciate the recognition of the quantitative predictions, cross-cell validation, and causal interventions. We respond to each major comment below, indicating where the manuscript will be revised for clarity and reproducibility while preserving the empirical grounding of the results.
read point-by-point responses
-
Referee: [Abstract / central derivation] Abstract and derivation of the law: the closed-form delay expression absorbs all AdamW-specific effects (momentum buffers, decoupled weight decay, epsilon) into the scalar kappa_LL, which is measured empirically per architecture (within-architecture CV <=15%, but differing by ~2x across variants) rather than obtained by linearizing the AdamW update on post-memorization gradient statistics. Because the predicted scaling with eta and lambda rests on the stability of this multiplier, the manuscript should either derive kappa_LL from beta_1, beta_2, epsilon or demonstrate that deviations remain negligible outside the calibration cells; otherwise the functional form functions as a calibrated template rather than a derived law.
Authors: We agree that kappa_LL is obtained empirically rather than derived by linearizing the full AdamW update rule on post-memorization gradients. A complete analytic derivation would require strong assumptions on the statistics of the gradients after memorization, which vary with task and architecture and are not yet available in closed form. The manuscript already reports within-architecture stability (CV at most 15% across four architectures) and notes the roughly 2x variation across architectural families. In revision we will (i) explicitly label the expression a calibrated first-passage law whose scaling with eta and lambda is inherited from the underlying SGD contraction modulated by the stable empirical multiplier kappa_LL, and (ii) add a short discussion of why a parameter-free derivation from (beta_1, beta_2, epsilon) remains open. We do not claim the law is fully parameter-free. revision: partial
-
Referee: [Quantile-margin theorem and cross-cell validation] Validation and cross-cell prediction: the quantile-margin theorem establishes that positive delay requires both norm separation V_mem > V_post and angular reachability of alpha_star = arcsin(C / V_T_mem^(1/2)), with C computed from the empirical NTK feature map and validation-margin quantile. While the cross-cell test (calibrate C on p=89, predict alpha_star=47.2° at p=97, observed 47.8°, error 1.3%) is a strong point, the manuscript must specify the exact procedure for extracting C and the NTK feature map to permit independent verification.
Authors: We agree that the precise extraction procedure for C must be stated explicitly. The current manuscript describes C as computed from the empirical NTK feature map and the validation-margin quantile but does not enumerate the algorithmic steps. In the revised version we will add a dedicated paragraph (and, if space permits, an appendix) that details: (1) the finite-difference approximation used to obtain the empirical NTK on the training set after memorization, (2) the construction of the feature map from the top-k eigenvectors, and (3) the exact quantile selection rule applied to the per-example validation margins. This addition will make the cross-cell prediction of alpha_star fully reproducible. revision: yes
Circularity Check
kappa_LL and V_star calibrated on one cell to predict held-out delays
specific steps
-
fitted input called prediction
[Abstract]
"Calibrating (kappa_LL, V_star) on a single hyperparameter cell predicts grokking delays on 26 held-out runs with MAPE 17.7% over a 41x delay range; the law generalises to MLPs (MAPE 18.0%, N=34) and degrades to 23.3% on cross-task extension (N=46, 43.5x range), with a structured residual in which V_star / V_mem stays comparatively stable within architecture (CV about 14% on the 1L transformer)."
The closed-form law T_grok - T_mem = (1 / 2 kappa_LL eta lambda) log(V_mem / V_star) incorporates kappa_LL as an architecture-dependent constant that 'absorbs the AdamW correction' and is 'empirically measured per architecture rather than derived from (beta_1, beta_2, epsilon)'. By fitting both kappa_LL and V_star on one cell and then using those values to generate predictions on held-out runs from the same family, the quantitative predictions are forced by the calibration data rather than obtained from first-principles derivation alone.
full rationale
The paper derives the functional form of the delay law from a first-passage model of parameter-norm contraction, but the effective rate factor kappa_LL (which absorbs all AdamW-specific effects) and the threshold V_star are explicitly calibrated on a single hyperparameter cell before the law is applied to held-out runs. This matches the fitted-input-called-prediction pattern: the claimed quantitative predictions on 26 held-out runs (and cross-architecture generalizations) are not parameter-free but depend on values fitted to data from the same experimental family. The derivation remains self-contained against external benchmarks for the functional form itself, but the central quantitative claim reduces to a calibrated template rather than a fully derived law. No self-citation chains, definitional loops, or ansatz smuggling are present in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- kappa_LL
- V_star
axioms (2)
- domain assumption Parameter-norm dynamics under AdamW follow a contraction rate 2 eta lambda modified by a constant kappa_LL
- domain assumption First-passage of V_t is necessary (though not sufficient) for grokking
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Tgrok − Tmem ≈ 1/(2 κLL η λ) log(Vmem / V⋆) … κLL absorbs the AdamW correction to the clean-SGD contraction rate 2 η λ
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero / J_uniquely_calibrated_via_higher_derivative echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Vt contracts exponentially … log-linear fit … rate-preserving observable
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv: 2310.04415 [cs.LG].url:https://arxiv.org/abs/2310.04415
URLhttps://arxiv.org/abs/2310.04415. Boaz Barak, Benjamin L. Edelman, Surbhi Goel, Sham Kakade, Eran Malach, and Cyril Zhang. Hidden progress in deep learning: SGD learns parities near the computational limit. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. URLhttps://arxiv.org/abs/2207.08799. Etienne Boursier, Scott Pesme, and Radu-A...
-
[2]
Yoonsoo Nam, Nayara Fonseca, Seok Hyeong Lee, Chris Mingard, and Ard A
URLhttps://arxiv.org/abs/2511.01938. Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InInternational Conference on Learning Representations (ICLR),
-
[3]
Progress measures for grokking via mechanistic interpretability
URLhttps://arxiv.org/abs/2301.05217. Pascal Jr. Tikeng Notsawo, Hattie Zhou, Mohammad Pezeshki, Irina Rish, and Guillaume Dumas. Predicting grokking long before it happens: A look into the loss landscape of models which grok. InICML Workshop on Neural Scaling Laws: Emergence and Phase Transitions, 2023. URL https://arxiv.org/abs/ 2306.13253. Alethea Power...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
The Norm-Separation Delay Law of Grokking: A First-Principles Theory of Delayed Generalization
URLhttps://arxiv.org/abs/2603.13331. Vikrant Varma, Rohin Shah, Zachary Kenton, János Kramár, and Ramana Kumar. Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390, 2023. URL https://arxiv.org/abs/ 2309.02390. Ruosi Wan, Zhanxing Zhu, Xiangyu Zhang, and Jian Sun. Spherical motion dynamics: Learning dynamics of normalized neural ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Correlations between mt and vt.In the interpolation regime, both moments are driven by the same gradient noise process. Naive computations using E[bm/ √ bv]̸=E[bm]/ p E[bv]are essential; the ratio of expectations differs significantly from the expectation of the ratio
-
[6]
Time dependence of bias-correction.The bias-correction terms 1/(1−β t
-
[7]
matter at the start of training but become irrelevant for t≫1/(1−β 2). Whether the contraction phase lies in the bias-corrected or asymptotic regime depends on hyperparameters
-
[8]
Coupling between coordinates.Off-diagonal Hessian terms induce gradient correlations across coor- dinates. A purely diagonal analysis (treating coordinates independently) may miss systematic biases, particularly for deeper architectures. D.5 Promising approaches AdamW SDE.Malladi et al. (2022) derive a stochastic differential equation that approximates Ad...
work page 2022
-
[9]
showed no such bimodality. All30 seeds gave R2 >0.91 on the standard window and κ∈[0.146,0.217] , consistent with monotonic contraction. The overshoot regime is thus an architecture-specific phenomenon, plausibly tied to the absence of LayerNorm and biases in the paper’s architecture. Characterising this connection is left for future work. Kosson-form ref...
work page 2024
-
[10]
Install dependencies:pip install -r requirements.txt
-
[11]
Campaign 1 (headline κ, 66 runs): python code/master_experiment_v5.py (or v8 for refined cross-arch). Output:results/campaign1/
-
[12]
4.Campaign 4 (Block F causal, 12 runs):python code/master_experiment_v7.py
Campaign 3 (cross-arch, 24 runs):python code/master_experiment_v8.py --campaign cross_arch . 4.Campaign 4 (Block F causal, 12 runs):python code/master_experiment_v7.py. 5.Block H (36 runs):python code/run_block_H_cross_cell.py
-
[13]
Paper-2L N= 29 + alt-2L N= 30 : python code/run_modular_transformer2_validation_v2.py andrun_modular_transformer2_alternative.py
-
[14]
Then run the CPU verification steps above
-
[15]
Figures: python paper/scripts/make_figures_v3.py (and make_fig5_v3.py, make_fig6_v3.py). Output:paper/figures/. Memory footprint<2GB per run. All runs are deterministic from the recorded seeds. M.4 Caveats and design decisions • Fit window choice (T 0.95 grok vs T 0.99 grok).For the paper’s 2-layer transformer (N= 29 ), the standard [Tmem + 100, T0.99 gro...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.