Distance-Aware Muon: Adaptive Step Scaling for Normalized Optimization
Pith reviewed 2026-05-20 12:20 UTC · model grok-4.3
The pith
Distance-adaptive Muon sets trust-region radius from the trajectory explored so far to obtain stationarity guarantees on smooth non-convex objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By letting the step scale be chosen from the radius already explored by the trajectory or from a local descent certificate, normalized Muon updates obtain stationarity guarantees for smooth non-convex problems and last-iterate linear convergence rates for star-convex problems, with the radius parameters appearing only in the analysis and not inside the algorithms themselves.
What carries the argument
The trust-region radius adaptation, which is set either from the distance traveled along the optimization path, from a local descent certificate derived from gradient and momentum, or from a scalar distance certificate together with a majorized one-dimensional search.
Load-bearing premise
The optimization trajectory or the initial sublevel set remains bounded.
What would settle it
A smooth non-convex problem in which the iterates diverge to infinity yet Distance-Adaptive Muon still reaches an approximate stationary point would refute the stationarity claim.
Figures



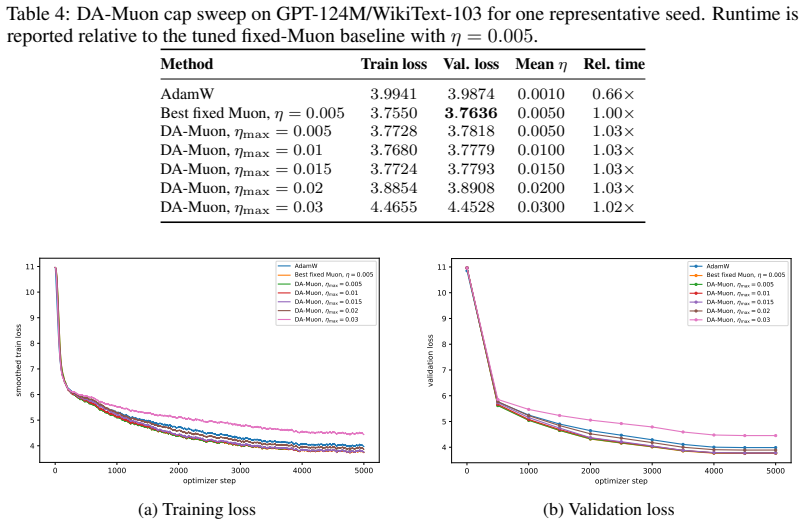






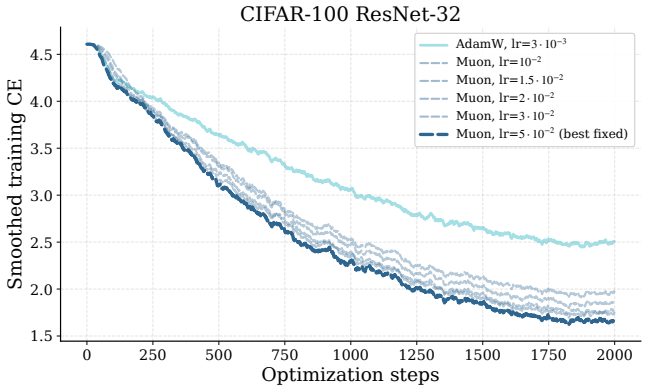
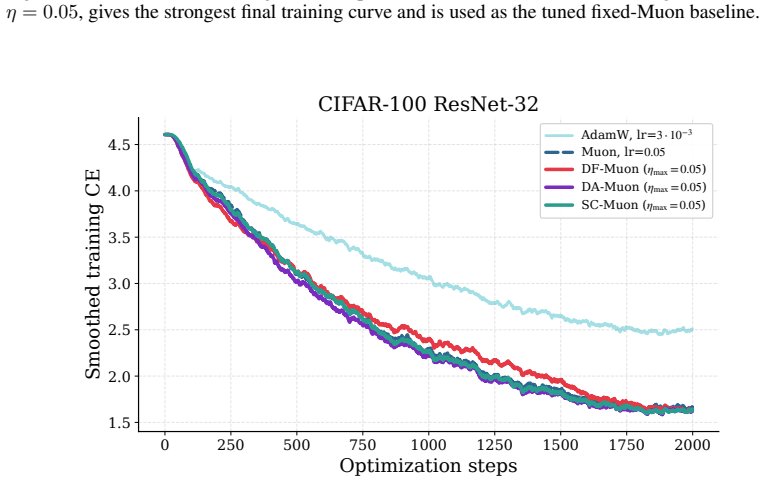
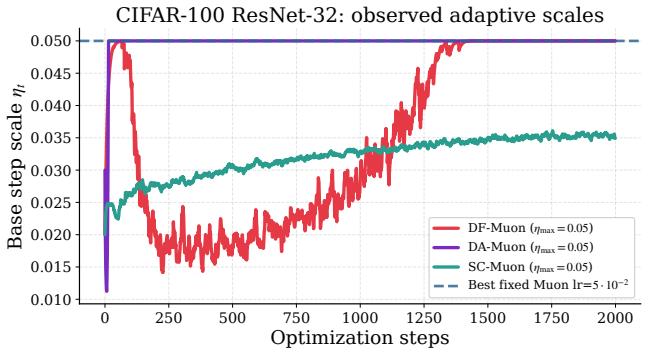
read the original abstract
Muon and related normalized optimizers decouple the choice of update direction from the choice of step scale, but their practical performance remains sensitive to the scale of the normalized step. We study adaptive scaling rules for Muon in general norm geometries and develop three complementary algorithms. For smooth non-convex objectives, we introduce Distance-Adaptive Muon, whose trust-region radius is set from the radius explored by the trajectory, and prove a stationarity guarantee under a bounded-trajectory assumption. We then turn to star-convex objectives, a tractable model of the favorable global geometry often used to reason about the empirical loss landscapes of deep neural networks, where objective-gap guarantees are possible. In this setting, we first introduce Scale-Calibrated Muon, which keeps Muon's exponential moving average but sets the step length from a local descent certificate computed from the current gradient and momentum. For this method, we prove a last-iterate O(1/T) objective-gap bound under a bounded initial sublevel-set assumption, where the corresponding radius parameter appears only in the analysis and not in the algorithm. Finally, we develop Distance-Free Muon, a recentered trust-region method that uses a scalar distance certificate and a majorized one-dimensional search to select the trust-region radius without requiring the unknown distance from the initialization to a global minimizer. Experiments on Transformer language modeling (GPT-124M/WikiText-103) and image classification (ViT-Tiny/CIFAR-100) show that the proposed adaptive scaling rules reduce sensitivity to manual scale tuning and match or improve tuned fixed-scale Muon baselines under the tested budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes three adaptive scaling algorithms for Muon and related normalized optimizers. Distance-Adaptive Muon sets its trust-region radius from the radius explored by the trajectory and proves a stationarity guarantee for smooth non-convex objectives under a bounded-trajectory assumption. Scale-Calibrated Muon retains Muon's EMA but selects step length from a local descent certificate, proving a last-iterate O(1/T) objective-gap bound for star-convex objectives under a bounded initial sublevel-set assumption (with the radius parameter appearing only in analysis). Distance-Free Muon uses a scalar distance certificate and majorized one-dimensional search to choose the radius without requiring the unknown distance to a global minimizer. Experiments on GPT-124M/WikiText-103 and ViT-Tiny/CIFAR-100 indicate that the adaptive rules reduce sensitivity to manual scale tuning while matching or exceeding tuned fixed-scale Muon baselines.
Significance. If the stated assumptions hold, the work supplies concrete convergence guarantees for adaptive normalized optimization together with practical algorithms that demonstrably lessen hyperparameter sensitivity on representative deep-learning tasks. The separation of algorithmic parameters from analysis-only quantities and the use of star-convex geometry as a model for favorable DNN loss landscapes are constructive contributions.
major comments (2)
- [Abstract] Abstract and the section presenting Distance-Adaptive Muon: the stationarity guarantee is conditioned on a bounded-trajectory assumption that the algorithm itself neither enforces nor monitors. In typical non-convex deep-learning landscapes the trajectory radius can grow without bound, which would render the radius-setting rule and the associated guarantee inapplicable. The manuscript should either relax the assumption, provide a practical detection mechanism, or supply empirical evidence that the explored radii remain bounded under the reported training budgets.
- [Abstract] Abstract and the section on Scale-Calibrated Muon: the O(1/T) objective-gap bound likewise rests on a bounded initial sublevel-set assumption that appears only in the analysis. While the paper correctly notes that the radius parameter does not enter the algorithm, the practical plausibility of the assumption for the star-convex model of DNN landscapes should be discussed or tested to substantiate the strength of the theoretical claim.
minor comments (1)
- [Experiments] The experimental section would benefit from reporting the number of independent runs and any statistical significance tests for the observed improvements over tuned Muon baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address each major comment below with clarifications and planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and the section presenting Distance-Adaptive Muon: the stationarity guarantee is conditioned on a bounded-trajectory assumption that the algorithm itself neither enforces nor monitors. In typical non-convex deep-learning landscapes the trajectory radius can grow without bound, which would render the radius-setting rule and the associated guarantee inapplicable. The manuscript should either relax the assumption, provide a practical detection mechanism, or supply empirical evidence that the explored radii remain bounded under the reported training budgets.
Authors: We agree that the bounded-trajectory assumption limits the applicability of the stationarity guarantee for Distance-Adaptive Muon in arbitrary non-convex settings where trajectories might diverge. Relaxing the assumption entirely would require a substantially different proof technique that is outside the scope of the current work. Instead, we will add empirical evidence in the revised manuscript by including plots of the maximum trajectory radius (distance from initialization) versus training step for the GPT-124M and ViT-Tiny experiments. These plots show that, under the reported budgets and standard regularization, the explored radii stabilize and remain bounded, supporting practical relevance of the guarantee. We will also add a short discussion acknowledging the assumption's theoretical nature while noting that normalization and early stopping in deep learning often prevent unbounded growth in practice. revision: yes
-
Referee: [Abstract] Abstract and the section on Scale-Calibrated Muon: the O(1/T) objective-gap bound likewise rests on a bounded initial sublevel-set assumption that appears only in the analysis. While the paper correctly notes that the radius parameter does not enter the algorithm, the practical plausibility of the assumption for the star-convex model of DNN landscapes should be discussed or tested to substantiate the strength of the theoretical claim.
Authors: We concur that further discussion of the bounded initial sublevel-set assumption would strengthen the presentation of the O(1/T) guarantee for Scale-Calibrated Muon. Although the radius parameter is analysis-only and does not affect the algorithm, we will expand the relevant section in the revision to address its plausibility under the star-convex model. The added discussion will reference existing empirical studies on DNN loss landscapes showing that sublevel sets near good minima are typically connected and locally bounded. We will also note that the star-convex geometry serves as a tractable proxy for favorable regions encountered in practice, and suggest that monitoring objective values during training could serve as a heuristic check for the assumption in future applications. revision: yes
Circularity Check
No circularity: adaptive rules and conditional guarantees are independent of target results
full rationale
The paper defines Distance-Adaptive Muon by setting trust-region radius directly from observed trajectory radius and proves stationarity only under an explicit bounded-trajectory assumption stated to appear solely in the analysis. Scale-Calibrated Muon derives step length from a local descent certificate computed from gradient and momentum, with its radius parameter likewise confined to the proof and absent from the algorithm. Distance-Free Muon uses a scalar distance certificate and one-dimensional search. None of these steps reduce the claimed guarantees to the inputs by construction, nor do they rename fitted quantities as predictions or rely on self-citation chains for uniqueness. The derivation remains self-contained against the stated external assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Bounded-trajectory assumption for non-convex stationarity guarantee
- domain assumption Bounded initial sublevel-set assumption for star-convex objective-gap bound
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Distance-Adaptive Muon ... trust-region radius is set from the radius explored by the trajectory ... under a bounded-trajectory assumption
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Scale-Calibrated Muon ... sets the step length from a local descent certificate ... under a bounded initial sublevel-set assumption
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amsel, N., Persson, D., Musco, C., and Gower, R. M. (2025). The polar express: Optimal matrix sign methods and their application to the muon algorithm.arXiv preprint arXiv:2505.16932. Bengio, Y . (2000). Gradient-based optimization of hyperparameters.Neural computation, 12(8):1889–
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Old Optimizer, New Norm: An Anthology
Bernstein, J. and Newhouse, L. (2024). Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325. Carlson, D., Cevher, V ., and Carin, L. (2015a). Stochastic spectral descent for restricted boltzmann machines. InArtificial intelligence and statistics, pages 111–119. PMLR. Carlson, D. E., Collins, E., Hsieh, Y .-P., Carin, L., and Cevher, V . (...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
11 Carmon, Y . and Hinder, O. (2022). Making sgd parameter-free. InConference on learning theory, pages 2360–2389. PMLR. Cartis, C., Gould, N. I., and Toint, P. L. (2011a). Adaptive cubic regularisation methods for unconstrained optimization. part i: motivation, convergence and numerical results.Mathematical Programming, 127(2):245–295. Cartis, C., Gould,...
-
[4]
Krizhevsky, A., Hinton, G., et al. (2009). Learning multiple layers of features from tiny images. Large, T., Liu, Y ., Huh, M., Bahng, H., Isola, P., and Bernstein, J. (2024). Scalable optimization in the modular norm.Advances in Neural Information Processing Systems, 37:73501–73548. Li, J. and Hong, M. (2025). A note on the convergence of muon and furthe...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[5]
Orabona, F. and Tommasi, T. (2017). Training deep networks without learning rates through coin betting.Advances in neural information processing systems,
work page 2017
-
[6]
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al. (2019). Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems,
work page 2019
-
[7]
13 Pethick, T., Xie, W., Antonakopoulos, K., Zhu, Z., Silveti-Falls, A., and Cevher, V . (2025a). Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529. Pethick, T., Xie, W., Erdogan, M., Antonakopoulos, K., Silveti-Falls, T., and Cevher, V . (2025b). Generalized gradient norm clipping & non-euclidean (l0, l1)-smoothness...
work page internal anchor Pith review arXiv 2025
-
[8]
Fork=s+j, we have kX i=1 ¯ri ≥ kX i=s+1 ¯ri = jX ℓ=1 aℓ,¯r k+1 =a j+1
Applying Lemma A.3 to{a j}M+1 j=0 with horizonMgives min 1≤j≤M aj+1 Pj ℓ=1 aℓ ≤ 1 M aM+1 a0 1/M log e aM+1 a0 . Fork=s+j, we have kX i=1 ¯ri ≥ kX i=s+1 ¯ri = jX ℓ=1 aℓ,¯r k+1 =a j+1. Therefore, min s+1≤k≤T ¯rk+1 Pk i=1 ¯ri ≤ 1 M ¯rT+1 ¯rs 1/M log e¯rT+1 ¯rs . SinceM≥T /2,¯r s ≥¯r0, and¯rT+1 ≥¯r0, the right-hand side is at most 2 T ¯rT+1 ¯r0 2/T log e¯rT+1...
work page 2025
-
[9]
28 RemarkC.5 (What is distance-free?).The algorithm never receives D=∥x 0 −x ⋆∥ as an input
Thus f(x T )−f ⋆ = eO LD2 T , D=∥x 0 −x ⋆∥, with constants depending only onα, ρ, λ, andM, but not onD.Q.E.D. 28 RemarkC.5 (What is distance-free?).The algorithm never receives D=∥x 0 −x ⋆∥ as an input. The proof uses D only as a hidden comparator radius in the scalar search. The scalar proxy dk is a D-adaptation-style lower certificate and is used only t...
-
[10]
DF-Muon cap diagnostic.We then ran a matched regularized 100-epoch one-seed diagnostic for DF-Muon, varying only the cap ηmax. Table 10 reports the result. The cap ηmax = 0.01 gives the best top-1 accuracy among the DF-Muon variants, while remaining close to the tuned fixed-Muon baseline in best validation cross-entropy. We therefore useη max = 0.01in the...
work page 2000
-
[11]
We report mean ± standard deviation over seeds {42,1337,2024}
Table 7: NanoGPT/WikiText-2 results over three seeds for the updated majorized DF-Muon im- plementation. We report mean ± standard deviation over seeds {42,1337,2024} . The fixed-Muon baseline usesη= 0.015; adaptive Muon variants useη max = 0.03. Method Train loss Val. loss Mean baseη AdamW5.5576±0.0163 5.7926±0.0339 0.0010 Best fixed Muon5.4489±0.0196 5....
-
[12]
The Muon-based methods reduce training cross-entropy much faster than AdamW. Among the Muon variants, the adaptive methods remain close to the tuned fixed-Muon baseline throughout training. 33 0 200 400 600 800 1000 optimizer step 6 7 8 9 10 11smoothed train loss AdamW Muon DF-Muon DA-Muon SC-Muon (a) Training loss 0 200 400 600 800 1000 optimizer step 6 ...
work page 2016
-
[13]
Table 9: Fixed-Muon learning-rate diagnostic on ViT-Tiny/CIFAR-100 for one representative seed
The fixed-Muon baseline uses η= 0.015 , DA-Muon saturates the cap ηmax = 0.03, SC-Muon stabilizes around 0.02, and DF-Muon follows a conservative-then-increasing scale trajec- tory. Table 9: Fixed-Muon learning-rate diagnostic on ViT-Tiny/CIFAR-100 for one representative seed. CIFAR-100 images are resized to224×224 . Runtime is reported relative to the re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.