Rotation-Aligned Key Channel Pruning for Efficient Vision-Language Model Inference
Pith reviewed 2026-05-20 07:39 UTC · model grok-4.3
The pith
RotateK aligns token-varying key channel importances via online PCA rotation so that lightweight head-wise masks can prune them accurately while preserving visual tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We resolve this with RotateK, a rotation-based structured Key channel pruning framework. RotateK applies an online PCA-based rotation that aligns token-dependent channel importance into a shared low-dimensional subspace, enabling accurate pruning under lightweight head-wise masks; a fused Triton attention kernel operates directly on sparse-channel Keys for efficient decoding. Experiments on two representative VLM backbones show that RotateK consistently outperforms prior Key channel pruning in both accuracy and decoding latency, while joint token-channel pruning improves over token-only baselines at matched KV cache budgets.
What carries the argument
online PCA-based rotation that aligns token-dependent channel importance into a shared low-dimensional subspace
If this is right
- Joint token-channel pruning outperforms token-only baselines at identical KV cache budgets.
- Decoding runs faster because the fused kernel processes sparse-channel keys directly.
- More visual tokens remain available without raising memory usage by shifting budget from tokens to channels.
- Accuracy holds better on fine-grained tasks than with prior unstructured or plain head-wise key pruning.
Where Pith is reading between the lines
- The same rotation alignment could apply to other attention-heavy models where per-token channel importance also varies.
- If the shared subspace remains stable at larger model scales, the approach would support longer context windows without proportional cache growth.
Load-bearing premise
An online PCA-based rotation can reliably align token-dependent channel importance into a shared low-dimensional subspace across varying inputs, models, and tasks.
What would settle it
Run head-wise key pruning on fine-grained VLM perception tasks both with and without the online PCA rotation; if the rotated version shows no accuracy improvement or higher degradation at the same sparsity level, the alignment claim does not hold.
Figures

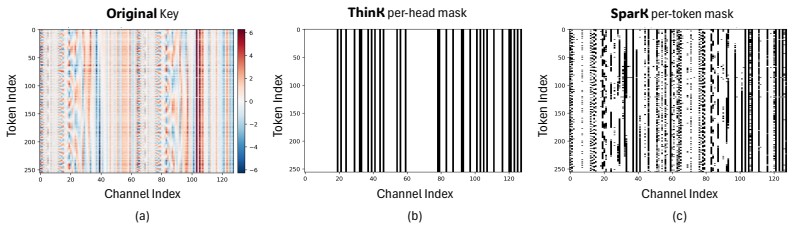





read the original abstract
Vision-Language Models suffer severe KV cache pressure at inference, as a single image often encodes into thousands of tokens. Most existing methods exploit token sparsity through token pruning, but permanently discarding visual content causes substantial degradation on fine-grained perception tasks. This motivates a complementary axis, feature sparsity: under a fixed KV cache budget, compressing the channel dimension preserves more visual tokens at the same memory cost. Prior Key channel pruning methods, however, face a structural trade-off: token-wise channel pruning is expressive but unstructured and slow, while head-wise approach is hardware-friendly but less robust. We resolve this with RotateK, a rotation-based structured Key channel pruning framework. RotateK applies an online PCA-based rotation that aligns token-dependent channel importance into a shared low-dimensional subspace, enabling accurate pruning under lightweight head-wise masks; a fused Triton attention kernel operates directly on sparse-channel Keys for efficient decoding. Experiments on two representative VLM backbones show that RotateK consistently outperforms prior Key channel pruning in both accuracy and decoding latency, while joint token-channel pruning improves over token-only baselines at matched KV cache budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RotateK, a rotation-based structured Key channel pruning framework for Vision-Language Models to mitigate KV cache pressure during inference. RotateK utilizes an online PCA-based rotation to align token-dependent channel importances into a shared low-dimensional subspace, facilitating accurate pruning with lightweight head-wise masks. A fused Triton attention kernel is introduced to handle sparse-channel Keys efficiently. Experiments on two representative VLM backbones indicate that RotateK outperforms prior Key channel pruning methods in both accuracy and decoding latency, with additional benefits from joint token-channel pruning at matched KV cache budgets.
Significance. Should the online PCA rotation prove effective in creating a stable shared subspace, this work would provide a valuable complementary strategy to token pruning for preserving visual content in VLMs under memory constraints. The structured, hardware-friendly pruning and custom kernel implementation represent practical advances for efficient multimodal model deployment.
major comments (2)
- [§3.2] §3.2 (online PCA rotation description): the central assumption that this rotation reliably aligns token-dependent channel importances into one shared low-dimensional subspace across token distributions and modalities lacks quantitative support; the manuscript should report explained-variance ratios post-rotation and subspace stability metrics (e.g., principal-component variation between visual and textual tokens) to validate that head-wise masks incur no substantial information loss.
- [§4] §4 (experiments) and Table 1: while consistent outperformance is claimed on two backbones, the absence of ablations isolating the rotation's contribution, error bars across runs, or sensitivity analysis to input modality mix makes it difficult to assess whether the reported accuracy-latency gains are robust or load-bearing for the framework's novelty.
minor comments (2)
- [§3] The notation for the rotation matrix and head-wise mask application could be clarified with an explicit equation reference in the method section to improve readability.
- Consider expanding the related-work discussion to include more recent KV-cache compression techniques for VLMs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (online PCA rotation description): the central assumption that this rotation reliably aligns token-dependent channel importances into one shared low-dimensional subspace across token distributions and modalities lacks quantitative support; the manuscript should report explained-variance ratios post-rotation and subspace stability metrics (e.g., principal-component variation between visual and textual tokens) to validate that head-wise masks incur no substantial information loss.
Authors: We agree that additional quantitative evidence would strengthen the validation of the rotation step. In the revised manuscript we will report explained-variance ratios after the online PCA rotation together with subspace stability metrics, including principal-component variation between visual and textual tokens. These results will directly show that head-wise masks preserve information with negligible loss across modalities. revision: yes
-
Referee: [§4] §4 (experiments) and Table 1: while consistent outperformance is claimed on two backbones, the absence of ablations isolating the rotation's contribution, error bars across runs, or sensitivity analysis to input modality mix makes it difficult to assess whether the reported accuracy-latency gains are robust or load-bearing for the framework's novelty.
Authors: We acknowledge the benefit of further experimental controls. The revised version will add ablations that isolate the rotation's contribution, include error bars computed over multiple runs, and provide sensitivity analysis across different visual-textual modality ratios. These additions will clarify the robustness of the observed gains and the role of the rotation within the overall framework. revision: yes
Circularity Check
No circularity: method applies standard PCA to pruning without reducing claims to inputs by construction
full rationale
The paper introduces RotateK as a practical framework that applies an online PCA-based rotation to align token-dependent channel importance for head-wise Key pruning in VLMs, followed by a fused Triton kernel. No equations, derivations, or load-bearing steps are shown that define a quantity in terms of itself, rename a fitted parameter as a prediction, or rely on self-citation chains for uniqueness or ansatz. The approach builds on established PCA and structured pruning techniques with external validation through experiments on VLM backbones; the central claim of improved accuracy-latency trade-off is presented as an empirical outcome rather than a self-referential reduction. This is the expected non-finding for an applied systems paper whose contributions are algorithmic and implementation-driven.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Online PCA-based rotation aligns token-dependent channel importance into a shared low-dimensional subspace
invented entities (1)
-
RotateK framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Llavanext: Improved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llavanext: Improved reasoning, ocr, and world knowledge, 2024
work page 2024
-
[2]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021
work page 2021
-
[5]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
work page 2016
-
[6]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35:2507–2521, 2022
work page 2022
-
[8]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 5971–5984, 2024
work page 2024
-
[9]
Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025
work page 2025
-
[10]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spatiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Longvila: Scaling long-context visual language models for long videos
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context visual language models for long videos. In The Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[13]
Dezhan Tu, Danylo Vashchilenko, Yuzhe Lu, and Panpan Xu. Vl-cache: Sparsity and modality-aware kv cache compression for vision-language model inference acceleration.arXiv preprint arXiv:2410.23317, 2024
-
[14]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[16]
Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, and Li Yuan. Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4065–4078, 2024
work page 2024
-
[17]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025. 10
work page 2025
-
[18]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
work page 2025
-
[19]
Sparsevila: Decoupling visual sparsity for efficient vlm inference
Samir Khaki, Junxian Guo, Jiaming Tang, Shang Yang, Yukang Chen, Konstantinos N Plataniotis, Yao Lu, Song Han, and Zhijian Liu. Sparsevila: Decoupling visual sparsity for efficient vlm inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 23784–23794, 2025
work page 2025
-
[20]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22128–22136, 2025
work page 2025
-
[21]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
work page 2022
-
[22]
Ocrbench: on the hidden mystery of ocr in large multimodal models
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences, 67(12):220102, 2024
work page 2024
-
[23]
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models.Advances in Neural Information Processing Systems, 37:121475–121499, 2024
work page 2024
-
[24]
Think: Thinner key cache by query-driven pruning.arXiv preprint arXiv:2407.21018, 2024
Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Aojun Zhou, Amrita Saha, Caiming Xiong, and Doyen Sahoo. Think: Thinner key cache by query-driven pruning.arXiv preprint arXiv:2407.21018, 2024
-
[25]
Spark: Query-aware unstructured sparsity with recoverable kv cache channel pruning
Huanxuan Liao, Yixing Xu, Shizhu He, Guanchen Li, Xuanwu Yin, Dong Li, Emad Barsoum, Jun Zhao, and Kang Liu. Spark: Query-aware unstructured sparsity with recoverable kv cache channel pruning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31961–31969, 2026
work page 2026
-
[26]
Leank: Learnable k cache channel pruning for efficient decoding
Yike Zhang, Zhiyuan He, Huiqiang Jiang, Chengruidong Zhang, Yuqing Yang, Jianyong Wang, and Lili Qiu. Leank: Learnable k cache channel pruning for efficient decoding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 31110–31125, 2025
work page 2025
-
[27]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Kvquant: Towards 10 million context length llm inference with kv cache quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization. Advances in Neural Information Processing Systems, 37:1270–1303, 2024
work page 2024
-
[29]
Federico Barbero, Alex Vitvitskyi, Christos Perivolaropoulos, Razvan Pascanu, and Petar Veli ˇckovi´c. Round and round we go! what makes rotary positional encodings useful?arXiv preprint arXiv:2410.06205, 2024
-
[30]
Ye Qiao, Haocheng Xu, Xiaofan Zhang, and Sitao Huang. Rethinking rope scaling in quantized llm: Theory, outlier, and channel-band analysis with weight rescaling.arXiv preprint arXiv:2510.00028, 2025
-
[31]
Lmms-eval: Reality check on the evaluation of large multimodal models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 881–916, 2025
work page 2025
-
[32]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
work page 2025
-
[33]
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20857–20867, 2025
work page 2025
-
[34]
Jintao Tong, Wenwei Jin, Pengda Qin, Anqi Li, Yixiong Zou, Yuhong Li, Yuhua Li, and Ruixuan Li. Flowcut: Rethinking redundancy via information flow for efficient vision-language models.arXiv preprint arXiv:2505.19536, 2025. 11
-
[35]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Multi-stage vision token dropping: Towards efficient multimodal large language model
Ting Liu, Liangtao Shi, Richang Hong, Yue Hu, Quanjun Yin, and Linfeng Zhang. Multi-stage vision token dropping: Towards efficient multimodal large language model.arXiv preprint arXiv:2411.10803, 2024
-
[37]
Post-training sparse attention with double sparsity.arXiv preprint arXiv:2408.07092, 2024
Shuo Yang, Ying Sheng, Joseph E Gonzalez, Ion Stoica, and Lianmin Zheng. Post-training sparse attention with double sparsity.arXiv preprint arXiv:2408.07092, 2024
-
[38]
Quarot: Outlier-free 4-bit inference in rotated llms
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. Advances in Neural Information Processing Systems, 37:100213–100240, 2024
work page 2024
-
[39]
SpinQuant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. Duquant: Distributing outliers via dual transformation makes stronger quantized llms. Advances in Neural Information Processing Systems, 37:87766–87800, 2024
work page 2024
-
[41]
Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, et al. Flatquant: Flatness matters for llm quantization.arXiv preprint arXiv:2410.09426, 2024
-
[42]
Slicegpt: Compress large language models by deleting rows and columns
Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari Do Nascimento, Torsten Hoefler, and James Hensman. Slicegpt: Compress large language models by deleting rows and columns. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[43]
Palu: Compressing kv-cache with low-rank projection.arXiv preprint arXiv:2407.21118,
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S Abdelfattah, and Kai-Chiang Wu. Palu: Compressing kv-cache with low-rank projection.arXiv preprint arXiv:2407.21118, 2024
-
[44]
MatryoshkaKV: Adaptive KV compression via trainable orthogonal projection
Bokai Lin, Zihao Zeng, Zipeng Xiao, Siqi Kou, Tianqi Hou, Xiaofeng Gao, Hao Zhang, and Zhijie Deng. Matryoshkakv: Adaptive kv compression via trainable orthogonal projection.arXiv preprint arXiv:2410.14731, 2024. 12 A Related Works A.1 Visual Token Pruning Token-axis compression of the visual KV cache falls into two regimes. Pre-LLM methods, exemplified b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.