Spectral Integrated Gradients for Coarse-to-Fine Feature Attribution
Pith reviewed 2026-05-20 05:27 UTC · model grok-4.3
pith:GEHZLP3C Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{GEHZLP3C}
Prints a linked pith:GEHZLP3C badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
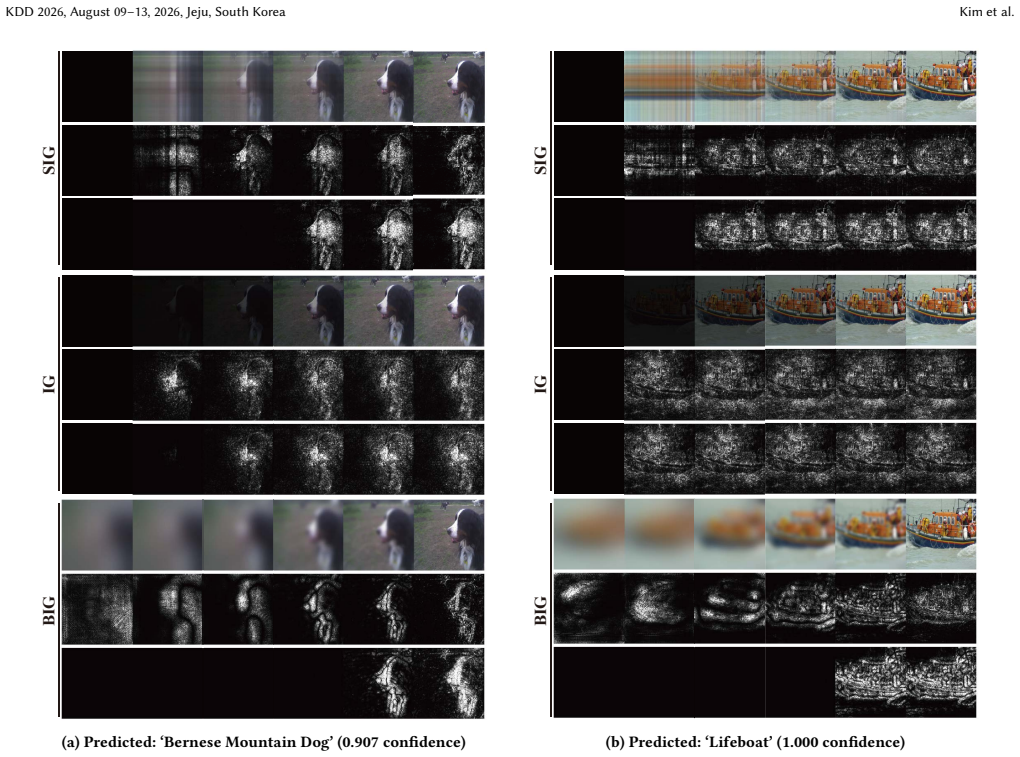
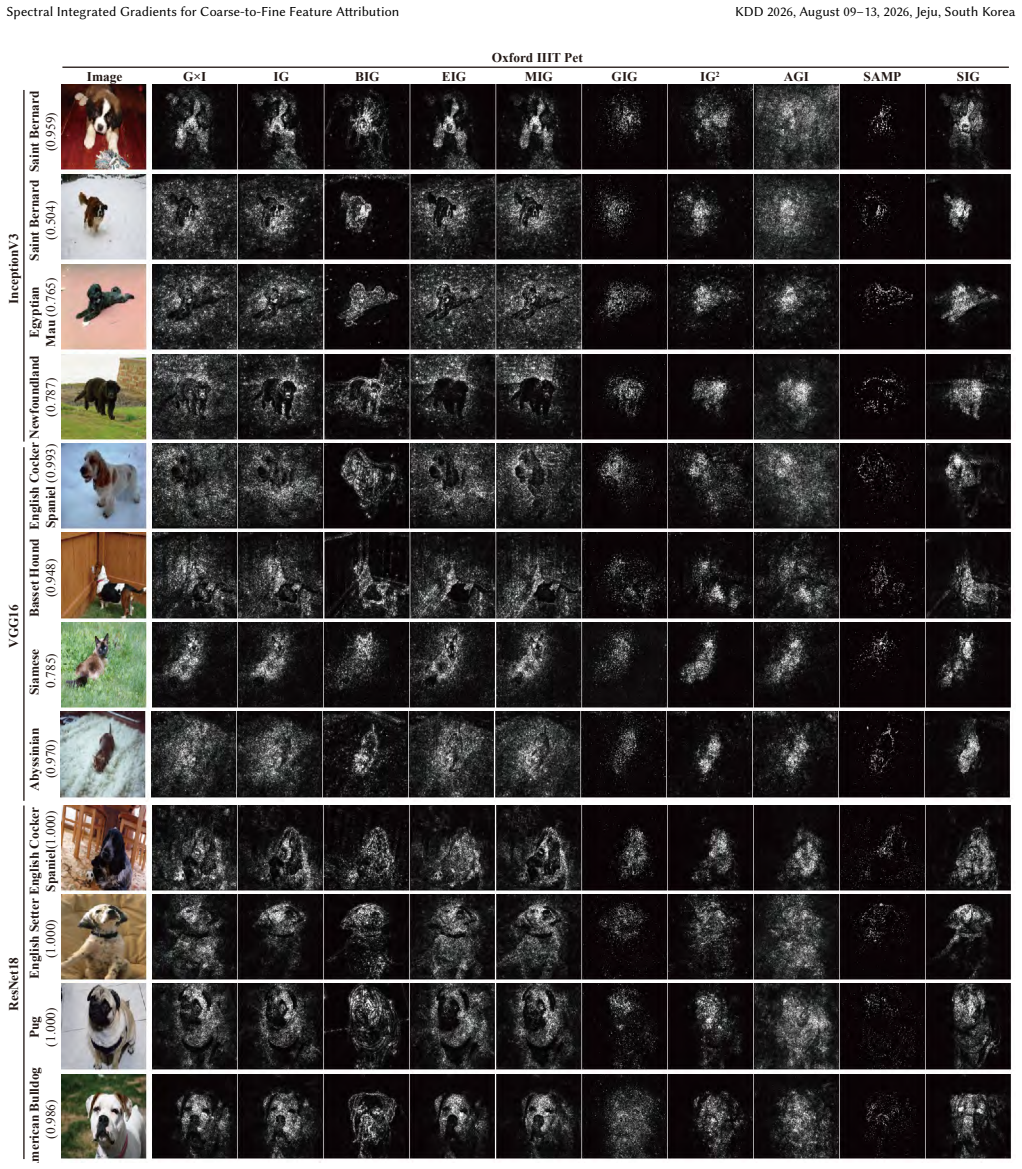
Spectral Integrated Gradients builds integration paths via SVD to introduce global structure before fine details, yielding cleaner attributions than straight-line paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
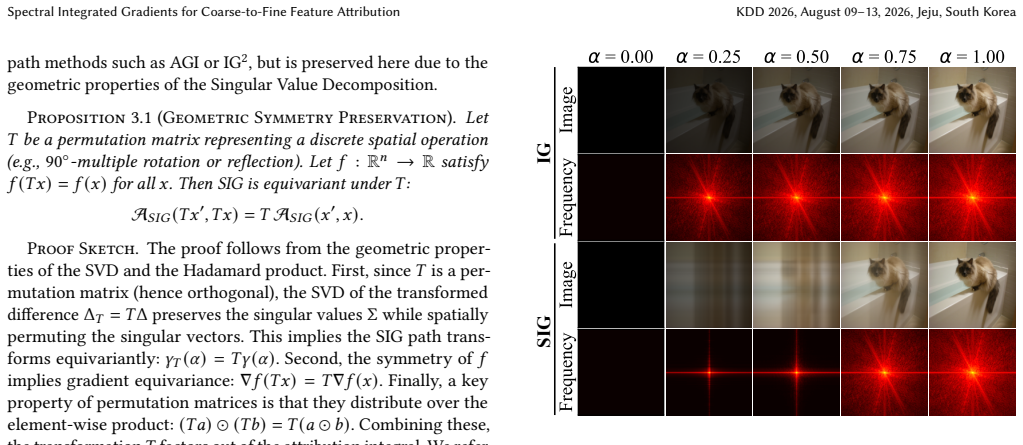
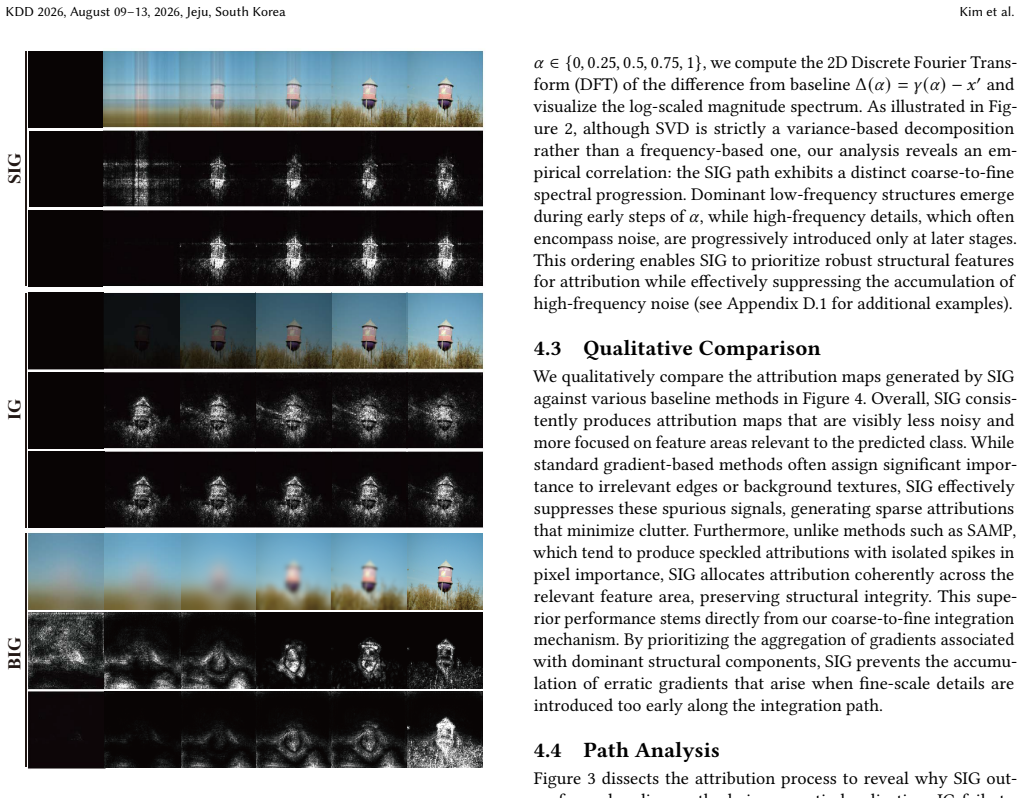
Integrated Gradients satisfies its axiomatic properties for any integration path, yet the conventional straight-line path from baseline to input activates every feature simultaneously and therefore collects noisy gradients along the way. Spectral Integrated Gradients replaces that path with one derived from the singular value decomposition of the baseline-to-input difference: the path is parameterized so that singular components are added in descending order of singular value. The resulting attributions therefore receive global structure before fine-grained details, producing maps with visibly reduced noise and higher quantitative scores on standard image-classification benchmarks while the
What carries the argument
Spectral Integrated Gradients, which constructs the integration path by ordering singular components from largest to smallest singular value so that global structure precedes fine details.
If this is right
- Attribution maps exhibit visibly lower noise levels on image data.
- Quantitative metrics for attribution quality improve over existing path-based baselines.
- Axiomatic guarantees of Integrated Gradients remain intact under the new path choice.
- The coarse-to-fine ordering applies across diverse image classification datasets without retraining.
- The method requires only an SVD on the input-baseline difference and no change to the underlying model.
Where Pith is reading between the lines
- The same SVD ordering idea could be tested on non-image domains where a natural low-rank decomposition exists.
- If the singular-value ordering aligns with human visual perception, it might explain why certain explanations feel more intuitive.
- Future work could compare the learned singular directions against known dataset biases or model failure modes.
- The approach suggests that other path-based methods might also benefit from ordering features by some measure of global importance rather than uniform activation.
Load-bearing premise
Ordering singular components from largest to smallest singular value will reduce noise and improve attribution quality without introducing new artifacts or violating the axiomatic properties of Integrated Gradients.
What would settle it
If quantitative noise metrics and performance scores on standard image datasets show no consistent improvement over straight-line Integrated Gradients or other path variants, the central claim would be falsified.
Figures





read the original abstract
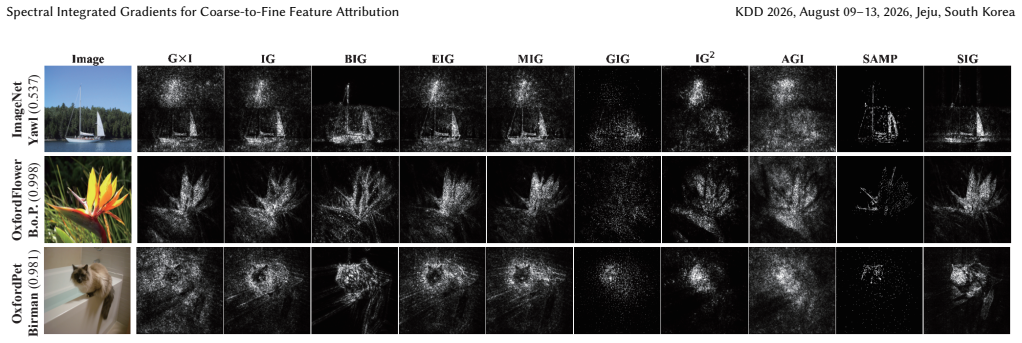
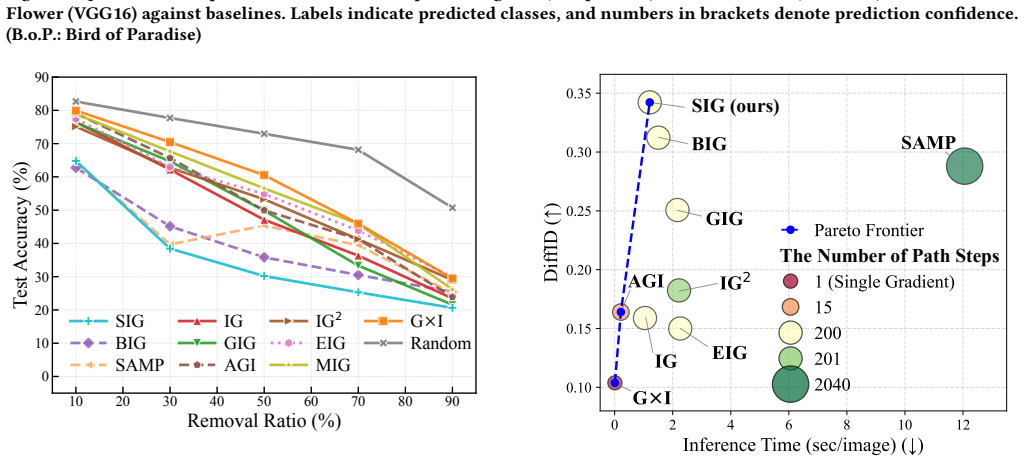
Integrated Gradients (IG) is a widely adopted feature attribution method that satisfies desirable axiomatic properties. However, the choice of integration path significantly affects the quality of attributions, and the standard straight-line path introduces all input features simultaneously, often accumulating noisy gradients along the way. To address this limitation, we propose Spectral Integrated Gradients, which constructs integration paths based on singular value decomposition (SVD) of the baseline-to-input difference. By progressively activating singular components from largest to smallest, SIG introduces global structure before fine-grained details, naturally following a coarse-to-fine progression. Through extensive evaluation across diverse image classification datasets, we demonstrate that SIG produces cleaner attribution maps with reduced noise and achieves improved quantitative performance compared to existing path-based attribution methods. Our code is available at https://github.com/leekwoon/sig/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spectral Integrated Gradients (SIG), a path-based variant of Integrated Gradients for feature attribution in image classification models. SIG constructs the integration path by applying SVD to the baseline-to-input difference and progressively activating singular components ordered from largest to smallest singular value, aiming for a coarse-to-fine progression that reduces noise compared to the standard straight-line path. The authors report that this yields cleaner attribution maps and improved quantitative performance across diverse datasets, with code released for reproducibility.
Significance. If the central claims hold, SIG could provide a practical enhancement to attribution quality in computer vision without violating IG axioms, potentially aiding interpretability of CNNs. The open-source code is a clear strength for reproducibility and further testing.
major comments (3)
- [§3] §3 (Path Construction): The SVD-based path must be explicitly shown to be a continuous, differentiable curve parameterized by a single scalar t ∈ [0,1] from baseline (zero components) to full input. It is unclear whether the progressive activation of singular components (largest to smallest) forms a monotonic trajectory that satisfies the fundamental theorem of calculus underlying the IG proof, or if it introduces piecewise behavior or interpolation artifacts.
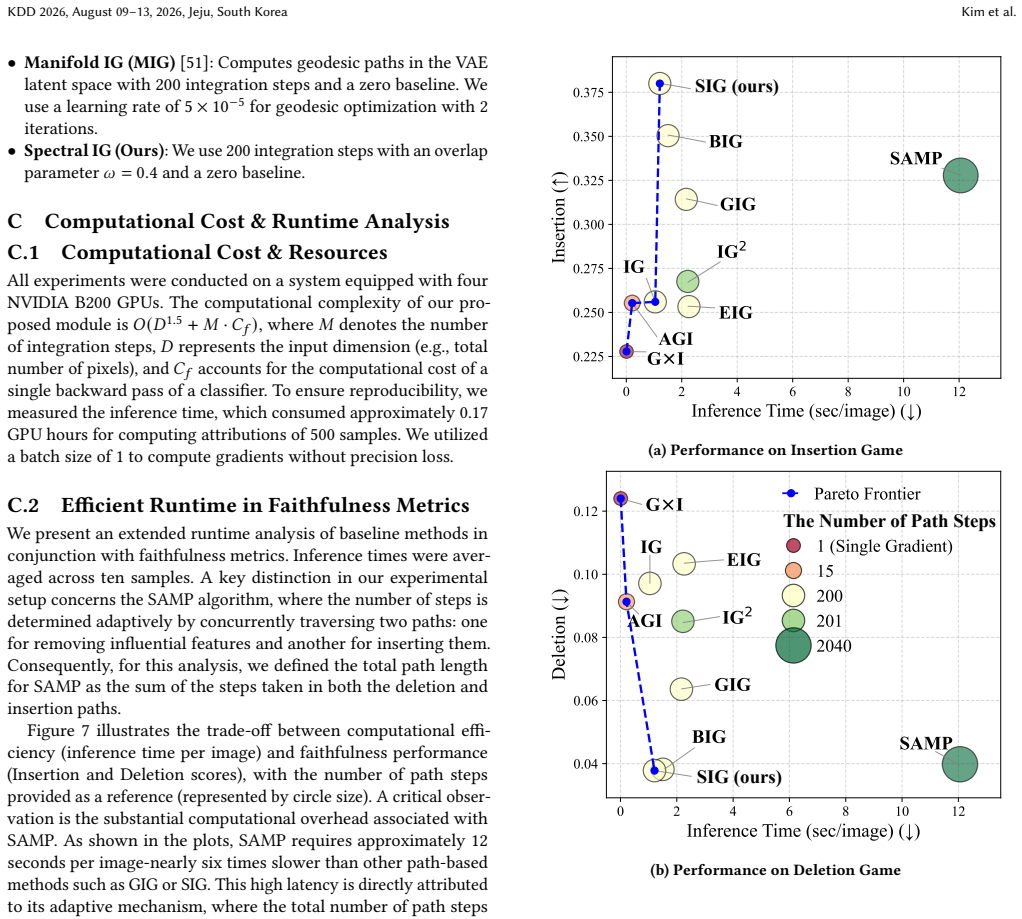
- [§4 or §5] §4 or §5 (Evaluation): The claim of improved quantitative performance and reduced noise requires concrete metrics (e.g., insertion/deletion scores, faithfulness metrics), statistical tests, dataset names/sizes, and direct comparisons to baselines such as standard IG and other path variants. The abstract asserts superiority after 'extensive evaluation' but the provided details do not allow verification of effect sizes or controls for path-dependent biases.
- [Axioms discussion] Axioms section: Completeness (sum of attributions equals f(x) − f(baseline)) must be verified numerically for the SVD path, as any deviation from a valid IG curve could make attributions incomplete or path-dependent in uncontrolled ways. The paper should include a proof sketch or empirical check that the ordering from largest to smallest singular values preserves this property.
minor comments (2)
- [Abstract] Abstract: Briefly list the specific datasets and at least one quantitative metric to support the performance claim, improving readability for readers scanning the paper.
- [Method] Notation: Define the parameterization of the SVD path (e.g., how components are scaled with t) with an equation early in the method section to avoid ambiguity in later derivations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each of the major comments point by point below, providing clarifications and indicating revisions where necessary to strengthen the presentation of Spectral Integrated Gradients.
read point-by-point responses
-
Referee: [§3] §3 (Path Construction): The SVD-based path must be explicitly shown to be a continuous, differentiable curve parameterized by a single scalar t ∈ [0,1] from baseline (zero components) to full input. It is unclear whether the progressive activation of singular components (largest to smallest) forms a monotonic trajectory that satisfies the fundamental theorem of calculus underlying the IG proof, or if it introduces piecewise behavior or interpolation artifacts.
Authors: We appreciate the referee's emphasis on rigorously defining the integration path. In the original manuscript, Section 3 describes the construction via SVD and progressive activation, but we acknowledge that the explicit parameterization as a function of t could be stated more formally. In the revised manuscript, we will add the definition of the path γ(t) for t ∈ [0,1] as a continuous curve in the spectral domain that monotonically activates components from largest to smallest singular value. This construction ensures differentiability and satisfies the conditions for the path integral underlying Integrated Gradients, with a derivation showing that the fundamental theorem of calculus holds without introducing piecewise artifacts or uncontrolled interpolation. revision: yes
-
Referee: [§4 or §5] §4 or §5 (Evaluation): The claim of improved quantitative performance and reduced noise requires concrete metrics (e.g., insertion/deletion scores, faithfulness metrics), statistical tests, dataset names/sizes, and direct comparisons to baselines such as standard IG and other path variants. The abstract asserts superiority after 'extensive evaluation' but the provided details do not allow verification of effect sizes or controls for path-dependent biases.
Authors: We agree that additional concrete details on the evaluation protocol would improve verifiability. The manuscript reports results across multiple image classification datasets with quantitative comparisons to standard Integrated Gradients and other path-based methods, including metrics such as insertion and deletion scores. To address the concern directly, we will revise the evaluation section to include an expanded summary table with dataset sizes, specific metric values, and controls for path-dependent effects, allowing clearer assessment of the reported improvements. revision: yes
-
Referee: [Axioms discussion] Axioms section: Completeness (sum of attributions equals f(x) − f(baseline)) must be verified numerically for the SVD path, as any deviation from a valid IG curve could make attributions incomplete or path-dependent in uncontrolled ways. The paper should include a proof sketch or empirical check that the ordering from largest to smallest singular values preserves this property.
Authors: We thank the referee for this observation on axiomatic guarantees. For any continuous path connecting the baseline to the input, completeness follows directly from the fundamental theorem of calculus applied to the gradient integral, independent of the particular ordering of singular components. The SVD ordering shapes the trajectory but preserves path validity. In the revised manuscript, we will add a short proof sketch to the axioms discussion and include numerical verification in the experiments section confirming that attribution sums match f(x) − f(baseline) within floating-point precision. revision: yes
Circularity Check
No circularity: SIG path is independently defined and evaluated empirically
full rationale
The paper defines Spectral Integrated Gradients by constructing an integration path via SVD decomposition of the baseline-to-input difference and ordering singular components from largest to smallest. This construction is presented as a direct proposal to achieve coarse-to-fine progression, independent of any evaluation outcomes or fitted parameters. The claimed improvements in attribution quality are supported solely by empirical results across image classification datasets, not by any reduction of the method to its own inputs or self-referential definitions. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked in the provided text to justify the central path choice. The derivation chain remains self-contained against external benchmarks, with the path definition standing apart from the quantitative performance claims.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By progressively activating singular components from largest to smallest, SIG introduces global structure before fine-grained details... Δ∗(α) = sum_{i=1}^{k(α)} σ_i u_i v_i^T (Eq. 5)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SIG path: γ_SIG(α) = x' + sum ϕ_i(α;ω) σ_i u_i v_i^T with overlap gating (Eq. 8)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. 2018. Sanity checks for saliency maps.Advances in neural information processing systems31 (2018)
work page 2018
-
[2]
Julius Adebayo, Michael Muelly, Ilaria Liccardi, and Been Kim. 2020. Debugging Tests for Model Explanations.Advances in Neural Information Processing Systems 33 (2020), 700–712
work page 2020
-
[3]
Christopher J Anders, Leander Weber, David Neumann, Wojciech Samek, Klaus- Robert Müller, and Sebastian Lapuschkin. 2022. Finding and removing clever hans: Using explanation methods to debug and improve deep models.Information Fusion77 (2022), 261–295
work page 2022
-
[4]
1974.Values of non-atomic games
Robert J Aumann and Lloyd S Shapley. 1974.Values of non-atomic games. Prince- ton University Press
work page 1974
-
[5]
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. 2015. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one10, 7 (2015), e0130140
work page 2015
-
[6]
Long Chen, Shaobo Lin, Xiankai Lu, Dongpu Cao, Hangbin Wu, Chi Guo, Chun Liu, and Fei-Yue Wang. 2021. Deep neural network based vehicle and pedestrian detection for autonomous driving: A survey.IEEE Transactions on Intelligent Transportation Systems22, 6 (2021), 3234–3246
work page 2021
-
[7]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255
work page 2009
-
[8]
Carl Eckart and Gale Young. 1936. The approximation of one matrix by another of lower rank.Psychometrika1, 3 (1936), 211–218
work page 1936
-
[9]
Thomas Fel, Rémi Cadène, Mathieu Chalvidal, Matthieu Cord, David Vigouroux, and Thomas Serre. 2021. Look at the variance! efficient black-box explanations with sobol-based sensitivity analysis.Advances in neural information processing systems34 (2021), 26005–26014
work page 2021
- [10]
-
[11]
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. 2020. Shortcut learn- ing in deep neural networks.Nature Machine Intelligence2, 11 (2020), 665–673
work page 2020
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. IEEE, 770–778
work page 2016
-
[13]
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. 2019. A benchmark for interpretability methods in deep neural networks.Advances in neural information processing systems32 (2019)
work page 2019
-
[14]
Giyoung Jeon, Haedong Jeong, and Jaesik Choi. 2022. Distilled gradient aggrega- tion: Purify features for input attribution in the deep neural network.Advances in Neural Information Processing Systems35 (2022), 26478–26491
work page 2022
-
[15]
Giyoung Jeon, Haedong Jeong, and Jaesik Choi. 2023. Beyond Single Path Inte- grated Gradients for Reliable Input Attribution via Randomized Path Sampling. InProceedings of the IEEE/CVF International Conference on Computer Vision. 2052– 2061
work page 2023
-
[16]
Anupama Jha, Joseph K. Aicher, Matthew R. Gazzara, Deependra Singh, and Yoseph Barash. 2020. Enhanced integrated gradients: improving interpretability of deep learning models using splicing codes as a case study.Genome biology21, 1 (2020), 149
work page 2020
-
[17]
Andrei Kapishnikov, Subhashini Venugopalan, Besim Avci, Ben Wedin, Michael Terry, and Tolga Bolukbasi. 2021. Guided integrated gradients: An adaptive path method for removing noise. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5050–5058
work page 2021
-
[18]
Gabriel Kasmi, Amandine Brunetto, Thomas Fel, and Jayneel Parekh. 2025. One Wave To Explain Them All: A Unifying Perspective On Feature Attribution. In Forty-second International Conference on Machine Learning
work page 2025
-
[19]
Soyeon Kim, Junho Choi, Yeji Choi, Subeen Lee, Artyom Stitsyuk, Minkyoung Park, Seongyeop Jeong, You-Hyun Baek, and Jaesik Choi. 2023. Explainable AI- based interface system for weather forecasting model. InInternational Conference on Human-Computer Interaction. Springer, 101–119
work page 2023
-
[20]
Soyeon Kim, Seongwoo Lim, Kyowoon Lee, and Jaesik Choi. 2026. Manifold- Aligned Guided Integrated Gradients for Reliable Feature Attribution. InPro- ceedings of the 43rd International Conference on Machine Learning (ICML). arXiv:2605.02167 https://arxiv.org/abs/2605.02167
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Pieter-Jan Kindermans, Sara Hooker, Julius Adebayo, Maximilian Alber, Kristof T Schütt, Sven Dähne, Dumitru Erhan, and Been Kim. 2019. The (un) reliability of saliency methods.Explainable AI: Interpreting, explaining and visualizing deep learning(2019), 267–280
work page 2019
-
[22]
Sebastian Lapuschkin, Stephan Wäldchen, Alexander Binder, Grégoire Montavon, Wojciech Samek, and Klaus-Robert Müller. 2019. Unmasking Clever Hans pre- dictors and assessing what machines really learn.Nature communications10, 1 (2019), 1096
work page 2019
- [23]
-
[24]
Kyowoon Lee and Jaesik Choi. 2025. State-Covering Trajectory Stitching for Diffusion Planners. InThirty-ninth Conference on Neural Information Processing Systems (NeurIPS)
work page 2025
-
[25]
Kyowoon Lee, Seongun Kim, and Jaesik Choi. 2023. Adaptive and explainable deployment of navigation skills via hierarchical deep reinforcement learning. In2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 11608–11614
work page 2023
-
[26]
Kyowoon Lee, Seongun Kim, and Jaesik Choi. 2023. Refining Diffusion Planner for Reliable Behavior Synthesis by Automatic Detection of Infeasible Plans. In Advances in Neural Information Processing Systems (NeurIPS)
work page 2023
-
[27]
Kyowoon Lee, Yunhao Luo, Anh Tong, and Jaesik Choi. 2026. Refining Compositional Diffusion for Reliable Long-Horizon Planning.arXiv preprint arXiv:2605.03075(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Yiming Lei, Zilong Li, Junping Zhang, and Hongming Shan. 2024. Denoising diffusion path: Attribution noise reduction with an auxiliary diffusion model. Advances in Neural Information Processing Systems37 (2024), 54003–54025
work page 2024
-
[29]
Scott M Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. InAdvances in Neural Information Processing Systems (NeurIPS)
work page 2017
-
[30]
2016.TorchVision: PyTorch’s Computer Vision library
TorchVision maintainers and contributors. 2016.TorchVision: PyTorch’s Computer Vision library
work page 2016
-
[31]
Grégoire Montavon, Alexander Binder, Sebastian Lapuschkin, Wojciech Samek, and Klaus-Robert Müller. 2019. Layer-wise relevance propagation: an overview. Explainable AI: interpreting, explaining and visualizing deep learning(2019), 193– 209
work page 2019
-
[32]
Maria-Elena Nilsback and Andrew Zisserman. 2008. Automated flower classifica- tion over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing. IEEE, 722–729
work page 2008
-
[33]
Deng Pan, Xin Li, and Dongxiao Zhu. 2021. Explaining deep neural network models with adversarial gradient integration. InThirtieth International Joint Conference on Artificial Intelligence (IJCAI)
work page 2021
-
[34]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. 2012. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition. IEEE, 3498–3505
work page 2012
-
[35]
Vitali Petsiuk, Abir Das, and Kate Saenko. 2018. RISE: Randomized Input Sampling for Explanation of Black-box Models. InProceedings of the British Machine Vision Conference (BMVC)
work page 2018
-
[36]
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al
-
[37]
InInternational Conference on Learning Representations
SAM 2: Segment Anything in Images and Videos. InInternational Conference on Learning Representations
-
[38]
Marco Túlio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. "Why Should I Trust You?": Explaining the Predictions of Any Classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, Balaji Krishnapuram, Mohak Shah, Alexander J. Smola, Charu C. Aggarwal, Dou ...
-
[39]
Yao Rong, Tobias Leemann, Vadim Borisov, Gjergji Kasneci, and Enkelejda Kas- neci. 2022. A consistent and efficient evaluation strategy for attribution methods. InInternational Conference on Machine Learning. PMLR, 18770–18795
work page 2022
-
[40]
Harshay Shah, Prateek Jain, and Praneeth Netrapalli. 2021. Do input gradients highlight discriminative features?Advances in Neural Information Processing Systems34 (2021), 2046–2059
work page 2021
-
[41]
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. 2017. Learning im- portant features through propagating activation differences. InInternational conference on machine learning. PMlR, 3145–3153
work page 2017
-
[42]
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2014. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. In2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Workshop Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1312.6034
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[43]
Karen Simonyan and Andrew Zisserman. 2015. Very Deep Convolutional Net- works for Large-Scale Image Recognition. InInternational Conference on Learning Representations
work page 2015
-
[44]
SmoothGrad: removing noise by adding noise
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda B. Viégas, and Martin Watten- berg. 2017. SmoothGrad: removing noise by adding noise.CoRRabs/1706.03825 (2017). arXiv:1706.03825 http://arxiv.org/abs/1706.03825
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Striving for Simplicity: The All Convolutional Net
Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, and Martin A. Ried- miller. 2015. Striving for Simplicity: The All Convolutional Net. In3rd Interna- tional Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Workshop Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). Spectral Integrated Gradients for Coars...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[46]
Pascal Sturmfels, Scott Lundberg, and Su-In Lee. 2020. Visualizing the impact of feature attribution baselines.Distill5, 1 (2020), e22
work page 2020
-
[47]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. InInternational conference on machine learning. PMLR, 3319– 3328
work page 2017
-
[48]
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. 2016. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2818–2826
work page 2016
-
[49]
Shawn Xu, Subhashini Venugopalan, and Mukund Sundararajan. 2020. Attribu- tion in scale and space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9680–9689
work page 2020
-
[50]
Peiyu Yang, Naveed Akhtar, Zeyi Wen, and Ajmal Mian. 2023. Local Path Integra- tion for Attribution.Proceedings of the AAAI Conference on Artificial Intelligence 37, 3 (Jun. 2023), 3173–3180. doi:10.1609/aaai.v37i3.25422
-
[51]
Peiyu Yang, Naveed Akhtar, Zeyi Wen, Mubarak Shah, and Ajmal Saeed Mian
-
[52]
InInternational Conference on Learning Representations ICLR
Re-calibrating feature attributions for model interpretation. InInternational Conference on Learning Representations ICLR
-
[53]
Eslam Zaher, Maciej Trzaskowski, Quan Nguyen, and Fred Roosta. 2024. Man- ifold Integrated Gradients: Riemannian Geometry for Feature Attribution. In Proceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Kather- ine Heller, Adrian Weller, Nuria Oliver, ...
work page 2024
-
[54]
Borui Zhang, Wenzhao Zheng, Jie Zhou, and Jiwen Lu. 2024. Path Choice Matters for Clear Attributions in Path Methods. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=gzYgsZgwXa
work page 2024
-
[55]
Jianming Zhang, Sarah Adel Bargal, Zhe Lin, Jonathan Brandt, Xiaohui Shen, and Stan Sclaroff. 2018. Top-Down Neural Attention by Excitation Backprop. International Journal of Computer Vision126, 10 (2018), 1084–1102
work page 2018
-
[56]
mean 3” is the average DiffID across the three baselines (zero, mean, blur), and “range
Yue Zhuo and Zhiqiang Ge. 2024. IG2: Integrated Gradient on Iterative Gradient Path for Feature Attribution .IEEE Transactions on Pattern Analysis & Machine Intelligence46, 11 (2024), 7173–7190. doi:10.1109/TPAMI.2024.3388092 Appendix Contents A Proofs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 B Expe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.