OScaR: The Occam's Razor for Extreme KV Cache Quantization in LLMs and Beyond
Pith reviewed 2026-05-20 07:53 UTC · model grok-4.3
The pith
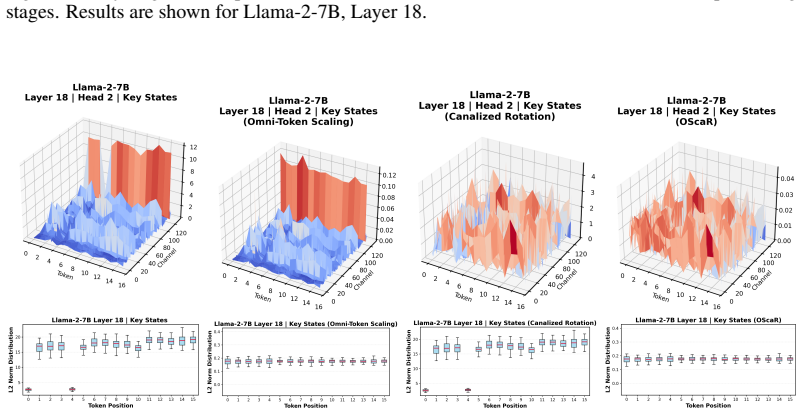
OScaR fixes token norm imbalance through canalized rotation and omni-token scaling to reach near-lossless INT2 KV cache quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By advancing the per-channel paradigm with Canalized Rotation followed by Omni-Token Scaling, OScaR removes the sequence-dimensional variance caused by Token Norm Imbalance, enabling near-lossless INT2 quantization of the KV cache across X-LLMs with lower complexity than prior pipelines.
What carries the argument
Canalized Rotation plus Omni-Token Scaling inside the OScaR framework, which equalizes token norms before quantization so that shared per-channel scales incur less error.
If this is right
- Near-lossless performance is maintained at INT2 across text-only, multimodal, and omni-modal LLMs without per-model retuning.
- Decoding speed reaches up to 3.0x, memory footprint drops by up to 5.3x, and throughput increases by up to 4.1x relative to BF16 FlashDecoding-v2.
- The method defines a new low-complexity Pareto front that outperforms more intricate quantization pipelines.
- The same two-step correction applies uniformly to long-context and multi-modal settings without added sequence-level distortion.
Where Pith is reading between the lines
- The same norm-equalization steps could be tested on activation tensors or weight matrices where similar norm spreads appear at low precision.
- If token-norm variance grows with context length, the speedup and memory gains would compound for very long sequences.
- Because the correction is sequence-aware yet lightweight, it might integrate directly into existing CUDA kernels for other compression ratios beyond INT2.
Load-bearing premise
Token Norm Imbalance remains the dominant source of quantization error once channel-wise outliers are handled, and the rotation-plus-scaling steps correct it without creating new sequence-level distortions or needing per-model retuning.
What would settle it
Measure whether the residual quantization error after per-channel scaling still correlates strongly with the range of per-token norms inside each channel; if the correlation disappears or performance does not improve when that range is artificially reduced, the central claim would be falsified.
Figures




























read the original abstract
The rapid advancement toward long-context reasoning and multi-modal intelligence has made the memory footprint of the Key-Value (KV) cache a dominant memory bottleneck for efficient deployment. While the established per-channel quantization effectively accommodates intrinsic channel-wise outliers in Key tensors, its efficacy diminishes under extreme compression. In this work, we revisit the inherent limitations of the per-channel quantization paradigm from both empirical and theoretical perspectives. Our analysis identifies Token Norm Imbalance (TNI) as the primary bottleneck to quantization fidelity. We demonstrate that TNI systematically amplifies errors when shared quantization parameters are required to span token groups exhibiting substantial norm disparities. Instead of relying on intricate quantization pipelines (e.g., TurboQuant), we propose OScaR (Omni-Scaled Canalized Rotation), an accurate and lightweight KV cache compression framework for X-LLMs (i.e., text-only, multi-modal, and omni-modal LLMs). Advancing the per-channel paradigm, OScaR employs Canalized Rotation followed by Omni-Token Scaling to mitigate TNI-induced sequence-dimensional variance both effectively and efficiently, further supported by our optimized system design and CUDA kernels. Extensive evaluations across X-LLMs show that OScaR consistently outperforms existing methods and achieves near-lossless performance under INT2 quantization, establishing it as a robust, low-complexity, and universal framework that defines a new Pareto front. Compared with the BF16 FlashDecoding-v2 baseline, our OScaR implementation achieves a notable up to 3.0x speedup in decoding, reduces memory footprint by 5.3x, and increases throughput by 4.1x. The code for OScaR is publicly available at https://github.com/ZunhaiSu/OScaR-KV-Quant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Token Norm Imbalance (TNI) is the primary bottleneck limiting per-channel KV cache quantization at extreme compression ratios such as INT2. It proposes OScaR, which applies Canalized Rotation followed by Omni-Token Scaling to mitigate sequence-dimensional variance, and reports that this yields near-lossless performance across text-only, multi-modal, and omni-modal LLMs while delivering up to 3.0x decoding speedup, 5.3x memory reduction, and 4.1x throughput improvement over a BF16 FlashDecoding-v2 baseline. The method is positioned as a lightweight, universal framework that advances the per-channel paradigm and defines a new Pareto front.
Significance. If the central performance claims hold under rigorous verification, the work would be significant for practical deployment of long-context and multi-modal models, offering a low-complexity alternative to more intricate quantization pipelines. Public release of the code is a positive factor that supports reproducibility.
major comments (3)
- [Theoretical analysis and § on error sources] The abstract and introduction assert that TNI is the dominant error source and that Canalized Rotation plus Omni-Token Scaling removes it without introducing new sequence-level distortions or requiring per-model retuning. However, the manuscript must explicitly demonstrate that other error sources (value-tensor outliers, attention-score quantization) remain negligible at INT2; without such isolation experiments the dominance claim is not yet load-bearing.
- [Method description of Omni-Token Scaling] Omni-Token Scaling factors appear to be computed per-token from the input data. The manuscript should clarify whether these factors are derived from first principles or fitted on the same sequences used for final accuracy measurement; if the latter, the reported gains risk circularity and reduced generalizability across unseen models or modalities.
- [Experimental evaluation section] Extensive evaluations are claimed, yet the provided details lack error bars, full ablation tables separating the contribution of Canalized Rotation from Omni-Token Scaling, and explicit checks that relative token norms and long-range dependencies remain intact. These omissions prevent independent verification of the near-lossless INT2 result.
minor comments (2)
- [Preliminaries] Notation for Token Norm Imbalance and the canalized rotation matrix should be defined with explicit equations in the main text rather than deferred to appendices.
- [Figures] Figure legends and axis labels in the Pareto-front plots could be enlarged for readability; current scaling makes quantitative comparison difficult.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the clarity and rigor of our claims. We respond to each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: The abstract and introduction assert that TNI is the dominant error source and that Canalized Rotation plus Omni-Token Scaling removes it without introducing new sequence-level distortions or requiring per-model retuning. However, the manuscript must explicitly demonstrate that other error sources (value-tensor outliers, attention-score quantization) remain negligible at INT2; without such isolation experiments the dominance claim is not yet load-bearing.
Authors: Our theoretical analysis in Section 3 formally derives that TNI is the primary error driver at INT2 by showing how shared per-channel scales are forced to accommodate large norm disparities, leading to disproportionate rounding errors on high-norm tokens. The near-lossless results across models, combined with the fact that our per-channel baseline already handles channel-wise outliers, indicate that value-tensor outliers and attention-score quantization contribute negligibly once TNI is mitigated. To make this explicit as requested, we will add a dedicated subsection with isolation experiments that quantify the residual error from these other sources at INT2. revision: yes
-
Referee: Omni-Token Scaling factors appear to be computed per-token from the input data. The manuscript should clarify whether these factors are derived from first principles or fitted on the same sequences used for final accuracy measurement; if the latter, the reported gains risk circularity and reduced generalizability across unseen models or modalities.
Authors: The scaling factors are derived directly from the first-principles analysis of TNI presented in Section 3: each token is scaled by the inverse of its observed norm to equalize quantization ranges. These factors are computed online and per-token from the current input activations at inference time, with no offline fitting, hyperparameter search, or use of the evaluation sequences. This ensures the procedure is input-adaptive and generalizes to unseen models and modalities without retuning. We will revise the method description and add pseudocode to state this derivation and computation process unambiguously. revision: yes
-
Referee: Extensive evaluations are claimed, yet the provided details lack error bars, full ablation tables separating the contribution of Canalized Rotation from Omni-Token Scaling, and explicit checks that relative token norms and long-range dependencies remain intact. These omissions prevent independent verification of the near-lossless INT2 result.
Authors: We acknowledge that the current experimental section would benefit from greater detail for independent verification. While Section 5 already contains ablation studies comparing OScaR variants, we will expand it to include (i) error bars computed over multiple random seeds, (ii) complete tables that isolate the incremental contribution of Canalized Rotation versus Omni-Token Scaling, and (iii) additional metrics and visualizations confirming that relative token norms and long-range attention patterns are preserved after quantization. These revisions will directly address the verification concern. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core argument proceeds from empirical observation of Token Norm Imbalance under per-channel quantization, introduces Canalized Rotation and Omni-Token Scaling as a lightweight mitigation, and validates the resulting compression via standard perplexity and throughput benchmarks on held-out model suites. No step equates a claimed prediction or first-principles result to its own fitted inputs by construction; scaling factors are computed deterministically from observed token norms as part of the algorithm rather than tuned to match final accuracy metrics. Self-citations, if present, are not load-bearing for the uniqueness or dominance claims, and the evaluation remains externally falsifiable on independent datasets and models. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Omni-Token Scaling factors
axioms (1)
- domain assumption Token Norm Imbalance is the primary bottleneck to quantization fidelity when shared parameters must cover token groups with large norm disparities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our analysis identifies Token Norm Imbalance (TNI) as the primary bottleneck to quantization fidelity. We demonstrate that TNI systematically amplifies errors when shared quantization parameters are required to span token groups exhibiting substantial norm disparities.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OScaR employs Canalized Rotation followed by Omni-Token Scaling to mitigate TNI-induced sequence-dimensional variance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
K. Agarwal, R. Astra, A. Hoque, and et al. Hadacore: Tensor core accelerated hadamard transform kernel.arXiv preprint arXiv:2412.08832, 2024
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213– 100240, 2024
work page 2024
-
[5]
S. Bai, Y . Cai, R. Chen, and et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
work page 2024
-
[7]
Y . Bondarenko, M. Nagel, and T. Blankevoort. Quantizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Information Processing Systems (NeurIPS), 36:75067–75096, 2023
work page 2023
-
[8]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Qwen3-Coder-Next Technical Report
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al. Qwen3-coder-next technical report.arXiv preprint arXiv:2603.00729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
D. Du, S. Cao, J. Cheng, and et al. Bitdecoding: Unlocking tensor cores for long-context llms decoding with low-bit kv cache.arXiv e-prints, 2025
work page 2025
-
[11]
Haojie Duanmu, Zhihang Yuan, Xiuhong Li, Jiangfei Duan, Xingcheng Zhang, and Dahua Lin. Skvq: Sliding-window key and value cache quantization for large language models.arXiv preprint arXiv:2405.06219, 2024
-
[12]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms.arXiv preprint arXiv:2310.01801, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [14]
-
[15]
Z. Guo, H. Kamigaito, and T. Watanabe. Attention score is not all you need for token importance indicator in kv cache reduction: Value also matters. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 21158–21166, 2024
work page 2024
-
[16]
Polarquant: Quantizing kv caches with polar transformation
Insu Han, Praneeth Kacham, Amin Karbasi, Vahab Mirrokni, and Amir Zandieh. Polarquant: Quantizing kv caches with polar transformation.arXiv preprint arXiv:2502.02617, 2025
-
[17]
LI Haoyang, Yiming Li, Anxin Tian, Tianhao Tang, Zhanchao Xu, Xuejia Chen, HU Nicole, Wei Dong, Li Qing, and Lei Chen. A survey on large language model acceleration based on kv cache management.Transactions on Machine Learning Research, 2025. 10
work page 2025
-
[18]
Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, and Bohan Zhuang. Zipcache: Accurate and efficient kv cache quantization with salient token identification.Advances in Neural Information Processing Systems, 37:68287–68307, 2024
work page 2024
-
[19]
WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
Jiaxing Hong, Siyu Yan, Jun Cai, et al. Worldsense: Evaluating real-world omnimodal under- standing for multimodal llms.arXiv preprint arXiv:2502.04326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems, 37:1270–1303, 2024
work page 2024
-
[21]
The llama 3 herd of models.preprint, 2024
Kunal Chawla Huang, Kushal Lakhotia, Kyle Huang, Lailin Chen, Lakshya Garg, A Lavender, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, et al. The llama 3 herd of models.preprint, 2024
work page 2024
-
[22]
Zhongping Ji. Isoquant: Hardware-aligned so (4) isoclinic rotations for llm kv cache compres- sion.arXiv preprint arXiv:2603.28430, 2026
- [23]
- [24]
-
[25]
See what you are told: Visual attention sink in large multimodal models
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
- [26]
-
[27]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Haoyang Li, Yiming Li, Anxin Tian, Tianhao Tang, Zhanchao Xu, Xuejia Chen, Nicole Hu, Wei Dong, Qing Li, and Lei Chen. A survey on large language model acceleration based on kv cache management.arXiv preprint arXiv:2412.19442, 2024
-
[29]
Kunjun Li, Zigeng Chen, Cheng-Yen Yang, and Jenq-Neng Hwang. Memory-efficient visual au- toregressive modeling with scale-aware kv cache compression.arXiv preprint arXiv:2505.19602, 2025
-
[30]
Guang Liang, Jie Shao, Ningyuan Tang, Xinyao Liu, and Jianxin Wu. Tweo: Transformers without extreme outliers enables fp8 training and quantization for dummies.arXiv preprint arXiv:2511.23225, 2025
-
[31]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
work page 2024
-
[32]
Y . Lin, H. Tang, S. Yang, and et al. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.Proceedings of Machine Learning and Systems (MLSys), 7, 2025
work page 2025
-
[33]
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, and Bohan Zhuang. Minicache: Kv cache compression in depth dimension for large language models.Advances in Neural Information Processing Systems, 37:139997–140031, 2024
work page 2024
-
[34]
H. Liu, C. Li, Y . Li, and et al. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26296–26306, 2024. 11
work page 2024
-
[35]
H. Liu, C. Li, Q. Wu, and et al. Visual instruction tuning.Advances in Neural Information Processing Systems (NeurIPS), 36:34892–34916, 2023
work page 2023
-
[36]
Kv cache compression for inference efficiency in llms: A review
Yanyu Liu, Jingying Fu, Sixiang Liu, Yitian Zou, Shouhua Zhang, and Jiehan Zhou. Kv cache compression for inference efficiency in llms: A review. InProceedings of the 4th International Conference on Artificial Intelligence and Intelligent Information Processing, pages 207–212, 2025
work page 2025
-
[37]
Yuliang Liu, Zhang Li, Ming Huang, and et al. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024
work page 2024
-
[38]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021
work page 2021
-
[40]
A White Paper on Neural Network Quantization
Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yelysei Bondarenko, Mart Van Baalen, and Tijmen Blankevoort. A white paper on neural network quantization.arXiv preprint arXiv:2106.08295, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
Rotorquant: Clifford algebra vector quantization for llm kv cache compression
John D Pope. Rotorquant: Clifford algebra vector quantization for llm kv cache compression. github, 2026
work page 2026
-
[42]
Head-aware kv cache compression for efficient visual autoregressive modeling
Ziran Qin, Youru Lv, Mingbao Lin, Hang Guo, Zeren Zhang, Danping Zou, and Weiyao Lin. Head-aware kv cache compression for efficient visual autoregressive modeling. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
work page 2026
-
[43]
Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[44]
Accurate kv cache quantization with outlier tokens tracing
Yi Su, Yuechi Zhou, Quantong Qiu, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, and Min Zhang. Accurate kv cache quantization with outlier tokens tracing. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12895–12915, 2025
work page 2025
-
[45]
Zunhai Su, Zhe Chen, Wang Shen, Hanyu Wei, Linge Li, Huangqi Yu, and Kehong Yuan. Rotatekv: Accurate and robust 2-bit kv cache quantization for llms via outlier-aware adaptive rotations.arXiv preprint arXiv:2501.16383, 2025
-
[46]
Unveiling super experts in mixture-of-experts large language models
Zunhai Su, Qingyuan Li, Hao Zhang, Weihao Ye, Qibo Xue, YuLei Qian, Yuchen Xie, Ngai Wong, and Kehong Yuan. Unveiling super experts in mixture-of-experts large language models. arXiv preprint arXiv:2507.23279, 2025
-
[47]
Akvq-vl: Attention-aware kv cache adaptive 2-bit quantization for vision-language models
Zunhai Su, Wang Shen, Linge Li, Zhe Chen, Hanyu Wei, Huangqi Yu, and Kehong Yuan. Akvq-vl: Attention-aware kv cache adaptive 2-bit quantization for vision-language models. In 2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025
work page 2025
-
[48]
Zunhai Su, Weihao Ye, Hansen Feng, Keyu Fan, Jing Zhang, Dahai Yu, Zhengwu Liu, and Ngai Wong. Xstreamvggt: Extremely memory-efficient streaming vision geometry grounded transformer with kv cache compression.Journal of the Society for Information Display, 2026
work page 2026
-
[49]
Zunhai Su and Kehong Yuan. Kvsink: Understanding and enhancing the preservation of attention sinks in kv cache quantization for llms.arXiv preprint arXiv:2508.04257, 2025
-
[50]
Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
Zunhai Su, Hengyuan Zhang, Wei Wu, Yifan Zhang, Yaxiu Liu, He Xiao, Qingyao Yang, Yuxuan Sun, Rui Yang, Chao Zhang, et al. Attention sink in transformers: A survey on utilization, interpretation, and mitigation.arXiv preprint arXiv:2604.10098, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Keda Tao, Haoxuan You, Yang Sui, Can Qin, and Huan Wang. Plug-and-play 1. x-bit kv cache quantization for video large language models.arXiv preprint arXiv:2503.16257, 2025
-
[53]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, et al. Kimi linear: An expressive, efficient attention architecture.arXiv preprint arXiv:2510.26692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [54]
- [55]
-
[56]
Longcat-video technical report
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report. arXiv preprint arXiv:2510.22200, 2025
-
[57]
Longcat-flash-thinking-2601 technical report.arXiv preprint arXiv:2601.16725, 2026
Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chen Gao, Chen Zhang, Chengcheng Han, et al. Longcat-flash-thinking-2601 technical report.arXiv preprint arXiv:2601.16725, 2026
-
[58]
Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883, 2025
Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chengcheng Han, Chenhui Yang, Chi Zhang, et al. Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883, 2025
-
[59]
Longcat-flash technical report.arXiv preprint arXiv:2509.01322,
Meituan LongCat Team, Bei Li, Bingye Lei, Bo Wang, Bolin Rong, Chao Wang, Chao Zhang, Chen Gao, Chen Zhang, Cheng Sun, et al. Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
-
[60]
LongCat-Image Technical Report
Meituan LongCat Team, Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, et al. Longcat-image technical report. arXiv preprint arXiv:2512.07584, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Attention reallocation: Towards zero-cost and controllable hallucination mitigation of mllms
Chongjun Tu, Peng Ye, Dongzhan Zhou, Lei Bai, Gang Yu, Tao Chen, and Wanli Ouyang. Attention reallocation: Towards zero-cost and controllable hallucination mitigation of mllms. International Journal of Computer Vision, 134(1):22, 2026
work page 2026
-
[62]
Tom Turney and Contributors. Turboquant+. GitHub repository, May 2026. Online; accessed 2026-05-01
work page 2026
-
[63]
A. Vaswani, N. Shazeer, N. Parmar, and et al. Attention is all you need.Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
work page 2017
-
[64]
Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, and Li Yuan. Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4065–4078, 2024
work page 2024
-
[65]
Jianing Wang, Jianfei Zhang, Qi Guo, Linsen Guo, Rumei Li, Chao Zhang, Chong Peng, Cunguang Wang, Dengchang Zhao, Jiarong Shi, et al. Longcat-flash-prover: Advancing native formal reasoning via agentic tool-integrated reinforcement learning.arXiv preprint arXiv:2603.21065, 2026
-
[66]
Xiuying Wei, Yunchen Zhang, Yuhang Li, Xiangguo Zhang, Ruihao Gong, Jinyang Guo, and Xianglong Liu. Outlier suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1648–1665, 2023
work page 2023
-
[67]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
G. Xiao, Y . Tian, B. Chen, and et al. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
work page 2023
-
[70]
He Xiao, Qingyao Yang, Dirui Xie, Wendong Xu, Zunhai Su, Wenyong Zhou, Haobo Liu, Zhengwu Liu, Ngai Wong, et al. Exploring layer-wise information effectiveness for post-training quantization in small language models.arXiv preprint arXiv:2508.03332, 2025
-
[71]
Dope: Denoising rotary position embedding.arXiv preprint arXiv:2511.09146, 2025
Jing Xiong, Liyang Fan, Hui Shen, Zunhai Su, Min Yang, Lingpeng Kong, and Ngai Wong. Dope: Denoising rotary position embedding.arXiv preprint arXiv:2511.09146, 2025
-
[72]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. Turboquant: Online vector quantization with near-optimal distortion rate.arXiv preprint arXiv:2504.19874, 2025
work page internal anchor Pith review arXiv 2025
-
[75]
Qjl: 1-bit quantized jl transform for kv cache quan- tization with zero overhead
Amir Zandieh, Majid Daliri, and Insu Han. Qjl: 1-bit quantized jl transform for kv cache quan- tization with zero overhead. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25805–25813, 2025
work page 2025
-
[76]
Hengyuan Zhang, Xinrong Chen, Zunhai Su, Xiao Liang, Jing Xiong, Wendong Xu, He Xiao, Chaofan Tao, Wei Zhang, Ruobing Xie, et al. Beyond outliers: A data-free layer-wise mixed- precision quantization approach driven by numerical and structural dual-sensitivity.arXiv preprint arXiv:2603.17354, 2026
-
[77]
Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Qibo Xue, et al. Locate, steer, and improve: A practical survey of actionable mechanistic interpretability in large language models.arXiv preprint arXiv:2601.14004, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[78]
Streaming 4D Visual Geometry Transformer
Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, and Jiwen Lu. Streaming 4d visual geometry transformer.arXiv preprint arXiv:2507.11539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Softpick: No Attention Sink, No Massive Activations with Rectified Softmax
Zayd MK Zuhri, Erland Hilman Fuadi, and Alham Fikri Aji. Softpick: No attention sink, no massive activations with rectified softmax.arXiv preprint arXiv:2504.20966, 2025. 14 Appendix Contents A Limitations and Future Directions 17 B Algorithm of OScaR 17 C Preliminaries on Low-Bit Quantization 17 D Token Norm Imbalance in Text-Only LLMs 17 E Outlier Token...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Hadamard rotation and token-wise normalization for keys, building upon HadaCore’s efficient transform primitive
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.