The Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
Pith reviewed 2026-05-21 05:18 UTC · model grok-4.3
The pith
Interventions in LLM-simulated experiments induce unintended shifts in latent user attributes, distorting effect estimates through user drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
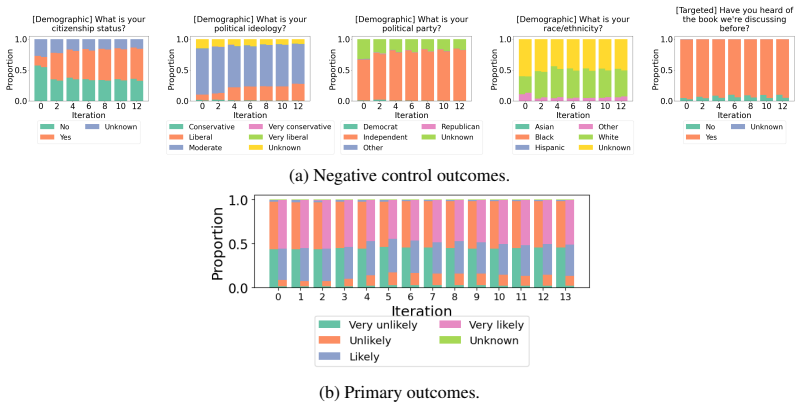
The authors show that intervention-dependent shifts in latent user attributes lead to user drift, where the implicit simulated population differs across treatment conditions. They formalize how this can cause confounding or selection bias that inflates or attenuates observed differences in responses. They propose using negative control outcomes to diagnose such shifts and demonstrate that eliciting additional setting-relevant confounders in persona specifications can reduce the bias in both survey-style and multi-turn agent evaluations.
What carries the argument
User drift from intervention-dependent shifts in latent attributes, diagnosed via negative control outcomes that should remain invariant.
If this is right
- Negative control outcomes can detect distribution shifts indicative of user drift across intervention conditions.
- Adjusting persona specifications with targeted confounders substantially reduces bias in effect estimates.
- This holds for both survey-style evaluations and multi-turn agent interactions.
- LLM-simulated experiments may require additional controls to approximate true experimental designs.
Where Pith is reading between the lines
- Researchers using LLM simulations for causal inference should routinely include negative controls to validate their setups.
- This issue may extend to other synthetic data generation methods trained on observational corpora.
- Combining LLM simulations with small-scale human validation could help quantify the extent of drift.
Load-bearing premise
That LLMs trained on observational data will produce shifts in latent user attributes when interventions are specified in simulations.
What would settle it
An experiment showing that effect estimates from LLM simulations match those from randomized human trials when negative controls indicate no distribution shift, or diverge when shifts are present.
Figures


























read the original abstract
Large language models (LLMs) show potential as simulators of human behavior, offering a scalable way to study responses to interventions. However, because LLMs are trained largely on observational data, interventions in experiments with LLM-simulated synthetic users can induce unintended shifts in latent user attributes, causing user drift where the implicit simulated population differs across treatment conditions, potentially distorting effect estimates. We formalize the confounding or selection bias that can arise due to user drift and show how intervention-dependent shifts can inflate or attenuate observed differences in user responses under intervention. To diagnose confounding, we propose using negative control outcomes--attributes that should remain invariant under intervention--to identify distribution shifts across intervention conditions, providing evidence of user drift. To mitigate drift, we study adjusting the persona specification by eliciting additional confounders, finding that targeted, setting-relevant confounders can substantially reduce bias across survey-style and multi-turn agent evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that interventions in LLM-simulated experiments induce unintended shifts in latent user attributes (termed 'user drift'), causing the implicit simulated population to differ across treatment conditions and thereby introducing confounding or selection bias that distorts effect estimates. It formalizes this bias, proposes negative control outcomes to diagnose distribution shifts across intervention conditions as evidence of drift, and reports that targeted persona adjustment by eliciting additional setting-relevant confounders substantially reduces bias in both survey-style and multi-turn agent evaluations.
Significance. If the formalization and empirical results hold, the work identifies a systematic source of bias in LLM-based behavioral simulation that parallels issues in observational studies, providing diagnostic tools (negative controls) and a mitigation strategy (persona adjustment). This could improve the validity of LLM-simulated experiments for studying interventions, particularly as such methods scale. The analogy to observational data and the focus on latent attribute shifts offer a useful conceptual framing, though the absence of quantitative details in the abstract limits immediate assessment of practical impact.
major comments (2)
- [Abstract] Abstract: the statement that targeted persona adjustment 'substantially reduce[s] bias' across two evaluation styles provides no quantitative effect sizes, error bars, or details on how drift magnitude was measured or how the reduction was quantified, which is load-bearing for evaluating whether the mitigation is effective or merely cosmetic.
- [Diagnosis of confounding] The diagnostic relying on negative control outcomes assumes these attributes remain invariant under intervention while still detecting shifts in other attributes. Because the LLM generates every attribute jointly from the same prompt, an intervention prompt can alter even putatively invariant attributes via prompt sensitivity or training-data associations, making it impossible to cleanly separate genuine user drift from model behavior; this assumption underpins both the formalization of bias and the reliability of the proposed diagnosis.
minor comments (1)
- [Abstract] The abstract refers to 'two evaluation styles' without naming them explicitly (e.g., survey-style vs. multi-turn); adding a brief parenthetical or table reference would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which identify key areas for improving the clarity and rigor of our presentation. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that targeted persona adjustment 'substantially reduce[s] bias' across two evaluation styles provides no quantitative effect sizes, error bars, or details on how drift magnitude was measured or how the reduction was quantified, which is load-bearing for evaluating whether the mitigation is effective or merely cosmetic.
Authors: We agree that the abstract would be strengthened by including quantitative details. The main text reports specific bias reductions and measurement procedures (via negative control outcome shifts), but these are not summarized in the abstract. In revision we will add concise quantitative results, including effect sizes for bias reduction and a brief description of the drift metric, while remaining within length limits. revision: yes
-
Referee: [Diagnosis of confounding] The diagnostic relying on negative control outcomes assumes these attributes remain invariant under intervention while still detecting shifts in other attributes. Because the LLM generates every attribute jointly from the same prompt, an intervention prompt can alter even putatively invariant attributes via prompt sensitivity or training-data associations, making it impossible to cleanly separate genuine user drift from model behavior; this assumption underpins both the formalization of bias and the reliability of the proposed diagnosis.
Authors: This correctly identifies a modeling assumption whose validity is not automatic. Our negative controls were chosen on substantive grounds (attributes whose invariance follows from the intervention definition and domain knowledge). We will add (i) explicit empirical checks confirming that selected negative controls show negligible shifts relative to primary outcomes and (ii) a limitations paragraph acknowledging residual prompt-sensitivity risk inherent to joint generation. We view this as a partial but honest strengthening rather than a full resolution of the joint-generation issue. revision: partial
Circularity Check
No significant circularity; claims rest on empirical comparisons and formalization without self-referential reduction
full rationale
The paper formalizes user drift and bias from LLM-simulated interventions, proposes negative control outcomes for diagnosis, and evaluates mitigation via persona adjustment. No equations, fitted parameters, or derivations are shown that reduce by construction to the target result. Central claims rely on described empirical comparisons across survey-style and multi-turn evaluations rather than tautological inputs or load-bearing self-citations. The premise about observational training data inducing shifts is stated as an assumption, not derived circularly. This is a normal non-finding for a conceptual/empirical paper without mathematical self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs are trained largely on observational data
invented entities (1)
-
user drift
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
interventions in experiments with LLM-simulated synthetic users can induce unintended shifts in latent user attributes, causing user drift where the implicit simulated population differs across treatment conditions
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose using negative control outcomes—attributes that should remain invariant under intervention—to identify distribution shifts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation , author=
-
[2]
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations , author=
-
[3]
Reasoning Elicitation in Language Models via Counterfactual Feedback , author=
-
[4]
arXiv preprint arXiv:2502.11425 , year=
Counterfactual-Consistency Prompting for Relative Temporal Understanding in Large Language Models , author=. arXiv preprint arXiv:2502.11425 , year=
-
[5]
Proceedings of the 40th International Conference on Machine Learning , pages =
Whose Opinions Do Language Models Reflect? , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[6]
Benchmarking Distributional Alignment of Large Language Models
Meister, Nicole and Guestrin, Carlos and Hashimoto, Tatsunori. Benchmarking Distributional Alignment of Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.2
-
[7]
Harper, F. Maxwell and Konstan, Joseph A. , title =. ACM Trans. Interact. Intell. Syst. , month = dec, articleno =. 2015 , issue_date =. doi:10.1145/2827872 , abstract =
-
[8]
and Kalai, Adam Tauman , title =
Aher, Gati and Arriaga, Rosa I. and Kalai, Adam Tauman , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
work page 2023
-
[9]
Second Conference on Language Modeling , year=
Deep Binding of Language Model Virtual Personas: a Study on Approximating Political Partisan Misperceptions , author=. Second Conference on Language Modeling , year=
-
[10]
Identity, Cooperation and Framing Effects within Groups of Real and Simulated Humans , author=. 2026 , eprint=
work page 2026
-
[11]
The Challenge of Using LLMs to Simulate Human Behavior: A Causal Inference Perspective , ISSN=
Gui, George and Toubia, Olivier , year=. The Challenge of Using LLMs to Simulate Human Behavior: A Causal Inference Perspective , ISSN=. doi:10.2139/ssrn.4650172 , journal=
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Persistent Instability in LLM’s Personality Measurements: Effects of Scale, Reasoning, and Conversation History , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i44.41133 , abstractNote=
-
[13]
S imulator A rena: Are User Simulators Reliable Proxies for Multi-Turn Evaluation of AI Assistants?
Dou, Yao and Galley, Michel and Peng, Baolin and Kedzie, Chris and Cai, Weixin and Ritter, Alan and Quirk, Chris and Xu, Wei and Gao, Jianfeng. S imulator A rena: Are User Simulators Reliable Proxies for Multi-Turn Evaluation of AI Assistants?. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/20...
-
[14]
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2023 , isbn =. doi:10.1145/3586183.3606763 , abstract =
-
[15]
Ang Li and Haozhe Chen and Hongseok Namkoong and Tianyi Peng , booktitle=. 2025 , url=
work page 2025
-
[16]
Quantifying the Persona Effect in LLM Simulations
Hu, Tiancheng and Collier, Nigel. Quantifying the Persona Effect in LLM Simulations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.554
-
[17]
LLMs Can Infer Political Alignment from Online Conversations , author=. 2026 , eprint=
work page 2026
-
[18]
Kaiser, Carolin and Kaiser, Jakob and Manewitsch, Vladimir and Rau, Lea and Schallner, Rene , title =. Adjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization , pages =. 2025 , isbn =. doi:10.1145/3708319.3733685 , abstract =
-
[19]
The Annals of Applied Statistics , volume=
SPLIT-DOOR CRITERION , author=. The Annals of Applied Statistics , volume=. 2018 , publisher=
work page 2018
-
[20]
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
work page 2025
-
[21]
Luke Guerdan and Justin Whitehouse and Kimberly Truong and Ken Holstein and Steven Wu , booktitle=. Doubly-Robust. 2026 , url=
work page 2026
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Should You Use LLMs to Simulate Opinions? Quality Checks for Early-Stage Deliberation , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i46.41254 , abstractNote=
-
[23]
Take Caution in Using LLMs as Human Surrogates: Scylla Ex Machina , author=. 2025 , eprint=
work page 2025
-
[24]
Can LLM be a Personalized Judge?
Dong, Yijiang River and Hu, Tiancheng and Collier, Nigel. Can LLM be a Personalized Judge?. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.592
-
[25]
Personas with Attitudes: Controlling LLM s for Diverse Data Annotation
Fr. Personas with Attitudes: Controlling LLM s for Diverse Data Annotation. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH). 2025
work page 2025
-
[26]
LLM Tropes: Revealing Fine-Grained Values and Opinions in Large Language Models
Wright, Dustin and Arora, Arnav and Borenstein, Nadav and Yadav, Srishti and Belongie, Serge and Augenstein, Isabelle. LLM Tropes: Revealing Fine-Grained Values and Opinions in Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.995
-
[27]
Negative controls: a tool for detecting confounding and bias in observational studies , author=. Epidemiology , volume=. 2010 , publisher=
work page 2010
- [28]
-
[29]
Identifying causal effects with proxy variables of an unmeasured confounder , author=. Biometrika , volume=. 2018 , publisher=
work page 2018
-
[30]
arXiv preprint arXiv:2009.10982 , year=
An introduction to proximal causal learning , author=. arXiv preprint arXiv:2009.10982 , year=
-
[31]
Measurement bias and effect restoration in causal inference , author=. Biometrika , pages=. 2014 , publisher=
work page 2014
-
[32]
International conference on machine learning , pages=
Proximal causal learning with kernels: Two-stage estimation and moment restriction , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[33]
arXiv preprint arXiv:2512.24413 , year=
Demystifying Proximal Causal Inference , author=. arXiv preprint arXiv:2512.24413 , year=
-
[34]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Lee, Harrison and Phatale, Samrat and Mansoor, Hassan and Mesnard, Thomas and Ferret, Johan and Lu, Kellie and Bishop, Colton and Hall, Ethan and Carbune, Victor and Rastogi, Abhinav and Prakash, Sushant , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[35]
PERSONA : A Reproducible Testbed for Pluralistic Alignment
Castricato, Louis and Lile, Nathan and Rafailov, Rafael and Fr. PERSONA : A Reproducible Testbed for Pluralistic Alignment. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[36]
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
work page 2022
-
[37]
Yun, Taedong and Yang, Eric and Safdari, Mustafa and Lee, Jong Ha and Kumar, Vaishnavi Vinod and Mahdavi, S. Sara and Amar, Jonathan and Peyton, Derek and Aharony, Reut and PhD, Andreas Michaelides and Schneider, Logan Douglas and Galatzer-Levy, Isaac and Jia, Yugang and Canny, John and Gretton, Arthur and Mataric, Maja. Sleepless Nights, Sugary Days: Cre...
-
[38]
Automated Social Science: Language Models as Scientist and Subjects , author=. 2024 , eprint=
work page 2024
-
[39]
Virtual Personas for Language Models via an Anthology of Backstories
Moon, Suhong and Abdulhai, Marwa and Kang, Minwoo and Suh, Joseph and Soedarmadji, Widyadewi and Behar, Eran Kohen and Chan, David M. Virtual Personas for Language Models via an Anthology of Backstories. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1110
-
[40]
Out of One, Many: Using Language Models to Simulate Human Samples , volume=. Political Analysis , author=. 2023 , pages=. doi:10.1017/pan.2023.2 , number=
-
[41]
Synthetic users: insights from designers’ interactions with persona-based chatbots , volume=
Gu, (Eric) Heng and Chandrasegaran, Senthil and Lloyd, Peter , year=. Synthetic users: insights from designers’ interactions with persona-based chatbots , volume=. doi:10.1017/S0890060424000283 , journal=
-
[42]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals , author=. 2026 , eprint=
work page 2026
-
[43]
Sclar, Melanie and Choi, Yejin and Tsvetkov, Yulia and Suhr, Alane , booktitle =. Quantifying Language Models Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting , url =
-
[44]
Kozlowski and Bernard Koch and Erik Brynjolfsson and James Evans and Michael S
Jacy Reese Anthis and Ryan Liu and Sean M Richardson and Austin C. Kozlowski and Bernard Koch and Erik Brynjolfsson and James Evans and Michael S. Bernstein , booktitle=. Position:. 2025 , url=
work page 2025
-
[45]
Sociological Methods and Research , issue=
Balancing large language model alignment and algorithmic fidelity in social science research , author=. Sociological Methods and Research , issue=. 2025 , volume=
work page 2025
- [46]
- [47]
- [48]
-
[49]
Gemma-4-31B-it , year =
-
[50]
Gemma-3-4B-it , year =
-
[51]
Gemini 3 Developer Guide | Gemini API , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.