RISE: Reliable Improvement in Self-Evolving Vision-Language Models
Pith reviewed 2026-05-21 05:35 UTC · model grok-4.3
The pith
RISE lets vision-language models improve themselves from unlabeled images by fixing three flaws in self-evolution loops.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a self-evolving framework called RISE, built from fine-grained role alternation between questioner and solver, a quality supervisor that validates generated questions and pseudo-labels, and skill-aware dynamic balancing to prevent mode collapse, enables reliable improvement of vision-language models directly from unlabeled images.
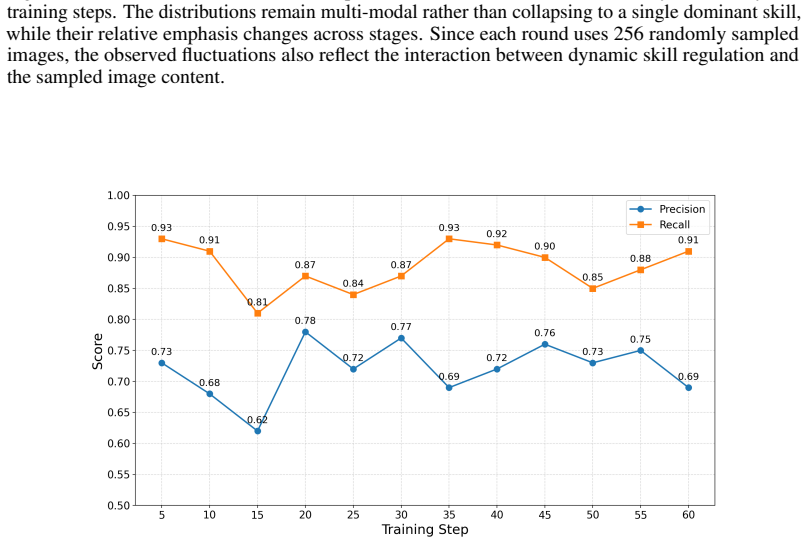
What carries the argument
RISE framework with its three components: fine-grained role alternation to shorten feedback loops, quality supervisor to check validity and correctness, and skill-aware dynamic balancing to maintain broad skill coverage.
If this is right
- The model achieves consistent performance gains on multiple multimodal benchmarks without new human labels.
- Fine-grained alternation shortens the cycle between question generation and solver updates.
- The quality supervisor maintains higher validity in generated questions and pseudo-labels.
- Skill-aware balancing prevents collapse to a narrow set of question types over time.
- Improvements remain broad and sustained rather than task-specific or short-lived.
Where Pith is reading between the lines
- Repeated cycles of the same process could produce compounding gains if the supervisor stays reliable.
- The approach might extend to pure language models or other modalities where labeled data is scarce.
- Lower dependence on human supervision could make iterative training of multimodal systems more scalable in practice.
Load-bearing premise
The quality supervisor can reliably judge question validity and pseudo-label correctness from the model's own outputs without external ground truth or human review.
What would settle it
Apply RISE to the base models and measure whether average accuracy rises, stays flat, or drops across the seven evaluation benchmarks after several evolution cycles.
Figures







read the original abstract
Vision-language models (VLMs) have achieved strong multimodal reasoning capabilities, but further improving them still relies heavily on large-scale human-constructed supervision for post-training. Such supervision is costly to obtain, especially for reasoning-intensive multimodal tasks where questions, answers, and feedback signals must be carefully designed. This motivates self-evolving learning, where a model improves itself through a dual-role closed loop: a questioner autonomously poses questions and a solver learns to solve them. However, we observe that current VLM self-evolving methods still face three major challenges: coarse-grained role alternation delays the interaction between question generation and solver adaptation; generated questions can progressively degrade in quality; and question types may collapse toward a narrow distribution. These issues limit the efficiency and reliability of self-evolution. Thus, we propose \textbf{RISE}, a reliable self-evolving framework for vision-language models. RISE is built on three complementary designs: fine-grained role alternation, which shortens the feedback loop between the questioner and the solver to improve efficiency; a quality supervisor, which improves question validity and pseudo-label reliability; and skill-aware dynamic balancing, which mitigates mode collapse and maintains broad skill coverage during evolution. Together, these components enable more reliable and effective self-evolution from unlabeled images. Experiments on two VLM backbones across seven benchmarks show that RISE consistently improves the base models, yielding broad and sustained gains. Our code is publicly available at https://github.com/AMAP-ML/RISE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RISE, a self-evolving framework for vision-language models that operates from unlabeled images. It identifies three limitations in prior self-evolving VLM methods (coarse role alternation, progressive quality degradation, and skill collapse) and introduces three components to address them: fine-grained role alternation to tighten the questioner-solver feedback loop, a quality supervisor to filter invalid questions and unreliable pseudo-labels, and skill-aware dynamic balancing to maintain broad skill coverage. The central empirical claim is that these designs produce consistent, broad, and sustained improvements when applied to two VLM backbones across seven benchmarks.
Significance. If the reported gains are robust, the work would meaningfully reduce dependence on expensive human-annotated multimodal reasoning data. The public code release is a clear positive for reproducibility. The significance hinges on whether the quality supervisor can be trusted to operate without external ground truth; absent stronger validation of that component, the practical impact remains uncertain.
major comments (2)
- [§3.2] §3.2 (Quality Supervisor): The supervisor is described as a prompted VLM from the same model family that judges question validity and pseudo-label correctness. No human agreement rates, calibration curves on held-out labeled data, or error analysis of accepted/rejected samples are reported. This omission directly affects the load-bearing premise that the closed loop produces reliable self-improvement rather than error amplification.
- [§5] §5 (Experiments): The claim of 'broad and sustained gains' across seven benchmarks is stated without per-benchmark tables showing absolute scores, deltas, standard deviations, or statistical tests. In addition, no ablation isolating the contribution of fine-grained alternation versus the supervisor versus dynamic balancing is presented, so the attribution of gains to the three proposed designs cannot be assessed.
minor comments (2)
- [Figure 2] Figure 2 and Algorithm 1: the notation for the dynamic balancing weights is introduced without an explicit equation linking the skill-coverage term to the sampling probability; a short derivation or pseudocode line would improve clarity.
- [§2] Related Work: the discussion of prior self-evolving VLM papers could more explicitly contrast the proposed fine-grained alternation with the coarse alternation used in the cited baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate the suggested additions into the revised manuscript to strengthen the validation of the quality supervisor and the experimental analysis.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Quality Supervisor): The supervisor is described as a prompted VLM from the same model family that judges question validity and pseudo-label correctness. No human agreement rates, calibration curves on held-out labeled data, or error analysis of accepted/rejected samples are reported. This omission directly affects the load-bearing premise that the closed loop produces reliable self-improvement rather than error amplification.
Authors: We agree that additional empirical validation of the quality supervisor is important to support the reliability claims. In the revised manuscript we will add: (1) human agreement rates on a sampled set of 200 questions and pseudo-labels, including inter-annotator agreement statistics; (2) a detailed error analysis breaking down accepted versus rejected samples by error type; and (3) a calibration study on a small held-out labeled subset drawn from one benchmark to produce reliability diagrams. These results will be reported in an expanded §3.2 and the appendix. revision: yes
-
Referee: [§5] §5 (Experiments): The claim of 'broad and sustained gains' across seven benchmarks is stated without per-benchmark tables showing absolute scores, deltas, standard deviations, or statistical tests. In addition, no ablation isolating the contribution of fine-grained alternation versus the supervisor versus dynamic balancing is presented, so the attribution of gains to the three proposed designs cannot be assessed.
Authors: We acknowledge the need for more granular reporting. The revised Section 5 will include complete per-benchmark tables with base-model scores, RISE scores, absolute deltas, standard deviations over three independent runs, and p-values from paired statistical tests. We will also add a dedicated ablation subsection that evaluates three controlled variants (each component disabled in turn) across all seven benchmarks, allowing direct attribution of performance gains to fine-grained alternation, the quality supervisor, and skill-aware dynamic balancing. revision: yes
Circularity Check
No significant circularity in RISE framework derivation
full rationale
The paper presents RISE as a procedural framework with three components (fine-grained role alternation, quality supervisor, skill-aware dynamic balancing) for self-evolving VLMs, validated empirically on two backbones across seven benchmarks. No equations, predictions, or first-principles derivations are described that reduce to fitted parameters, self-definitions, or self-citation chains by construction. Claims of consistent improvements rest on experimental results rather than inputs that are renamed or presupposed as outputs. The quality supervisor's reliability is an empirical assumption, not a circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A dual-role closed loop of autonomous question generation and solving can produce reliable improvement in VLMs
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
work page 2025
-
[5]
Yuji Cao, Huan Zhao, Yuheng Cheng, Ting Shu, Yue Chen, Guolong Liu, Gaoqi Liang, Junhua Zhao, Jinyue Yan, and Yun Li. Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods.IEEE Transactions on Neural Networks and Learning Systems, 36(6):9737–9757, 2024
work page 2024
-
[6]
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models.arXiv preprint arXiv:2504.11468, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
GPG: A simple and strong reinforcement learning baseline for model reasoning
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. GPG: A simple and strong reinforcement learning baseline for model reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=inccdtfx8x
work page 2026
-
[8]
Self-improvement in multimodal large language models: A survey
Shijian Deng, Kai Wang, Tianyu Yang, Harsh Singh, and Yapeng Tian. Self-improvement in multimodal large language models: A survey. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 1987–2006, 2025
work page 2025
-
[9]
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Open- vlthinker: An early exploration to complex vision-language reasoning via iterative self- improvement.arXiv e-prints, pages arXiv–2503, 2025
work page 2025
-
[10]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024
work page 2024
-
[12]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1.5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Visplay: Self-evolving vision-language models from images.arXiv preprint arXiv:2511.15661, 2025
Yicheng He, Chengsong Huang, Zongxia Li, Jiaxin Huang, and Yonghui Yang. Visplay: Self-evolving vision-language models from images.arXiv preprint arXiv:2511.15661, 2025
-
[15]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Large language models can self-improve
Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 1051–1068, 2023
work page 2023
-
[17]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Vision-language instruction tuning: A review and analysis.arXiv preprint arXiv:2311.08172, 2023
Chen Li, Yixiao Ge, Dian Li, and Ying Shan. Vision-language instruction tuning: A review and analysis.arXiv preprint arXiv:2311.08172, 2023
-
[20]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. Llms-as-judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Surveying the mllm landscape: A meta-review of current surveys.arXiv preprint arXiv:2409.18991, 2024
Ming Li, Keyu Chen, Ziqian Bi, Ming Liu, Xinyuan Song, Zekun Jiang, Tianyang Wang, Benji Peng, Qian Niu, Junyu Liu, et al. Surveying the mllm landscape: A meta-review of current surveys.arXiv preprint arXiv:2409.18991, 2024
-
[22]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Zongxia Li, Wenhao Yu, Chengsong Huang, Rui Liu, Zhenwen Liang, Fuxiao Liu, Jingxi Che, Dian Yu, Jordan Boyd-Graber, Haitao Mi, et al. Self-rewarding vision-language model via reasoning decomposition.arXiv preprint arXiv:2508.19652, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Zongxia Li, Hongyang Du, Chengsong Huang, Xiyang Wu, Lantao Yu, Yicheng He, Jing Xie, Xiaomin Wu, Zhichao Liu, Jiarui Zhang, et al. Mm-zero: Self-evolving multi-model vision language models from zero data.arXiv preprint arXiv:2603.09206, 2026
-
[24]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
-
[26]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[27]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
work page 2022
-
[29]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, et al. Beyond human data: Scaling self-training for problem-solving with language models.arXiv preprint arXiv:2312.06585, 2023. 11
-
[32]
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. Improving data efficiency for llm reinforcement fine-tuning through difficulty- targeted online data selection and rollout replay.arXiv preprint arXiv:2506.05316, 2025
-
[33]
A survey on self-evolution of large language models, 2024
Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, and Jingren Zhou. A survey on self-evolution of large language models, 2024
work page 2024
-
[34]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Omkar Thawakar, Shravan Venkatraman, Ritesh Thawkar, Abdelrahman Shaker, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Khan. Evolmm: Self-evolving large multimodal models with continuous rewards.arXiv preprint arXiv:2511.16672, 2025
-
[36]
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
work page 2024
-
[37]
Position: Will we run out of data? limits of llm scaling based on human-generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of llm scaling based on human-generated data. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[38]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37:95095–95169, 2024
work page 2024
-
[39]
Qinsi Wang, Bo Liu, Tianyi Zhou, Jing Shi, Yueqian Lin, Yiran Chen, Hai Helen Li, Kun Wan, and Wentian Zhao. Vision-zero: Scalable vlm self-improvement via strategic gamified self-play. arXiv preprint arXiv:2509.25541, 2025
-
[40]
Self-instruct: Aligning language models with self-generated instruc- tions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
work page 2023
-
[41]
Realworldqa: Real-world spatial understanding benchmark
xAI. Realworldqa: Real-world spatial understanding benchmark. https://huggingface. co/datasets/xai-org/RealworldQA, 2024. CC BY-ND 4.0 license. Benchmark dataset released with Grok-1.5 Vision Preview; see alsohttps://x.ai/news/grok-1.5v
work page 2024
-
[42]
Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning
Peng Xia, Kaide Zeng, Jiaqi Liu, Can Qin, Fang Wu, Yiyang Zhou, Caiming Xiong, and Huaxiu Yao. Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning. arXiv preprint arXiv:2511.16043, 2025
-
[43]
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2376–2385, 2025
work page 2025
-
[44]
A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
work page 2024
-
[45]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Guided self-evolving llms with minimal human supervision.arXiv preprint arXiv:2512.02472, 2025
Wenhao Yu, Zhenwen Liang, Chengsong Huang, Kishan Panaganti, Tianqing Fang, Haitao Mi, and Dong Yu. Guided self-evolving llms with minimal human supervision.arXiv preprint arXiv:2512.02472, 2025. 12
-
[47]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
work page 2024
-
[48]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
work page 2022
-
[49]
Jiarui Zhang, Jinyi Hu, Mahyar Khayatkhoei, Filip Ilievski, and Maosong Sun. Exploring perceptual limitation of multimodal large language models.arXiv preprint arXiv:2402.07384, 2024
-
[50]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186. Springer, 2024
work page 2024
-
[51]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025. 13 Appendix A Detailed Training and Implementation Details A.1 Hyperparameter Settings We use the same training hyperparameters for the questioner and the ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
require visual analysis or reasoning rather than simple description
-
[55]
belong to exactly one skill category: coarse perception, fine-grained perception, instance reasoning, logical reasoning, math & counting, or science & technology
-
[56]
belong to exactly one question type: multiple choice, numerical, or regression
-
[57]
have a short, unique, and verifiable answer. Output strictly in the following format: <skill>...</skill> <type>...</type> <question>...</question> 14 User: [IMAGE] Generate one new challenging reasoning question based on this image. Solver prompt.The solver is prompted to answer the generated question based on the image. To make answer extraction reliable...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.