From Circuit Evidence to Mechanistic Theory: An Inductive Logic Approach
Pith reviewed 2026-05-21 05:57 UTC · model grok-4.3
The pith
Pairing causal evidence with inductive logic turns isolated neural circuits into comparable and portable mechanistic theories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
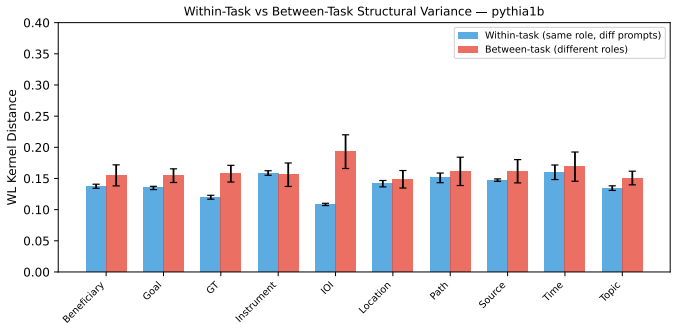
Each circuit is characterised at two levels: a Causal Functional Signature (CFS) that grounds component behaviour in causal attribution evidence and token role profiles, and an architectural signature τ_arch learned by inductive logic programming from scale-invariant structural predicates. Together these form a formal coherence layer that makes mechanistic claims explicit, comparable via θ-subsumption, and portable across model scales. CFS reveals qualitatively distinct computational strategies across task types, including attention-mediated copying versus MLP-mediated binding, while ILP signatures achieve substantially better structural separation than graph kernel and feature-vector Baseli
What carries the argument
The formal coherence layer consisting of the Causal Functional Signature (CFS), which encodes causal attribution evidence and token role profiles, and the architectural signature τ_arch learned by inductive logic programming from scale-invariant structural predicates.
If this is right
- Mechanistic claims become explicitly comparable across experiments by checking whether one signature θ-subsumes another.
- Architectural signatures support principled transfer of findings from smaller models to larger models and across architecture families.
- Distinct computational strategies, such as attention-mediated copying versus MLP-mediated binding, become identifiable as separate classes.
- Structural separation of circuits improves over graph kernel and feature-vector baselines while remaining interpretable as logic programs.
Where Pith is reading between the lines
- A growing collection of signatures could function as a shared reference set against which new circuit discoveries are automatically matched or classified.
- The same logic-programming abstraction might be applied to other forms of mechanistic evidence, such as activation patterns or ablation results, to build broader theories.
- If signatures prove portable, they could be used to predict which circuit types are likely to emerge in a new architecture before any experiments are run.
Load-bearing premise
The scale-invariant structural predicates supplied to inductive logic programming are sufficient to capture the computationally relevant architectural features of circuits and that the resulting signatures support meaningful transfer and separation beyond what graph kernels already achieve.
What would settle it
If circuits that human experts judge to implement the same function receive signatures that fail to subsume one another under θ-subsumption, or if signatures trained on small models cannot classify or transfer to circuits found in larger models of the same family on the same task.
Figures









read the original abstract
Mechanistic interpretability produces circuit-level causal analyses of neural network behaviour, but discovered circuits often remain isolated experimental artefacts: there is no shared formal representation for what circuits compute, how they relate, or when two findings provide evidence for the same mechanism. This work provides a formal infrastructure for cumulative mechanistic science by treating circuit interpretation as inductive theory construction. Each circuit is characterised at two levels: a Causal Functional Signature (CFS), which grounds component behaviour in causal attribution evidence and token role profiles, and an architectural signature $\tau_{\mathrm{arch}}$, learned by inductive logic programming (ILP) from scale-invariant structural predicates. Together, these constitute a formal coherence layer that makes mechanistic claims explicit, comparable via $\theta$-subsumption, and portable across model scales. CFS reveals qualitatively distinct computational strategies across task types, including attention-mediated copying versus MLP-mediated binding. ILP signatures achieve substantially better structural separation than graph kernel and feature-vector baselines, and support principled transfer across model scales and architecture families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a formal infrastructure for cumulative mechanistic interpretability by characterizing each circuit via a Causal Functional Signature (CFS) grounded in causal attribution evidence and token role profiles, together with an architectural signature τ_arch learned by inductive logic programming (ILP) from scale-invariant structural predicates. These elements form a coherence layer enabling explicit mechanistic claims that are comparable via θ-subsumption and portable across model scales and architecture families. The abstract reports that CFS reveals qualitatively distinct strategies (e.g., attention-mediated copying versus MLP-mediated binding) and that ILP signatures achieve substantially better structural separation than graph-kernel and feature-vector baselines.
Significance. If the central claims are substantiated with quantitative evidence, the work would supply a shared formal representation that moves mechanistic interpretability from isolated circuit discoveries toward cumulative theory construction. The introduction of ILP-derived signatures offers a principled route to structural comparison and cross-scale transfer that, if shown to exceed existing graph-based methods, could become a standard tool for relating findings across models.
major comments (3)
- Abstract: the claim that ILP signatures achieve 'substantially better structural separation' than graph kernel and feature-vector baselines is presented without any quantitative metrics, error bars, dataset details, or statistical tests. This absence is load-bearing for the central claim of improved separation and principled transfer.
- Abstract / method description: no explicit checks or ablations are reported demonstrating that the supplied scale-invariant structural predicates remain informative and align with causal roles in the CFS when circuit depth or width changes by orders of magnitude. Without such evidence the portability claim risks reducing to recovery of graph topology already achievable by kernels.
- Abstract: the qualitative distinction between attention-mediated copying and MLP-mediated binding via CFS is asserted but lacks detail on how the signatures are computed, validated, or compared to alternative functional representations, leaving the coherence-layer claim under-supported.
minor comments (2)
- The notation τ_arch and the precise definition of θ-subsumption would benefit from a short illustrative example early in the manuscript to aid readability.
- Clarify whether the ILP predicates are chosen a priori or derived from the circuit data, and state any assumptions about their completeness for capturing computationally relevant features.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas where the presentation of quantitative evidence and methodological details can be strengthened to better support the central claims. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the claim that ILP signatures achieve 'substantially better structural separation' than graph kernel and feature-vector baselines is presented without any quantitative metrics, error bars, dataset details, or statistical tests. This absence is load-bearing for the central claim of improved separation and principled transfer.
Authors: We agree that the abstract would be strengthened by including key quantitative metrics, error bars, dataset details, and statistical tests. The experimental results in the main text (Section 5) contain these details, including separation performance across baselines with statistical comparisons. We have revised the abstract to incorporate a concise summary of the quantitative findings and dataset information. revision: yes
-
Referee: Abstract / method description: no explicit checks or ablations are reported demonstrating that the supplied scale-invariant structural predicates remain informative and align with causal roles in the CFS when circuit depth or width changes by orders of magnitude. Without such evidence the portability claim risks reducing to recovery of graph topology already achievable by kernels.
Authors: We agree that explicit ablations across large changes in depth and width would provide stronger support for the scale-invariance and alignment claims. The predicates are constructed to be independent of absolute model size (using relative and arity-invariant relations), and the manuscript demonstrates transfer on models of different scales. We will add a dedicated ablation subsection with experiments varying model size by orders of magnitude to show that predicate informativeness and alignment with CFS causal roles are preserved. revision: yes
-
Referee: Abstract: the qualitative distinction between attention-mediated copying and MLP-mediated binding via CFS is asserted but lacks detail on how the signatures are computed, validated, or compared to alternative functional representations, leaving the coherence-layer claim under-supported.
Authors: We agree that additional detail on computation and validation would better support the coherence-layer claim in the abstract. The full method section explains CFS construction via causal attribution evidence combined with token role profiles, with validation against known circuits. We have revised the abstract to briefly describe the signature computation process and how distinctions are validated. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper constructs CFS from causal attribution evidence and token role profiles, then learns τ_arch via ILP applied to explicitly supplied scale-invariant structural predicates. Claims of explicitness, θ-subsumption comparability, and cross-scale portability follow directly from these definitional choices and standard ILP properties rather than from any derived prediction or fitted parameter that reduces to the inputs by construction. The reported superior separation versus graph-kernel baselines is presented as an empirical outcome of applying the method, not a tautological result. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the abstract or described chain. The overall infrastructure is therefore an independent formal proposal whose central claims do not collapse to re-labeling of the supplied data or predicates.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Circuits admit characterisation by causal attribution evidence together with token role profiles.
- domain assumption Scale-invariant structural predicates exist that ILP can learn to produce transferable architectural signatures.
invented entities (2)
-
Causal Functional Signature (CFS)
no independent evidence
-
architectural signature τ_arch
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each circuit is characterised at two levels: a Causal Functional Signature (CFS)... and an architectural signature τ_arch, learned by inductive logic programming (ILP) from scale-invariant structural predicates... comparable via θ-subsumption
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ILP signatures achieve substantially better structural separation than graph kernel and feature-vector baselines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
work page 2023
-
[8]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[10]
Proceedings of the 37th Conference on Neural Information Processing Systems , year =
Towards Automated Circuit Discovery for Mechanistic Interpretability , author =. Proceedings of the 37th Conference on Neural Information Processing Systems , year =
-
[11]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
A Mechanistic Interpretation of Arithmetic Reasoning in Language Models Using Causal Mediation Analysis , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
work page 2023
-
[12]
Findings of the Association for Computational Linguistics:
Reasoning Circuits in Language Models: A Mechanistic Interpretation of Syllogistic Inference , author =. Findings of the Association for Computational Linguistics:. 2025 , address =
work page 2025
-
[13]
Decomposing Natural Logic Inferences for Neural
Rozanova, Julia and Ferreira, Deborah and Thayaparan, Mokanarangan and Valentino, Marco and Freitas, Andre , booktitle =. Decomposing Natural Logic Inferences for Neural. 2022 , address =
work page 2022
-
[14]
A Symbolic Framework for Evaluating Mathematical Reasoning and Generalisation with Transformers , author =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , editor =. 2024 , address =
work page 2024
-
[15]
Formal Semantic Controls over Language Models , author =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024): Tutorial Summaries , editor =. 2024 , address =
work page 2024
-
[16]
Quan, Xin and Valentino, Marco and Carvalho, Danilo and Dalal, Dhairya and Freitas, Andre , booktitle =. 2025 , address =. doi:10.18653/v1/2025.acl-demo.2 , isbn =
-
[17]
Annals of the New York Academy of Sciences , volume =
Frame Semantics and the Nature of Language , author =. Annals of the New York Academy of Sciences , volume =. 1976 , doi =
work page 1976
-
[18]
Thayaparan, Mokanarangan and Valentino, Marco and Ferreira, Deborah and Rozanova, Julia and Freitas, Andr. Diff-. Transactions of the Association for Computational Linguistics , year =
-
[19]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[20]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in
-
[21]
A Mechanistic Interpretation of Arithmetic Reasoning in Language Models using Causal Mediation Analysis , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
work page 2023
-
[22]
Decomposing Natural Logic Inferences for Neural
Rozanova, Julia and Ferreira, Deborah and Thayaparan, Mokanarangan and Valentino, Marco and Freitas, Andre , booktitle =. Decomposing Natural Logic Inferences for Neural
-
[23]
A note on inductive generalization , journal =
Gordon D Plotkin , year =. A note on inductive generalization , journal =
-
[24]
Subsumption and implication , journal =
Georg Gottlob , keywords =. Subsumption and implication , journal =. 1987 , issn =. doi:https://doi.org/10.1016/0020-0190(87)90103-7 , url =
-
[25]
Computational Linguistics , note =
Are formal and functional linguistic mechanisms dissociated in language models? , author =. Computational Linguistics , note =
-
[26]
International Conference on Learning Representations (ICLR) , year =
Progress measures for grokking via mechanistic interpretability , author =. International Conference on Learning Representations (ICLR) , year =
- [27]
-
[28]
The Insurmountable Problem of Formal Reasoning in LLMs , author =
-
[29]
On the use of large language models in model-driven engineering: J. Di Rocco et al. , author=. Software and Systems Modeling , volume=. 2025 , publisher=
work page 2025
-
[30]
Computational Linguistics , pages =
Hanna, Michael and Belinkov, Yonatan and Pezzelle, Sandro , title =. Computational Linguistics , pages =. 2025 , month =. doi:10.1162/coli.a.24 , url =
-
[31]
arXiv preprint arXiv:2502.11856 , year=
LLMs as a synthesis between symbolic and continuous approaches to language , author=. arXiv preprint arXiv:2502.11856 , year=
-
[32]
Lectures on Government and Binding , title =
Noam Chomsky , publisher =. Lectures on Government and Binding , title =. 1993 , lastchecked =. doi:doi:10.1515/9783110884166 , isbn =
- [33]
-
[34]
ICML 2024 Workshop on Mechanistic Interpretability , year=
Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms , author=. ICML 2024 Workshop on Mechanistic Interpretability , year=
work page 2024
-
[35]
Emergence and Localisation of Semantic Role Circuits in LLMs , author=. 2025 , eprint=
work page 2025
-
[36]
and Jun, Eunice and Terry, Michael and Yang, Qian and Hartmann, Bjoern , title =
Zamfirescu-Pereira, J.D. and Jun, Eunice and Terry, Michael and Yang, Qian and Hartmann, Bjoern , title =. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , articleno =. 2025 , isbn =. doi:10.1145/3706598.3714154 , abstract =
-
[37]
Quan, Xin and Valentino, Marco and Dennis, Louise A. and Freitas, Andre. Verification and Refinement of Natural Language Explanations through LLM -Symbolic Theorem Proving. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.172
-
[38]
ACM Transactions on Intelligent Systems and Technology , volume=
A comprehensive overview of large language models , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
work page 2025
-
[39]
A Primer on the Inner Workings of Transformer-based Language Models , author=. 2024 , eprint=
work page 2024
-
[40]
Finding Skill Neurons in Pre-trained Transformer-based Language Models
Wang, Xiaozhi and Wen, Kaiyue and Zhang, Zhengyan and Hou, Lei and Liu, Zhiyuan and Li, Juanzi. Finding Skill Neurons in Pre-trained Transformer-based Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.765
-
[41]
Journal of Machine Learning Research , year =
Atticus Geiger and Duligur Ibeling and Amir Zur and Maheep Chaudhary and Sonakshi Chauhan and Jing Huang and Aryaman Arora and Zhengxuan Wu and Noah Goodman and Christopher Potts and Thomas Icard , title =. Journal of Machine Learning Research , year =
-
[42]
arXiv preprint arXiv:2506.09890 , year=
The Emergence of Abstract Thought in Large Language Models Beyond Any Language , author=. arXiv preprint arXiv:2506.09890 , year=
-
[43]
Forty-second International Conference on Machine Learning , year=
Towards Global-level Mechanistic Interpretability: A Perspective of Modular Circuits of Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[44]
New generation computing , volume=
Inductive logic programming , author=. New generation computing , volume=. 1991 , publisher=
work page 1991
-
[45]
Probabilistic Inductive Logic Programming
De Raedt, Luc and Kersting, Kristian. Probabilistic Inductive Logic Programming. Probabilistic Inductive Logic Programming: Theory and Applications. 2008. doi:10.1007/978-3-540-78652-8_1
-
[46]
Localizing Model Behavior with Path Patching
Localizing model behavior with path patching , author=. arXiv preprint arXiv:2304.05969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[48]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
arXiv preprint arXiv:2411.04105 , year=
A Implies B: Circuit Analysis in LLMs for Propositional Logical Reasoning , author=. arXiv preprint arXiv:2411.04105 , year=
-
[51]
Journal of Artificial Intelligence Research , volume=
Inductive logic programming at 30: a new introduction , author=. Journal of Artificial Intelligence Research , volume=
-
[52]
Artificial intelligence a modern approach , author=. 2010 , publisher=
work page 2010
-
[53]
A mathematical theory of communication , year=
Shannon, Claude Elwood , journal=. A mathematical theory of communication , year=
-
[54]
The Twelfth International Conference on Learning Representations , year=
Circuit Component Reuse Across Tasks in Transformer Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[55]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[56]
Forty-second International Conference on Machine Learning , year=
Validating Mechanistic Interpretations: An Axiomatic Approach , author=. Forty-second International Conference on Machine Learning , year=
-
[57]
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
work page 2021
- [58]
-
[59]
The Thirteenth International Conference on Learning Representations , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[60]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[61]
The Fourteenth International Conference on Learning Representations , year=
Formal Mechanistic Interpretability: Automated Circuit Discovery with Provable Guarantees , author=. The Fourteenth International Conference on Learning Representations , year=
-
[62]
Causal scrubbing, a method for rigorously testing interpretability hypotheses , author=. 2022 , journal=
work page 2022
-
[63]
Interpreting GPT: The Logit Lens , author =. 2020 , howpublished =
work page 2020
-
[64]
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , biburl =. doi:10.5281/zenodo.1212303 , interhash =
-
[65]
TRACE : Training and Inference-Time Interpretability Analysis for Language Models
Aljaafari, Nura and Carvalho, Danilo and Freitas, Andre. TRACE : Training and Inference-Time Interpretability Analysis for Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2025. doi:10.18653/v1/2025.emnlp-demos.62
- [66]
-
[67]
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , journal=. Scikit-learn: Machine Learning in
-
[68]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[69]
Nino Shervashidze and Pascal Schweitzer and Erik Jan van Leeuwen and Kurt Mehlhorn and Karsten M. Borgwardt , title =. Journal of Machine Learning Research , year =
-
[70]
Random forests , author=. Machine Learning , volume=. 2001 , publisher=
work page 2001
-
[71]
Mib: A mechanistic interpretability benchmark , author=. arXiv preprint arXiv:2504.13151 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.