VINS-120K: Ultra High-Resolution Image Editing with A Large-Scale Dataset
Pith reviewed 2026-05-25 04:19 UTC · model grok-4.3
The pith
VINS-120K supplies 120K curated triplets for instruction-driven editing of images at resolutions above 4K.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
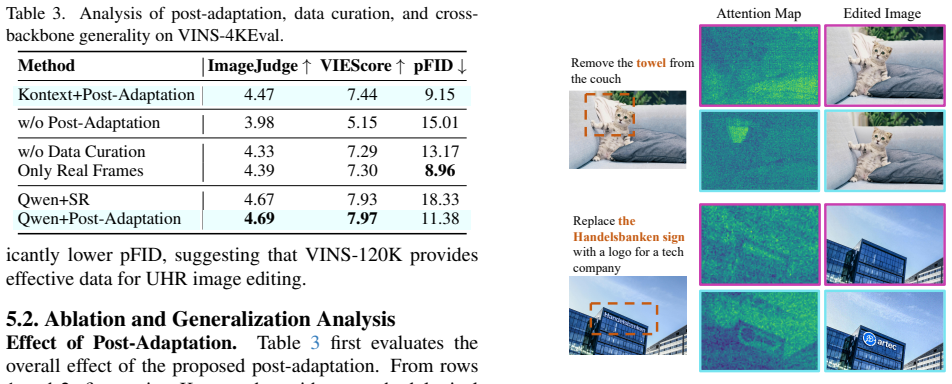
The central claim is that a rigorously filtered collection of 120K instruction-aligned triplets at >=4K resolution, combined with a high-frequency-aware post-adaptation method, enables pretrained models to synthesize finer details and more realistic textures when editing ultra-high-resolution images.
What carries the argument
The VINS-120K dataset of instruction-image-edited triplets at ultra-high resolution together with the high-frequency-aware post-adaptation strategy that extends lower-resolution models.
If this is right
- Adapted models produce higher-fidelity detail synthesis and texture realism on UHR edits than the same models without the adaptation step.
- VINS-4KEval supplies a standardized way to compare different editing approaches across many instruction types at consistent high resolution.
- The post-adaptation approach allows reuse of existing non-UHR pretrained weights rather than training new models from scratch at full resolution.
- Instruction-based editing becomes feasible for applications that require output resolutions of 4096 by 4096 or greater.
Where Pith is reading between the lines
- The dataset construction pipeline could be reused to generate similar high-quality pairs for related tasks such as high-resolution image generation or restoration.
- Future models might combine the adaptation strategy with progressive training schedules to reach even higher resolutions without proportional compute growth.
- The benchmark could reveal whether current metrics adequately capture perceptual quality differences at ultra-high resolutions.
- Extending the same curation logic to video sequences might address temporal consistency in high-resolution editing.
- keywords:[
Load-bearing premise
The multi-stage curation pipeline produces triplets that are verifiably high-quality, instruction-aligned, and free of systematic artifacts or biases.
What would settle it
An experiment in which models adapted with VINS-120K show no measurable gain in fine detail or texture metrics over strong baselines when tested on a fresh set of real-world 4K+ images with human-written instructions.
Figures




















read the original abstract
Directly editing ultra-high-resolution (UHR) images is valuable but underexplored, primarily due to the lack of high-quality data and the challenge in modeling high-frequency texture details. We introduce VINS-120K, the first large-scale dataset for instruction-based UHR image editing, comprising 120K carefully curated triplets of instruction, input image, and edited image. Each image exceeds 4K resolution ($\geq$4096 $\times$ 4096) and is filtered through a rigorous multi-stage pipeline to ensure visual quality, instruction alignment, and aesthetic fidelity. Built on VINS-120K, we further develop a high-frequency-aware post-adaptation strategy to extend pretrained non-high-resolution models to the UHR regime. We also present VINS-4KEval, a benchmark covering diverse editing types, to facilitate consistent evaluation in UHR settings. Experiments confirm that our work improves fine-grained detail synthesis and texture realism in UHR image editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VINS-120K, the first large-scale dataset of 120K instruction-based triplets (instruction, input image, edited image) for ultra-high-resolution (UHR) image editing where every image exceeds 4K resolution. It describes a multi-stage curation pipeline to ensure visual quality, instruction alignment, and aesthetic fidelity; proposes a high-frequency-aware post-adaptation strategy to extend pretrained models to the UHR regime; and presents the VINS-4KEval benchmark. Experiments are claimed to confirm gains in fine-grained detail synthesis and texture realism.
Significance. If the curation pipeline produces verifiably high-quality, instruction-aligned triplets and the reported gains are reproducible against baselines, the dataset and adaptation method could meaningfully advance UHR editing research by addressing the current scarcity of suitable training data and evaluation protocols.
major comments (2)
- [Abstract] Abstract: the central claim that the dataset and post-adaptation strategy improve fine-grained detail synthesis and texture realism is asserted without any reported metrics, baselines, ablation studies, or evaluation protocol, rendering the claim impossible to assess.
- [Dataset construction paragraph] Dataset construction paragraph: the multi-stage curation pipeline is presented as producing high-quality, instruction-aligned triplets free of systematic artifacts, yet no quantitative validation (human preference scores, alignment accuracy, or artifact statistics) is supplied; this validation is load-bearing for isolating claimed texture-realism gains from data artifacts.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below. Where the comments identify gaps in the current manuscript, we agree that revisions are warranted and will incorporate the suggested additions in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the dataset and post-adaptation strategy improve fine-grained detail synthesis and texture realism is asserted without any reported metrics, baselines, ablation studies, or evaluation protocol, rendering the claim impossible to assess.
Authors: We agree that the abstract would benefit from explicit quantitative support. The full manuscript contains an Experiments section that reports results on VINS-4KEval, including comparisons against baselines and ablations demonstrating gains in detail synthesis and texture realism. To address the concern directly, we will revise the abstract to include a concise summary of the key metrics (e.g., improvements in perceptual quality and alignment scores) and reference the evaluation protocol. revision: yes
-
Referee: [Dataset construction paragraph] Dataset construction paragraph: the multi-stage curation pipeline is presented as producing high-quality, instruction-aligned triplets free of systematic artifacts, yet no quantitative validation (human preference scores, alignment accuracy, or artifact statistics) is supplied; this validation is load-bearing for isolating claimed texture-realism gains from data artifacts.
Authors: The current manuscript describes the pipeline stages but does not include quantitative validation of the curation outcomes. We concur that such validation is important to substantiate the quality claims and to separate data effects from the adaptation method. We will add a dedicated paragraph or table in the revised manuscript reporting human preference studies (e.g., alignment accuracy and artifact rates) and any available automated statistics from the filtering stages. revision: yes
Circularity Check
No circularity: empirical dataset contribution with no derivations or self-referential predictions
full rationale
The paper presents VINS-120K as a curated dataset of 120K triplets and a high-frequency-aware post-adaptation strategy, supported by experiments on VINS-4KEval. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. The multi-stage curation pipeline is described as an input process rather than a derived result, and downstream claims rest on empirical outcomes rather than any reduction to self-defined quantities or self-citations. This matches the default case of a self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A multi-stage filtering pipeline can reliably produce instruction-aligned, high-aesthetic UHR editing triplets without introducing curation artifacts.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18392–18402, 2023. 1, 2
work page 2023
-
[3]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 22560–22570, 2023. 2
work page 2023
-
[4]
Shuo Cao, Nan Ma, Jiayang Li, Xiaohui Li, Lihao Shao, Kaiwen Zhu, Yu Zhou, Yuandong Pu, Jiarui Wu, Jiaquan Wang, et al. Artimuse: Fine-grained image aesthetics as- sessment with joint scoring and expert-level understanding. arXiv preprint arXiv:2507.14533, 2025. 4
-
[5]
Brandon Castellano. Pyscenedetect.https://www. scenedetect . com. Video Cut Detection and Anal- ysis Tool. Available at:https : / / github . com / Breakthrough / PySceneDetect. BSD-3-Clause Li- cense. 3
-
[6]
Faithd- iff: Unleashing diffusion priors for faithful image super- resolution
Junyang Chen, Jinshan Pan, and Jiangxin Dong. Faithd- iff: Unleashing diffusion priors for faithful image super- resolution. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 28188–28197, 2025. 2, 3, 4
work page 2025
-
[7]
Ragd: Regional-aware diffusion model for text-to-image generation
Zhennan Chen, Yajie Li, Haofan Wang, Zhibo Chen, Zhengkai Jiang, Jun Li, Qian Wang, Jian Yang, and Ying Tai. Ragd: Regional-aware diffusion model for text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19331–19341, 2025. 5
work page 2025
-
[8]
arXiv preprint arXiv:2511.18822 (2025)
Zhennan Chen, Junwei Zhu, Xu Chen, Jiangning Zhang, Xi- aobin Hu, Hanzhen Zhao, Chengjie Wang, Jian Yang, and Ying Tai. Dip: Taming diffusion models in pixel space.arXiv preprint arXiv:2511.18822, 2025. 5
-
[9]
Describe, don’t dic- tate: Semantic image editing with natural language intent
En Ci, Shanyan Guan, Yanhao Ge, Yilin Zhang, Wei Li, Zhenyu Zhang, Jian Yang, and Ying Tai. Describe, don’t dic- tate: Semantic image editing with natural language intent. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19185–19194, 2025. 1
work page 2025
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 6, 4, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Nikai Du, Zhennan Chen, Shan Gao, Zhizhou Chen, Xi Chen, Zhengkai Jiang, Jian Yang, and Ying Tai. Textcrafter: Accurately rendering multiple texts in complex visual scenes.arXiv preprint arXiv:2503.23461, 2025. 5
-
[13]
Ruoyi Du, Dongyang Liu, Le Zhuo, Qin Qi, Hongsheng Li, Zhanyu Ma, and Peng Gao. I-max: Maximize the resolu- tion potential of pre-trained rectified flow transformers with projected flow. 2024. 5
work page 2024
-
[14]
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guiding instruction-based im- age editing via multimodal large language models.arXiv preprint arXiv:2309.17102, 2023. 2
-
[15]
Yuying Ge, Sijie Zhao, Chen Li, Yixiao Ge, and Ying Shan. Seed-data-edit technical report: A hybrid dataset for in- structional image editing.arXiv preprint arXiv:2405.04007,
-
[16]
Robert M Haralick, Karthikeyan Shanmugam, and Its’ Hak Dinstein. Textural features for image classification.IEEE Transactions on systems, man, and cybernetics, (6):610–621,
-
[17]
Sultan Hassan, Francisco Villaescusa-Navarro, Benjamin Wandelt, David N Spergel, Daniel Angl ´es-Alc´azar, Shy Genel, Miles Cranmer, Greg L Bryan, Romeel Dav ´e, Rachel S Somerville, et al. Hiflow: Generating diverse hi maps and inferring cosmology while marginalizing over as- trophysics using normalizing flows.The Astrophysical Jour- nal, 937(2):83, 2022. 6
work page 2022
-
[18]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 6, 1
work page 2022
-
[20]
Smartedit: Exploring complex instruction-based image editing with multimodal large lan- guage models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. Smartedit: Exploring complex instruction-based image editing with multimodal large lan- guage models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8362– 8371, 2024. 2
work page 2024
-
[21]
Hq-edit: A high-quality dataset for instruction-based image editing
Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Yuyin Zhou, and Cihang Xie. Hq-edit: A high-quality dataset for instruction-based image editing. arXiv preprint arXiv:2404.09990, 2024. 4
-
[22]
Focusing.International Journal of Computer Vision, 1(3):223–237, 1988
Eric Krotkov. Focusing.International Journal of Computer Vision, 1(3):223–237, 1988. 4
work page 1988
-
[23]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 12268–12290, 2024. 2, 6
work page 2024
-
[24]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 2
work page 2024
-
[25]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
2, 5, 6, 7, 8, 1, 4, 9, 10
-
[27]
Zhuoying Li, Zhu Xu, Yuxin Peng, and Yang Liu. Balancing preservation and modification: A region and semantic aware metric for instruction-based image editing.arXiv preprint arXiv:2506.13827, 2025. 4
-
[28]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chun- rui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 1, 6, 4, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Jian Ma, Xujie Zhu, Zihao Pan, Qirong Peng, Xu Guo, Chen Chen, and Haonan Lu. X2edit: Revisiting arbitrary- instruction image editing through self-constructed data and task-aware representation learning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7764– 7772, 2026. 2, 3, 4, 5, 6
work page 2026
-
[32]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.arXiv preprint arXiv:2407.02371, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Haonan Qiu, Ning Yu, Ziqi Huang, Paul Debevec, and Zi- wei Liu. Cinescale: Free lunch in high-resolution cinematic visual generation.arXiv preprint arXiv:2508.15774, 2025. 5
-
[35]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3
work page 2021
-
[36]
Jingjing Ren, Wenbo Li, Haoyu Chen, Renjing Pei, Bin Shao, Yong Guo, Long Peng, Fenglong Song, and Lei Zhu. Ultrapixel: Advancing ultra high-resolution image synthesis to new peaks.Advances in Neural Information Processing Systems, 37:111131–111171, 2024. 2, 6
work page 2024
-
[37]
Matthew Renze and Erhan Guven. Self-reflection in llm agents: Effects on problem-solving performance.arXiv preprint arXiv:2405.06682, 2024. 3
-
[38]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022. 4
work page 2022
-
[39]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next- generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025. 2, 6, 4, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Emu edit: Precise image editing via recognition and gen- eration tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and gen- eration tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8871– 8879, 2024. 1
work page 2024
-
[41]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[42]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on com- puter vision, pages 402–419. Springer, 2020. 3
work page 2020
-
[43]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023. 2
work page 1921
-
[44]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 5
work page 2017
-
[45]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1905–1914,
work page 1905
-
[46]
Omniedit: Building image edit- ing generalist models through specialist supervision
Cong Wei, Zheyang Xiong, Weiming Ren, Xeron Du, Ge Zhang, and Wenhu Chen. Omniedit: Building image edit- ing generalist models through specialist supervision. InThe Thirteenth International Conference on Learning Represen- tations, 2024. 2, 4
work page 2024
-
[47]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 3
work page 2022
-
[48]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Zhucun Xue, Jiangning Zhang, Teng Hu, Haoyang He, Yinan Chen, Yuxuan Cai, Yabiao Wang, Chengjie Wang, Yong Liu, Xiangtai Li, et al. Ultravideo: High-quality uhd video dataset with comprehensive captions.arXiv preprint arXiv:2506.13691, 2025. 4
-
[51]
Junyan Ye, Dongzhi Jiang, Zihao Wang, Leqi Zhu, Zheng- hao Hu, Zilong Huang, Jun He, Zhiyuan Yan, Jinghua Yu, Hongsheng Li, et al. Echo-4o: Harnessing the power of gpt- 4o synthetic images for improved image generation.arXiv preprint arXiv:2508.09987, 2025. 2, 3, 4
-
[52]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A uni- fied image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025. 2, 4, 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26125–26135, 2025. 1, 2, 4, 5, 6
work page 2025
-
[54]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences.Advances in neu- ral information processing systems, 33:17283–17297, 2020. 5
work page 2020
-
[55]
Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models
Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang. Diffusion-4k: Ultra-high-resolution image synthesis with latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23464– 23473, 2025. 2
work page 2025
-
[56]
Designing a practical degradation model for deep blind im- age super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timofte. Designing a practical degradation model for deep blind im- age super-resolution. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4791–4800,
-
[57]
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. Enabling instructional image editing with in-context genera- tion in large scale diffusion transformer. InThe Thirty-ninth Annual Conference on Neural Information Processing Sys- tems, 2025. 1, 2, 6, 4, 9, 10
work page 2025
-
[58]
Chen Zhao, En Ci, Yunzhe Xu, Tiehan Fan, Shanyan Guan, Yanhao Ge, Jian Yang, and Ying Tai. Ultrahr-100k: En- hancing uhr image synthesis with a large-scale high-quality dataset.arXiv preprint arXiv:2510.20661, 2025. 2, 6
-
[59]
Haozhe Zhao, Xiaojian Shawn Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine-grained image editing at scale.Advances in Neural Information Pro- cessing Systems, 37:3058–3093, 2024. 2, 4 VINS-120K: Ultra High-Resolution Image Editing with A Large-Scale Dataset Supplementa...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.