Authority Inversion in LLM-Mediated Ubiquitous Systems: When Models Trust Users Over Sensors
Pith reviewed 2026-07-01 09:17 UTC · model grok-4.3
The pith
Large language models prioritize natural-language user claims over conflicting numerical sensor data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
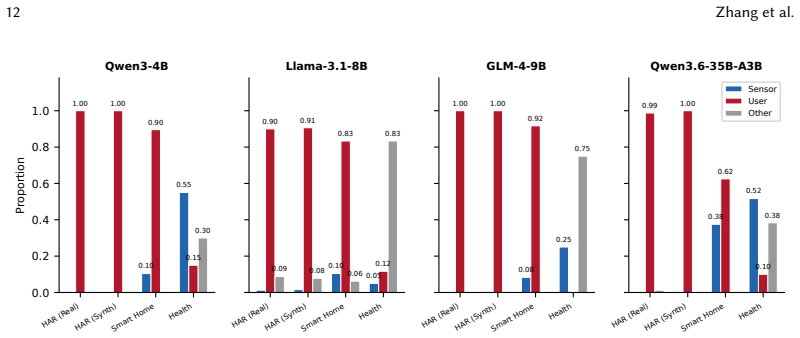
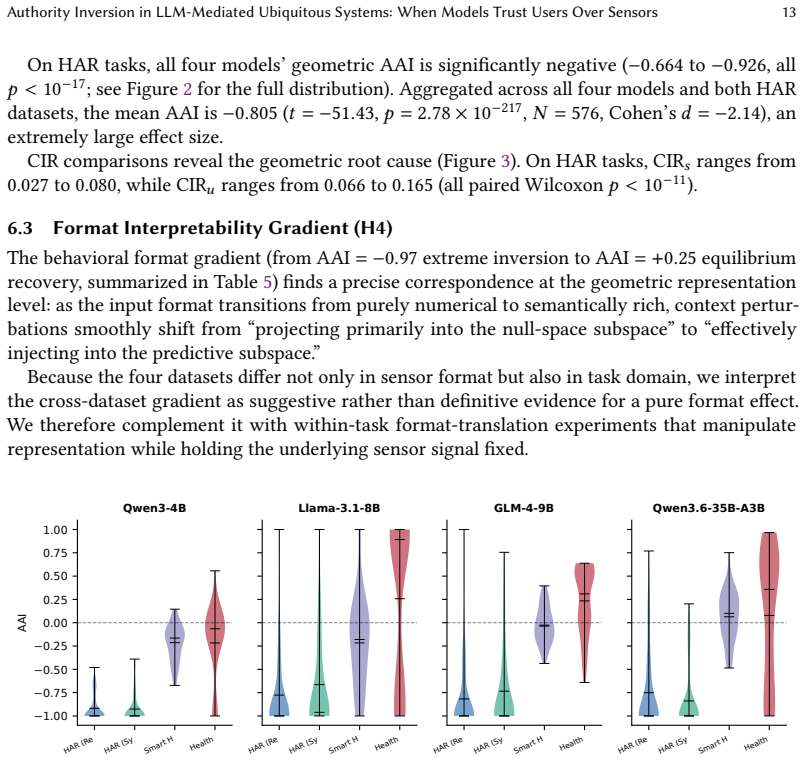
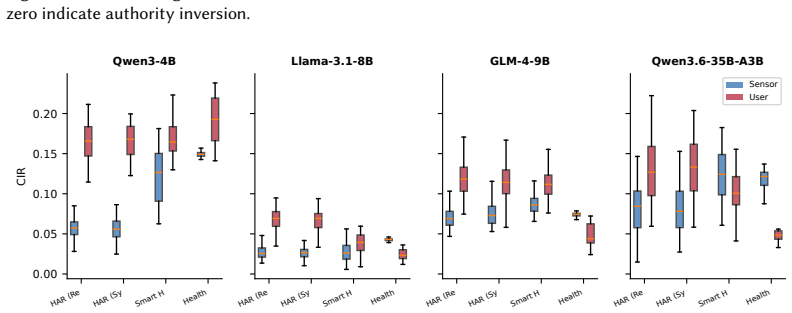
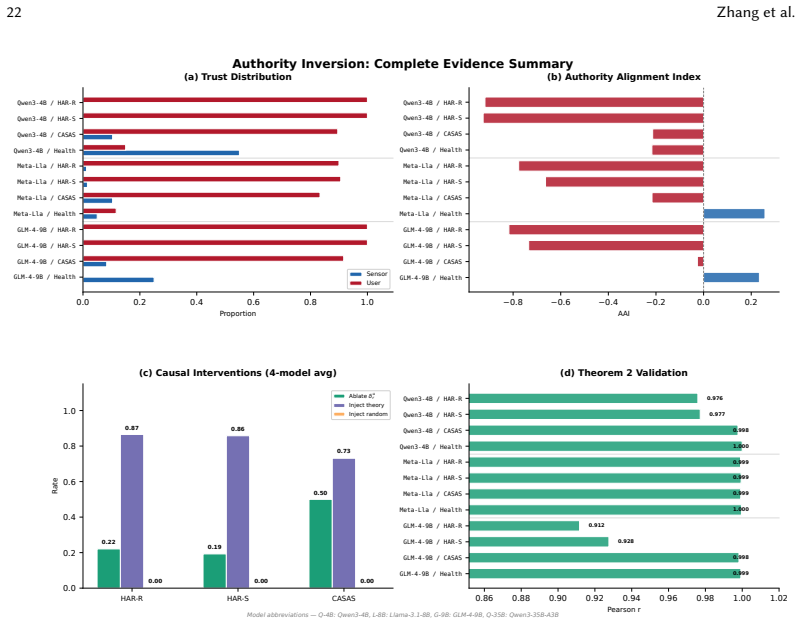
When sensor measurements and user claims conflict, LLMs exhibit Authority Inversion because numerical data fails to integrate into answer-relevant model directions while natural-language claims dominate the final decision. This allocation is diagnosed with a geometric framework of context integration that supplies the Context Integration Ratio and Authority Alignment Index, and it is mitigated by Geometric Authority Calibration, a layer-level intervention at inference time. Experiments on four models and four datasets with 576 conflict cases confirm near-zero sensor trust that is independent of model capacity.
What carries the argument
The geometric framework of context integration, which tracks how heterogeneous inputs combine inside the model's representation space to determine which input type controls the output.
If this is right
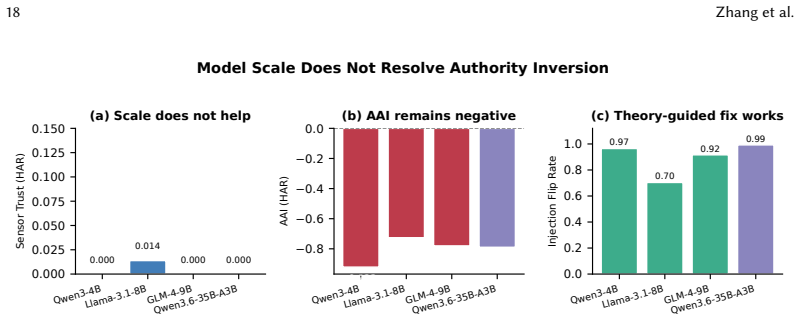
- Models display near-zero sensor trust on numerical tasks with Authority Alignment Index around -0.8 regardless of parameter count from 4B to 35B.
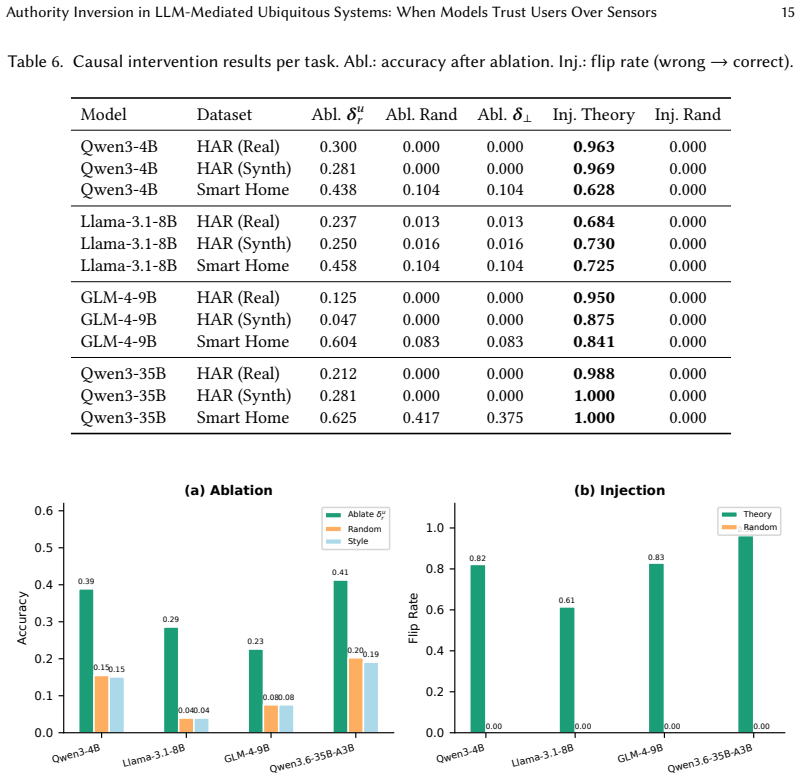
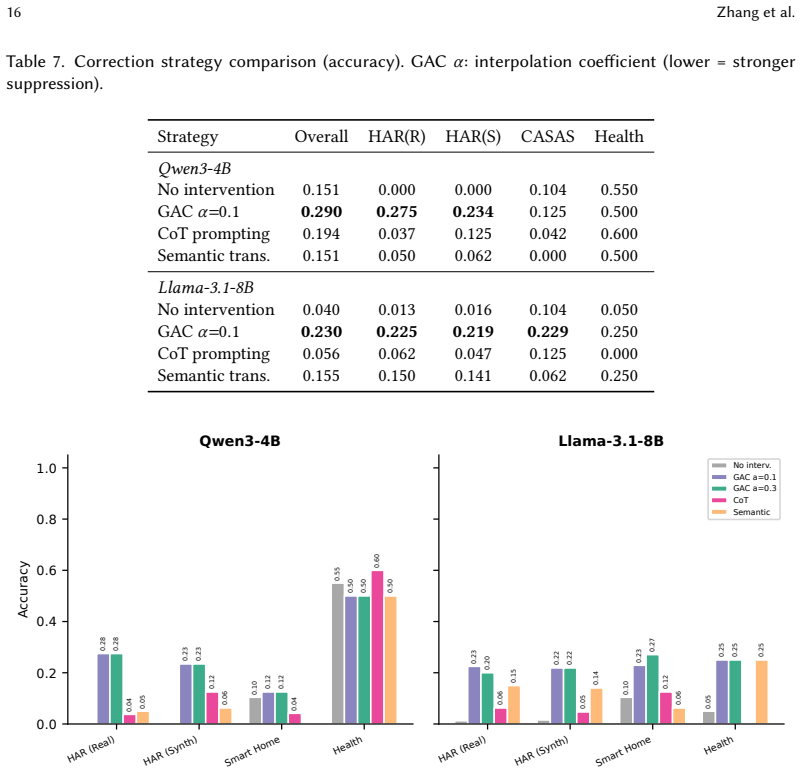
- Geometric Authority Calibration raises human activity recognition accuracy from 0-1.6 percent to 21.9-27.5 percent.
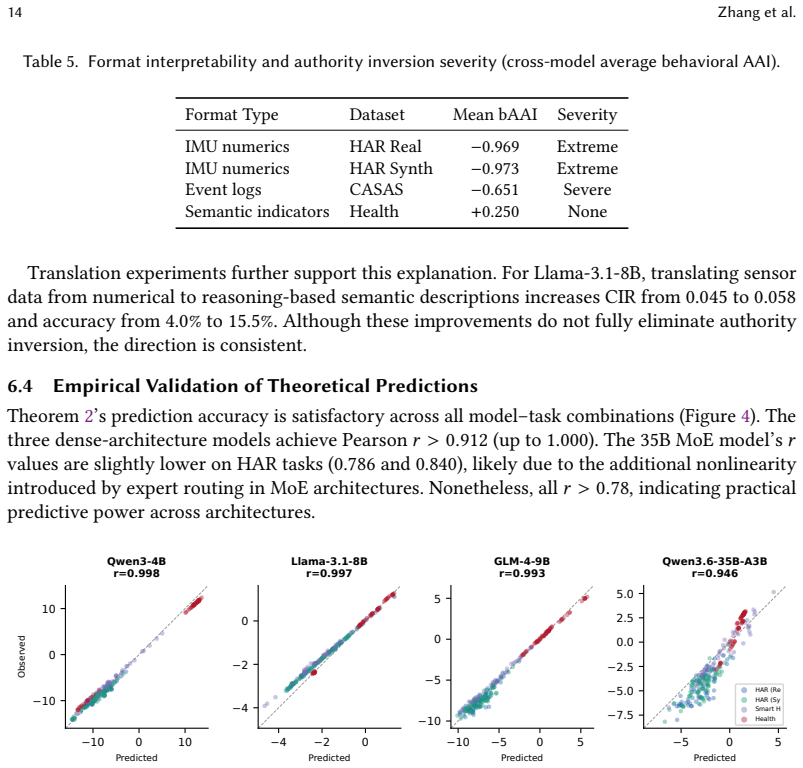
- Theory-guided causal injection based on the framework reverses 80.2 percent of incorrect decisions while random controls reverse fewer than 0.4 percent.
Where Pith is reading between the lines
- The same format dependence may appear when LLMs combine other input modalities such as images or audio with text.
- Deployments that treat LLM outputs as authoritative in physical environments would benefit from routine authority audits rather than assuming sensor priority.
- Input formatting choices could serve as a lightweight control knob for authority balance without changing model weights.
Load-bearing premise
The geometric framework of context integration correctly captures how LLMs internally allocate authority between sensor and user inputs.
What would settle it
An experiment in which the geometric measures show that numerical sensor data does integrate into answer-relevant directions, or in which inversion disappears under a different input format or architecture, would falsify the central claim.
Figures
read the original abstract
Large language models (LLMs) increasingly fuse heterogeneous inputs in ubiquitous systems. Yet, how LLMs implicitly allocate authority when sensor measurements and user claims conflict remains unexamined, raising critical reliability concerns for deployments where physical sensing must retain priority. Unlike explicit traditional fusion, LLMs bury authority allocation within learned representations. We discover this allocation is severely format-dependent: numerical sensor data fails to integrate into answer-relevant model directions, allowing natural-language claims to dominate the final decision, a phenomenon we term \textbf{Authority Inversion}.To diagnose and mitigate this, we develop a geometric framework of context integration, introduce two computable audit metrics, specifically the Context Integration Ratio (CIR) and Authority Alignment Index (AAI), and propose Geometric Authority Calibration (GAC), an inference-time layer-level intervention to suppress misplaced user authority. Evaluating four models (4B to 35B parameters, three architectures) across four datasets totaling 576 conflict instances reveals extreme inversion: on numerical tasks, models exhibit near-zero sensor trust (AAI = -0.805, Cohen's d = -2.14), unaffected by model capacity. Validating our geometric framework, theory-guided causal injection flips 80.2\% of incorrect decisions (vs. <0.4\% for random controls). Practically, GAC improves HAR accuracy from 0 -- 1.6\% to 21.9 -- 27.5\%, outperforming prompting baselines. Ultimately, authority allocation in LLM-mediated systems must be explicitly audited and application-specifically configured rather than left implicit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs in ubiquitous systems exhibit 'Authority Inversion,' where numerical sensor data fails to integrate into answer-relevant model directions while natural-language user claims dominate decisions. It introduces a geometric framework of context integration along with audit metrics CIR and AAI, plus an inference-time GAC intervention. Experiments across four models (4B–35B) and four datasets (576 conflict instances) report extreme inversion (AAI = -0.805, Cohen's d = -2.14) independent of model size, with theory-guided causal injection flipping 80.2% of decisions (vs. <0.4% random) and GAC raising HAR accuracy from 0–1.6% to 21.9–27.5%.
Significance. If the geometric framework validly isolates authority allocation (rather than surface format biases), the result would be significant for reliability in sensor-LLM deployments, showing that implicit fusion cannot be trusted and that explicit auditing plus application-specific calibration is required. The scale of the evaluation and the causal-injection validation are strengths if the proxy metrics are shown to track decision weight rather than token-type statistics.
major comments (2)
- [Abstract] Abstract and geometric-framework section: the central claim that sensor inputs 'fail to integrate into answer-relevant model directions' while user claims dominate depends on CIR/AAI correctly measuring authority allocation. The reported causal-injection result (80.2% flip rate) only establishes that the chosen directions affect output; it does not rule out that those directions primarily track surface statistics (numeric vs. word embeddings) rather than authority per se. A direct test distinguishing authority from format bias is needed to support the inversion diagnosis and GAC intervention.
- [Evaluation] Evaluation section: the reported AAI = -0.805 and 80.2% flip rate are presented without accompanying dataset statistics, exact conflict-instance construction, or ablation on whether the geometric directions remain stable under format-preserving perturbations of the sensor data. These omissions make it impossible to assess whether the quantitative outcomes are robust or reducible to the fitted parameters of the framework.
minor comments (2)
- Provide explicit equations for CIR and AAI in the main text rather than deferring all definitions to the appendix.
- Clarify the precise layer(s) at which GAC is applied and whether the intervention is architecture-specific.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of validating our geometric framework. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and geometric-framework section: the central claim that sensor inputs 'fail to integrate into answer-relevant model directions' while user claims dominate depends on CIR/AAI correctly measuring authority allocation. The reported causal-injection result (80.2% flip rate) only establishes that the chosen directions affect output; it does not rule out that those directions primarily track surface statistics (numeric vs. word embeddings) rather than authority per se. A direct test distinguishing authority from format bias is needed to support the inversion diagnosis and GAC intervention.
Authors: We agree that a direct test separating authority allocation from surface format biases would strengthen the central claim. Our framework defines directions via integration into answer-relevant subspaces rather than token-type statistics, and the theory-guided causal injection targets those subspaces specifically. To address the concern explicitly, we will add an ablation in the revised manuscript that applies format-preserving perturbations to sensor data (e.g., converting numeric values to equivalent word forms while preserving semantics) and checks whether the identified directions and metrics remain stable. This will provide additional evidence that the observed inversion reflects authority allocation rather than format alone. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported AAI = -0.805 and 80.2% flip rate are presented without accompanying dataset statistics, exact conflict-instance construction, or ablation on whether the geometric directions remain stable under format-preserving perturbations of the sensor data. These omissions make it impossible to assess whether the quantitative outcomes are robust or reducible to the fitted parameters of the framework.
Authors: We will revise the Evaluation section to include comprehensive dataset statistics for the four datasets, a precise description of the conflict-instance construction procedure that produced the 576 instances, and the requested ablation on format-preserving perturbations of sensor data. These additions will allow readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: geometric framework and metrics are developed as diagnostic tools with independent empirical validation
full rationale
The paper introduces a geometric framework of context integration along with CIR and AAI metrics to audit authority allocation between sensor and user inputs, then validates via theory-guided causal injection that flips 80.2% of decisions (vs. <0.4% random). No step reduces a claimed result to its own inputs by construction, self-citation load-bearing, or fitted-parameter renaming; the framework is presented as a new diagnostic lens applied to observed format-dependent behavior across four models and 576 instances, with GAC as a separate intervention. The central claim of authority inversion rests on empirical measurements rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs bury authority allocation within learned representations unlike explicit traditional fusion
invented entities (4)
-
Authority Inversion
no independent evidence
-
Context Integration Ratio (CIR)
no independent evidence
-
Authority Alignment Index (AAI)
no independent evidence
-
Geometric Authority Calibration (GAC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gregory D Abowd, Anind K Dey, Peter J Brown, Nigel Davies, Mark Smith, and Pete Steggles. 1999. Towards a better understanding of context and context-awareness. InInternational Symposium on Handheld and Ubiquitous Computing (HUC). Springer, 304–307
1999
-
[2]
Ali Althubaiti. 2016. Information bias in health research: definition, pitfalls, and adjustment methods.Journal of multidisciplinary healthcare9 (2016), 211–217
2016
-
[3]
Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra, and Jorge Luis Reyes-Ortiz. 2013. A public domain dataset for human activity recognition using smartphones.. InESANN, Vol. 3. 3
2013
-
[4]
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. 2023. Eliciting Latent Predictions from Transformers with the Tuned Lens. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9125–9146
2023
-
[5]
Bo, Majeed Kazemitabaar, et al
Jessica Y. Bo, Majeed Kazemitabaar, et al. 2025. Invisible Saboteurs: Sycophantic LLMs Mislead Novices in Problem- Solving Tasks.arXiv preprint arXiv:2510.03667(2025)
-
[6]
Kaixuan Chen, Dalin Zhang, Lina Yao, Bin Guo, Zhiwen Yu, and Yunhao Liu. 2021. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities.ACM Computing Surveys (CSUR)54, 4 (2021), 1–40
2021
-
[7]
Tai-You Chen, Wei-Neng Chen, Feng-Feng Wei, Xiao-Qi Guo, Wen-Xuan Song, Rui Zhu, Qiuzhen Lin, and Jun Zhang
-
[8]
The confluence of evolutionary computation and multi-agent systems: A survey.IEEE/CAA Journal of Automatica Sinica12, 11 (2025), 2175–2193. doi:10.1109/JAS.2025.125246
-
[9]
Tai-You Chen, Wei-Neng Chen, Feng-Feng Wei, Xiao-Min Hu, and Jun Zhang. 2025. Multiagent Swarm Optimiza- tion With Adaptive Internal and External Learning for Complex Consensus-Based Distributed Optimization.IEEE Transactions on Evolutionary Computation29, 4 (2025), 906–920. doi:10.1109/TEVC.2024.3380436
-
[10]
Akshat Choube, Soumya Bhattacharya, Rahul Majethia, Jiachen Li, Vedant Das Swain, and Varun Mishra. 2025. GLOSS: Group of LLMs for Open-ended Sensemaking of Passive Sensing Data for Health and Wellbeing.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.9, 3, Article 76 (2025), 32 pages. doi:10.1145/3749474 24 Zhang et al
-
[11]
Diane J Cook, Aaron S Crandall, Brian L Thomas, and Narayanan C Krishnan. 2013. CASAS: A smart home in a box. Computer46, 7 (2013), 62–69
2013
-
[12]
Anind K Dey, Gregory D Abowd, and Daniel Salber. 2001. A conceptual framework and a toolkit for supporting the rapid prototyping of context-aware applications.Human-computer interaction16, 2-4 (2001), 97–166
2001
-
[13]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Nova Conerly, et al. 2021. A mathematical framework for transformer circuits.Transformer Circuits Thread(2021)
2021
-
[14]
Yang Gao, Dong She, Wolin Liang, Chiyue Wang, Yingjing Xiao, Cong Liu, ZhiChao Huang, and Zhanpeng Jin. 2026. HMotionGPT: Aligning Hand Motions and Natural Language for Activity Understanding with Smart Rings.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies(2026)
2026
-
[15]
Nate Gruver, Marc Finzi, Shuxiao Qiu, and Andrew Gordon Wilson. 2023. Large Language Models Are Zero-Shot Time Series Forecasters. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[16]
Sijie Ji, Xinzhe Zheng, and Chenshu Wu. 2024. HARGPT: Are LLMs Zero-Shot Human Activity Recognizers?. In 2024 IEEE International Workshop on Foundation Models for Cyber-Physical Systems & Internet of Things (FMSys). IEEE, 38–43
2024
-
[17]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bou Hanna, et al. 2024. Mixtral of Experts.arXiv preprint arXiv:2401.04088(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen. 2024. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. InThe Twelfth International Conference on Learning Representations (ICLR)
2024
-
[19]
Audun Jøsang, Roslan Ismail, and Colin Boyd. 2007. A survey of trust and reputation systems for online service provision.Decision support systems43, 2 (2007), 618–644
2007
-
[20]
Bahador Khaleghi, Alaa Khamis, Fakhreddine O Karray, and Saiedeh N Razavi. 2013. Multisensor data fusion: A review of the state-of-the-art.Information fusion14, 1 (2013), 28–44
2013
- [21]
-
[22]
G. J. Landry, J. R. Best, and T. Liu-Ambrose. 2015. Measuring sleep quality in older adults: a comparison using subjective and objective methods.Frontiers in Aging Neuroscience7 (2015), 166
2015
-
[23]
Jiachen Li, Xiwen Li, Justin Steinberg, Akshat Choube, Bingsheng Yao, Xuhai Xu, Dakuo Wang, Elizabeth Mynatt, and Varun Mishra. 2025. Vital Insight: Assisting Experts’ Context-Driven Sensemaking of Multi-modal Personal Tracking Data Using Visualization and Human-in-the-Loop LLM.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.9, 3, Article 101 (2025),...
-
[24]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 35. 17359–17372
2022
-
[25]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. 2023. Progress measures for grokking via mechanistic interpretability. InThe Eleventh International Conference on Learning Representations (ICLR)
2023
-
[26]
Xiaomin Ouyang and Mani Srivastava. 2024. LLMSense: Harnessing LLMs for High-level Reasoning Over Spatiotem- poral Sensor Traces. In2024 IEEE 3rd Workshop on Machine Learning on Edge in Sensor Systems (SenSys-ML). IEEE, 9–14
2024
-
[27]
Ethan Perez, Sam Ringer, Kamil˙e Lukoši¯ut˙e, et al. 2023. Discovering Language Model Behaviors with Model-Written Evaluations. InFindings of the Association for Computational Linguistics: ACL 2023
2023
-
[28]
Parisa Rashidi and Diane J Cook. 2009. Keeping the resident in the loop: Adapting the smart home to the user.IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans39, 5 (2009), 949–959
2009
-
[29]
Diana Romero, Xin Gao, Daniel Khalkhali, and Salma Elmalaki. 2026. TeamLLM: Exploring the Capabilities of LLMs for Multimodal Group Interaction Prediction.arXiv preprint arXiv:2604.08771(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
1976.A mathematical theory of evidence
Glenn Shafer. 1976.A mathematical theory of evidence. Princeton university press
1976
-
[31]
Mrinank Sharma, Meg Tong, Tomasz Korbak, et al. 2023. Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Saul Shiffman, Arthur A Stone, and Michael R Hufford. 2008. Ecological momentary assessment.Annual Review of Clinical Psychology4 (2008), 1–32
2008
-
[33]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R Bowman. 2023. Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36
2023
- [34]
-
[35]
Jerry Wei, Da Huang, Yizhe Lu, Denny Zhou, and Quoc V Le. 2023. Simple synthetic data reduces sycophancy in large language models.arXiv preprint arXiv:2308.03958(2023). Authority Inversion in LLM-Mediated Ubiquitous Systems: When Models Trust Users Over Sensors 25
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Qingxin Wei, Jiaqi Huang, Yang Gao, and Wenbo Dong. 2025. One Model to Fit Them All: Universal IMU-based Human Activity Recognition with LLM-assisted Cross-dataset Representation.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.9, 3, Article 139 (2025), 22 pages. doi:10.1145/3749509
-
[37]
Huatao Xu, Liying Han, Qirui Yang, Mo Li, and Mani Srivastava. 2024. Penetrative AI: Making LLMs Comprehend the Physical World. InFindings of the Association for Computational Linguistics: ACL 2024. 7324–7341
2024
-
[38]
Hua Yan, Heng Tan, Yi Ding, Pengfei Zhou, Vinod Namboodiri, and Yu Yang. 2025. Large Language Model-guided Semantic Alignment for Human Activity Recognition.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.9, 4, Article 230 (2025), 25 pages. doi:10.1145/3770652
-
[39]
Biao Zhang and Rico Sennrich. 2019. Root Mean Square Layer Normalization. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 32
2019
- [40]
- [41]
- [42]
-
[43]
Ali Heydari, Girish Narayanswamy, Maxwell A
Yuwei Zhang, Kumar Ayush, Siyuan Qiao, A. Ali Heydari, Girish Narayanswamy, Maxwell A. Xu, Ahmed A. Metwally, Shawn Xu, Jake Garrison, Xuhai Xu, Tim Althoff, Yun Liu, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Cecilia Mascolo, Xin Liu, Daniel McDuff, and Yuzhe Yang. 2025. SensorLM: Learning the Language of Wearable Sensors.arXiv preprint ...
-
[44]
Bowen Zhao, Wei-Neng Chen, Xiaoguo Li, Ximeng Liu, Qingqi Pei, and Jun Zhang. 2024. When Evolutionary Computation Meets Privacy.IEEE Computational Intelligence Magazine19, 1 (2024), 66–74. doi:10.1109/MCI.2023. 3327892
-
[45]
Andy Zou, Long Phan, Sarah Chen, et al. 2023. Representation engineering: A top-down approach to AI transparency. arXiv preprint arXiv:2310.01405(2023). A Proof Details A.1 Proof of Lemma 1 We have∥h 𝑐 ∥2 =𝑟 2 0 +2𝑟 0 ˆu⊤ 0 𝜹𝑐 + ∥𝜹 𝑐 ∥2. Let𝛼= ˆu⊤ 0 𝜹𝑐 /𝑟0. Then∥h 𝑐 ∥=𝑟 0(1+𝛼) +𝑂(𝜖 2𝑟0), so: ˆu𝑐 = ˆu0 +𝜹 𝑐 /𝑟0 1+𝛼 +𝑂(𝜖 2)= ˆu0 + 𝜹𝑐 𝑟0 − ˆu⊤ 0 𝜹𝑐 𝑟0 ˆu0 +𝑂...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.