Stop Comparing LLM Agents Without Disclosing the Harness
Pith reviewed 2026-06-30 23:13 UTC · model grok-4.3
The pith
The execution harness often determines LLM agent performance more than the model it wraps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
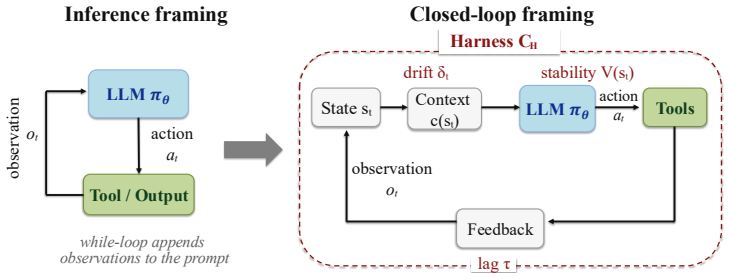
The Binding Constraint Thesis states that, for long-horizon tasks with comparable frontier models, performance variance is governed more by harness configuration than by model choice, and current evaluation protocols therefore systematically misattribute harness-level gains to model improvements. The thesis is defended by treating the harness as the controller of a closed-loop dynamical system whose LLM component functions as the governed stochastic policy, by showing through benchmark analysis and variance decomposition that harness-induced variance can substantially exceed model-induced variance including cases of ranking reversal, and by outlining a harness-aware evaluation framework that
What carries the argument
The Binding Constraint Thesis, which treats the harness as controller of a closed-loop dynamical system and the LLM as the stochastic policy it governs.
If this is right
- Current leaderboard comparisons of long-horizon agents are incomplete and potentially misleading without harness disclosure.
- Harness configuration changes can produce performance shifts larger than those obtained by substituting one model for another.
- Model rankings can reverse when the same models are evaluated under different harnesses.
- A standardized disclosure requirement and variance decomposition protocol are needed to isolate model contributions.
Where Pith is reading between the lines
- Agent research may benefit more from systematic harness tuning than from repeated model swaps in the current regime.
- The same confounding pattern could appear in evaluations of other composite AI systems where supporting layers are not reported.
- Requiring harness disclosure would allow future meta-analyses to quantify the relative contribution of infrastructure versus model across published results.
Load-bearing premise
The control-theoretic view that treats the harness as controller and the LLM as policy accurately explains why small harness changes can exceed model substitution effects.
What would settle it
A controlled study that fixes one harness across several frontier models and measures model-induced variance, then fixes one model across several harness configurations and measures harness-induced variance, showing the latter does not exceed the former.
Figures
read the original abstract
This position paper argues that, for long-horizon tasks evaluated across models with comparable frontier capability, the agent execution harness, namely the infrastructure layer that governs context construction, tool interaction, orchestration, and verification around a language model, is often a stronger determinant of agent performance than the model it wraps. We formalize and defend the Binding Constraint Thesis: in this regime, performance variance is governed more by harness configuration than by model choice, and current evaluation protocols therefore systematically misattribute harness-level gains to model improvements. We support this thesis along three lines. First, a control-theoretic formalization treats the harness as the controller of a closed-loop dynamical system and the LLM as the stochastic policy it governs, which explains why small harness changes can produce performance shifts that exceed those obtained by substituting one model for another. Second, published benchmarks, industry deployments, and a controlled variance decomposition show that harness-induced variance can substantially exceed model-induced variance, including cases of model ranking reversal. Third, we propose a harness-aware evaluation framework with a disclosure standard and a variance decomposition protocol. Until harness specifications are disclosed, leaderboard comparisons for long-horizon agents should be treated as incomplete and potentially misleading.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that for long-horizon LLM agent tasks evaluated across models with comparable frontier capability, the agent execution harness (infrastructure governing context construction, tool interaction, orchestration, and verification) is often a stronger determinant of performance than the model itself. It formalizes the Binding Constraint Thesis—that performance variance is governed more by harness configuration than model choice, causing current evaluation protocols to misattribute harness-level gains to model improvements—and supports the thesis via a control-theoretic formalization (harness as closed-loop controller, LLM as stochastic policy), references to published benchmarks/industry deployments/variance decompositions showing harness variance exceeding model variance (including ranking reversals), and a proposed harness-aware evaluation framework with disclosure standards and variance decomposition protocol.
Significance. If the Binding Constraint Thesis holds, the result would be significant for LLM agent evaluation practices, indicating that leaderboards are systematically incomplete without harness disclosure and that variance decomposition protocols could yield more reliable model comparisons. The control-theoretic framing, if made rigorous, offers a potentially useful lens for explaining why small harness changes can dominate model substitution effects.
major comments (2)
- [control-theoretic formalization (first support line)] The control-theoretic formalization (first line of support in the abstract): the argument is presented at a high level only and invokes standard control models without addressing how they accommodate the discrete, non-stationary state transitions, context truncation, tool failures, and multi-turn memory that characterize LLM agent execution. Absent explicit assumptions on observability and stationarity, this does not establish that harness effects are binding in the claimed regime or explain performance shifts exceeding model substitution.
- [empirical support (second support line)] The empirical support via published benchmarks, industry deployments, and controlled variance decomposition (second line of support in the abstract): the manuscript supplies no new data, derivations, or error analysis and does not report specific variance numbers, decomposition results, or the protocol details, making it impossible to assess the claim that harness-induced variance substantially exceeds model-induced variance or produces ranking reversals.
minor comments (2)
- [introduction] The definition of 'harness' appears in the abstract but would benefit from an operational definition with concrete components (e.g., context window management, tool-calling loop) in the introduction to ground subsequent claims.
- [proposed framework] The proposed harness-aware evaluation framework is outlined at the end of the abstract but lacks a concrete example of the disclosure standard or variance decomposition protocol, which would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight areas where the position paper's arguments can be strengthened. We address each major comment below, indicating planned revisions where appropriate. As this is a position paper, our responses focus on clarifying the scope and enhancing rigor without introducing new empirical work.
read point-by-point responses
-
Referee: [control-theoretic formalization (first support line)] The control-theoretic formalization (first line of support in the abstract): the argument is presented at a high level only and invokes standard control models without addressing how they accommodate the discrete, non-stationary state transitions, context truncation, tool failures, and multi-turn memory that characterize LLM agent execution. Absent explicit assumptions on observability and stationarity, this does not establish that harness effects are binding in the claimed regime or explain performance shifts exceeding model substitution.
Authors: We agree the formalization is presented at a high level. In revision, we will expand the relevant section to specify assumptions on partial observability (harness observes tool outputs and context state) and non-stationarity (due to context truncation and evolving task state), and explain accommodation of discrete transitions, tool failures, and multi-turn memory via the harness's closed-loop orchestration. This will more rigorously link the controller-policy framing to performance shifts exceeding model substitution in the long-horizon regime. revision: yes
-
Referee: [empirical support (second support line)] The empirical support via published benchmarks, industry deployments, and controlled variance decomposition (second line of support in the abstract): the manuscript supplies no new data, derivations, or error analysis and does not report specific variance numbers, decomposition results, or the protocol details, making it impossible to assess the claim that harness-induced variance substantially exceeds model-induced variance or produces ranking reversals.
Authors: As a position paper, the manuscript synthesizes evidence from existing published benchmarks and deployments rather than presenting new data or derivations. We will revise to extract and report specific variance numbers, decomposition results, and protocol details from the cited sources (including explicit references to ranking reversal cases), enabling readers to evaluate the relative magnitudes of harness vs. model variance. revision: partial
Circularity Check
No significant circularity; thesis supported by external benchmarks and controlled experiments
full rationale
The paper's Binding Constraint Thesis is supported along three lines: a control-theoretic formalization (explanatory analogy, not a fitted prediction), published benchmarks and industry deployments (external references), and a controlled variance decomposition (empirical protocol). No step reduces a claimed result to a self-defined quantity, a fitted input renamed as prediction, or a load-bearing self-citation chain. The derivation remains self-contained against external evidence and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The harness functions as the controller of a closed-loop dynamical system with the LLM acting as the stochastic policy.
Reference graph
Works this paper leans on
-
[1]
Opencode: The open source coding agent., 2025
Anomaly. Opencode: The open source coding agent., 2025. URL https://github.com/ anomalyco/opencode
2025
-
[2]
Claude-code, 2025
Anthropic. Claude-code, 2025. URLhttps://github.com/anthropics/claude-code
2025
-
[3]
I improved 15 LLMs at coding in one afternoon
Can Bölük. I improved 15 LLMs at coding in one afternoon. Only the harness changed., February 2026. URLhttps://blog.can.ac/2026/02/12/the-harness-problem/
2026
-
[4]
Why benchmarking is hard
Florian Brand and JSD. Why benchmarking is hard. Epoch AI, Gradient Updates, December
-
[5]
URLhttps://epochai.substack.com/p/why-benchmarking-is-hard
-
[6]
Yuxuan Cai, Lu Chen, Qiaoling Chen, Yuyang Ding, Liwen Fan, Wenjie Fu, Yufei Gao, Honglin Guo, Pinxue Guo, Zhenhua Han, et al. Nex-n1: Agentic models trained via a unified ecosystem for large-scale environment construction.arXiv preprint arXiv:2512.04987, 2025
-
[7]
Mle-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, et al. Mle-bench: Evaluating machine learning agents on machine learning engineering. InThe Thirteenth International Conference on Learning Representations
-
[8]
Deepseek-v4: Towards highly efficient million-token context intelligence, April
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, April
-
[9]
URL https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/ DeepSeek_V4.pdf
-
[10]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Chris Ge, Daria Kryvosheieva, Daniel Fried, Uzay Girit, and Kaivalya Hariharan. Agent psychometrics: Task-level performance prediction in agentic coding benchmarks.arXiv preprint arXiv:2604.00594, 2026
-
[12]
Terminus-2, 2026
Harbor. Terminus-2, 2026. URL https://www.harborframework.com/docs/agents/ terminus-2
2026
-
[13]
Automated Design of Agentic Systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations
-
[15]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, et al. Holistic agent leaderboard: The missing infrastructure for ai agent evaluation.arXiv preprint arXiv:2510.11977, 2025
-
[17]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Deepagent: A general reasoning agent with scalable toolsets
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, Guanting Dong, Jiajie Jin, Yinuo Wang, Hao Wang, Yutao Zhu, Ji-Rong Wen, Yuan Lu, et al. Deepagent: A general reasoning agent with scalable toolsets. InProceedings of the ACM Web Conference 2026, pages 2219–2230, 2026
2026
-
[19]
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Jiahang Lin, Shichun Liu, Chengjun Pan, Lizhi Lin, Shihan Dou, Xuanjing Huang, Hang Yan, Zhenhua Han, and Tao Gui. Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses, 2026. URLhttps://arxiv.org/abs/2604.25850. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Autoharness: Improving llm agents by automatically synthesizing a code harness
Xinghua Lou, Miguel Lázaro-Gredilla, Antoine Dedieu, Carter Wendelken, Wolfgang Lehrach, and Kevin P Murphy. Autoharness: improving llm agents by automatically synthesizing a code harness.arXiv preprint arXiv:2603.03329, 2026
-
[22]
Scaling Managed Agents: Decoupling the brain from the hands, April 2026
Lance Martin, Gabe Cemaj, and Michael Cohen. Scaling Managed Agents: Decoupling the brain from the hands, April 2026. URL https://www.anthropic.com/engineering/ managed-agents
2026
-
[23]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[25]
Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering? InInterna- tional Conference on Machine Learning, pages 44412–44450
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering? InInterna- tional Conference on Machine Learning, pages 44412–44450. PMLR, 2025
2025
-
[26]
Kimi-k2.6, April 2026
Moonshot AI. Kimi-k2.6, April 2026. URL https://huggingface.co/moonshotai/ Kimi-K2.6
2026
-
[27]
SWE-Bench Pro Leaderboard (2026): Why 46% Beats 81%, March 2026
Morph. SWE-Bench Pro Leaderboard (2026): Why 46% Beats 81%, March 2026. URL https://www.morphllm.com/swe-bench-pro
2026
-
[28]
Codex cli, 2025
OpenAI. Codex cli, 2025. URLhttps://developers.openai.com/codex/cli
2025
-
[29]
Introducing gpt-5.4, March 2026
OpenAI. Introducing gpt-5.4, March 2026. URL https://openai.com/index/ introducing-gpt-5-4/
2026
-
[30]
Training Software Engineering Agents and Verifiers with SWE-Gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym.arXiv preprint arXiv:2412.21139, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
We removed 80% of our agent’s tools, December 2025
Andrew Qu. We removed 80% of our agent’s tools, December 2025. URL https://vercel. com/blog/we-removed-80-percent-of-our-agents-tools
2025
-
[32]
Harness design for long-running application develop- ment, March 2026
Prithvi Rajasekaran. Harness design for long-running application develop- ment, March 2026. URL https://www.anthropic.com/engineering/ harness-design-long-running-apps
2026
-
[33]
Hermes agent — the agent that grows with you, 2026
Nous Research. Hermes agent — the agent that grows with you, 2026. URL https:// hermes-agent.nousresearch.com/
2026
-
[34]
Raising the Bar on SWE-bench Verified with Claude 3.5 Sonnet, January 2025
Erik Schluntz. Raising the Bar on SWE-bench Verified with Claude 3.5 Sonnet, January 2025. URLhttps://www.anthropic.com/research/swe-bench-sonnet
2025
-
[35]
Seeing like an agent: How we design tools in Claude Code, April 2026
Thariq Shihipar. Seeing like an agent: How we design tools in Claude Code, April 2026. URL https://claude.com/blog/seeing-like-an-agent
2026
-
[36]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[37]
Qwen3.6-plus: Towards real world agents, April 2026
Qwen Team. Qwen3.6-plus: Towards real world agents, April 2026. URL https://qwenlm. github.io/blog/qwen3.6/
2026
-
[38]
Improving Deep Agents with harness engineer- ing, February 2026
Vivek Trivedy. Improving Deep Agents with harness engineer- ing, February 2026. URL https://www.langchain.com/blog/ improving-deep-agents-with-harness-engineering. 11
2026
-
[39]
SWE-Bench, 2026
Vals AI. SWE-Bench, 2026. URLhttps://www.vals.ai/benchmarks/swebench
2026
-
[40]
Bertie Vidgen, Austin Mann, Abby Fennelly, John Wright Stanly, Lucas Rothman, Marco Burstein, Julien Benchek, David Ostrofsky, Anirudh Ravichandran, Debnil Sur, et al. Apex- agents.arXiv preprint arXiv:2601.14242, 2026
-
[41]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Demystifying llm- based software engineering agents.Proceedings of the ACM on Software Engineering, 2(FSE): 801–824, 2025
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Demystifying llm- based software engineering agents.Proceedings of the ACM on Software Engineering, 2(FSE): 801–824, 2025
2025
-
[43]
SWE-agent: Agent-computer interfaces enable automated soft- ware engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=mXpq6ut8J3
2024
-
[44]
SWE-bench multimodal: Do AI systems generalize to visual software domains? InThe Thirteenth International Conference on Learning Representations, 2025
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, Diyi Yang, Sida Wang, and Ofir Press. SWE-bench multimodal: Do AI systems generalize to visual software domains? InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //ope...
2025
-
[45]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
Glm-5.1, April 2026
Z.ai. Glm-5.1, April 2026. URLhttps://huggingface.co/zai-org/GLM-5.1
2026
-
[47]
Agentic context engineering: Evolving contexts for self-improving language models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models. InThe Fourteenth International Conference on Learning Representations,
-
[48]
URLhttps://openreview.net/forum?id=eC4ygDs02R
-
[49]
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions
Terry Yue Zhuo, Vu Minh Chien, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen GONG, James Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Davi...
2025
-
[50]
subset100
Gregor Zunic. The bitter lesson of agent harnesses, April 2026. URL https://browser-use. com/posts/bitter-lesson-agent-harnesses. 12 A Example ETCSOVG Disclosure Card Table 3 gives the full field set that we expect a benchmark submission to disclose. The compact example in Table 4 instantiates these fields forH 3 in our controlled experiment. Table 3: ETC...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.