LC-ERD: Mining Latent Logic for Self-Evolving Reasoning via Consistency-Regulated Reward Decomposition
Pith reviewed 2026-06-30 18:42 UTC · model grok-4.3
The pith
LC-ERD mines latent logic via consistency-regulated reward decomposition to enable self-evolving LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
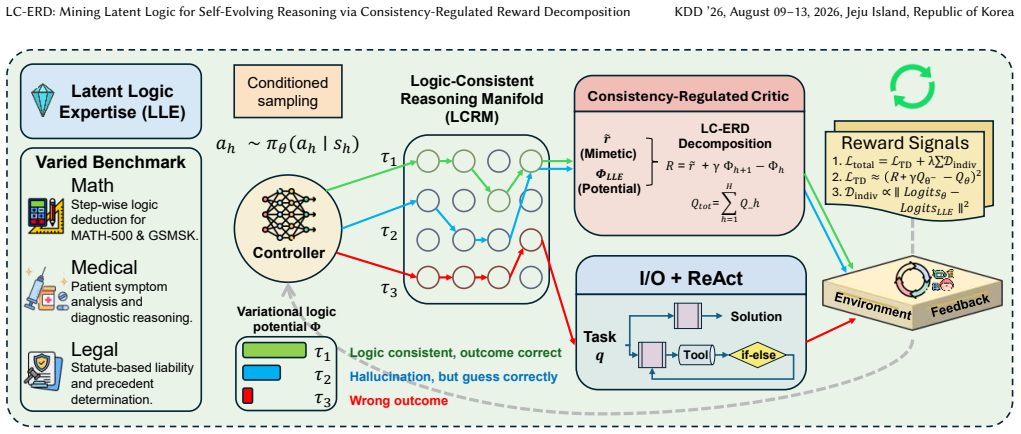
LC-ERD frames self-alignment as latent structure mining. It derives a Variational Logic Potential by aggregating consensus from the model's Latent Logic Expertise (LLE) to denoise the reasoning manifold, and introduces a Multi-Agent Value Decomposition protocol based on the IGM principle to quantify individual step utility, yielding a robust self-evolution path that uncovers trade-offs between logic consistency and accuracy while identifying high-value reasoning patterns missed by standard rewards.
What carries the argument
Variational Logic Potential aggregated from Latent Logic Expertise (LLE) consensus to denoise the reasoning manifold, paired with Multi-Agent Value Decomposition based on the IGM principle to quantify per-step utility.
If this is right
- Provides granular step-level guidance instead of treating entire reasoning chains as single units.
- Reduces label noise from mimetic bias and distributional collapse during self-alignment.
- Reveals explicit trade-offs between logic consistency and accuracy in evolved reasoning.
- Surfaces high-value reasoning patterns that standard global rewards overlook.
Where Pith is reading between the lines
- The approach may reduce reliance on external labeled process data if the internal consensus mechanism scales reliably.
- Patterns identified by the decomposition could serve as seeds for improved synthetic training sets in subsequent iterations.
- The same denoising-plus-decomposition structure might extend to other endogenous reward settings beyond pure reasoning tasks.
Load-bearing premise
Consensus aggregated from the model's Latent Logic Expertise can reliably denoise the reasoning manifold, and the IGM-based multi-agent decomposition accurately quantifies individual step utility.
What would settle it
Applying LC-ERD to standard reasoning benchmarks and observing no gain in final accuracy or no distinct high-value patterns compared with baseline reward methods such as GRPO would falsify the central claim.
Figures
read the original abstract
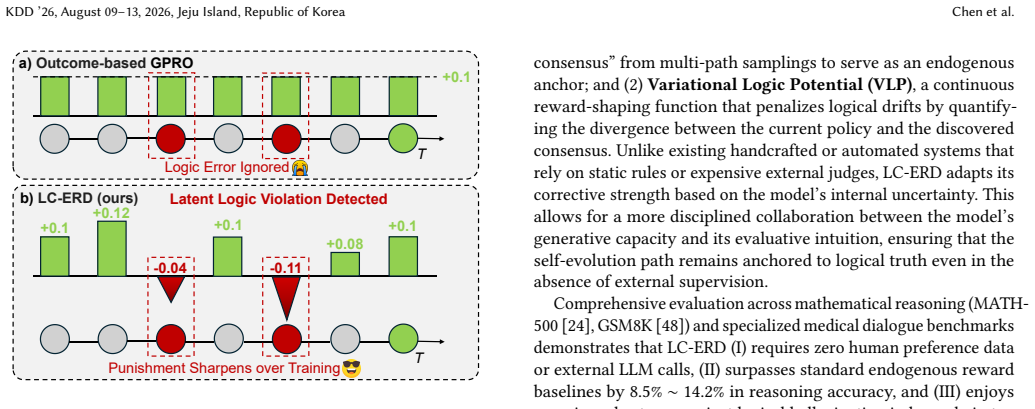
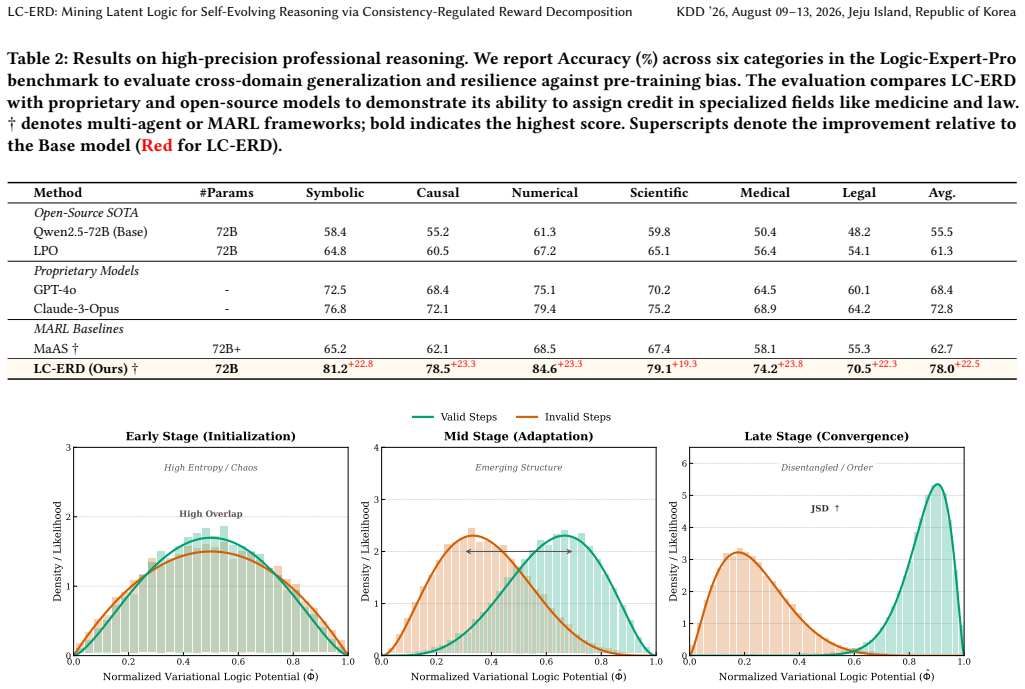
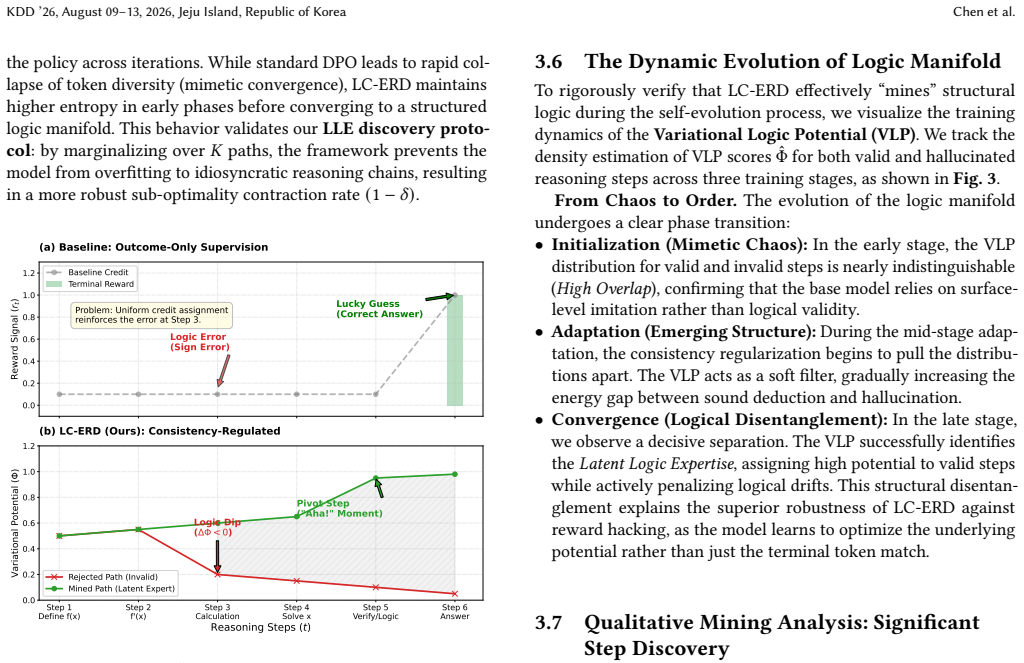
The evolution of Large Language Model (LLM) reasoning is bottlenecked by the scarcity of high-quality process data. While self-alignment via endogenous rewards offers a solution, mining valid supervision faces three challenges: (1) Label Noise via Mimetic Bias, where rewards prioritize statistical likelihood over logical truth, creating a "correctness illusion" that masks compounding errors; (2) Coarse-Grained Supervision, where sparse global outcomes (e.g., in GRPO) fail to provide granular guidance, treating reasoning chains as monolithic; and (3) Distributional Collapse, where signals fail to generalize without amplifying pre-training biases. To address these, we introduce LC-ERD (Logic-Consistent Endogenous Reward Decomposition), a framework framing self-alignment as latent structure mining. We derive a Variational Logic Potential by aggregating consensus from the model's Latent Logic Expertise (LLE) to denoise the reasoning manifold, and introduce a Multi-Agent Value Decomposition protocol based on the IGM principle to quantify individual step utility. Experiments show LC-ERD delivers a robust self-evolution path, uncovering trade-offs between logic consistency and accuracy while identifying high-value reasoning patterns missed by standard rewards. Our code is available at https://github.com/LC-ERD-repo/LC-ERD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LC-ERD, a framework for self-evolving LLM reasoning that frames self-alignment as latent structure mining. It identifies three challenges (label noise via mimetic bias, coarse-grained supervision from global outcomes like GRPO, and distributional collapse) and addresses them by deriving a Variational Logic Potential via consensus aggregation from the model's Latent Logic Expertise (LLE) to denoise the reasoning manifold, plus a Multi-Agent Value Decomposition protocol based on the IGM principle to assign per-step utilities. Experiments are claimed to demonstrate a robust self-evolution path that reveals trade-offs between logic consistency and accuracy and identifies high-value reasoning patterns missed by standard rewards; code is released at a GitHub link.
Significance. If the derivations and empirical results hold, the work could contribute a more granular, logic-aware endogenous reward mechanism that mitigates compounding errors in LLM reasoning chains. The explicit release of code supports reproducibility, which strengthens the assessment of any claimed self-evolution path.
major comments (2)
- [Abstract] Abstract (paragraph describing the framework): The Variational Logic Potential is defined by aggregating consensus from LLE, yet LLE is presented as an internal model construct without an independent grounding or external validation mechanism; this creates a risk that the potential reduces to a quantity fitted from the model's own outputs, undermining the claim of denoising the reasoning manifold.
- [Abstract] Abstract (final sentence on experiments): The claim that 'Experiments show LC-ERD delivers a robust self-evolution path' is unsupported by any metrics, datasets, baselines, ablation controls, or statistical details, rendering it impossible to evaluate whether the reported trade-offs or missed patterns are genuine or artifacts of the evaluation protocol.
minor comments (2)
- [Abstract] Abstract: The term 'mimetic bias' is introduced without a reference or precise definition, which could be clarified by linking to prior work on reward hacking or likelihood-based biases.
- [Abstract] Abstract: The IGM principle is invoked without a citation or brief explanation of how it is adapted to the multi-agent decomposition, which would aid readers unfamiliar with the reference.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on the abstract. We address each major point below, providing clarifications based on the manuscript content while noting where revisions may strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the framework): The Variational Logic Potential is defined by aggregating consensus from LLE, yet LLE is presented as an internal model construct without an independent grounding or external validation mechanism; this creates a risk that the potential reduces to a quantity fitted from the model's own outputs, undermining the claim of denoising the reasoning manifold.
Authors: The LLE is constructed from the model's internal latent representations across multiple sampled reasoning trajectories, and the Variational Logic Potential explicitly aggregates consensus to identify structures that recur reliably rather than fitting to isolated outputs. This is intended to mitigate mimetic bias as described in the introduction. We agree that the abstract could more explicitly note the endogenous nature of the grounding and the reliance on consensus for denoising; a revision will add a clarifying clause without altering the core claim. revision: partial
-
Referee: [Abstract] Abstract (final sentence on experiments): The claim that 'Experiments show LC-ERD delivers a robust self-evolution path' is unsupported by any metrics, datasets, baselines, ablation controls, or statistical details, rendering it impossible to evaluate whether the reported trade-offs or missed patterns are genuine or artifacts of the evaluation protocol.
Authors: The abstract is a concise summary; the supporting details—including datasets (e.g., GSM8K, MATH), baselines (GRPO and variants), ablation controls on the value decomposition and consensus aggregation, quantitative metrics on accuracy-consistency trade-offs, and statistical reporting—are provided in Sections 4 and 5 with accompanying tables and figures. The referee summary correctly notes that experiments are claimed and described in the paper body. No change to the abstract is required, as this level of detail is standard for abstracts. revision: no
Circularity Check
No significant circularity identified
full rationale
The abstract describes deriving a Variational Logic Potential via LLE consensus aggregation and an IGM-based value decomposition protocol, but supplies no equations, definitions, or derivations that reduce any claimed prediction or result to its own inputs by construction. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems are quoted that would create a load-bearing circular step. The central claims rest on experimental outcomes rather than internal redefinitions, rendering the derivation self-contained on the supplied text.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Latent Logic Expertise (LLE)
no independent evidence
-
Variational Logic Potential
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. 2025. Towards reason- ing era: A survey of long chain-of-thought for reasoning large language models. arXiv preprint arXiv:2503.09567(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Yanyu Chen, Jiyue Jiang, Jiahong Liu, Yifei Zhang, Xiao Guo, and Irwin King. 2026. Trace: Trajectory-aware comprehensive evaluation for deep research agents. In Proceedings of the ACM Web Conference 2026. 2524–2534
2026
-
[5]
Hao Cheng, Wentong Liao, Xuejiao Tang, Michael Ying Yang, Monika Sester, and Bodo Rosenhahn. 2021. Exploring dynamic context for multi-path trajectory prediction. In2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 12795–12801
2021
-
[6]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. 2023. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [7]
-
[8]
David Ellerman. 2013. An introduction to logical entropy and its relation to Shannon entropy. 121–145 pages
2013
- [9]
-
[10]
Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Alan Huang, Songyang Zhang, Kai Chen, Zhixin Yin, Zongwen Shen, Jidong Ge, and Vincent Ng. 2024. Lawbench: Benchmarking legal knowledge of large language models. InProceedings of the 2024 conference on empirical methods in natural language processing. 7933–7962
2024
-
[11]
Frédérick Garcia and Emmanuel Rachelson. 2013. Markov decision processes. Markov Decision Processes in Artificial Intelligence(2013), 1–38
2013
-
[12]
Yitian Hong, Yaochu Jin, and Yang Tang. 2022. Rethinking individual global max in cooperative multi-agent reinforcement learning.Advances in neural information processing systems35 (2022), 32438–32449
2022
- [13]
- [14]
-
[15]
Edwin T Jaynes. 1982. On the rationale of maximum-entropy methods.Proc. IEEE70, 9 (1982), 939–952
1982
-
[16]
Jiyue Jiang, Yanyu Chen, Peng Chen, Kai-Chun Liu, Jingqi Zhou, Zheyong Zhu, He Hu, Fei Ma, Qi Tian, and Chuan Wu. 2026. A Principle-Driven Adaptive Policy for Group Cognitive Stimulation Dialogue for Elderly with Cognitive Impairment. InAAAI Conference on Artificial Intelligence. https://api.semanticscholar.org/ CorpusID:286457185
2026
-
[17]
Jiyue Jiang, Yunke Li, Shiwei Cao, Yuheng Shan, Yuexing Liu, Tianyi Fei, Yule Yu, Yi Feng, Yu Li, Yixue Li, et al. 2025. Artificial intelligence in bioinformatics: a survey.Briefings in Bioinformatics26, 6 (2025), bbaf576
2025
-
[18]
Hyeongyu Kang, Jaewoo Lee, Woocheol Shin, Kiyoung Om, and Jinkyoo Park
- [19]
- [20]
- [21]
- [22]
-
[23]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations
2023
-
[24]
Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, and Fei Wu. 2025. Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners.arXiv preprint arXiv:2504.14239 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
-
[26]
Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems37 (2024), 124198–124235
2024
-
[27]
Ng and Stuart J
Andrew Y. Ng and Stuart J. Russell. 2000. Algorithms for inverse reinforcement learning.. InIcml, Vol. 1. 2
2000
- [28]
-
[29]
Eduardo Pignatelli, Johan Ferret, Matthieu Geist, Thomas Mesnard, Hado van Hasselt, Olivier Pietquin, and Laura Toni. 2023. A survey of temporal credit assignment in deep reinforcement learning.arXiv preprint arXiv:2312.01072 (2023). KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Chen et al
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2023. Principle-driven self-alignment of language models from scratch with minimal human supervision.Advances in Neural Information Processing Systems36 (2023), 2511–2565
2023
-
[32]
Shengyuan Tang, Linwan Zhang, Shengzhe Xu, Xinyue Zeng, Peng Hu, Xinyi Gong, and Manzhou Li. 2025. Communication-Efficient Federated Optimiza- tion with Gradient Clipping and Attention Aggregation for Data Analytics and Prediction.Electronics14, 23 (2025), 4778
2025
-
[33]
Tim Van Erven and Peter Harremos. 2014. Rényi divergence and Kullback-Leibler divergence.IEEE Transactions on Information Theory60, 7 (2014), 3797–3820
2014
-
[34]
Adriano Vinhas, João Correia, and Penousal Machado. 2024. Towards evolution of deep neural networks through contrastive self-supervised learning. In2024 IEEE Congress on Evolutionary Computation (CEC). IEEE, 1–8
2024
-
[35]
Guoyong Wang, Kaijun Zhang, Jiyue Jiang, Chaonan Wang, Hui Bi, Haojun Liang, Zuoliang Qi, Ying Huang, Yu Li, and Xiaonan Yang. 2026. Human–large language model collaboration in clinical medicine: a systematic review and meta-analysis. npj Digital Medicine(2026)
2026
-
[36]
Hongcheng Wang, Yinuo Huang, Sukai Wang, Guanghui Ren, and Hao Dong
- [37]
-
[38]
Zhenyu Wang, Zikang Wang, Jiyue Jiang, Pengan Chen, Xiangyu Shi, and Yu Li. 2025. Large language models in bioinformatics: A survey. InFindings of the Association for Computational Linguistics: ACL 2025. 3602–3615
2025
-
[39]
Zheng Wu, Heyuan Huang, Yanjia Yang, Yuanyi Song, Xingyu Lou, Weiwen Liu, Weinan Zhang, Jun Wang, and Zhuosheng Zhang. 2025. Quick on the uptake: Eliciting implicit intents from human demonstrations for personalized mobile-use agents.arXiv preprint arXiv:2508.08645(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Zheng Wu, Xingyu Lou, Xinbei Ma, Yansi Li, Weiwen Liu, Weinan Zhang, Jun Wang, and Zhuosheng Zhang. 2026. Agent-Dice: Disentangling Knowledge Updates via Geometric Consensus for Agent Continual Learning.arXiv preprint arXiv:2601.03641(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Tengyang Xie, Ching-An Cheng, Nan Jiang, Paul Mineiro, and Alekh Agarwal
-
[42]
Bellman-consistent pessimism for offline reinforcement learning.Advances in neural information processing systems34 (2021), 6683–6694
2021
- [43]
-
[44]
Hang Yang, Hao Chen, Hui Guo, Yineng Chen, Ching-Sheng Lin, Shu Hu, Jinrong Hu, Xi Wu, and Xin Wang. 2025. Llm-medqa: Enhancing medical question answering through case studies in large language models. In2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
2025
-
[45]
Zonghai Yao, Zihao Zhang, Chaolong Tang, Xingyu Bian, Youxia Zhao, Zhichao Yang, Junda Wang, Huixue Zhou, Won Seok Jang, Feiyun Ouyang, and Hong Yu
- [46]
-
[47]
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue
-
[48]
Demystifying long chain-of-thought reasoning in llms.arXiv preprint arXiv:2502.03373(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. 2024. Self-rewarding language models. InForty-first International Conference on Machine Learning
2024
-
[50]
Haifeng Zhang, Weizhe Chen, Zeren Huang, Minne Li, Yaodong Yang, Weinan Zhang, and Jun Wang. 2020. Bi-level actor-critic for multi-agent coordination. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 7325–7332
2020
-
[51]
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. 2024. Aflow: Automating agentic workflow generation.arXiv preprint arXiv:2410.10762(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [52]
-
[53]
Qihuang Zhong, Kang Wang, Ziyang Xu, Liang Ding, Juhua Liu, and Bo Du. 2026. Achieving> 97% on gsm8k: Deeply understanding the problems makes llms better solvers for math word problems.Frontiers of Computer Science20, 1 (2026), 1–3
2026
-
[54]
Jingqi Zhou, Sheng Wang, Jingwei Dong, Kai Liu, Lei Li, Jiahui Gao, Jiyue Jiang, Lingpeng Kong, and Chuan Wu. 2025. PROREASON: Multi-Modal Proactive Reasoning with Decoupled Eyesight and Wisdom. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 31650–31679
2025
-
[55]
Incorrect Rewarding for Silent Errors
Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, and Mengdi Wang. 2025. ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of- Thought Reasoning in LLMs.arXiv preprint arXiv:2506.18896(2025). A Appendix A.1 Proof of the Identity between LLM Logits and Latent Soft Q-functions We aim to rigorously prove that the unnormalized logits produ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.