MGVQ: Synergizing Multi-dimensional Sensitivity-Aware and Gradient-Hessian Fusion for Vector Quantization
Pith reviewed 2026-06-30 17:33 UTC · model grok-4.3
The pith
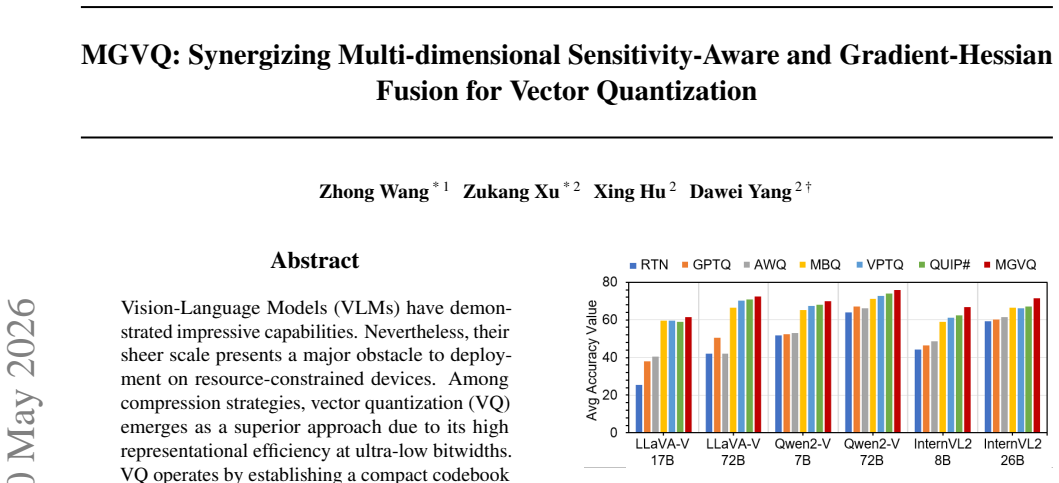
MGVQ achieves up to 4.9 point accuracy gains in 2-bit quantization of vision-language models by fusing multi-dimensional sensitivity analysis with gradient-Hessian error compensation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that integrating multi-dimensional sensitivity perception and gradient-Hessian fusion in MGVQ allows for effective vector quantization of VLMs, overcoming limitations of unified codebooks and ignoring gradient info, resulting in superior performance in 2-bit settings with a maximum accuracy improvement of 4.9 points on InternVL2-26B compared to existing post-training quantization methods.
What carries the argument
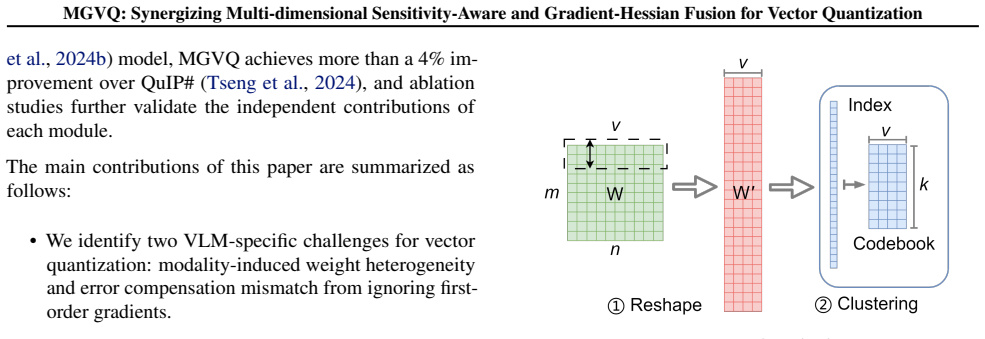
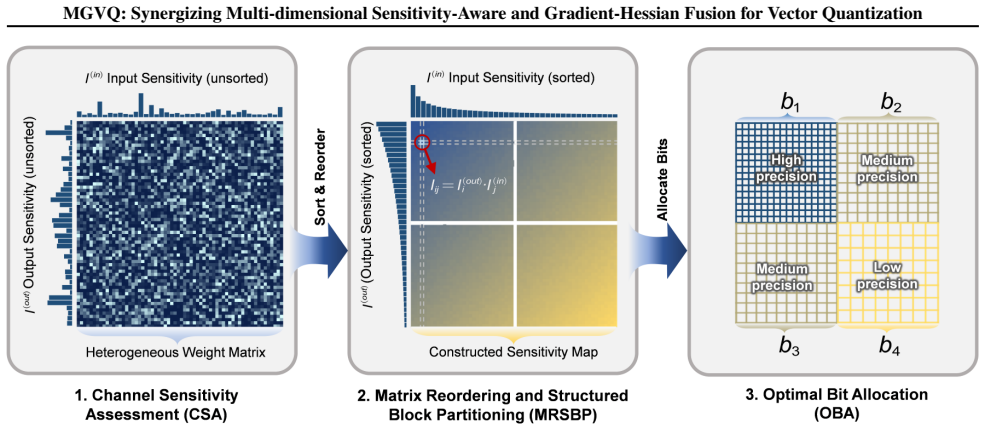
The sensitivity-guided structured mixed-precision quantization module that dynamically assigns bit-widths using combined global and local sensitivity analysis, and the gradient-aware second-order error compensation module that embeds first-order gradients and uses Kronecker and Block-LDL decomposition for computational efficiency.
If this is right
- VLMs can be quantized to 2 bits with higher accuracy than previous methods, facilitating edge deployment.
- The framework applies across mainstream VLMs like LLaVA-onevision, InternVL2, and Qwen2-VL.
- Error compensation becomes less biased by including gradient information, reducing deviation from pre-trained states.
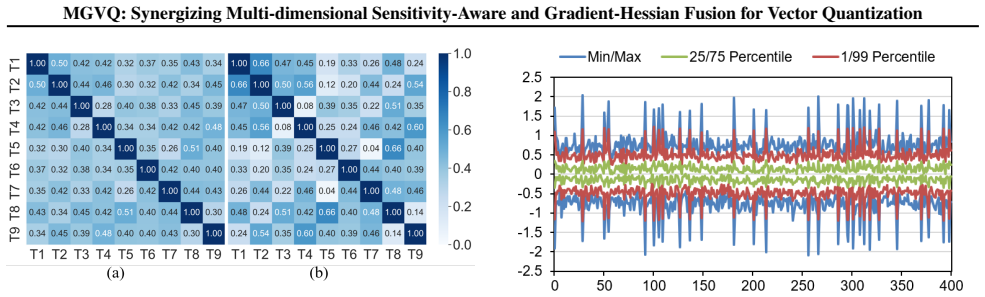
- Resource allocation is refined by accounting for cross-modality weight distribution differences.
Where Pith is reading between the lines
- If the sensitivity analysis generalizes, MGVQ could be adapted for quantizing other large multimodal models.
- The method might inspire similar fusion techniques in other model compression domains like pruning or knowledge distillation.
- Testing on even lower bits or different hardware could reveal further benefits or limitations not covered in the experiments.
Load-bearing premise
The load-bearing premise is that multi-dimensional sensitivity analysis combined with embedding first-order gradients into second-order compensation produces bit assignments and error corrections that generalize to new VLMs without dataset-specific tuning.
What would settle it
Running MGVQ on a vision-language model outside the tested set, such as a different architecture or size, and checking if the accuracy at 2-bit quantization still exceeds the best baseline by at least 3 points.
Figures
read the original abstract
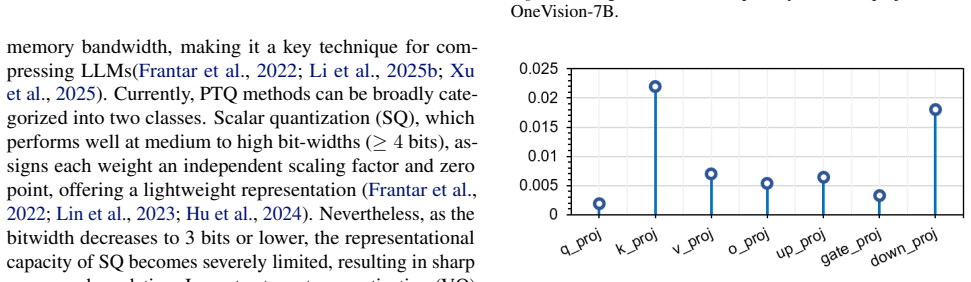
Vision-Language Models (VLMs) achieve outstanding performance, yet their huge model size severely hinders deployment on edge devices with limited resources. As an efficient model compression technique, vector quantization (VQ) excels in ultra-low-bit representation, which maps model weights to discrete codewords in a compact codebook to cut memory consumption and transmission overhead while preserving model capability. Direct VQ application to VLMs still has two core limitations. First, cross-modality weight distribution differences brought by visual and textual inputs cannot be well fitted by a single unified codebook. Second, current second-order error compensation ignores first-order gradient information, causing weight deviation from pre-trained optimal states, gradient drift and biased compensation results. This work proposes MGVQ, a novel vector quantization framework integrating multi-dimensional sensitivity perception and gradient-Hessian fusion. It consists of two core modules: sensitivity-guided structured mixed-precision quantization dynamically assigns different bit-widths according to channel sensitivity via combined global and local sensitivity analysis for refined resource allocation; gradient-aware second-order error compensation embeds first-order gradients into error correction, and adopts Kronecker and Block-LDL decomposition to ensure low computational cost. Extensive experiments on mainstream VLMs including LLaVA-onevision, InternVL2 and Qwen2-VL verify the effectiveness of MGVQ. In 2-bit quantization settings, MGVQ surpasses existing advanced post-training quantization methods significantly, achieving a maximum accuracy improvement of 4.9 points (71.4% vs 67.0% on InternVL2-26B). The proposed method realizes stable and efficient ultra-low-bit VLM quantization, greatly promoting the practical deployment of multimodal large models in resource-limited environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MGVQ, a post-training vector quantization framework for vision-language models. It introduces two modules: (1) sensitivity-guided structured mixed-precision quantization that performs global-plus-local sensitivity analysis to assign per-channel bit-widths, and (2) gradient-aware second-order error compensation that embeds first-order gradients into Hessian-based correction and uses Kronecker and Block-LDL factorizations for efficiency. Experiments on LLaVA-OneVision, InternVL2 and Qwen2-VL report that the method yields up to 4.9 percentage-point gains over prior PTQ baselines in the 2-bit regime (e.g., 71.4 % vs. 67.0 % on InternVL2-26B).
Significance. If the reported accuracy gains prove reproducible and the bit-assignment procedure generalizes without model-specific retuning, the work would constitute a practically useful advance for deploying large VLMs under tight memory budgets. The combination of multi-dimensional sensitivity analysis with explicit first-order gradient information in the compensation step is a plausible route to more stable ultra-low-bit representations than purely second-order methods.
major comments (3)
- [§3.2, §4.2] §3.2 and §4.2: the sensitivity thresholds that determine bit-width assignment and the scaling factors inside the Kronecker/Block-LDL decompositions are stated to be chosen or fitted on the target model; no external validation set, cross-model transfer experiment, or sensitivity analysis is reported to show that these choices are not post-hoc tuned to the three evaluated VLMs. This directly affects the central claim that the method “realizes stable … ultra-low-bit VLM quantization.”
- [Table 2, Figure 4] Table 2 / Figure 4 (2-bit rows): the headline 4.9-point gain on InternVL2-26B is presented without error bars, multiple random seeds, or statistical significance tests. Given that the reader’s soundness assessment already flags the absence of implementation details and ablations, the numerical superiority cannot yet be treated as load-bearing evidence.
- [§4.3] §4.3: the ablation that isolates the contribution of the gradient-embedding term versus the pure Hessian baseline is missing; without it, it is impossible to attribute the observed gains to the claimed “gradient-Hessian fusion” rather than to the mixed-precision allocation alone.
minor comments (2)
- [Eqs. 3–5] Notation for the global and local sensitivity metrics (Eqs. 3–5) is introduced without an explicit comparison to the sensitivity definitions used in prior mixed-precision VQ papers (e.g., GPTQ, AWQ).
- The manuscript does not state the codebook size or the number of codewords per layer, which is standard information for reproducibility in VQ papers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on reproducibility, statistical rigor, and attribution of contributions. We address each major comment below, indicating planned revisions to strengthen the manuscript while clarifying the design choices in MGVQ.
read point-by-point responses
-
Referee: [§3.2, §4.2] §3.2 and §4.2: the sensitivity thresholds that determine bit-width assignment and the scaling factors inside the Kronecker/Block-LDL decompositions are stated to be chosen or fitted on the target model; no external validation set, cross-model transfer experiment, or sensitivity analysis is reported to show that these choices are not post-hoc tuned to the three evaluated VLMs. This directly affects the central claim that the method “realizes stable … ultra-low-bit VLM quantization.”
Authors: The sensitivity thresholds are computed deterministically from the combined global (model-level weight distribution statistics) and local (per-channel gradient magnitude) analysis described in §3.2; they are not free hyperparameters fitted via search on a validation set. The Kronecker and Block-LDL scaling factors are likewise obtained directly from the closed-form decompositions of the approximated Hessian without additional fitting. Nevertheless, we acknowledge the value of demonstrating transferability. In the revision we will add a cross-model transfer experiment (applying bit-width rules derived on InternVL2 to Qwen2-VL without retuning) and expand §3.2 with the exact algorithmic procedure and pseudocode for threshold selection. revision: yes
-
Referee: [Table 2, Figure 4] Table 2 / Figure 4 (2-bit rows): the headline 4.9-point gain on InternVL2-26B is presented without error bars, multiple random seeds, or statistical significance tests. Given that the reader’s soundness assessment already flags the absence of implementation details and ablations, the numerical superiority cannot yet be treated as load-bearing evidence.
Authors: We agree that variability reporting is necessary to substantiate the headline gains. In the revised manuscript we will rerun the 2-bit experiments on InternVL2-26B (and the other models) across multiple random seeds, report mean and standard deviation, and include error bars in Table 2 and Figure 4. We will also add paired statistical significance tests between MGVQ and the strongest baseline. revision: yes
-
Referee: [§4.3] §4.3: the ablation that isolates the contribution of the gradient-embedding term versus the pure Hessian baseline is missing; without it, it is impossible to attribute the observed gains to the claimed “gradient-Hessian fusion” rather than to the mixed-precision allocation alone.
Authors: We accept this criticism. The current §4.3 ablations focus on the overall framework but do not isolate the gradient-embedding component. We will add a controlled ablation that keeps the mixed-precision allocation fixed and compares (i) pure Hessian compensation against (ii) the full gradient-aware second-order compensation, reporting accuracy deltas on the same models and bit-widths. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical post-training quantization method consisting of two algorithmic modules (sensitivity-guided mixed-precision assignment and gradient-aware Hessian compensation) whose performance is validated through direct experiments on VLMs such as InternVL2-26B. No derivation chain, uniqueness theorem, or mathematical reduction is claimed; the reported accuracy gains are measured outcomes on external benchmarks rather than quantities forced by construction from fitted parameters or self-citations. The method description contains no self-definitional steps, fitted-input predictions, or load-bearing self-citations that collapse the central result to its inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- sensitivity thresholds for bit-width assignment
- scaling factors inside Kronecker and Block-LDL decompositions
axioms (2)
- domain assumption Combined global and local sensitivity analysis correctly identifies channels whose quantization error most affects final task performance.
- domain assumption Embedding first-order gradients into second-order error compensation yields unbiased corrections for VLM weight distributions.
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., and Zhou, J. Qwen-vl: A versatile vision- language model for understanding, localization, text read- ing, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2405.17247 (2024) 1
Bordes, F., Pang, R. Y ., Ajay, A., Li, A. C., Bardes, A., Petryk, S., Ma˜nas, O., Lin, Z., Mahmoud, A., Jayaraman, B., et al. An introduction to vision-language modeling. arXiv preprint arXiv:2405.17247,
-
[3]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., and Lin, D. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision, pp. 370–387. Springer, 2024a. Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al. Internvl: Scaling up vision foundat...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Hu, X., Cheng, Y ., Yang, D., Yuan, Z., Yu, J., Xu, C., and Zhou, S. I-llm: Efficient integer-only inference for fully- quantized low-bit large language models.arXiv preprint arXiv:2405.17849,
-
[5]
Hu, X., Cheng, Y ., Yang, D., Xu, Z., Yuan, Z., Yu, J., Xu, C., Jiang, Z., and Zhou, S. Ostquant: Refining large language model quantization with orthogonal and scal- ing transformations for better distribution fitting.arXiv preprint arXiv:2501.13987,
-
[6]
Kim, J., Halabi, M. E., Park, W., Schaefer, C. J., Lee, D., Park, Y ., Lee, J. W., and Song, H. O. Guidedquant: Large language model quantization via exploiting end loss guidance.arXiv preprint arXiv:2505.07004,
-
[7]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Ge, Y ., Ge, Y ., Wang, G., Wang, R., Zhang, R., and Shan, Y . Seed-bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13299–13308, 2024a. Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., et al. Llava- onevi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2409.17066 , year=
Liu, Y ., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.-C., Liu, C.-L., Jin, L., and Bai, X. Ocrbench: on the hidden mystery of ocr in large multimodal models.Sci- ence China Information Sciences, 67(12):220102, 2024a. Liu, Y ., Wen, J., Wang, Y ., Ye, S., Zhang, L. L., Cao, T., Li, C., and Yang, M. Vptq: Extreme low-bit vector post- training quant...
- [9]
-
[10]
Model-Preserving Adaptive Rounding
Tseng, A., Sun, Z., and De Sa, C. Model-preserving adap- tive rounding.arXiv preprint arXiv:2505.22988,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Gptvq: The blessing of dimensionality in llm quantization.arXiv preprint arXiv:2402.15319, 2024
Van Baalen, M., Kuzmin, A., Koryakovskiy, I., Nagel, M., Couperus, P., Bastoul, C., Mahurin, E., Blankevoort, T., and Whatmough, P. Gptvq: The blessing of dimensional- ity for llm quantization.arXiv preprint arXiv:2402.15319,
-
[12]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Mambaquant: Quantizing the mamba family with variance aligned rotation methods
Xu, Z., Yue, Y ., Hu, X., Yuan, Z., Jiang, Z., Chen, Z., Yu, J., Xu, C., Zhou, S., and Yang, D. Mambaquant: Quantizing the mamba family with variance aligned rotation methods. arXiv preprint arXiv:2501.13484,
-
[14]
Xue, Y ., Huang, Y ., Shao, J., and Zhang, J. Vlmq: Effi- cient post-training quantization for large vision-language models via hessian augmentation.arXiv preprint arXiv:2508.03351,
-
[15]
Yue, Y ., Xu, Z., Yuan, Z., Yang, D., Wu, J., and Nie, L. Pcdvq: Enhancing vector quantization for large language models via polar coordinate decoupling.arXiv preprint arXiv:2506.05432,
-
[16]
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Zhang, J., Huang, J., Jin, S., and Lu, S. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625– 5644, 2024a. Zhang, K., Li, B., Zhang, P., Pu, F., Cahyono, J. A., Hu, K., Liu, S., Zhang, Y ., Yang, J., Li, C., et al. Lmms- eval: Reality check on the evaluation of large multimodal mode...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.