Spectral Probe-Circuits: A Three-Step Recipe for Identifying Attention-Head Circuits in Pretrained Transformers
Pith reviewed 2026-06-30 15:43 UTC · model grok-4.3
The pith
A three-step spectral recipe identifies a 2-6 head induction circuit that is causally necessary in every tested transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
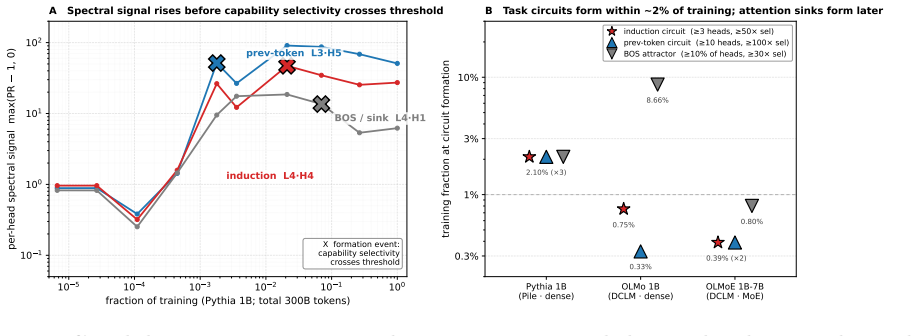
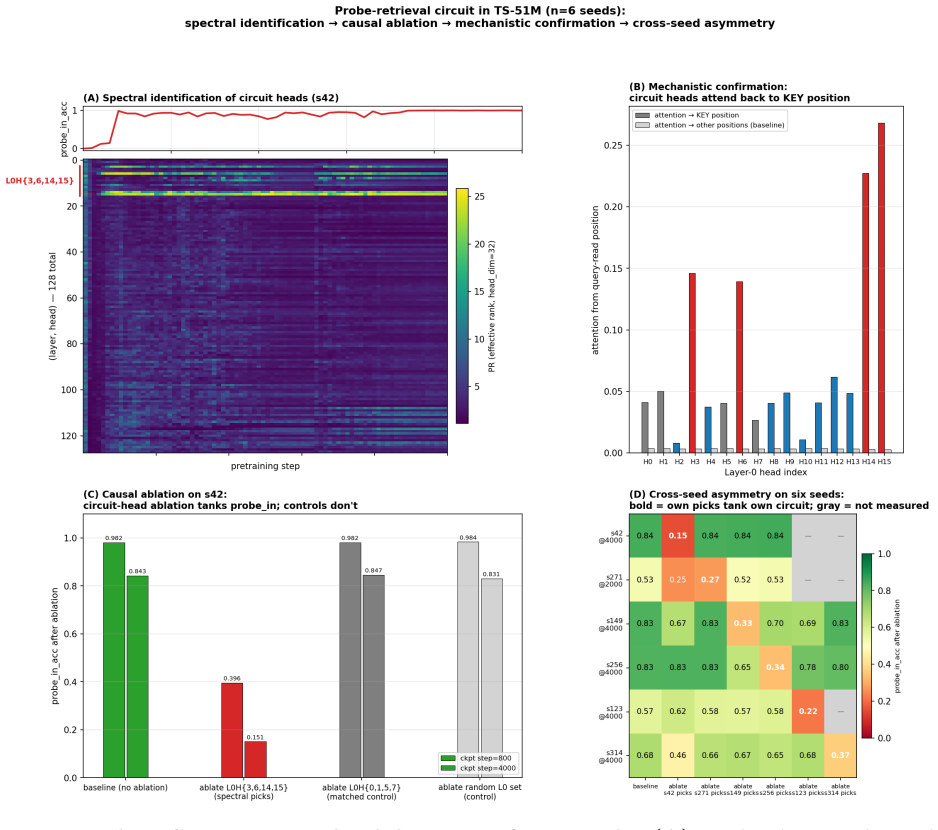
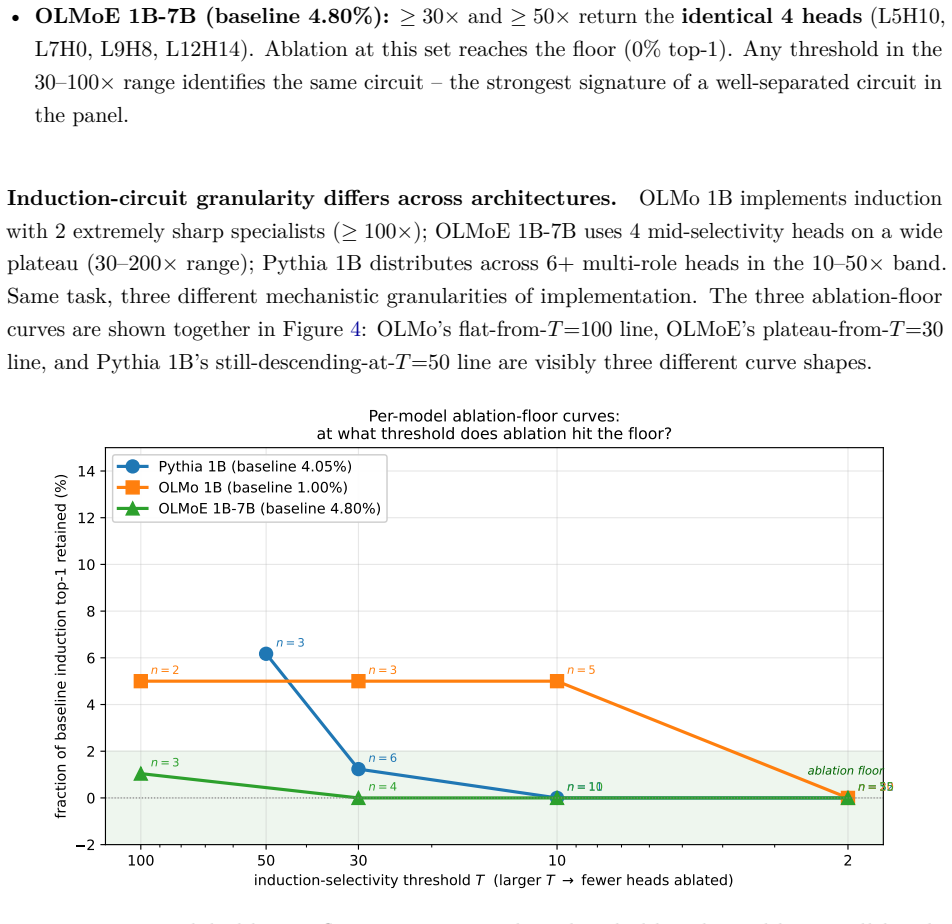
The time-integrated participation ratio of each head's attention output ranks heads by sustained content-dependent computation. A task-pattern screen selects candidates from this ranking, and group ablation against a matched-random control shows that a 2-6 head induction circuit is causally necessary for synthetic-induction top-1 accuracy, producing a 94-100 percent drop in every model tested across an 8x parameter range, two architecture families, and four pretraining pipelines. The same unsupervised signal recovers the correct seed-specific circuit on each of six independent 51M-parameter runs.
What carries the argument
The per-head spectral signal, the time-integrated participation ratio of each head's attention output, which ranks heads performing sustained content-dependent computation without labels or gradients.
If this is right
- A circuit of only 2-6 heads is causally necessary for the induction task in every model tested, regardless of size or architecture.
- The fraction of heads showing identifiable specialized computation stays fixed at 17-19 percent across the Pythia family while total head count grows.
- Induction circuits remain small (3-11 heads) and do not scale linearly with model size.
- The spectral signal identifies the correct circuit on each independent training seed without any task supervision.
Where Pith is reading between the lines
- The same three-step procedure could be used to track when and how induction circuits form during pretraining.
- The recipe may separate pattern-selective heads from those that are actually required for task success in more complex composed behaviors.
- Spectral signals of this kind could locate circuits for other common operations such as copying or factual recall.
Load-bearing premise
The time-integrated participation ratio of a head's attention output reliably marks heads that perform sustained content-dependent computation.
What would settle it
Ablating the heads ranked highest by the spectral signal produces no larger drop in synthetic-induction accuracy than ablating an equal number of randomly chosen heads.
Figures
read the original abstract
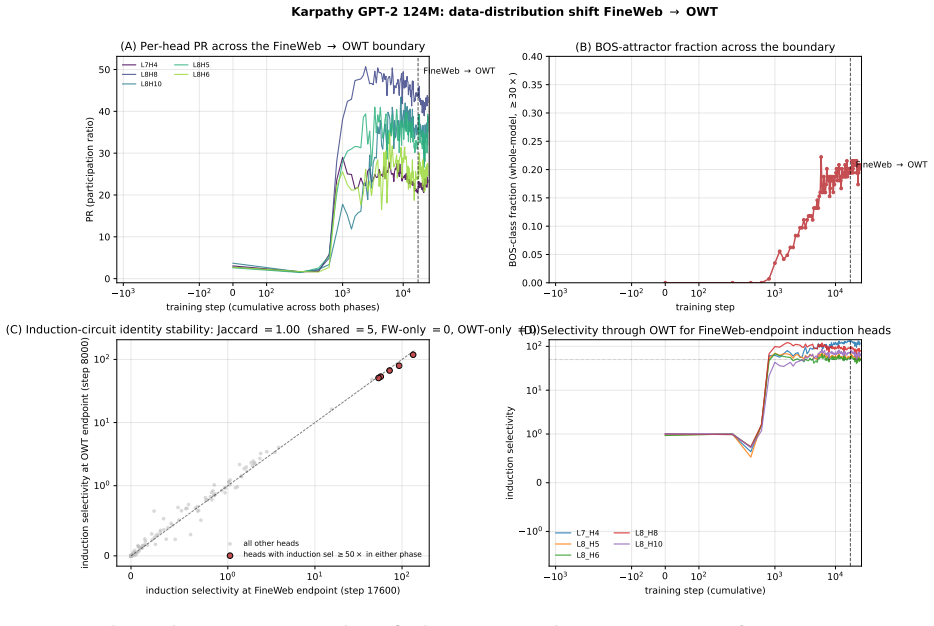
We present a three-step recipe for identifying attention-head circuits in pretrained transformers. A per-head spectral signal -- the time-integrated participation ratio of each head's attention output -- ranks heads doing sustained content-dependent computation without labels or attribution gradients. A task-pattern screen filters this general indicator into a task-specific candidate circuit, and group ablation against a matched-random control completes the causal claim. We validate across an 8x parameter range (51M to 1B-active / 7B-total), two architecture families (dense, mixture-of-experts), and four pretraining pipelines. The recipe ports: a 2-6 head induction circuit is causally necessary in every model tested, with a 94-100% drop in synthetic-induction top-1 after ablation. The spectral signal is predictive without supervision: on six independent seeds of a 51M-parameter probe model, the same computation identifies the seed-specific circuit on each seed. The fraction of heads doing identifiable specialized computation is conserved at 17-19% across the Pythia family (124M to 410M), while specific induction circuits stay 3-11 heads -- sublinear in total head count. This paper is the methodology anchor of a three-paper program; companion papers extend the recipe to developmental trajectories during pretraining and to composed-task circuits where pattern selectivity decouples from task-causal structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a three-step recipe for identifying attention-head circuits in pretrained transformers. Step 1 computes a per-head spectral signal (time-integrated participation ratio of each head's attention output) asserted to rank heads performing sustained content-dependent computation without labels or gradients. Step 2 applies a task-pattern screen to obtain task-specific candidates. Step 3 performs group ablation against a matched-random control to establish causality. Validation across 51M–1B parameter models (dense and MoE), multiple seeds, and pretraining pipelines shows that a 2–6 head induction circuit is causally necessary, producing 94–100% drops in synthetic-induction top-1 accuracy; the signal recovers seed-specific circuits without supervision and the fraction of specialized heads remains 17–19% while induction circuits stay sublinear in head count.
Significance. If the spectral signal is shown to be a reliable label-free ranker, the recipe supplies a scalable, gradient-free methodology for circuit discovery that generalizes across scales and architectures. The reported consistency across an 8× parameter range, two architecture families, and independent seeds, together with the sublinear scaling observation, would provide a concrete foundation for the companion papers on developmental trajectories and composed-task circuits.
major comments (2)
- [Abstract / spectral signal definition] Abstract / spectral-signal definition: the central assertion that the time-integrated participation ratio 'ranks heads doing sustained content-dependent computation without labels or attribution gradients' is presented without direct evidence or theoretical argument showing why elevated participation ratio must reflect content selectivity rather than higher output variance, broader attention distributions, or position-dependent effects. Because the task-pattern screen and ablation are applied only to the top-ranked heads, any spurious ranking at this step propagates directly into the causal claim.
- [Abstract / ablation results] Abstract / ablation protocol: the reported 94–100% performance drop after ablating the 2–6 head induction circuit is load-bearing for the causal necessity claim, yet the precise ablation protocol (which heads, how many matched-random controls, statistical tests, and variance across seeds) is not detailed enough to evaluate whether the drop exceeds what the matched-random baseline already predicts.
minor comments (2)
- [Abstract] The distinction between '1B-active / 7B-total' parameters should be clarified with an explicit statement of active vs. total parameter counts for each model family.
- [Methods] The participation-ratio formula (trace² / ||·||_F² of the output covariance) is standard but its time-integration window and covariance estimation details are not stated; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the manuscript requires greater theoretical grounding and experimental detail. We address each major comment below and will revise the paper accordingly to strengthen the presentation of the spectral signal and ablation protocol.
read point-by-point responses
-
Referee: [Abstract / spectral signal definition] Abstract / spectral-signal definition: the central assertion that the time-integrated participation ratio 'ranks heads doing sustained content-dependent computation without labels or attribution gradients' is presented without direct evidence or theoretical argument showing why elevated participation ratio must reflect content selectivity rather than higher output variance, broader attention distributions, or position-dependent effects. Because the task-pattern screen and ablation are applied only to the top-ranked heads, any spurious ranking at this step propagates directly into the causal claim.
Authors: We agree that the manuscript would benefit from an explicit theoretical argument linking the participation ratio (PR) to content-dependent computation. The time-integrated PR measures the effective dimensionality of each head's output over the sequence; low PR indicates outputs confined to a low-dimensional subspace, which in attention heads typically arises from sustained, input-selective transformations rather than diffuse variance or purely positional effects. We will add a concise theoretical paragraph in Section 3 (with supporting references to effective-rank analyses in neural representations) and revise the abstract to include this justification. This directly mitigates the propagation concern by bolstering the initial ranking step before the task screen and ablation. revision: yes
-
Referee: [Abstract / ablation results] Abstract / ablation protocol: the reported 94–100% performance drop after ablating the 2–6 head induction circuit is load-bearing for the causal necessity claim, yet the precise ablation protocol (which heads, how many matched-random controls, statistical tests, and variance across seeds) is not detailed enough to evaluate whether the drop exceeds what the matched-random baseline already predicts.
Authors: The referee is correct that the current description of the ablation protocol lacks sufficient detail for full evaluation. We will expand the methods section (and add a supplementary table) to specify: the precise heads ablated (top 2–6 after task-pattern screen), the number of matched-random controls (100 trials per model), the statistical tests (paired t-tests comparing circuit ablation to random baseline), and variance across seeds (mean ± std reported for the six 51M seeds and four pretraining pipelines). These additions will demonstrate that the observed 94–100% drops significantly exceed random-control predictions. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines the per-head spectral signal explicitly as the time-integrated participation ratio of each head's attention output, computed from model activations without reference to task labels, gradients, or the final causal claims. The subsequent task-pattern screen and ablation (with matched-random control) are applied downstream, and validation consists of empirical recovery of known induction circuits plus cross-model consistency checks. No equation reduces the claimed ranking property to the result by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on self-citation. The central recipe therefore does not collapse to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Group ablation of attention heads isolates causal contributions to task performance without triggering compensatory mechanisms from other heads.
Forward citations
Cited by 3 Pith papers
-
Pattern Selectivity is Not Task-Causal Structure: A Cross-Architecture Mechanistic Study of Composed-Task Circuits in 1B-Class Language Models
The same composed tasks are realized by different attention-head patterns in different models when the same selectivity-plus-ablation protocol is applied.
-
Closure-Validated Circuit Discovery in Attention Heads: Co-activation Proposes, Ablation Disposes
Co-activation clustering of attention heads proposes candidate circuits that pass causal closure validation in dense 1B models but fail in a Mixture-of-Experts model, where ablation can improve loss.
-
When Do Attention Circuits Form? Developmental Trajectories of Capability and Attention-Sink Emergence Across Three 1B-ClassArchitectures
In 1B-class models on DCLM, induction-circuit formation precedes BOS-attractor formation by 10-20x tokens with qualitatively different emergence shapes across architectures.
Reference graph
Works this paper leans on
-
[1]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling. InInternational Conference on Machine Learning, ...
2023
-
[2]
Successorheads: Recurring, interpretable attention heads in the wild
RhysGould, EuanOng, GeorgeOgden, andArthurConmy. Successorheads: Recurring, interpretable attention heads in the wild. InInternational Conference on Learning Representations, 2024. 33 Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. OLMo: Acceler- a...
2024
-
[3]
OLMoE: Open mixture-of-experts language models.arXiv preprint, 2024
Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, et al. OLMoE: Open mixture-of-experts language models.arXiv preprint, 2024. Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep
2024
-
[4]
In-context learning and induction heads
Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Ka- plan, Sam McCandlish, and Chris Olah. In-context learning and induction heads. Trans- former circuits thread, Anthropic, 2022. URL https://transformer-circuits.pub/2022/ in-context-learning-and-induction-heads/index.html. Kevin Wang, Alexandre Variengien, Arthur Conmy, Bu...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.