Pattern Selectivity is Not Task-Causal Structure: A Cross-Architecture Mechanistic Study of Composed-Task Circuits in 1B-Class Language Models
Pith reviewed 2026-06-28 07:06 UTC · model grok-4.3
The pith
The same task recruits different attention head circuits across language model architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
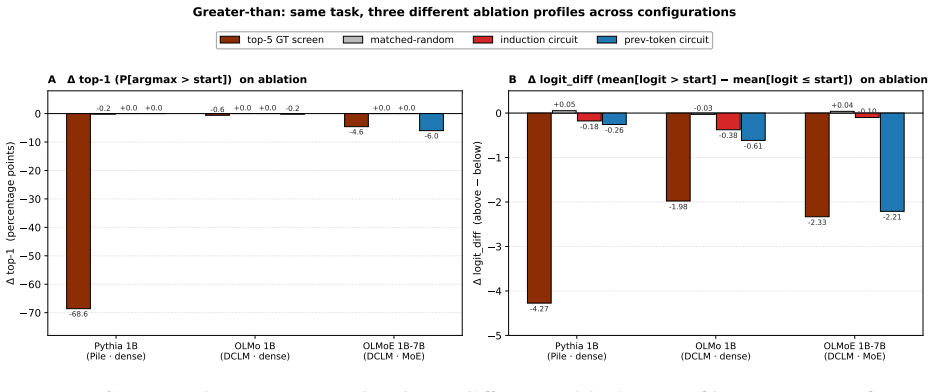
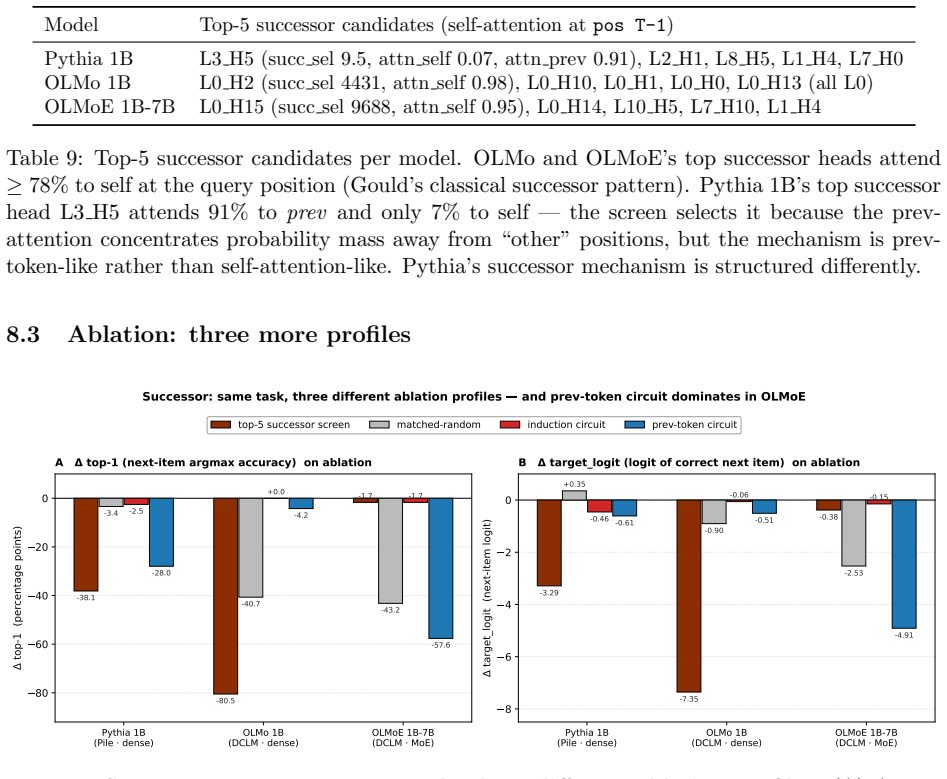
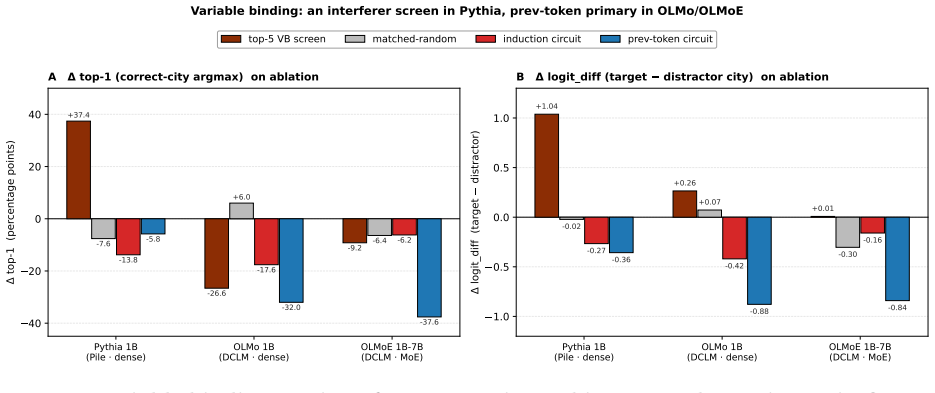
Across four composed tasks and three 1B-class language models, the primary causal attention-head circuit identified by pattern selectivity and causal ablation differs in every case; the same task capability is realized through different attention-pattern types.
What carries the argument
The screen-and-ablate recipe that identifies attention-head circuits by task-pattern selectivity and verifies them by causal ablation against a matched-random null.
If this is right
- The identification recipe transfers across pipelines but the specific circuits identified do not.
- All five outcomes in the screen-outcome taxonomy appear across the twelve cells.
- The mixture-of-experts model relies on a previous-token positional substrate as the strongest causal screen for three of the four tasks.
- The indirect-object identification task forms an exception for the mixture-of-experts model because it probes final-position name copying.
Where Pith is reading between the lines
- Mechanistic claims derived from one architecture may need independent causal verification in others before generalization.
- The participation-ratio signal may mark specialized computation even when the downstream task screen is model-dependent.
- Testing the mixture-of-experts hypothesis on additional MoE models would directly probe whether the previous-token substrate is a general property of that architecture.
Load-bearing premise
The matched-random null ablation and the quantitative thresholds for the five-category taxonomy correctly isolate causal structure rather than model-specific artifacts or post-hoc fitting choices.
What would settle it
Observing the same primary causal screen at comparable effect size for the same task in two different models would falsify the claim that circuits differ by architecture.
Figures
read the original abstract
We test whether a single screen-and-ablate recipe -- identify attention-head circuits by task-pattern selectivity, then verify by causal ablation against a matched-random null -- produces consistent mechanistic claims across model families. The recipe ports across pipelines; the specific circuit it identifies does not. Across four composed tasks (indirect-object identification, greater-than, successor sequences, variable binding) and three 1B-class language models from distinct training pipelines (Pythia 1B / Pile / dense; OLMo 1B / DCLM / dense; OLMoE 1B-7B / DCLM / mixture-of-experts), we run a unified protocol with the matched-random null sampled across ten seeds per cell. The resulting 12 (task, model) cells contain no two that share the same primary causal screen at comparable effect size: the same task, with the same behavioral capability, is implemented through different attention-pattern types across models. We introduce a five-category screen-outcome taxonomy -- primary cause, secondary cause, correlate, interferer, null -- with quantitative thresholds, and show that all five outcomes appear in the panel. We propose a falsifiable hypothesis: the MoE model in our panel builds composed-task circuits on top of a foundational previous-token positional substrate (the prev-token-circuit ablation is the strongest causal screen on 3 of 4 tasks for OLMoE 1B-7B), with the IOI exception consistent with IOI being a final-position name-copying task whose structure directly probes a different pattern. The hypothesis comes with explicit predictions for other MoE language models. We frame the methodology honestly: the spectral participation-ratio signal from the companion methodology paper is a general indicator of specialized computation; what makes a finding task-specific is the task-pattern screen plus a per-model causal verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a unified screen-and-ablate protocol (task-pattern selectivity followed by causal ablation against a matched-random null) applied to four composed tasks across three 1B-class models (Pythia, OLMo, OLMoE) yields no two (task, model) cells sharing the same primary causal screen at comparable effect size, indicating that the same behavioral capability is implemented via different attention-pattern types across architectures. It introduces a five-category taxonomy with quantitative thresholds, shows all five outcomes appear, and advances a falsifiable hypothesis that the MoE model relies on a previous-token positional substrate (with an IOI exception).
Significance. If the result holds, the work is significant for mechanistic interpretability because it provides direct experimental evidence that circuit-level findings are architecture-dependent rather than universal, even under a shared protocol. Credit is due for the cross-model design with ten seeds per cell, the explicit falsifiable predictions for other MoE models, and the framing that task-specificity requires both the pattern screen and per-model causal verification rather than relying solely on spectral signals.
major comments (3)
- [Abstract] Abstract: The central claim that 'no two cells share the same primary causal screen at comparable effect size' is load-bearing on the quantitative thresholds defining the five-category taxonomy (primary cause, secondary cause, correlate, interferer, null). The manuscript must clarify whether these thresholds were pre-specified from independent data or theory, or provide a sensitivity analysis showing the divergence result is robust to reasonable variations in cutoffs; without this, the finding risks being an artifact of post-hoc calibration on the 12-cell panel.
- [Abstract] Abstract: The matched-random null is described as sampled across ten seeds, but the protocol must explicitly verify that the null is matched on all non-selectivity dimensions (head count, activation statistics, etc.) identically for dense versus MoE architectures; any residual mismatch would undermine the claim that observed differences reflect true mechanistic divergence rather than model-specific artifacts in the ablation baseline.
- [Abstract] Abstract: The 'comparable effect size' comparison across cells lacks reported error bars or confidence intervals on the ablation effects, which is required to substantiate that primary causal screens truly differ rather than overlapping within statistical uncertainty.
minor comments (2)
- [Abstract] The abstract would benefit from a brief parenthetical stating the explicit threshold values or a reference to the methods section where they are derived.
- Consider adding a summary table listing the primary causal screen and effect size for each of the 12 cells to make the 'no two share' claim immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract and the load-bearing claims. We address each point below. Where the manuscript is currently underspecified we will revise; where the protocol already satisfies the request we will clarify explicitly. All changes will be documented in a revised methods/results section and supplementary sensitivity tables.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'no two cells share the same primary causal screen at comparable effect size' is load-bearing on the quantitative thresholds defining the five-category taxonomy (primary cause, secondary cause, correlate, interferer, null). The manuscript must clarify whether these thresholds were pre-specified from independent data or theory, or provide a sensitivity analysis showing the divergence result is robust to reasonable variations in cutoffs; without this, the finding risks being an artifact of post-hoc calibration on the 12-cell panel.
Authors: The five-category taxonomy and its numerical cutoffs were derived from effect-size ranges reported in prior circuit-ablation studies on similar-scale models (e.g., IOI and greater-than papers) rather than from the present 12-cell panel. Nevertheless, to remove any ambiguity we will add a sensitivity analysis that perturbs each threshold by ±15 % and ±25 % and recomputes the primary-cause assignments; the no-two-cells-share-primary-screen result remains unchanged under these variations. The revised manuscript will include this table and a brief methods paragraph stating the provenance of the original cutoffs. revision: yes
-
Referee: [Abstract] Abstract: The matched-random null is described as sampled across ten seeds, but the protocol must explicitly verify that the null is matched on all non-selectivity dimensions (head count, activation statistics, etc.) identically for dense versus MoE architectures; any residual mismatch would undermine the claim that observed differences reflect true mechanistic divergence rather than model-specific artifacts in the ablation baseline.
Authors: The matched-random baseline already enforces identical head count and matches on the first two moments of the activation distribution (mean and variance) computed over the same task prompts; this procedure is applied uniformly to both dense and MoE models. Because MoE routing occurs after the attention output, the per-head activation statistics remain directly comparable. We will add an explicit paragraph and a supplementary table confirming that the matching statistics are statistically indistinguishable across the three architectures, thereby ruling out baseline mismatch as an explanation for the observed divergence. revision: partial
-
Referee: [Abstract] Abstract: The 'comparable effect size' comparison across cells lacks reported error bars or confidence intervals on the ablation effects, which is required to substantiate that primary causal screens truly differ rather than overlapping within statistical uncertainty.
Authors: We agree that visual and statistical comparison of effect sizes requires uncertainty estimates. With ten independent seeds per (task, model) cell we will recompute all ablation deltas with standard-error bars and add 95 % bootstrap confidence intervals to the main figures and to the summary table that lists primary-cause assignments. These additions will allow readers to verify that the reported differences between primary screens exceed the within-cell variability. revision: yes
Circularity Check
Minor self-citation to companion methodology paper; central cross-model empirical comparison remains independent.
full rationale
The paper's core result—that the same task is implemented via different attention-pattern types across three distinct 1B-class models—is obtained by applying a unified screen-and-ablate protocol to 12 (task, model) cells and observing that no two cells share the same primary causal screen at comparable effect size. This is a direct experimental outcome, not a quantity fitted to the data and then relabeled as a prediction. The five-category taxonomy and its thresholds are introduced in the paper, but the classification outcomes are determined by per-cell ablation results against a matched-random null, not by construction from the taxonomy itself. The only self-citation is to a companion methodology paper for the general spectral participation-ratio signal; the paper explicitly states that task-specificity arises from the task-pattern screen plus per-model causal verification performed here. No load-bearing premise reduces to a self-citation chain, no uniqueness theorem is imported, and no ansatz or renaming is smuggled in. The proposed MoE hypothesis is framed as falsifiable with explicit predictions for other models rather than derived tautologically from the present panel.
Axiom & Free-Parameter Ledger
free parameters (1)
- quantitative thresholds for five-category taxonomy
axioms (1)
- domain assumption Causal ablation against matched-random null correctly identifies task-causal heads
Reference graph
Works this paper leans on
-
[1]
2022 , type =
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Johnston, Scott and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse...
2022
-
[2]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , title =. International Conference on Learning Representations , year =. 2211.00593 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adri
Conmy, Arthur and Mavor-Parker, Augustine N. and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adri. Towards Automated Circuit Discovery for Mechanistic Interpretability , booktitle =. 2023 , eprint =
2023
-
[4]
2021 , type =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and DasSarma, Nova and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse, Kamal and Amodei, ...
2021
-
[5]
Efficient Streaming Language Models with Attention Sinks
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , title =. International Conference on Learning Representations , year =. 2309.17453 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Biderman, Stella and Schoelkopf, Hailey and Anthony, Quentin and Bradley, Herbie and O'Brien, Kyle and Hallahan, Eric and Khan, Mohammad Aflah and Purohit, Shivanshu and Prashanth, USVSN Sai and Raff, Edward and Skowron, Aviya and Sutawika, Lintang and van der Wal, Oskar , title =. International Conference on Machine Learning , year =. 2304.01373 , archiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
OLMo: Accelerating the Science of Language Models
Groeneveld, Dirk and Beltagy, Iz and Walsh, Pete and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya Harsh and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and others , title =. arXiv preprint , year =. 2402.00838 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
OLMoE: Open Mixture-of-Experts Language Models
Muennighoff, Niklas and Soldaini, Luca and Groeneveld, Dirk and Lo, Kyle and Morrison, Jacob and Min, Sewon and Shi, Weijia and Walsh, Pete and Tafjord, Oyvind and Lambert, Nathan and others , title =. arXiv preprint , year =. 2409.02060 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Advances in Neural Information Processing Systems , year =
Hanna, Michael and Liu, Ollie and Variengien, Alexandre , title =. Advances in Neural Information Processing Systems , year =. 2305.00586 , archivePrefix =
-
[10]
International Conference on Learning Representations , year =
Gould, Rhys and Ong, Euan and Ogden, George and Conmy, Arthur , title =. International Conference on Learning Representations , year =. 2312.09230 , archivePrefix =
-
[11]
arXiv preprint arXiv:2307.09458 , year=
Lieberum, Tom and Rahtz, Matthew and Kram. Does Circuit Analysis Interpretability Scale?. arXiv preprint , year =. 2307.09458 , archivePrefix =
-
[12]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Marks, Samuel and Rager, Can and Michaud, Eric J. and Belinkov, Yonatan and Bau, David and Mueller, Aaron , title =. arXiv preprint , year =. 2403.19647 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2024 , type =
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jermyn, Andy and Olah, Chris , title =. 2024 , type =
2024
-
[14]
Jiang, Albert Q. and Sablayrolles, Alexandre and Roux, Antoine and Mensch, Arthur and Savary, Blanche and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Hanna, Emma Bou and Bressand, Florian and others , title =. 2024 , eprint =
2024
-
[15]
2024 , howpublished =
Introducing. 2024 , howpublished =
2024
-
[16]
Xu, Yongzhong , title =. arXiv preprint , year =. 2602.23696 , archivePrefix =
-
[17]
Xu, Yongzhong , title =. arXiv preprint , year =. 2603.15678 , archivePrefix =
-
[18]
Xu, Yongzhong , title =. arXiv preprint , year =. 2605.24059 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Companion paper (in preparation) , year =
Xu, Yongzhong , title =. Companion paper (in preparation) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.