Riemannian Archetypal Analysis: Interpretable non-linear data analysis on deformed star distributions
Pith reviewed 2026-06-30 16:30 UTC · model grok-4.3
The pith
Riemannian archetypal analysis projects data onto manifolds of geodesically convex archetype combinations via pullback geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Riemannian archetypal mapping is defined as a projection onto the manifold of geodesically convex combinations of archetypes under the pullback Riemannian geometry induced by deformed star distributions, providing a statistically interpretable non-linear extension of classical archetypal analysis that combines interpretability with expressive power through a practical optimization scheme of convex relaxation and non-convex refinement.
What carries the argument
The Riemannian archetypal mapping (RAM) as the projection onto the manifold of geodesically convex combinations of archetypes, enabled by pullback Riemannian geometry on deformed star distributions.
If this is right
- The method produces meaningful geodesics between archetypes on the learned manifold.
- It yields useful denoising projections of input data points.
- It enables geometry-aware classifications of data.
- It clarifies remaining limitations in the convex-plus-non-convex optimization scheme.
Where Pith is reading between the lines
- The framework could be tested on additional high-dimensional datasets to assess scalability beyond MNIST.
- More effective schemes for learning the deformed star distributions from data might reduce the gap to optimality.
- Similar pullback constructions could be explored for other linear interpretable methods to create Riemannian variants.
Load-bearing premise
Data-driven pullback geometry defined on deformed star distributions supplies a valid statistical interpretation of the manifold mappings for real-valued data.
What would settle it
An experiment where the learned geodesics fail to produce better denoising or classification performance than classical linear archetypal analysis on the MNIST dataset would falsify the claimed practical advantage of the Riemannian extension.
Figures
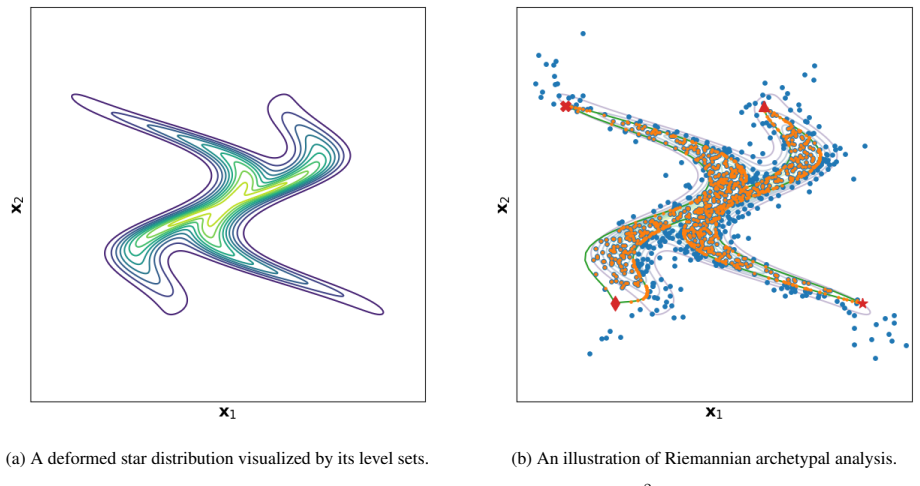

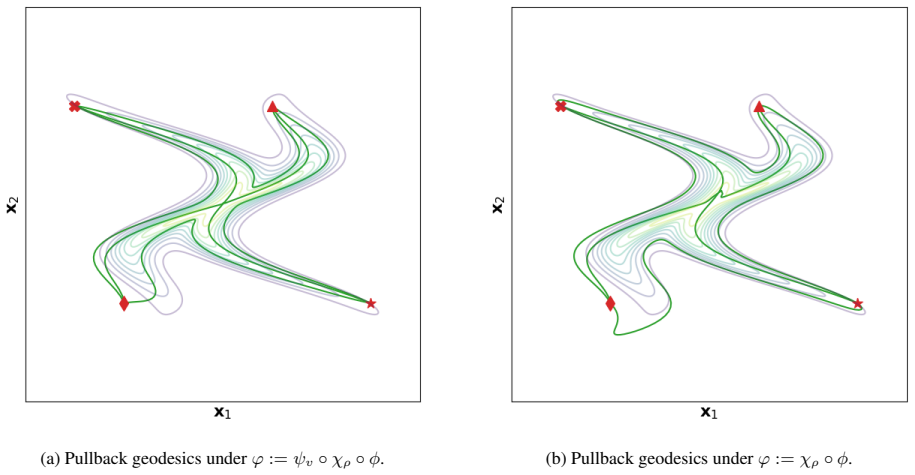
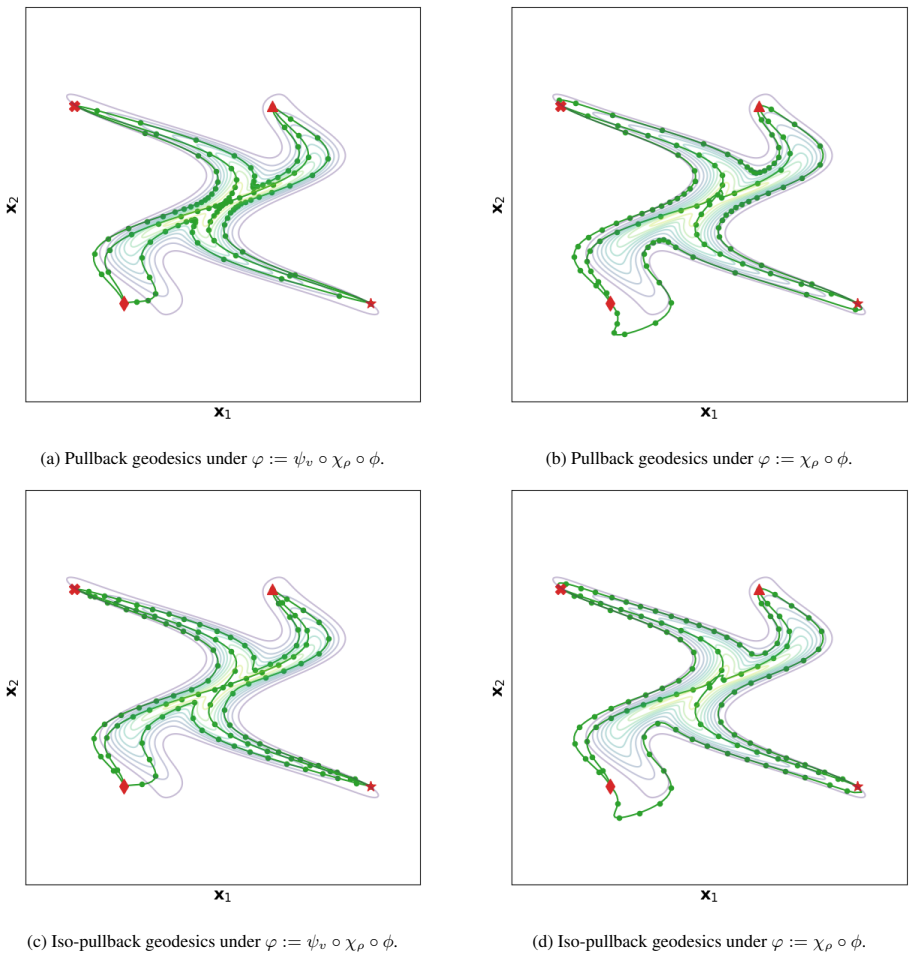
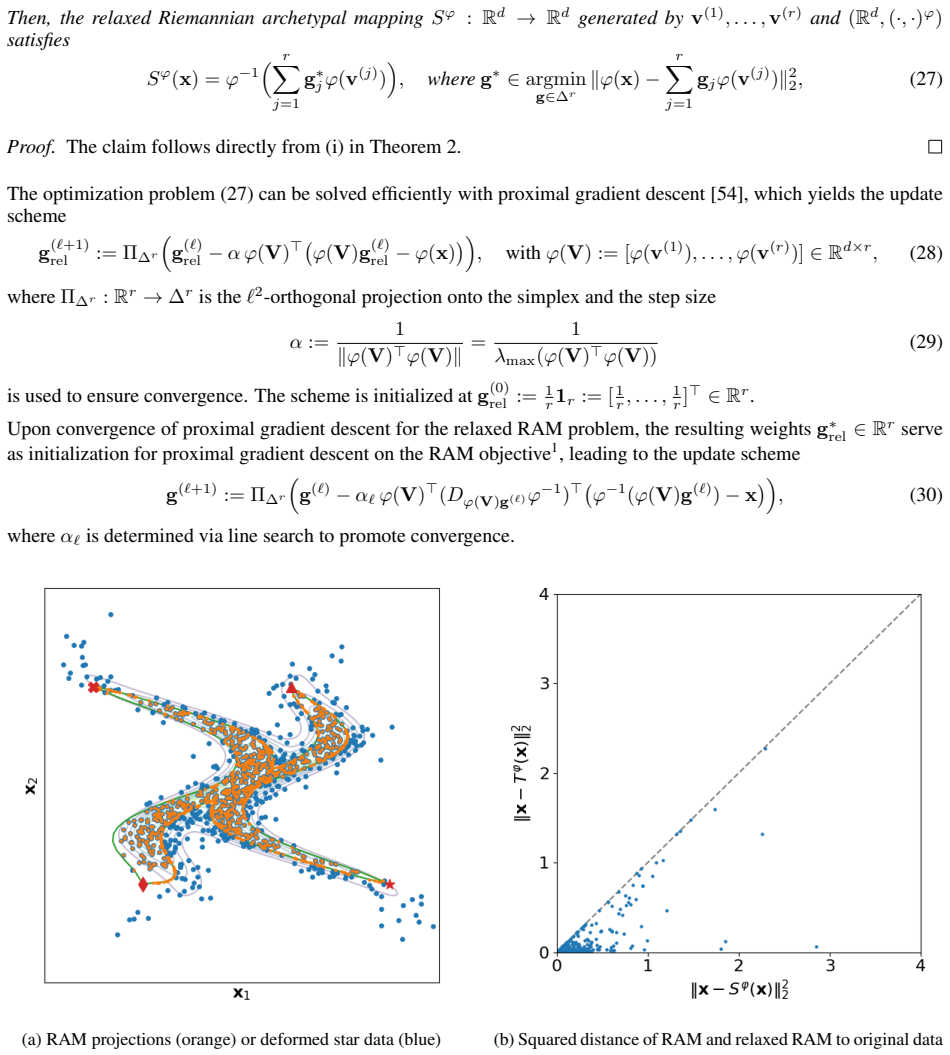


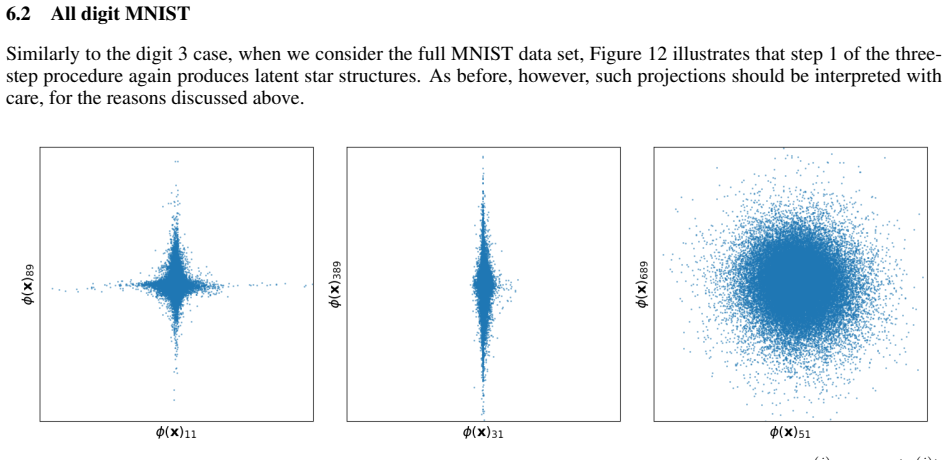



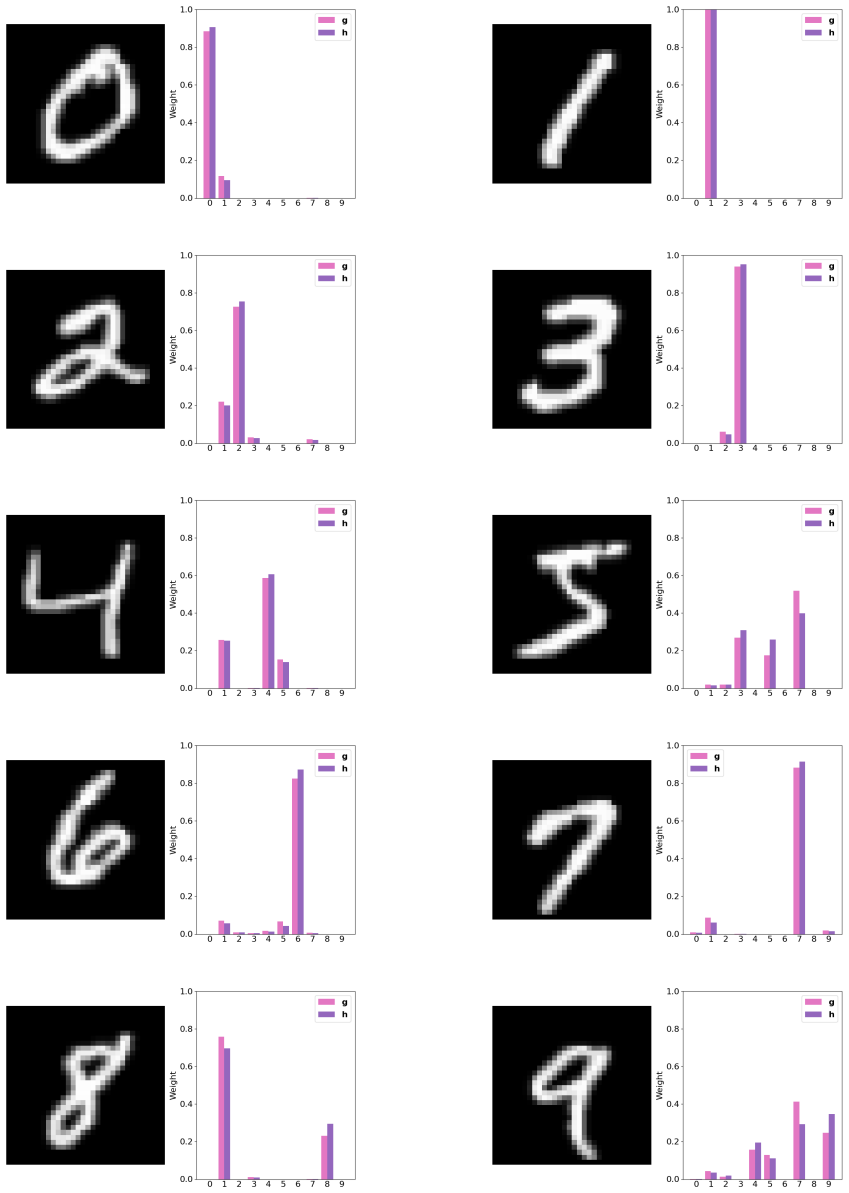
read the original abstract
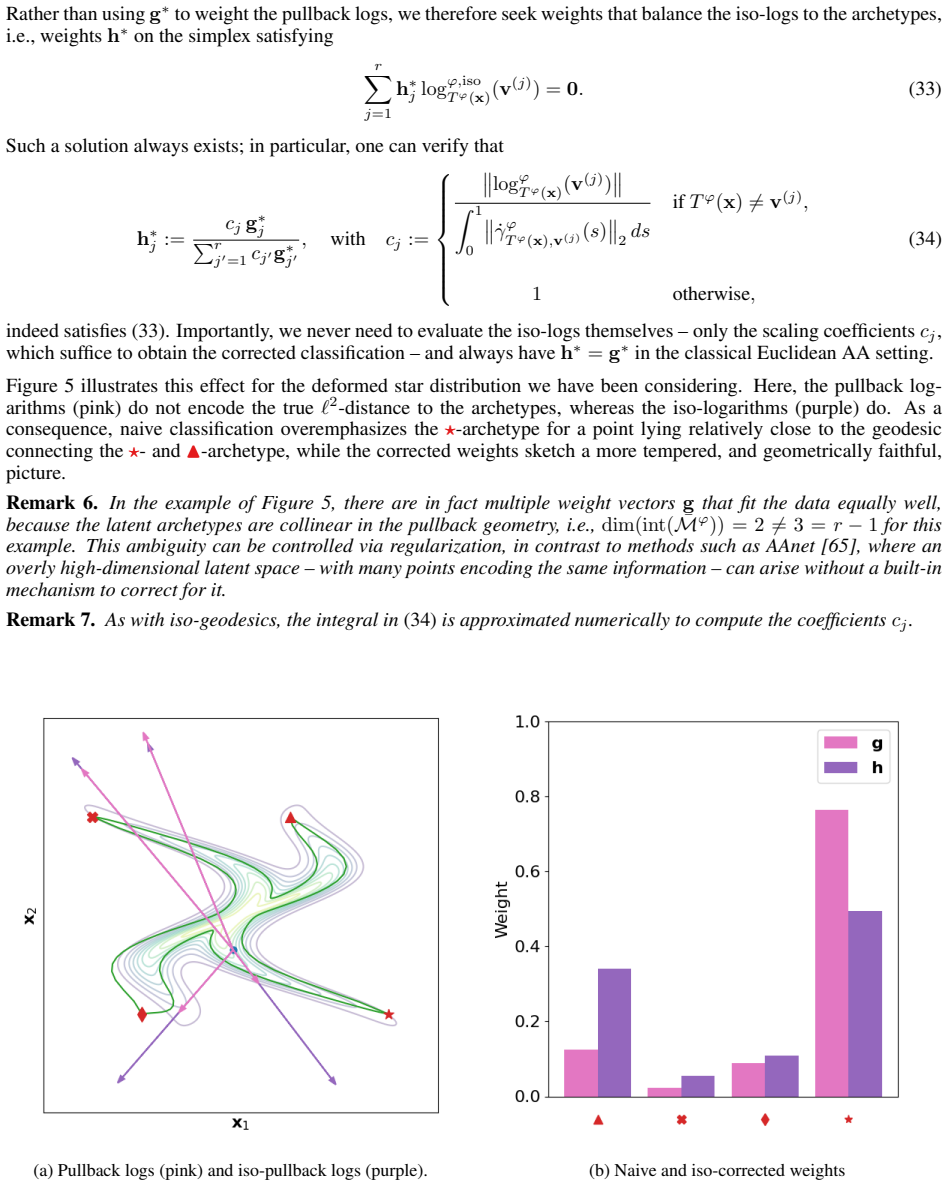
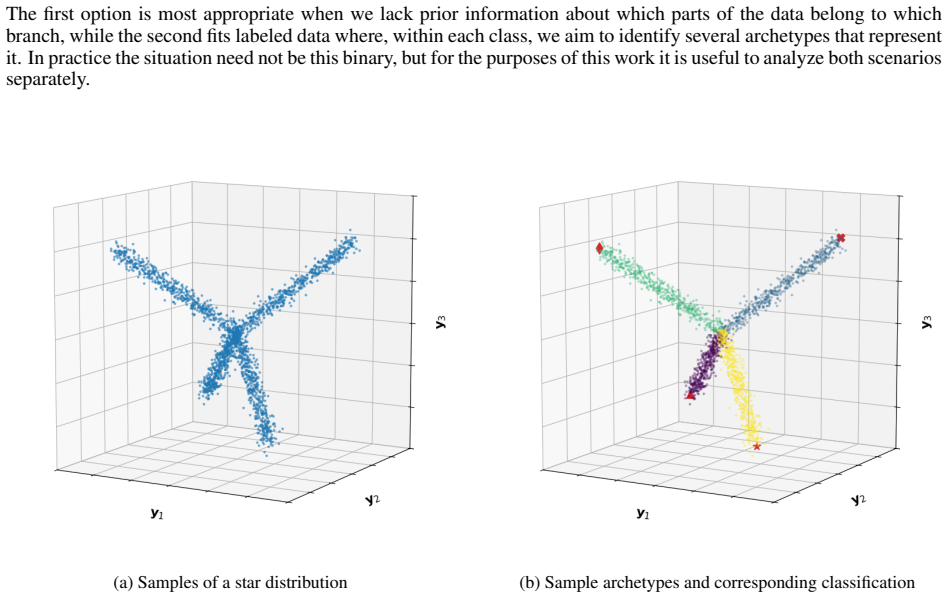
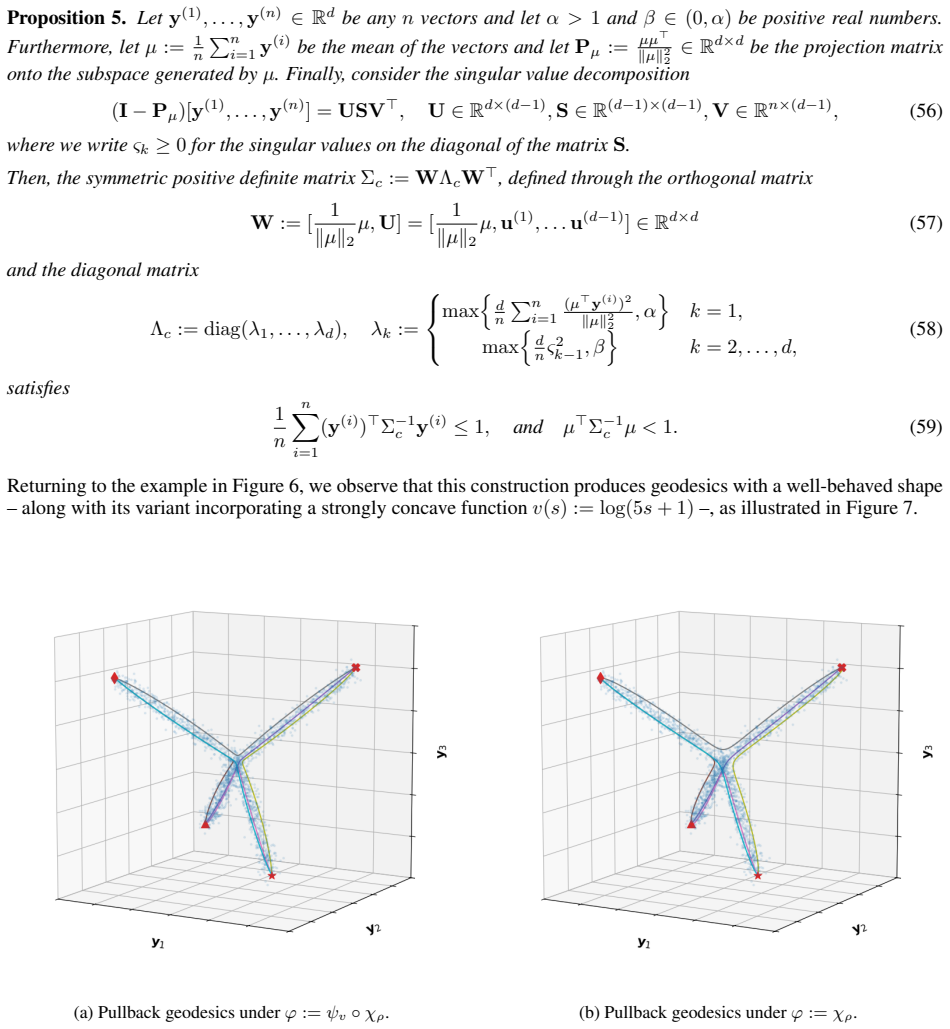
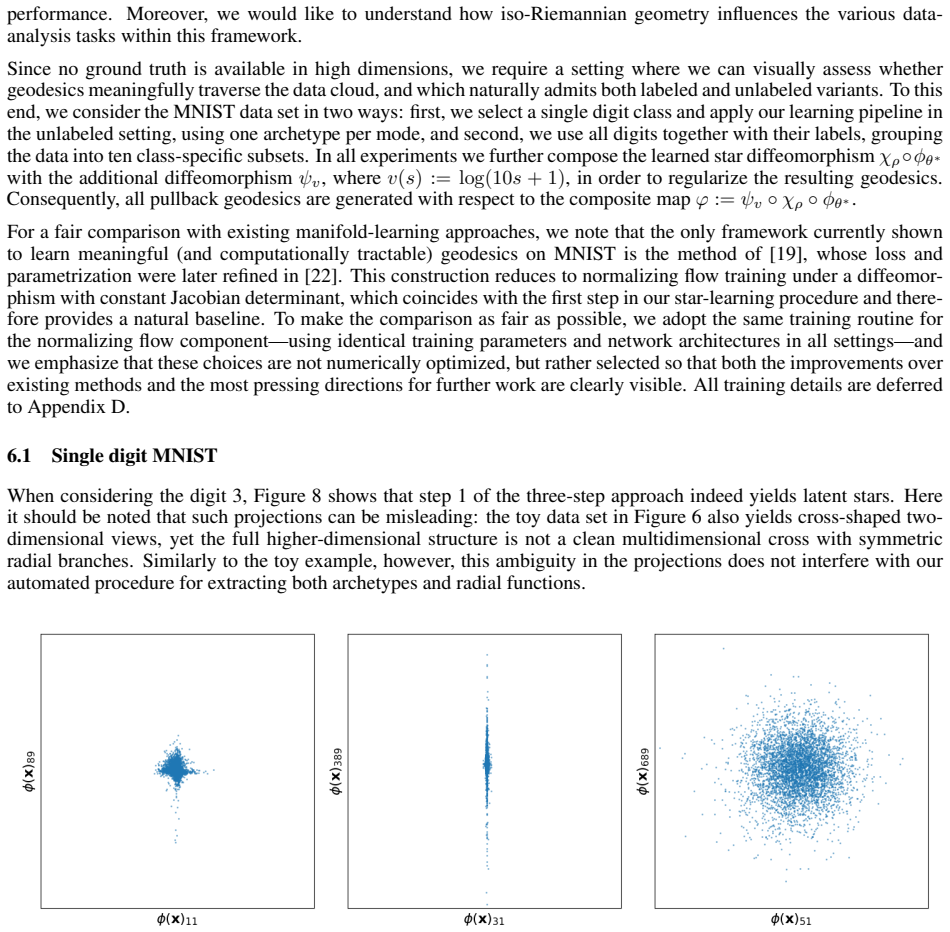
Classical archetypal analysis is appealing for its interpretability, but its linear geometry can limit performance on data with strongly non-linear structure; at the same time, existing neural extensions improve flexibility while often weakening the geometric meaning of archetypes and interpolations. In this work, we develop a Riemannian version of archetypal analysis based on data-driven pullback geometry for real-valued data, with the goal of combining the interpretability of classical archetypal analysis with the expressive power of modern non-linear models. We introduce a class of deformed star distributions together with associated pullback Riemannian geometry to provide a statistical interpretation of the resulting manifold mappings, define the Riemannian archetypal mapping (RAM) as a projection onto the manifold of geodesically convex combinations of archetypes, and propose a practical optimization scheme based on convex relaxation followed by non-convex refinement. We further propose a learning scheme that yields reasonable, albeit generally suboptimal, deformed star distributions from data. Experiments on synthetic examples and MNIST show that the resulting framework produces meaningful geodesics, useful denoising projections, and geometry-aware classifications, while also clarifying where current optimization limitations remain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops Riemannian Archetypal Analysis (RAM) for non-linear interpretable data analysis. It introduces a class of deformed star distributions to induce data-driven pullback Riemannian geometry, defines RAM as the projection onto the manifold of geodesically convex combinations of archetypes, proposes an optimization scheme via convex relaxation followed by non-convex refinement, and includes a learning scheme to obtain the distributions from data. Experiments on synthetic examples and MNIST are reported to produce meaningful geodesics, denoising projections, and geometry-aware classifications.
Significance. If the central construction is valid, the framework could usefully combine the interpretability of classical archetypal analysis with non-linear flexibility while retaining geometric meaning for archetypes and interpolations. The reported experiments indicate practical utility on both synthetic and image data, but the significance hinges on whether the pullback geometry supplies a coherent statistical model rather than an arbitrary construction.
major comments (2)
- [Abstract] Abstract: the assertion that deformed star distributions together with their pullback Riemannian geometry 'provide a statistical interpretation' of the manifold mappings is load-bearing for the central claim, yet the abstract (and the described construction) supplies no independent derivation linking the pullback metric to a standard statistical object such as a density or likelihood; the geometry is data-driven by construction, leaving open whether geodesics and convex combinations correspond to any coherent probabilistic model for real-valued data.
- [Learning scheme description] The learning scheme that produces deformed star distributions from data is presented as yielding 'reasonable, albeit generally suboptimal' results, but without external benchmarks or verification that the induced manifold satisfies the statistical-interpretation requirement, the scheme risks circularity: the distributions are fitted to enable the geometry that is then claimed to interpret the mappings.
minor comments (2)
- [Optimization] The optimization scheme is described at a high level (convex relaxation then non-convex refinement) but lacks explicit convergence analysis or guarantees that the refined solution remains on the geodesically convex hull; this should be clarified with pseudocode or a dedicated subsection.
- [Experiments] MNIST experiments report qualitative benefits for denoising and classification but provide no quantitative metrics (e.g., reconstruction error, classification accuracy) or comparisons against linear archetypal analysis or other non-linear baselines.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that deformed star distributions together with their pullback Riemannian geometry 'provide a statistical interpretation' of the manifold mappings is load-bearing for the central claim, yet the abstract (and the described construction) supplies no independent derivation linking the pullback metric to a standard statistical object such as a density or likelihood; the geometry is data-driven by construction, leaving open whether geodesics and convex combinations correspond to any coherent probabilistic model for real-valued data.
Authors: The deformed star distributions are explicitly constructed as a parametric family of probability distributions on the data space. The pullback Riemannian geometry is then induced by considering the mapping from the simplex of archetype weights to the parameters of these distributions. This provides a statistical interpretation because the archetypes correspond to specific distributions in the family, and geodesically convex combinations correspond to paths within this parametric family, allowing for probabilistic interpretations of interpolations and projections. We acknowledge that this does not constitute a full likelihood model for general real-valued data beyond the induced geometry. To address the concern, we will revise the abstract to clarify that the statistical interpretation is in terms of the parametric family of distributions rather than a direct density estimation framework. revision: yes
-
Referee: [Learning scheme description] The learning scheme that produces deformed star distributions from data is presented as yielding 'reasonable, albeit generally suboptimal' results, but without external benchmarks or verification that the induced manifold satisfies the statistical-interpretation requirement, the scheme risks circularity: the distributions are fitted to enable the geometry that is then claimed to interpret the mappings.
Authors: We agree that the learning scheme is heuristic, as explicitly stated in the manuscript. The scheme fits the distributions to the data to capture its structure, after which the geometry is derived. While this could appear circular, the experiments on synthetic data and MNIST demonstrate that the resulting manifolds yield meaningful geodesics and classifications, providing empirical support. We do not provide external benchmarks comparing to other distribution learning methods, which is a limitation. In the revision, we will expand the discussion of the learning scheme to include its limitations and potential for future improvements with more rigorous validation. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces deformed star distributions and associated pullback geometry as a new construction to support the Riemannian archetypal mapping, along with a proposed learning scheme and optimization procedure. No equations or self-citations are available in the provided text that reduce any central claim (such as the statistical interpretation or manifold mappings) to a fitted input, self-definition, or prior author result by construction. The framework is presented as a novel combination of interpretability and non-linear modeling, with experiments on synthetic data and MNIST serving as external validation points. The derivation chain is therefore self-contained against the stated assumptions and does not exhibit load-bearing reductions of the enumerated kinds.
Axiom & Free-Parameter Ledger
invented entities (1)
-
deformed star distributions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Simplex-structured matrix factorization: Sparsity-based identifiability and provably correct algorithms.SIAM Journal on Mathematics of Data Science, 3(2):593–623, 2021
Maryam Abdolali and Nicolas Gillis. Simplex-structured matrix factorization: Sparsity-based identifiability and provably correct algorithms.SIAM Journal on Mathematics of Data Science, 3(2):593–623, 2021
2021
-
[2]
Princeton University Press, 2008
P-A Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization algorithms on matrix manifolds. Princeton University Press, 2008
2008
-
[3]
Manifold learning by mixture models of vaes for inverse problems.Journal of Machine Learning Research, 25(202):1–35, 2024
Giovanni S Alberti, Johannes Hertrich, Matteo Santacesaria, and Silvia Sciutto. Manifold learning by mixture models of vaes for inverse problems.Journal of Machine Learning Research, 25(202):1–35, 2024
2024
-
[4]
A survey on archetypal analysis.arXiv preprint arXiv:2504.12392, 2025
Aleix Alcacer, Irene Epifanio, Sebastian Mair, and Morten Mørup. A survey on archetypal analysis.arXiv preprint arXiv:2504.12392, 2025
-
[5]
A locally adaptive normal distribution.Advances in Neural Information Processing Systems, 29, 2016
Georgios Arvanitidis, Lars K Hansen, and Søren Hauberg. A locally adaptive normal distribution.Advances in Neural Information Processing Systems, 29, 2016
2016
-
[6]
Uncov- ering developmental lineages from single-cell data with contrastive poincar ´e maps.bioRxiv, pages 2025–08, 2025
Nithya Bhasker, Hattie Chung, Louis Boucherie, Vladislav Kim, Stefanie Speidel, and Melanie Weber. Uncov- ering developmental lineages from single-cell data with contrastive poincar ´e maps.bioRxiv, pages 2025–08, 2025
2025
-
[7]
William M Boothby.An introduction to differentiable manifolds and Riemannian geometry, Revised, volume
-
[8]
Gulf Professional Publishing, 2003
2003
-
[9]
Cambridge University Press, 2023
Nicolas Boumal.An introduction to optimization on smooth manifolds. Cambridge University Press, 2023
2023
-
[10]
Birkh ¨auser, 1992
Manfredo Perdigao do Carmo.Riemannian geometry. Birkh ¨auser, 1992
1992
-
[11]
Redunet: A white-box deep network from the principle of maximizing rate reduction.Journal of machine learning research, 23(114):1–103, 2022
Kwan Ho Ryan Chan, Yaodong Yu, Chong You, Haozhi Qi, John Wright, and Yi Ma. Redunet: A white-box deep network from the principle of maximizing rate reduction.Journal of machine learning research, 23(114):1–103, 2022
2022
-
[12]
The specious art of single-cell genomics.PLOS Computational Biology, 19(8):e1011288, 2023
Tara Chari and Lior Pachter. The specious art of single-cell genomics.PLOS Computational Biology, 19(8):e1011288, 2023
2023
-
[13]
Curvature corrected nonnegative manifold data factoriza- tion.arXiv preprint arXiv:2502.15124, 2025
Joyce Chew, Willem Diepeveen, and Deanna Needell. Curvature corrected nonnegative manifold data factoriza- tion.arXiv preprint arXiv:2502.15124, 2025
-
[14]
Hyperbolic vae via latent gaussian distributions.Advances in Neural Information Processing Systems, 36:569–588, 2023
Seunghyuk Cho, Juyong Lee, and Dongwoo Kim. Hyperbolic vae via latent gaussian distributions.Advances in Neural Information Processing Systems, 36:569–588, 2023
2023
-
[15]
Independent component analysis, a new concept?Signal processing, 36(3):287–314, 1994
Pierre Comon. Independent component analysis, a new concept?Signal processing, 36(3):287–314, 1994
1994
-
[16]
Archetypal analysis.Technometrics, 36(4):338–347, 1994
Adele Cutler and Leo Breiman. Archetypal analysis.Technometrics, 36(4):338–347, 1994. 26
1994
-
[17]
Intermediate layer optimization for inverse problems using deep generative models
Giannis Daras, Joseph Dean, Ajil Jalal, and Alex Dimakis. Intermediate layer optimization for inverse problems using deep generative models. InInternational Conference on Machine Learning, pages 2421–2432. PMLR, 2021
2021
-
[18]
Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M
Tim R. Davidson, Luca Falorsi, Nicola De Cao, Thomas Kipf, and Jakub M. Tomczak. Hyperspherical variational auto-encoders.34th Conference on Uncertainty in Artificial Intelligence (UAI-18), 2018
2018
-
[19]
Pulling back symmetric riemannian geometry for data analysis.arXiv preprint arXiv:2403.06612, 2024
Willem Diepeveen. Pulling back symmetric riemannian geometry for data analysis.arXiv preprint arXiv:2403.06612, 2024
-
[20]
Score-based pullback riemannian geometry: Extracting the data manifold geometry using anisotropic flows
Willem Diepeveen, Georgios Batzolis, Zakhar Shumaylov, and Carola-Bibiane Sch¨onlieb. Score-based pullback riemannian geometry: Extracting the data manifold geometry using anisotropic flows. InForty-second Interna- tional Conference on Machine Learning, 2025
2025
-
[21]
Curvature-corrected tangent space-based approximation of manifold-valued data.Information and Inference: A Journal of the IMA, 14(4):iaaf031, 2025
Willem Diepeveen, Joyce Chew, and Deanna Needell. Curvature-corrected tangent space-based approximation of manifold-valued data.Information and Inference: A Journal of the IMA, 14(4):iaaf031, 2025
2025
-
[22]
Willem Diepeveen and Oscar Leong. Riemannian ambientflow: Towards simultaneous manifold learning and generative modeling from corrupted data.arXiv preprint arXiv:2601.18728, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Willem Diepeveen and Deanna Needell. Manifold learning with normalizing flows: Towards regularity, expres- sivity and iso-riemannian geometry.arXiv preprint arXiv:2505.08087, 2025
-
[24]
Iso-Riemannian Optimization on Learned Data Manifolds
Willem Diepeveen and Melanie Weber. Iso-riemannian optimization on learned data manifolds.arXiv preprint arXiv:2510.21033, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Convex and semi-nonnegative matrix factorizations.IEEE transactions on pattern analysis and machine intelligence, 32(1):45–55, 2008
Chris HQ Ding, Tao Li, and Michael I Jordan. Convex and semi-nonnegative matrix factorizations.IEEE transactions on pattern analysis and machine intelligence, 32(1):45–55, 2008
2008
-
[26]
NICE: Non-linear Independent Components Estimation
Laurent Dinh, David Krueger, and Yoshua Bengio. Nice: Non-linear independent components estimation.arXiv preprint arXiv:1410.8516, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Testing the manifold hypothesis.Journal of the American Mathematical Society, 29(4):983–1049, 2016
Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis.Journal of the American Mathematical Society, 29(4):983–1049, 2016
2016
-
[28]
Principal geodesic analysis for the study of nonlinear statistics of shape.IEEE transactions on medical imaging, 23(8):995–1005, 2004
P Thomas Fletcher, Conglin Lu, Stephen M Pizer, and Sarang Joshi. Principal geodesic analysis for the study of nonlinear statistics of shape.IEEE transactions on medical imaging, 23(8):995–1005, 2004
2004
-
[29]
Riemannian metric learning: Closer to you than you imagine.arXiv preprint arXiv:2503.05321, 2025
Samuel Gruffaz and Josua Sassen. Riemannian metric learning: Closer to you than you imagine.arXiv preprint arXiv:2503.05321, 2025
-
[30]
Phase retrieval under a generative prior.Advances in Neural Information Processing Systems, 31, 2018
Paul Hand, Oscar Leong, and Vlad V oroninski. Phase retrieval under a generative prior.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[31]
Global guarantees for enforcing deep generative priors by empirical risk
Paul Hand and Vladislav V oroninski. Global guarantees for enforcing deep generative priors by empirical risk. InConference On Learning Theory, pages 970–978. PMLR, 2018
2018
-
[32]
Geodesic Calculus on Implicitly Defined Latent Manifolds
Florine Hartwig, Josua Sassen, Juliane Braunsmann, Martin Rumpf, and Benedikt Wirth. Geodesic calculus on implicitly defined latent manifolds.arXiv preprint arXiv:2510.09468, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
A geometric take on metric learning.Advances in Neural Information Processing Systems, 25, 2012
Søren Hauberg, Oren Freifeld, and Michael Black. A geometric take on metric learning.Advances in Neural Information Processing Systems, 25, 2012
2012
-
[34]
Johannes Hertrich, Hok Shing Wong, Alexander Denker, Stanislas Ducotterd, Zhenghan Fang, Markus Halt- meier, ˇZeljko Kereta, Erich Kobler, Oscar Leong, Mohammad Sadegh Salehi, et al. Learning regularization functionals for inverse problems: A comparative study.arXiv preprint arXiv:2510.01755, 2025
-
[35]
On a nonlinear generalization of sparse coding and dictionary learn- ing
Jeffrey Ho, Yuchen Xie, and Baba Vemuri. On a nonlinear generalization of sparse coding and dictionary learn- ing. InInternational conference on machine learning, pages 1480–1488. PMLR, 2013
2013
-
[36]
Riemannian center of mass and mollifier smoothing.Communications on pure and applied mathematics, 30(5):509–541, 1977
Hermann Karcher. Riemannian center of mass and mollifier smoothing.Communications on pure and applied mathematics, 30(5):509–541, 1977
1977
-
[37]
Learning extremal representations with deep archetypal analysis.International journal of computer vision, 129(4):805– 820, 2021
Sebastian Mathias Keller, Maxim Samarin, Fabricio Arend Torres, Mario Wieser, and V olker Roth. Learning extremal representations with deep archetypal analysis.International journal of computer vision, 129(4):805– 820, 2021
2021
-
[38]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[39]
Glow: Generative flow with invertible 1x1 convolutions.Advances in neural information processing systems, 31, 2018
Durk P Kingma and Prafulla Dhariwal. Glow: Generative flow with invertible 1x1 convolutions.Advances in neural information processing systems, 31, 2018
2018
-
[40]
Non-negative matrix factor- ization and deconvolution as a dual simplex problem.Genome Biology, 2026
Denis Kleverov, Ekaterina Aladyeva, Alexey Serdyukov, and Maxim N Artyomov. Non-negative matrix factor- ization and deconvolution as a dual simplex problem.Genome Biology, 2026. 27
2026
-
[41]
Ldle: Low distortion local eigenmaps.Journal of machine learning research, 22(282):1–64, 2021
Dhruv Kohli, Alexander Cloninger, and Gal Mishne. Ldle: Low distortion local eigenmaps.Journal of machine learning research, 22(282):1–64, 2021
2021
-
[42]
Smooth manifolds
John M Lee. Smooth manifolds. InIntroduction to Smooth Manifolds, pages 1–31. Springer, 2013
2013
-
[43]
Geometry-Preserving Encoder/Decoder in Latent Generative Models
Wonjun Lee, Riley CW O’Neill, Dongmian Zou, Jeff Calder, and Gilad Lerman. Geometry-preserving en- coder/decoder in latent generative models.arXiv preprint arXiv:2501.09876, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Inverting deep generative models, one layer at a time.Advances in neural information processing systems, 32, 2019
Qi Lei, Ajil Jalal, Inderjit S Dhillon, and Alexandros G Dimakis. Inverting deep generative models, one layer at a time.Advances in neural information processing systems, 32, 2019
2019
-
[45]
The star geometry of critic-based regularizer learning.Advances in Neural Information Processing Systems, 37:71240–71276, 2024
Oscar Leong, Eliza O’Reilly, and Yong S Soh. The star geometry of critic-based regularizer learning.Advances in Neural Information Processing Systems, 37:71240–71276, 2024
2024
-
[46]
Optimal regularization for a data source.Foundations of Computational Mathematics, pages 1–50, 2025
Oscar Leong, Eliza O’Reilly, Yong Sheng Soh, and Venkat Chandrasekaran. Optimal regularization for a data source.Foundations of Computational Mathematics, pages 1–50, 2025
2025
-
[47]
Oscar Leong and Yann Traonmilin. A recovery theory for diffusion priors: Deterministic analysis of the implicit prior algorithm.arXiv preprint arXiv:2509.20511, 2025
-
[48]
Minimum volume simplex analysis: A fast algorithm to unmix hyperspectral data
Jun Li and Jos ´e M Bioucas-Dias. Minimum volume simplex analysis: A fast algorithm to unmix hyperspectral data. InIGARSS 2008-2008 IEEE International Geoscience and Remote Sensing Symposium, volume 3, pages III–250. IEEE, 2008
2008
-
[49]
Chia-Hsiang Lin, Ruiyuan Wu, Wing-Kin Ma, Chong-Yung Chi, and Yue Wang. Maximum volume inscribed ellipsoid: A new simplex-structured matrix factorization framework via facet enumeration and convex optimiza- tion.SIAM Journal on Imaging Sciences, 11(2):1651–1679, 2018
2018
-
[50]
Lidan Miao and Hairong Qi. Endmember extraction from highly mixed data using minimum volume constrained nonnegative matrix factorization.IEEE Transactions on Geoscience and Remote Sensing, 45(3):765–777, 2007
2007
-
[51]
Geomstats: A python package for riemannian geometry in machine learning.Journal of Machine Learning Research, 21(223):1–9, 2020
Nina Miolane, Nicolas Guigui, Alice Le Brigant, Johan Mathe, Benjamin Hou, Yann Thanwerdas, Stefan Heyder, Olivier Peltre, Niklas Koep, Hadi Zaatiti, et al. Geomstats: A python package for riemannian geometry in machine learning.Journal of Machine Learning Research, 21(223):1–9, 2020
2020
-
[52]
Visualizing structure and transitions in high-dimensional biological data.Nature biotechnology, 37(12):1482–1492, 2019
Kevin R Moon, David Van Dijk, Zheng Wang, Scott Gigante, Daniel B Burkhardt, William S Chen, Kristina Yim, Antonia van den Elzen, Matthew J Hirn, Ronald R Coifman, et al. Visualizing structure and transitions in high-dimensional biological data.Nature biotechnology, 37(12):1482–1492, 2019
2019
-
[53]
Vertex component analysis: A fast algorithm to unmix hyperspectral data.IEEE transactions on Geoscience and Remote Sensing, 43(4):898–910, 2005
Jos ´e MP Nascimento and Jos ´e MB Dias. Vertex component analysis: A fast algorithm to unmix hyperspectral data.IEEE transactions on Geoscience and Remote Sensing, 43(4):898–910, 2005
2005
-
[54]
Positive matrix factorization: A non-negative factor model with optimal utiliza- tion of error estimates of data values.Environmetrics, 5(2):111–126, 1994
Pentti Paatero and Unto Tapper. Positive matrix factorization: A non-negative factor model with optimal utiliza- tion of error estimates of data values.Environmetrics, 5(2):111–126, 1994
1994
-
[55]
Proximal algorithms.Foundations and Trends in optimization, 1(3):127–239, 2014
Neal Parikh and Stephen Boyd. Proximal algorithms.Foundations and Trends in optimization, 1(3):127–239, 2014
2014
-
[56]
Karl Pearson. Liii. on lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin philosophical magazine and journal of science, 2(11):559–572, 1901
1901
-
[57]
Improved learning of riemannian metrics for exploratory analysis.Neural Networks, 17(8-9):1087–1100, 2004
Jaakko Peltonen, Arto Klami, and Samuel Kaski. Improved learning of riemannian metrics for exploratory analysis.Neural Networks, 17(8-9):1087–1100, 2004
2004
-
[58]
Representation learning via manifold flattening and reconstruction.Journal of Machine Learning Research, 25(132):1–47, 2024
Michael Psenka, Druv Pai, Vishal Raman, Shankar Sastry, and Yi Ma. Representation learning via manifold flattening and reconstruction.Journal of Machine Learning Research, 25(132):1–47, 2024
2024
-
[59]
Manifold learning and optimization using tangent space proxies.arXiv preprint arXiv:2501.12678, 2025
Ryan A Robinett, Lorenzo Orecchia, and Samantha J Riesenfeld. Manifold learning and optimization using tangent space proxies.arXiv preprint arXiv:2501.12678, 2025
-
[60]
American Mathematical Soc., 1996
Takashi Sakai.Riemannian geometry, volume 149. American Mathematical Soc., 1996
1996
-
[61]
Riemannian metric learning via optimal transport
Christopher Scarvelis and Justin Solomon. Riemannian metric learning via optimal transport. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[62]
Manifold free riemannian optimization.arXiv preprint arXiv:2209.03269, 2022
Boris Shustin, Haim Avron, and Barak Sober. Manifold free riemannian optimization.arXiv preprint arXiv:2209.03269, 2022
-
[63]
Learning distances from data with normalizing flows and score matching
Peter Sorrenson, Daniel Behrend-Uriarte, Christoph Schnoerr, and Ullrich Koethe. Learning distances from data with normalizing flows and score matching. InForty-second International Conference on Machine Learning, 2025. 28
2025
-
[64]
Xingzhi Sun, Danqi Liao, Kincaid MacDonald, Yanlei Zhang, Guillaume Huguet, Guy Wolf, Ian Adelstein, Tim G. J. Rudner, and Smita Krishnaswamy. Geometry-aware autoencoders for metric learning and generative modeling on data manifolds. InICML 2024 Workshop on Geometry-grounded Representation Learning and Generative Modeling, 2024
2024
-
[65]
K-deep simplex: Manifold learning via local dictionaries.IEEE Transactions on Signal Processing, 71:3741–3754, 2023
Abiy Tasissa, Pranay Tankala, James M Murphy, and Demba Ba. K-deep simplex: Manifold learning via local dictionaries.IEEE Transactions on Signal Processing, 71:3741–3754, 2023
2023
-
[66]
Finding archetypal spaces using neural networks
David van Dijk, Daniel B Burkhardt, Matthew Amodio, Alexander Tong, Guy Wolf, and Smita Krishnaswamy. Finding archetypal spaces using neural networks. In2019 IEEE International Conference on Big Data (Big Data), pages 2634–2643. IEEE, 2019
2019
-
[67]
Aanet resolves a continuum of spatially localized cell states to unveil intratumoral heterogeneity.Cancer Discovery, 15(10):2139–2165, 2025
Aarthi Venkat, Scott E Youlten, Beatriz P San Juan, Carley A Purcell, Shabarni Gupta, Matthew Amodio, Daniel P Neumann, John G Lock, Anton E Westacott, Cerys S McCool, et al. Aanet resolves a continuum of spatially localized cell states to unveil intratumoral heterogeneity.Cancer Discovery, 15(10):2139–2165, 2025
2025
-
[68]
Discovering data manifold geometry via non-contracting flows.arXiv preprint arXiv:2602.02611, 2026
David Vigouroux, Lucas Drumetz, Ronan Fablet, and Franc ¸ois Rousseau. Discovering data manifold geometry via non-contracting flows.arXiv preprint arXiv:2602.02611, 2026
-
[69]
Diffusion models learn low- dimensional distributions via subspace clustering
Peng Wang, Huijie Zhang, Zekai Zhang, Siyi Chen, Yi Ma, and Qing Qu. Diffusion models learn low- dimensional distributions via subspace clustering. In2025 IEEE 10th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), pages 211–215. IEEE, 2025
2025
-
[70]
Statistical exploration of the manifold hypothesis
Nick Whiteley, Annie Gray, and Patrick Rubin-Delanchy. Statistical exploration of the manifold hypothesis. arXiv preprint arXiv:2208.11665, 2022
-
[71]
Revisiting deep archetypal analysis for phenotype discovery in high content imaging
Mario Wieser, Daniel Siegismund, and Stephan Steigele. Revisiting deep archetypal analysis for phenotype discovery in high content imaging. InProceedings of the Winter Conference on Applications of Computer Vision, pages 3802–3811, 2025
2025
-
[72]
White-box transformers via sparse rate reduction.Advances in Neural Information Processing Systems, 36:9422–9457, 2023
Yaodong Yu, Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Benjamin Haeffele, and Yi Ma. White-box transformers via sparse rate reduction.Advances in Neural Information Processing Systems, 36:9422–9457, 2023. A Supplementary material to section 3 Proof of Proposition 1 Proof.The statement follows from direct computation. To see this, firs...
2023
-
[73]
Applies a fixed squeeze transform with factor 2 (halving height and width, quadrupling channels)
-
[74]
Applies a learned image transformT ℓ
-
[75]
flow steps
Splits the channels in half, passing one half to the next level and storing the other for the inverse pass. The dimensions are chosen so that the first level sees4channels of size16×16, and for eachℓ= 2, . . . , L, Cℓ = 2Cℓ−1, H ℓ =H ℓ−1/2, W ℓ =W ℓ−1/2, i.e., spatial dimensions shrink by a factor of 2 while the number of channels doubles at every level. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.