Inference Time Context Sparsity: Illusion or Opportunity?
Pith reviewed 2026-06-30 15:55 UTC · model grok-4.3
The pith
LLMs remain accurate when most context tokens are ignored during inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
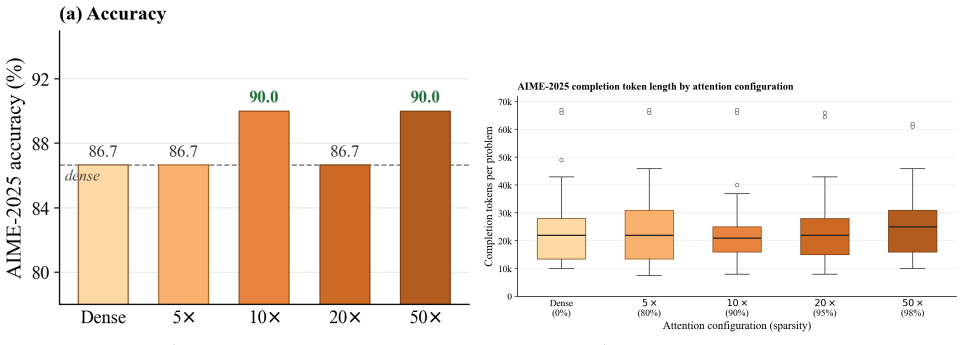
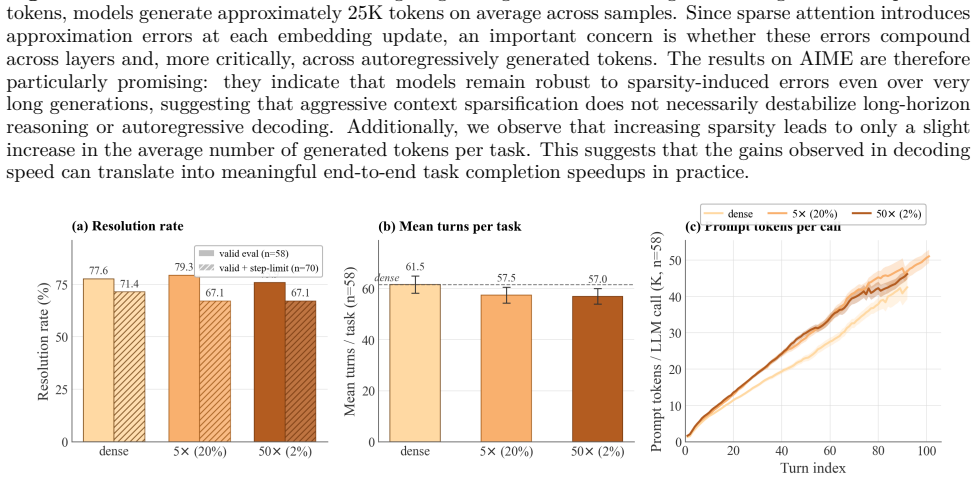
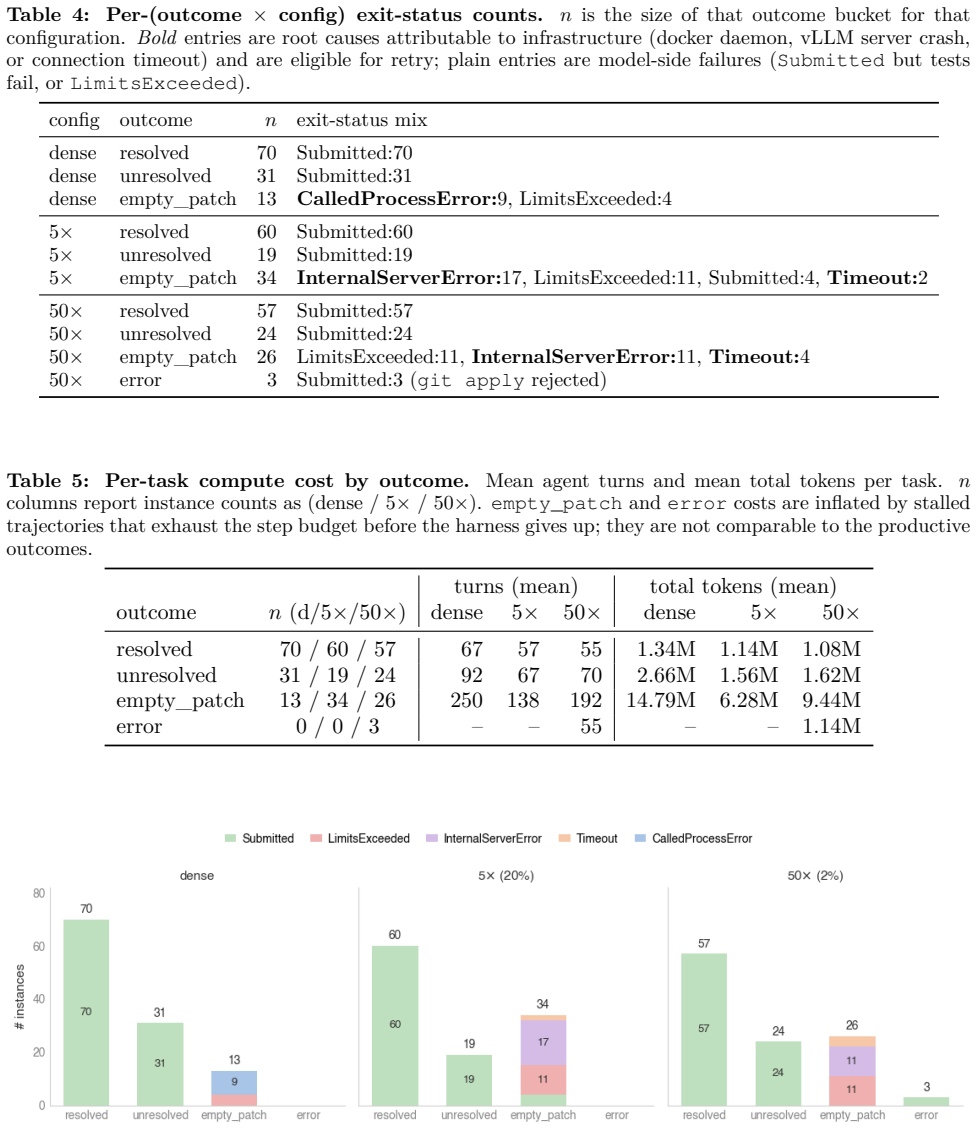
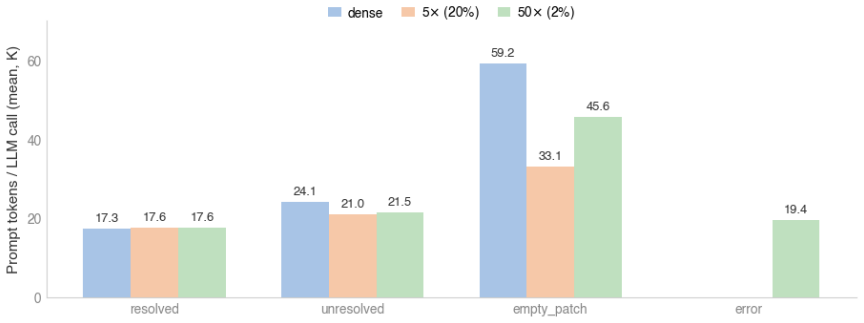
Current LLMs are remarkably robust to inference-time decode sparsity across tasks of varying complexity, including retrieval, multi-hop QA, mathematical reasoning, and agentic coding. This robustness exists even though the models were never trained for sparsity, and the process of projecting a long context into a much smaller hidden dimension already makes dense attention inherently lossy. Combined with the fact that sparse kernels on existing hardware such as the H100 deliver up to 10x acceleration at 50x sparsity, the results position extreme context sparsity as a feasible and beneficial foundation for LLM inference.
What carries the argument
Inference-time decode sparsity: the selective use of only a small fraction of context tokens when computing attention during decoding.
If this is right
- Hardware such as the H100 can already deliver up to 10x speedups over dense kernels at 50x sparsity using sparse decode implementations.
- No retraining or model modification is required to obtain the robustness and efficiency gains.
- The same sparsity approach works across retrieval, multi-hop QA, mathematical reasoning, and agentic coding tasks.
- Context sparsity can serve as a starting point for redesigning inference systems, training procedures, and model architectures.
Where Pith is reading between the lines
- Training objectives that explicitly encourage context sparsity could produce models that tolerate even higher sparsity ratios.
- New attention mechanisms could be designed from the start to operate only on sparse context subsets rather than approximating dense attention.
- Similar sparsity opportunities may exist in other layers or components beyond the attention mechanism.
Load-bearing premise
The observed robustness to sparsity will continue to hold for arbitrary models, tasks, context lengths, and sparsity ratios without retraining or architectural changes.
What would settle it
Performance on retrieval or reasoning tasks drops sharply for a new model family once sparsity exceeds 20x on contexts longer than those tested.
Figures
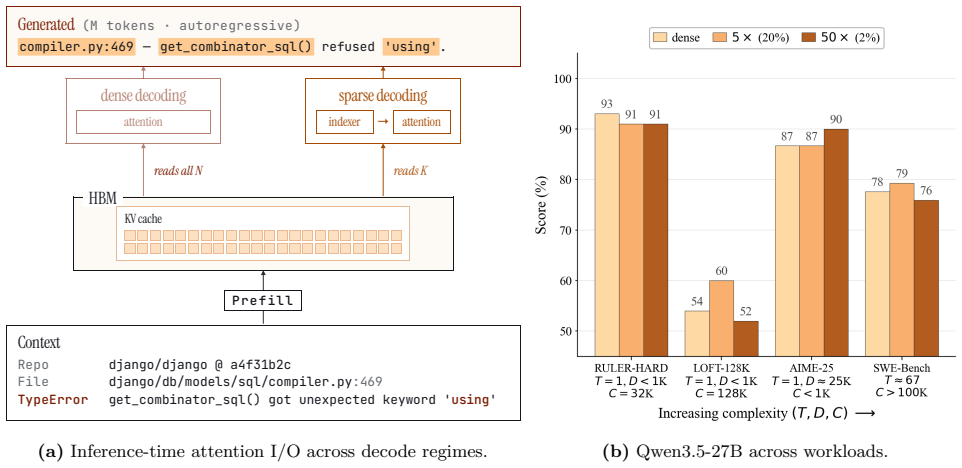
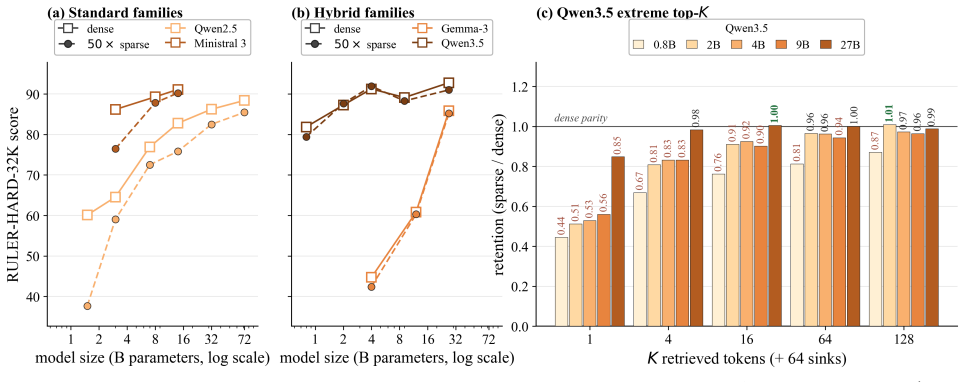
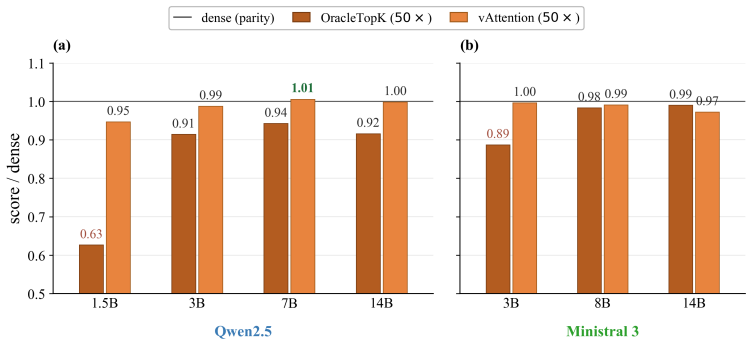
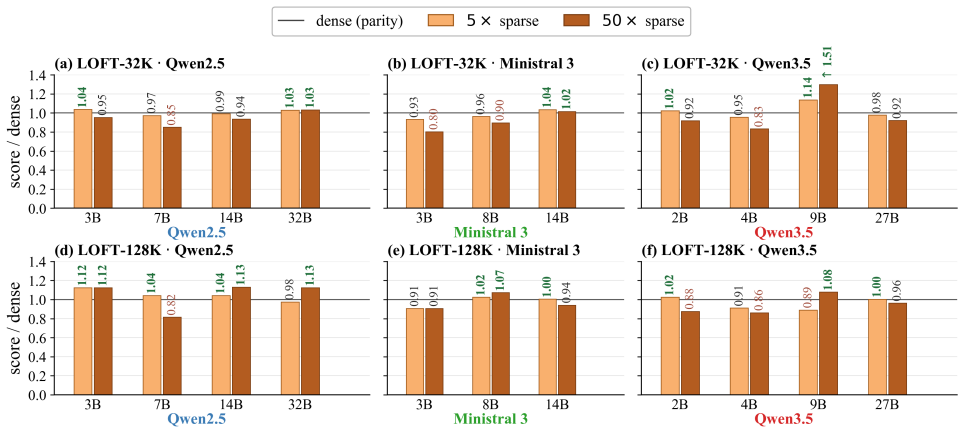
read the original abstract
Sparsity has long been a central theme in LLM efficiency, but its role in context processing remains unresolved. As LLM workloads shift toward longer contexts and agentic interactions, the compute and memory bottlenecks of attention become increasingly critical, raising the question of whether these constraints are fundamental. Our position is that these constraints are artificial and unnecessary, and that the future of LLM inference lies in extreme but principled sparsity along the context dimension. This position is supported by several strands of empirical and theoretical evidence. First, we find the insistence on dense attention unreasonable, since in a long context a query effectively projects O(N) attention information into a hidden space of dimension d << N, making the process inherently lossy. Second, we perform an extensive study of sparsity in LLMs spanning 20 models across five model families, varying context lengths, and different sparsity levels. We empirically demonstrate a strong trend: current LLMs, despite not being trained for context sparsity, are remarkably robust to inference-time decode sparsity across tasks of varying complexity, including retrieval, multi-hop QA, mathematical reasoning, and agentic coding. Importantly, we also show that current hardware is already sufficient to realize substantial gains from this sparsity. For example, our sparse decode kernels accelerate large-context processing by up to 10x over FlashInfer at 50x sparsity levels on hardware such as the H100. Overall, these results position extreme context sparsity not as a heuristic, but as a principled foundation for LLM inference, training, and architecture design: one that is both feasible and beneficial, and a compelling direction for future systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that dense attention during LLM inference is an artificial constraint rather than a fundamental requirement. It advances a theoretical claim that a query projects O(N) context information into a d-dimensional hidden space (d << N), rendering dense attention inherently lossy, and supports this with an empirical study across 20 models from five families. The study reports that current LLMs remain robust to inference-time decode sparsity on retrieval, multi-hop QA, mathematical reasoning, and agentic coding tasks, with sparse kernels delivering up to 10x speedup over FlashInfer at 50x sparsity on H100 hardware. The position is that extreme context sparsity should become a foundational principle for future inference, training, and architecture design.
Significance. If the reported robustness generalizes, the work would have substantial practical significance for scaling long-context and agentic LLM workloads by reducing attention compute and memory without retraining. The breadth of the multi-family empirical evaluation and the concrete hardware kernel results are strengths that could influence systems research. The theoretical dimensionality argument provides an intuitive motivation but does not itself predict downstream task accuracy under token dropping.
major comments (2)
- [Abstract] Abstract: the central empirical claim of 'remarkable robustness' across arbitrary context lengths, sparsity ratios, model families, and task distributions rests on extrapolation from a finite study; the dimensionality argument explains potential lossiness but supplies no bound on when task performance will degrade, leaving the generalization assumption load-bearing and untested.
- [Abstract] Abstract: the statement that 'current hardware is already sufficient' and the 10x speedup claim over FlashInfer at 50x sparsity require explicit reporting of the sparsity pattern selection method, prompt formatting controls, and statistical significance across the 20 models to rule out confounds in the experimental setup.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the exact sparsity ratios, context lengths, and task metrics used in the 'extensive study' to allow readers to assess the scope of the robustness claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our empirical claims and the need for clearer experimental details. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of 'remarkable robustness' across arbitrary context lengths, sparsity ratios, model families, and task distributions rests on extrapolation from a finite study; the dimensionality argument explains potential lossiness but supplies no bound on when task performance will degrade, leaving the generalization assumption load-bearing and untested.
Authors: We agree that the study is finite and does not furnish a theoretical bound on degradation points. The dimensionality argument is offered only as intuition for why dense attention may be lossy, not as a predictive guarantee. Our central claim is the observed empirical trend of robustness across the tested regimes (20 models, 5 families, varied lengths/ratios/tasks). In revision we will add an explicit limitations paragraph qualifying that generalization beyond the studied distributions remains an open question and is not proven by the current results. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'current hardware is already sufficient' and the 10x speedup claim over FlashInfer at 50x sparsity require explicit reporting of the sparsity pattern selection method, prompt formatting controls, and statistical significance across the 20 models to rule out confounds in the experimental setup.
Authors: We will revise the abstract and methods section to state explicitly: (1) sparsity pattern is top-k selection on per-query attention scores, (2) prompt formatting follows the standard templates released with each benchmark, and (3) all reported speedups and accuracy numbers are means with standard deviation across the 20 models, with the same trend holding in every family. These details already appear in the full experimental appendix; we will surface them in the main text and abstract for clarity. revision: yes
Circularity Check
No circularity: claims rest on empirical study and qualitative dimensionality argument
full rationale
The paper supports its position via an extensive empirical evaluation on 20 models across tasks and a qualitative argument that attention is lossy because a query projects O(N) information into dimension d << N. Neither element reduces to a self-definition, fitted parameter renamed as prediction, or self-citation chain. The robustness observation is reported as measured data, not derived from quantities defined in terms of the target result. No equations or ansatzes are smuggled via prior self-work in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A query token projects O(N) context information into a hidden space of dimension d << N, rendering dense attention inherently lossy
- domain assumption Robustness to inference-time sparsity does not require any model retraining or architectural change
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 Tech- nical Report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b Model Card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, 2023
2023
-
[4]
Separations in the representational capabilities of transformers and recurrent architectures
Satwik Bhattamishra, Michael Hahn, Phil Blunsom, and Varun Kanade. Separations in the representational capabilities of transformers and recurrent architectures. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[5]
SLIDE : In Defense of Smart Algorithms over Hardware Acceleration for Large-Scale Deep Learning Systems
Beidi Chen, Tharun Medini, James Farwell, Charlie Tai, Anshumali Shrivastava, et al. SLIDE : In Defense of Smart Algorithms over Hardware Acceleration for Large-Scale Deep Learning Systems. Proceedings of Machine Learning and Systems, 2:291–306, 2020
2020
-
[6]
MagicPIG: LSH Sampling for Efficient LLM Generation
Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuan- dong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, and Beidi Chen. MagicPIG: LSH Sampling for Efficient LLM Generation. InThe Thirteenth International Conference on Learning Repre- sentations, 2025
2025
-
[7]
Rethinking Attention with Per- formers
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J Colwell, and Adrian Weller. Rethinking Attention with Per- formers. InInternational Conference on Learning Representations, 2021
2021
-
[8]
Gonzalez, and Ion Stoica
Aditya Desai, Kumar Krishna Agrawal, Shuo Yang, Alejandro Cuadron, Luis Gaspar Schroeder, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. vAttention: Verified Sparse Attention via Sampling. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[9]
Gonzalez, and Ion Stoica
Aditya Desai, Shuo Yang, Alejandro Cuadron, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. HashAttention: Semantic Sparsity for Faster Inference. InForty-second International Conference on Machine Learning, 2025
2025
-
[10]
Switch Transformers: Scaling to Trillion Param- eter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 23(120):1– 39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch Transformers: Scaling to Trillion Param- eter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 23(120):1– 39, 2022
2022
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. InFirst Conference on Language Modeling, 2024
2024
-
[13]
REALM: Retrieval-Augmented Language Model Pre-Training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval-Augmented Language Model Pre-Training. InInternational Conference on Machine Learning (ICML), 2020. 11
2020
-
[14]
Squeezed Attention: Accelerating Long Context Length LLM Inference
Coleman Richard Charles Hooper, Sehoon Kim, Hiva Mohammadzadeh, Monishwaran Mah- eswaran, Sebastian Zhao, June Paik, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. Squeezed Attention: Accelerating Long Context Length LLM Inference. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[15]
Large Language Models for Software Engineering: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology, 33:1–79, 2024
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology, 33:1–79, 2024
2024
-
[16]
RULER: What’s the real context size of your long-context language models? In First Conference on Language Modeling, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? In First Conference on Language Modeling, 2024
2024
-
[17]
Leveraging Passage Retrieval with Generative Models for OpenDomainQuestionAnswering
Gautier Izacard and Edouard Grave. Leveraging Passage Retrieval with Generative Models for OpenDomainQuestionAnswering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, 2021
2021
-
[18]
ATLAS: Few-Shot Learning with Retrieval Augmented Language Models.The Journal of Machine Learning Research, 24(1), 2023
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. ATLAS: Few-Shot Learning with Retrieval Augmented Language Models.The Journal of Machine Learning Research, 24(1), 2023
2023
-
[19]
SWE-bench: Can Language Models Resolve Real-world Github Issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can Language Models Resolve Real-world Github Issues? InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[20]
SOCKET: SOft Collision Kernel EsTimator for Sparse Attention
Sahil Joshi, Agniva Chowdhury, Wyatt Bellinger, Amar Kanakamedala, Ekam Singh, Hoang Anh Duy Le, Aditya Desai, and Anshumali Shrivastava. SOCKET: SOft Collison Kernel EsTimator for Sparse Attention.arXiv preprint arXiv:2602.06283, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
RACE Attention: A Strictly Linear-Time Attention Layer for Training on Outra- geouslyLargeContexts
Sahil Joshi, Agniva Chowdhury, Amar Kanakamedala, Ekam Singh, Evan Tu, and Anshumali Shrivastava. RACE Attention: A Strictly Linear-Time Attention Layer for Training on Outra- geouslyLargeContexts. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[22]
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. InInternational Conference on Machine Learning, 2020
2020
-
[23]
Mamba-3: Improved Sequence Modeling using State Space Principles
Aakash Lahoti, Kevin Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Al- bert Gu. Mamba-3: Improved Sequence Modeling using State Space Principles. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[24]
FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, and Xun Zhou. FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[25]
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, Sébastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, and Kelvin Guu. Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and...
-
[26]
Competition-Level Code Generation with AlphaCode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-Level Code Generation with AlphaCode.Science, 378(6624):1092–1097, 2022. 12
2022
-
[27]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chen- gruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, and Lili Qiu. RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[31]
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time.Advances in Neural Information Processing Systems, 36, 2024
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[32]
Deja vu: Contextual sparsity for efficient llms at inference time
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. InInternational Conference on Machine Learning, pages 22137–22176. PMLR, 2023
2023
-
[33]
American Invitational Mathematics Examination (AIME) 2025.https://maa.org/maa-invitational-competitions/, 2025
Mathematical Association of America. American Invitational Mathematics Examination (AIME) 2025.https://maa.org/maa-invitational-competitions/, 2025. Accessed: 2026-05- 20
2025
-
[34]
Random Feature Attention
Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah Smith, and Lingpeng Kong. Random Feature Attention. InInternational Conference on Learning Representations, 2021
2021
-
[35]
Measuring and Narrowing the Compositionality Gap in Language Models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. Measuring and Narrowing the Compositionality Gap in Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023, 2023
2023
-
[36]
Code Llama: Open Foundation Models for Code
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code Llama: Open Foundation Models for Code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Survey: Transformer based Video-Language Pre-Training.AI Open, 3:1–13, 2022
Ludan Ruan and Qin Jin. Survey: Transformer based Video-Language Pre-Training.AI Open, 3:1–13, 2022
2022
-
[38]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[39]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, *Azalia Mirhoseini, *Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. InInternational Conference on Learning Representations, 2017. 13
2017
-
[40]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. OpenAI GPT-5 System Card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
OpenClaw: Personal AI Assistant.https: //github.com/openclaw/openclaw, 2026
Peter Steinberger and OpenClaw contributors. OpenClaw: Personal AI Assistant.https: //github.com/openclaw/openclaw, 2026
2026
-
[42]
QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference. InInternational Conference on Machine Learning, 2024
2024
-
[43]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
2026
-
[45]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. LLaMA: Open and Efficient Foundation Language Models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
arXiv preprint arXiv:2408.07092 , year=
Shuo Yang, Ying Sheng, Joseph E. Gonzalez, Ion Stoica, and Lianmin Zheng. Post-Training Sparse Attention with Double Sparsity.arXiv preprint arXiv:2408.07092, 2024
-
[49]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh Interna- tional Conference on Learning Representations, 2023
2023
-
[50]
LongMamba: Enhancing Mamba’s Long- Context Capabilities via Training-Free Receptive Field Enlargement
Zhifan Ye, Kejing Xia, Yonggan Fu, Xin Dong, Jihoon Hong, Xiangchi Yuan, Shizhe Diao, Jan Kautz, Pavlo Molchanov, and Yingyan Celine Lin. LongMamba: Enhancing Mamba’s Long- Context Capabilities via Training-Free Receptive Field Enlargement. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[51]
Flashinfer documentation,
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. Flashinfer documentation,
-
[52]
Accessed: 2025-05-27. 14
2025
-
[53]
Benjamin Erichson
Annan Yu and N. Benjamin Erichson. Block-Biased Mamba for Long-Range Sequence Processing. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[54]
Big Bird: Trans- formers for Longer Sequences
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago On- tanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big Bird: Trans- formers for Longer Sequences. InAdvances in Neural Information Processing Systems, 2020
2020
-
[55]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. GLM-5: from Vibe Coding to Agentic Engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
PQCache: Product Quantization-based KVCache for Long Context LLM Inference.Proceedings of the ACM on Management of Data, 3(3):1–30, 2025
Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, and Bin Cui. PQCache: Product Quantization-based KVCache for Long Context LLM Inference.Proceedings of the ACM on Management of Data, 3(3):1–30, 2025
2025
-
[57]
SpargeAttention: Accurate and Training-free Sparse Attention Accelerating Any Model Inference
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. SpargeAttention: Accurate and Training-free Sparse Attention Accelerating Any Model Inference. InForty-second International Conference on Machine Learning, 2025
2025
-
[58]
H2O: Heavy- Hitter Oracle for Efficient Generative Inference of Large Language Models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Re, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy- Hitter Oracle for Efficient Generative Inference of Large Language Models. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[59]
An efficient training algorithm for models with block-wise sparsity.Transactions on Machine Learning Research, 2025
Ding Zhu, Zhiqun Zuo, and Mohammad Mahdi Khalili. An efficient training algorithm for models with block-wise sparsity.Transactions on Machine Learning Research, 2025. 15 Appendix A Proofs A.1 Proof of Theorem 1 Proof.Consider the linear mapT:R N→Rd defined byT(a) :=V ⊤a. SinceV ⊤∈Rd×N, we have rank(T)≤d. LetN(T) :={z∈RN :V ⊤z= 0}be the null space ofT. By ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.