EPPC-OASIS: Ontology-Aware Adaptation and Structured Inference Refinement for Electronic Patient-Provider Communication Mining in Secure Messages
Pith reviewed 2026-06-30 15:51 UTC · model grok-4.3
The pith
Ontology-aware adaptation with structured refinement improves extraction of patient-provider communication codes by 1-2 F1 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
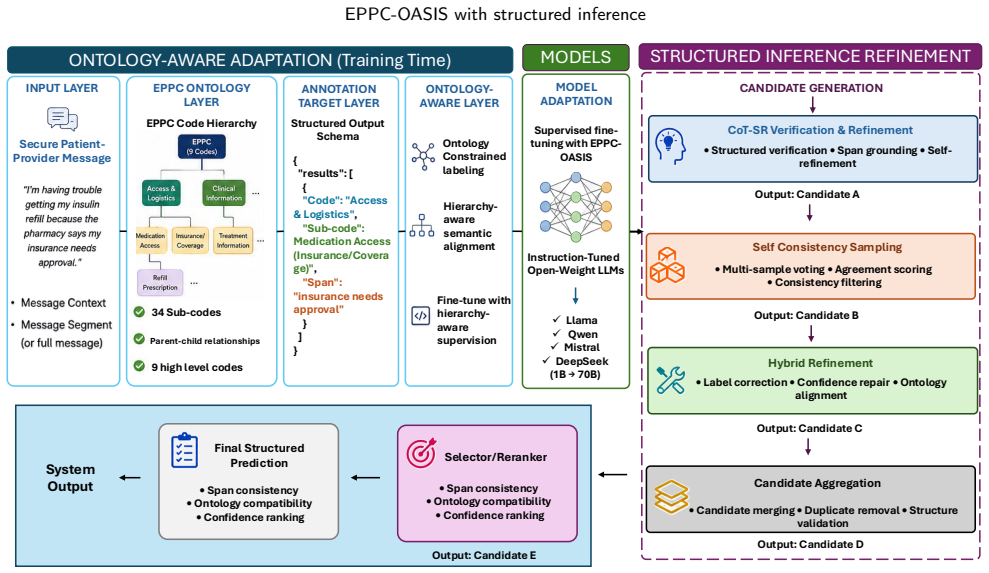
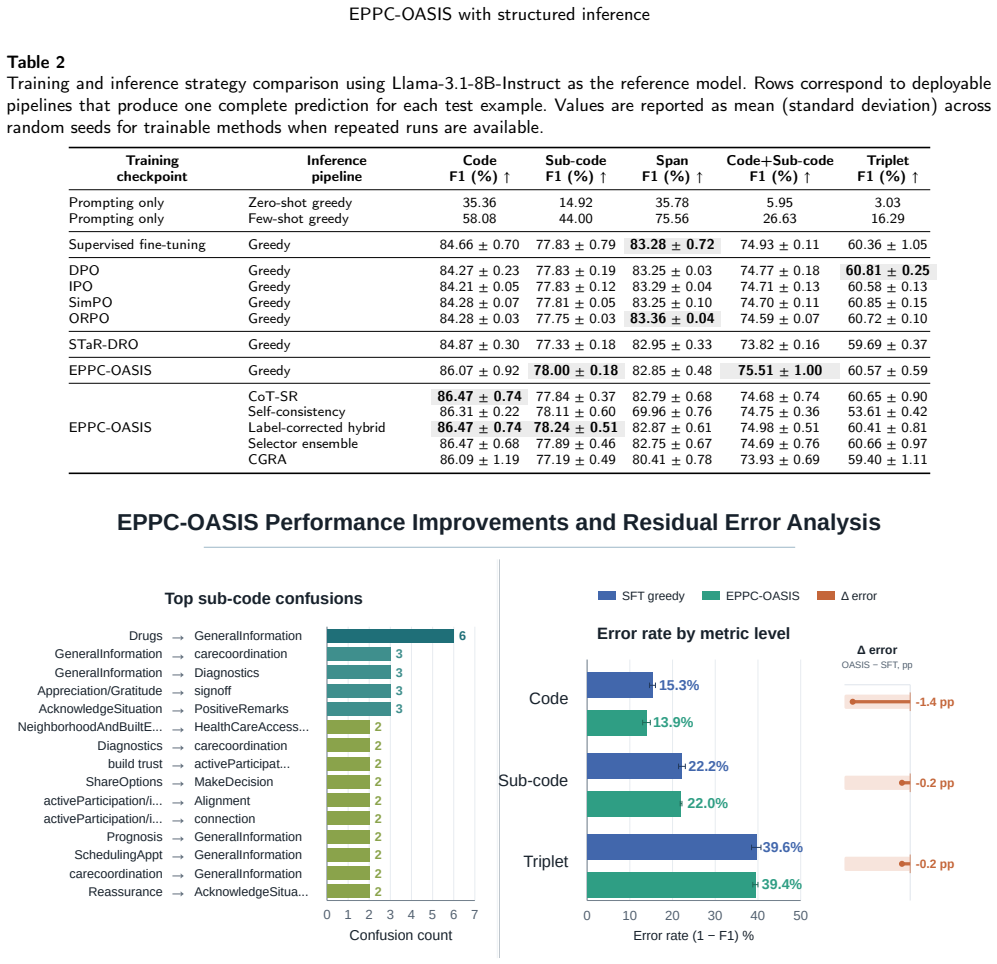
EPPC-OASIS augments supervised fine-tuning with a Wasserstein alignment objective that encourages alignment between model representation neighborhoods and EPPC ontology-derived neighborhoods, while inference refinement uses verification, self-consistency, hybrid correction, and selection or ensembling to address residual prediction errors. On the de-identified corpus the best deployable pipeline achieved 77.13 percent Code+Sub-code F1 and 63.83 percent Triplet F1, corresponding to absolute gains of 1.39 and 2.12 F1 points over the strongest supervised fine-tuning baseline.
What carries the argument
EPPC-OASIS, which combines Wasserstein alignment of representation neighborhoods to EPPC ontology neighborhoods during adaptation with post-hoc verification, self-consistency, and hybrid correction at inference time.
If this is right
- Structured predictions preserve the code and sub-code hierarchy more faithfully than plain fine-tuning.
- The same pipeline can be applied across multiple open-weight language model families without requiring new labeled data.
- Retrospective mining of large archives of secure messages becomes more feasible at scale.
- Residual errors after fine-tuning can be reduced by the listed inference procedures without retraining.
Where Pith is reading between the lines
- If the alignment mechanism proves robust, analogous neighborhood-matching objectives could be tested on other medical ontologies that also require hierarchical label structures.
- The modest absolute gains suggest the method may be most useful when combined with larger base models or additional unlabeled message data.
- Operational deployment would still require separate checks on live, non-de-identified streams to confirm the gains persist outside the study corpus.
Load-bearing premise
The performance gains are produced by the ontology alignment and inference-refinement steps rather than by unexamined differences in training procedure or data handling, and the de-identified corpus is representative of the messages on which the system would be deployed.
What would settle it
Re-training the same models with the Wasserstein alignment term removed or on a fresh held-out message set and checking whether the reported F1 margins over the supervised baseline disappear.
Figures
read the original abstract
Secure patient-provider messages contain clinically important communication behaviors that are difficult to characterize manually at scale. The Electronic Patient-Provider Communication (EPPC) framework provides an ontology for coding these behaviors, but automated extraction remains challenging because predictions must preserve fine-grained code/sub-code structure while grounding annotations in message text. We developed EPPC-OASIS, an ontology-aware adaptation approach for structured EPPC extraction, and combined it with deployable inference-refinement procedures designed to improve the coherence of final annotations. EPPC-OASIS augments supervised fine-tuning with a Wasserstein alignment objective that encourages alignment between model representation neighborhoods and EPPC ontology-derived neighborhoods, while inference refinement uses verification, self-consistency, hybrid correction, and selection or ensembling to address residual prediction errors. We evaluated the framework on a de-identified corpus of secure patient-provider messages against prompting, supervised fine-tuning, preference-based, and robustness-oriented baselines across multiple open-weight language models. Across model families, the best deployable pipeline achieved 77.13% Code+Sub-code F1 and 63.83% Triplet F1, corresponding to modest but consistent absolute gains of +1.39 and +2.12 F1 points over the strongest supervised fine-tuning baseline. These results suggest that ontology-aware adaptation with structured inference refinement can support scalable retrospective EPPC mining, although external validation is needed before operational use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EPPC-OASIS, an ontology-aware adaptation method that augments supervised fine-tuning (SFT) with a Wasserstein alignment objective to encourage alignment between model representation neighborhoods and EPPC ontology-derived neighborhoods. It combines this with deployable inference-refinement procedures (verification, self-consistency, hybrid correction, and selection/ensembling) for structured extraction of EPPC codes, sub-codes, and triplets from secure patient-provider messages. Evaluated on a de-identified corpus against prompting, SFT, preference-based, and robustness baselines across multiple open-weight LLMs, the best pipeline reports 77.13% Code+Sub-code F1 and 63.83% Triplet F1, with absolute gains of +1.39 and +2.12 over the strongest SFT baseline.
Significance. If the modest gains can be shown to arise specifically from the Wasserstein alignment and inference-refinement components rather than from differences in training procedure or data handling, the framework could support more scalable retrospective mining of clinically relevant communication behaviors under the EPPC ontology. The multi-model-family evaluation and explicit comparison to several baseline categories are positive features, but the small effect sizes and stated need for external validation limit the immediate operational significance.
major comments (2)
- [Evaluation] The evaluation does not report whether the SFT baseline used identical optimizer, learning-rate schedule, epoch count, batch size, or random-seed handling as the EPPC-OASIS runs. Because the central performance claim rests on the +1.39 and +2.12 F1 improvements being caused by the Wasserstein alignment objective plus the verification/self-consistency/hybrid-correction steps, the absence of these controls is load-bearing.
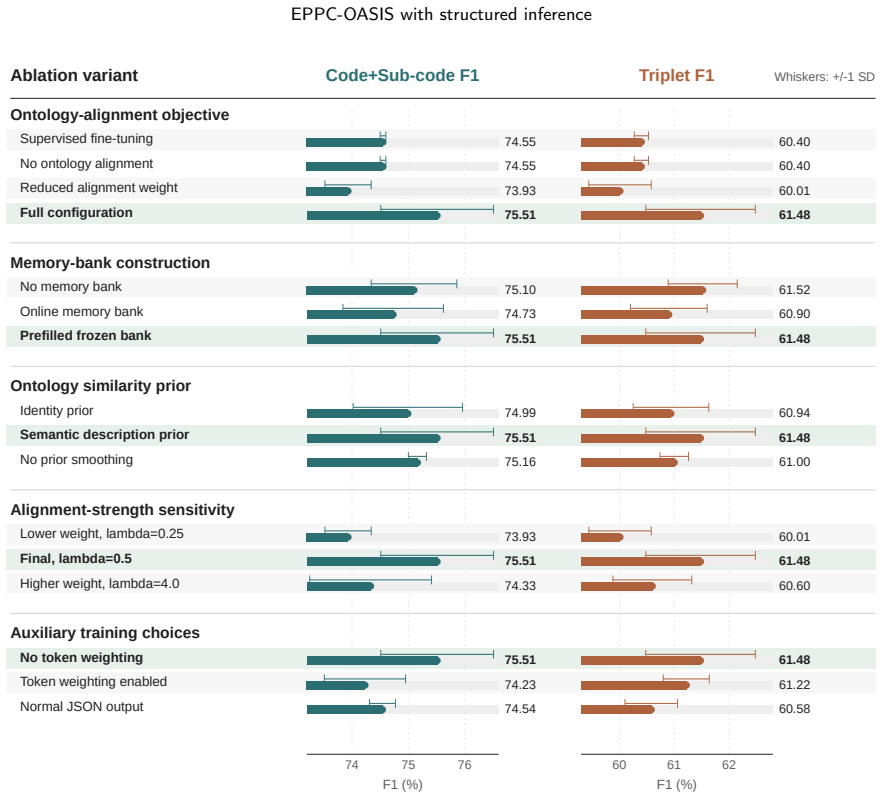
- [Methods] No ablation tables or controlled experiments isolate the contribution of the Wasserstein alignment term from the base SFT objective or from the subsequent inference-refinement procedures. Without such ablations, the attribution of the reported F1 gains to the ontology-aware adaptation cannot be confirmed.
minor comments (2)
- The abstract refers to a 'deployable pipeline' without defining the criteria that distinguish deployable from non-deployable inference-refinement configurations.
- Consider adding a brief error analysis or qualitative examples illustrating the specific error types corrected by the verification and hybrid-correction steps that remain after SFT alone.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for tighter experimental controls to support attribution of the reported gains. We address both major comments below and will revise the manuscript to include the requested details and experiments.
read point-by-point responses
-
Referee: [Evaluation] The evaluation does not report whether the SFT baseline used identical optimizer, learning-rate schedule, epoch count, batch size, or random-seed handling as the EPPC-OASIS runs. Because the central performance claim rests on the +1.39 and +2.12 F1 improvements being caused by the Wasserstein alignment objective plus the verification/self-consistency/hybrid-correction steps, the absence of these controls is load-bearing.
Authors: The SFT baselines were trained with identical settings: AdamW optimizer, linear warmup/decay schedule, 3 epochs, batch size 16, and random seed 42. These choices were made explicitly to isolate the contribution of the Wasserstein term. We will add a new 'Training Configuration' subsection with a comparison table documenting all hyperparameters for both SFT and EPPC-OASIS runs. revision: yes
-
Referee: [Methods] No ablation tables or controlled experiments isolate the contribution of the Wasserstein alignment term from the base SFT objective or from the subsequent inference-refinement procedures. Without such ablations, the attribution of the reported F1 gains to the ontology-aware adaptation cannot be confirmed.
Authors: We agree that dedicated ablations are needed to isolate effects. The revised manuscript will include two new controlled experiments: (i) SFT versus SFT+Wasserstein (no inference refinement) and (ii) SFT versus SFT+inference refinement (no Wasserstein). Results will appear in a new ablation table with statistical significance tests, allowing direct attribution of the +1.39/+2.12 gains. revision: yes
Circularity Check
No significant circularity; empirical comparison is self-contained
full rationale
The paper reports an empirical evaluation of EPPC-OASIS (ontology-aware adaptation via Wasserstein alignment plus inference refinement) against prompting, SFT, preference, and robustness baselines across model families on a de-identified message corpus, with absolute F1 gains presented as experimental outcomes. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described method; the central claims rest on direct metric comparisons rather than any derivation that reduces outputs to inputs by construction. This is the expected non-finding for a standard applied ML paper whose results are externally falsifiable via replication on held-out data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agrawal, M., Hegselmann, S., Lang, H., Kim, Y., Sontag, D.,
-
[2]
1998–2022
Large language models are few-shot clinical informa- tion extractors, in: Proceedings of the 2022 Conference on Em- pirical Methods in Natural Language Processing, pp. 1998–2022. URL:https://aclanthology.org/2022.emnlp-main.130/,doi:10.18653/ v1/2022.emnlp-main.130
2022
-
[3]
A keyword-enhanced approach to handle class imbalance in clinical text classification
Blanchard, A.E., Gao, S., Yoon, H.J., Christian, J.B., Durbin, E.B., Wu, X.C., Stroup, A., Doherty, J., Schwartz, S.M., Wiggins, C., Coyle, L., Penberthy, L., Tourassi, G.D., 2022. A keyword-enhanced approach to handle class imbalance in clinical text classification. IEEE Journal of Biomedical and Health Informatics 26, 2796–2803. URL:https://doi.org/10.1...
-
[4]
Cronin, R.M., Davis, S.E., Shenson, J.A., Chen, Q., Rosenbloom, S.T., Jackson, G.P., 2015. Growth of secure messaging through a Fodeh et al.:Preprint submitted to ElsevierPage 14 of 19 EPPC-OASIS with structured inference patient portal as a form of outpatient interaction across clinical spe- cialties. AppliedClinicalInformatics6,288–304. URL:https://doi....
-
[5]
Sinkhorn distances: Lightspeed computation of optimal transport, in: Advances in Neural Information Processing Systems
Cuturi, M., 2013. Sinkhorn distances: Lightspeed computation of optimal transport, in: Advances in Neural Information Processing Systems. URL:https://papers.nips.cc/paper/ 4927-sinkhorn-distances-lightspeed-computation-of-optimal-transport
2013
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI,Guo,D.,Yang,D.,Zhang,H.,Song,J.,Wang,P.,Zhu, Q., Xu, R., Zhang, R., Ma, S., et al., 2025. DeepSeek-R1: Incentiviz- ing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948 URL:https://arxiv.org/abs/2501.12948, doi:10.48550/arXiv.2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[7]
8-bit optimizers via block-wise quantization, in: International Conference on Learning Representations
Dettmers, T., Lewis, M., Shleifer, S., Zettlemoyer, L., 2022. 8-bit optimizers via block-wise quantization, in: International Conference on Learning Representations. URL:https://openreview.net/forum? id=shpkpVXzo3h
2022
-
[8]
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.,
-
[9]
URL: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1feb87871436031bdc0f2beaa62a049b-Abstract.html
QLoRA: Efficient finetuning of quantized LLMs, in: Advances in Neural Information Processing Systems. URL: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1feb87871436031bdc0f2beaa62a049b-Abstract.html
2023
-
[10]
DeYoung, J., Jain, S., Rajani, N.F., Lehman, E., Xiong, C., Socher, R., Wallace, B.C., 2020. ERASER: A benchmark to evaluate ratio- nalized NLP models, in: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4443–4458. URL:https://doi.org/10.18653/v1/2020.acl-main.408,doi:10.18653/ v1/2020.acl-main.408
-
[11]
POT:Pythonoptimaltransport
Flamary, R., Courty, N., Gramfort, A., Alaya, M.Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., Gautheron, L., Gayraud, N.T.H., Janati, H., Rakotomamonjy, A., Redko,I.,Rolet,A.,Schutz,A.,Seguy,V.,Sutherland,D.J.,Tavenard, R.,Tong,A.,Vayer,T.,2021. POT:Pythonoptimaltransport. Journal ofMachineLearningResearch22,1–8. URL...
2021
-
[12]
Fodeh,S.,Ma,L.,Puthiaraju,G.,Talakokkul,S.,Khan,A.,Hagaman, A., Lowe, S., Roundtree, A., 2026a. PVminerLLM: Structured extraction of patient voice from patient-generated text using large language models. arXiv preprint arXiv:2603.05776 URL:https: //arxiv.org/abs/2603.05776, doi:10.48550/arXiv.2603.05776
-
[13]
Fodeh,S.,Ma,L.,Puthiaraju,G.,Talakokkul,S.,Khan,A.,Hagaman, A., Lowe, S.R., Roundtree, A.K., 2026b. TAB-PO: Preference optimization with a token-level adaptive barrier for token-critical structuredgeneration. arXivpreprintarXiv:2603.00025URL:https: //arxiv.org/abs/2603.00025, doi:10.48550/arXiv.2603.00025
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.00025
-
[14]
Fodeh,S.,Ma,L.,Wang,Y.,Talakokkul,S.,Puthiaraju,G.,Khan,A., Hagaman, A., Lowe, S., Roundtree, A., 2026c. PVminer: A domain- specifictooltodetectthepatientvoiceinpatientgenerateddata.arXiv preprint arXiv:2602.21165 URL:https://arxiv.org/abs/2602.21165, doi:10.48550/arXiv.2602.21165
-
[15]
STaR-DRO: Stateful Tsallis Reweighting for Group-Robust Structured Prediction
Fodeh,S.,Puthiaraju,G.,Irankhah,E.,Ma,L.,Talakokkul,S.,Khan, A., Ramachandran, S., Alpert, J., Schellhorn, S., 2026d. STaR-DRO: Stateful tsallis reweighting for group-robust structured prediction. arXiv preprint arXiv:2604.09737 URL:https://arxiv.org/abs/2604. 09737, doi:10.48550/arXiv.2604.09737
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09737
-
[16]
Fodeh, S.J., Wang, Y., Ma, L., Talakokkul, S., Alpert, J.M., Schell- horn, S., 2026e. EPPCMinerBen: A novel benchmark for evaluating large language models on electronic patient-provider communica- tion via the patient portal. Artificial Intelligence in Medicine , 103429URL:https://doi.org/10.1016/j.artmed.2026.103429,doi:10. 1016/j.artmed.2026.103429
-
[17]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al- Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al., 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783 URL:https://arxiv.org/abs/2407.21783, doi:10. 48550/arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Henning, S., Beluch, W., Fraser, A., Friedrich, A., 2023. A survey of methods for addressing class imbalance in deep-learning based natu- rallanguageprocessing,in:Proceedingsofthe17thConferenceofthe European Chapter of the Association for Computational Linguistics, pp.523–540. URL:https://doi.org/10.18653/v1/2023.eacl-main.38, doi:10.18653/v1/2023.eacl-main.38
-
[19]
LoRA: Low-rank adaptation of large language models, in: International Conference on Learning Representations
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., 2022. LoRA: Low-rank adaptation of large language models, in: International Conference on Learning Representations. URL:https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[20]
Characterizing patient-clinician communication in secure medical messages: Retrospective study
Huang, M., Fan, J., Prigge, J., Shah, N.D., Costello, B.A., Yao, L., 2022. Characterizing patient-clinician communication in secure medical messages: Retrospective study. Journal of Medical Internet Research 24, e17273. URL:https://doi.org/10.2196/17273, doi:10. 2196/17273
-
[21]
Kwon,W.,Li,Z.,Zhuang,S.,Sheng,Y.,Zheng,L.,Yu,C.H.,Gonza- lez, J.E., Zhang, H., Stoica, I., 2023. Efficient memory management for large language model serving with PagedAttention, in: Proceed- ings of the 29th ACM Symposium on Operating Systems Principles, pp. 611–626. URL:https://dblp.org/rec/conf/sosp/KwonLZ0ZY0ZS23, doi:10.1145/3600006.3613165
-
[22]
Self-refine: Iterative refinement with self-feedback, in: Advances in Neural Information Processing Systems
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., Gupta, S., Majumder, B.P., Hermann, K., Welleck, S., Yazdanbakhsh, A., Clark, P., 2023. Self-refine: Iterative refinement with self-feedback, in: Advances in Neural Information Processing Systems. URL: https://proceedings.neurips.cc/pape...
2023
-
[23]
https://github.com/huggingface/peft
Mangrulkar, S., Gugger, S., Debut, L., Belkada, Y., Paul, S., 2022.PEFT:State-of-the-artparameter-efficientfine-tuningmethods. https://github.com/huggingface/peft. Accessed 2026-05-12
2022
-
[24]
Meng, Y., Xia, M., Chen, D., 2024. SimPO: Simple preference optimization with a reference-free reward, in: Advances in Neural Information Processing Systems. URL: https://proceedings.neurips.cc/paper_files/paper/2024/hash/ e099c1c9699814af0be873a175361713-Abstract-Conference.html, doi:10.52202/079017-3946
-
[25]
Llama 3.2 1b and 3b instruct model cards.https: //huggingface.co/meta-llama
Meta AI, 2024a. Llama 3.2 1b and 3b instruct model cards.https: //huggingface.co/meta-llama. Accessed 2026-05-12
2026
-
[26]
Llama 3.3 70B Instruct model card.https:// huggingface.co/meta-llama/Llama-3.3-70B-Instruct
Meta AI, 2024b. Llama 3.3 70B Instruct model card.https:// huggingface.co/meta-llama/Llama-3.3-70B-Instruct. Accessed2026- 05-12
-
[27]
Mistral-Small-24B-Instruct-2501 model card.https://huggingface.co/mistralai/ Mistral-Small-24B-Instruct-2501
Mistral AI, 2025. Mistral-Small-24B-Instruct-2501 model card.https://huggingface.co/mistralai/ Mistral-Small-24B-Instruct-2501. Accessed 2026-05-12
2025
-
[28]
North,F., Luhman,K.E.,Mallmann, E.A.,Mallmann,T.J., Tulledge- Scheitel, S.M., North, E.J., Pecina, J.L., 2020. A retrospective analysis of provider-to-patient secure messages: How much are they increasing, who is doing the work, and is the work happening after hours? JMIRMedicalInformatics8,e16521. URL:https://doi.org/ 10.2196/16521, doi:10.2196/16521
-
[29]
PyTorch: An imperative style, high-performance deep learning library, in: Advances in Neural Information Processing Systems
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S., 2019. PyTorch: An imperative style, high-performance deep learning library, in: Advances in Neural In...
2019
-
[30]
Direct preference optimization: Your language model is secretly a reward model, in: Advances in Neural Information Processing Systems
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., Finn, C., 2023. Direct preference optimization: Your language model is secretly a reward model, in: Advances in Neural Information Processing Systems. URL: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html
2023
-
[31]
Multi-label classification: An overview
Tsoumakas, G., Katakis, I., 2007. Multi-label classification: An overview. International Journal of Data Warehousing and Mining 3, 1–13. URL:https://doi.org/10.4018/jdwm.2007070101, doi:10.4018/ jdwm.2007070101. Fodeh et al.:Preprint submitted to ElsevierPage 15 of 19 EPPC-OASIS with structured inference
-
[32]
U, S.C.L., He, J., Basulto, V.G., Pan, J.Z., 2023. Instances and labels: Hierarchy-aware joint supervised contrastive learning for hi- erarchical multi-label text classification, in: Findings of the Associ- ation for Computational Linguistics: EMNLP 2023, pp. 8858–8875. URL:https://doi.org/10.18653/v1/2023.findings-emnlp.594,doi:10. 18653/v1/2023.findings...
-
[33]
Unsloth: Fast language model fine-tuning.https: //github.com/unslothai/unsloth
Unsloth AI, 2024. Unsloth: Fast language model fine-tuning.https: //github.com/unslothai/unsloth. Accessed 2026-05-21
2024
-
[34]
Self-consistency improves chain of thought reasoning in language models, in: International Conference on Learning Representations
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D., 2023. Self-consistency improves chain of thought reasoning in language models, in: International Conference on Learning Representations. URL:https://openreview.net/forum? id=1PL1NIMMrw
2023
-
[35]
Wang, Z., Wang, P., Liu, T., Lin, B., Cao, Y., Sui, Z., Wang, H.,
-
[36]
HPT: Hierarchy-aware prompt tuning for hierarchical text classification, in: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 3740–3751. URL: https://doi.org/10.18653/v1/2022.emnlp-main.246, doi:10.18653/v1/ 2022.emnlp-main.246
-
[37]
Chain-of-thought prompting elicits reasoning in large language models, in: Advances in Neural Information Processing Systems
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D., 2022. Chain-of-thought prompting elicits reasoning in large language models, in: Advances in Neural Information Processing Systems. URL: https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 9d5609613524ecf4f15af0f7b31abca4-Abstract.html
2022
-
[38]
Generating sequences by learning to self-correct
Welleck, S., Lu, X., West, P., Brahman, F., Shen, T., Khashabi, D., Choi, Y., 2022. Generating sequences by learning to self-correct. arXiv preprint arXiv:2211.00053 URL:https://arxiv.org/abs/2211. 00053, doi:10.48550/arXiv.2211.00053
-
[39]
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Le Scao, T., Gugger, S., Drame, M., Lhoest, Q., Rush, A.M., 2020. Hugging- Face’s transformers: State-of-the-art natural language processing, in: Proceedings of...
2020
-
[40]
Xu, L., Teng, S., Zhao, R., Guo, J., Xiao, C., Jiang, D., Ren, B.,
-
[41]
Hierarchical multi-label text classification with horizontal and vertical category correlations, in: Proceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, pp. 2459–2468. URL:https://doi.org/10.18653/v1/2021.emnlp-main. 190, doi:10.18653/v1/2021.emnlp-main.190
-
[42]
Yang,A.,Yang,B.,Zhang,B.,Hui,B.,Zheng,B.,Yu,B.,Li,C.,Liu, D., Huang, F., Wei, H., et al., 2025. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 URL:https://arxiv.org/abs/2412.15115, doi:10.48550/arXiv.2412.15115. Fodeh et al.:Preprint submitted to ElsevierPage 16 of 19 EPPC-OASIS with structured inference A. Appendix: Inference Details A.1. Pars...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.