LLMs Show No Signs Of Individuated Metacognition
Pith reviewed 2026-06-30 15:18 UTC · model grok-4.3
The pith
LLMs show no individuated metacognition in confidence judgments across benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
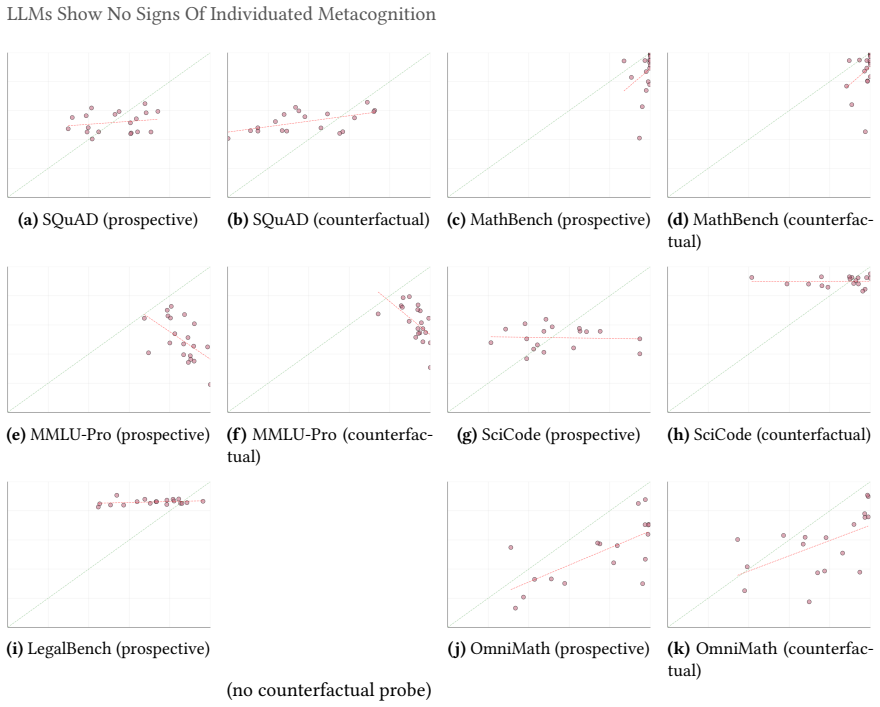
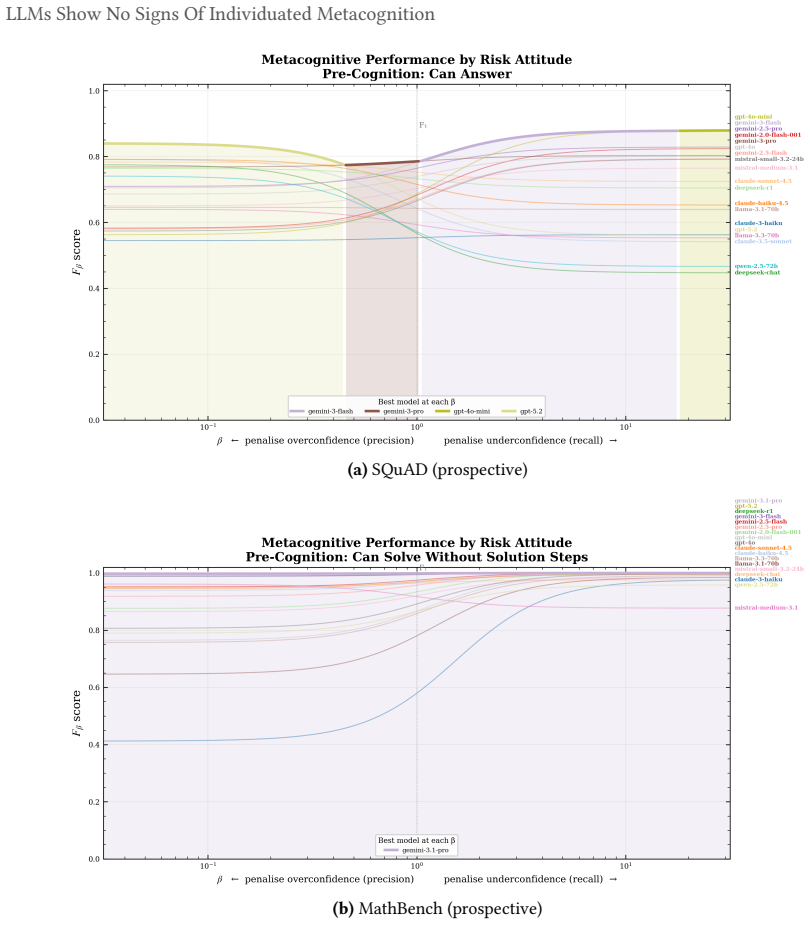
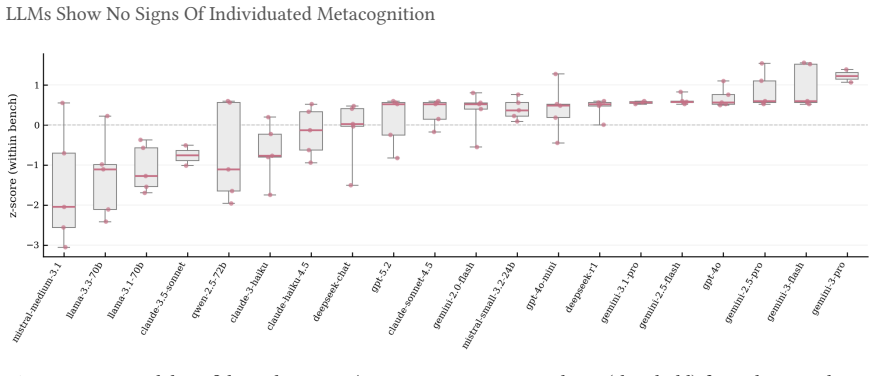
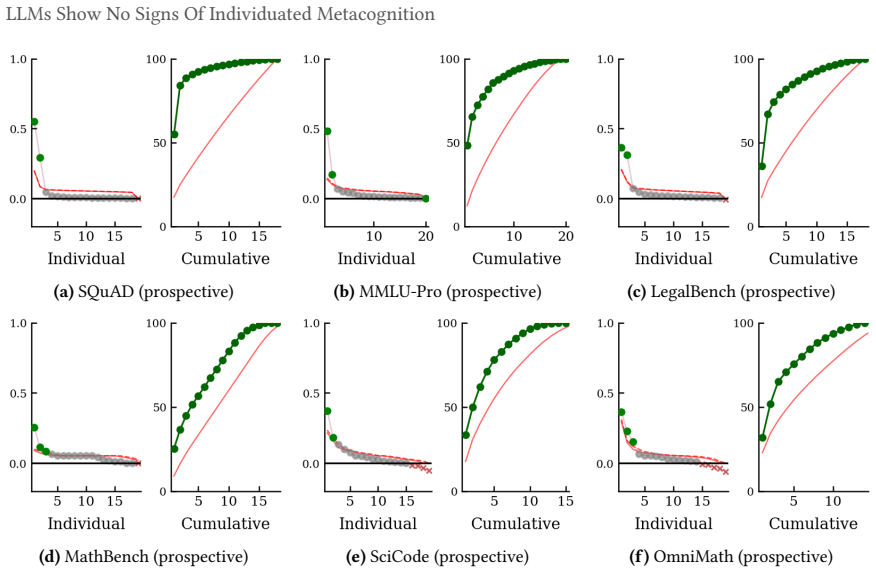
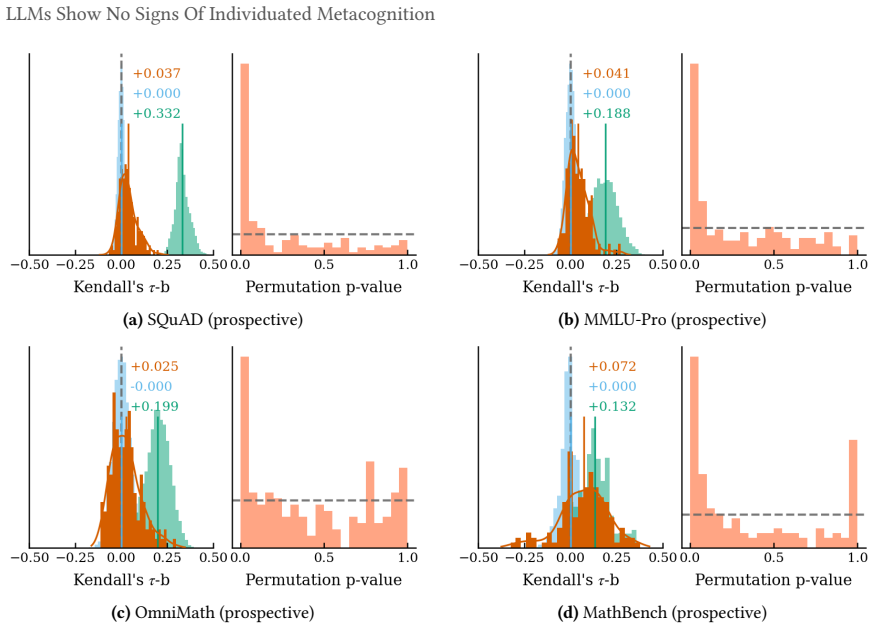
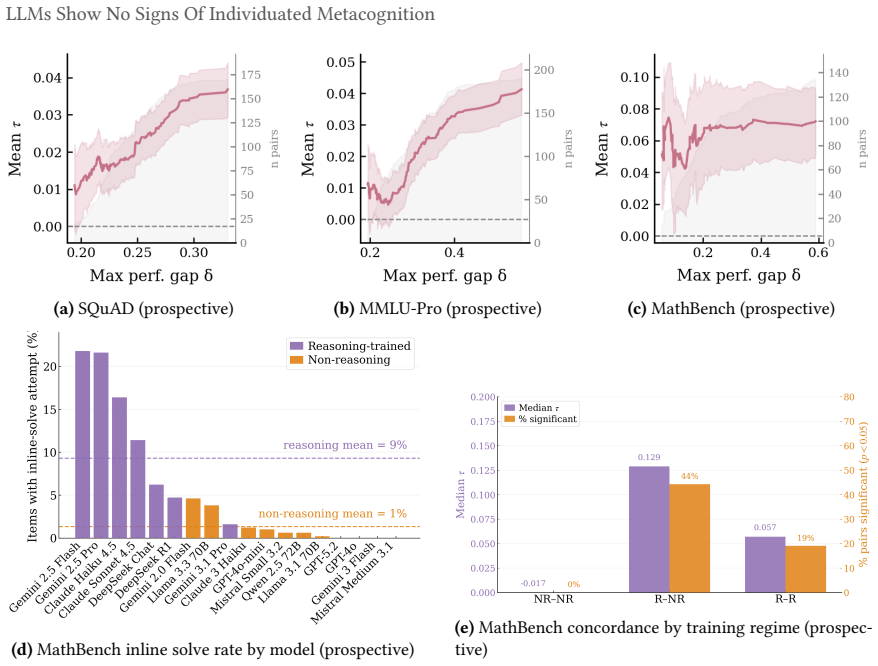
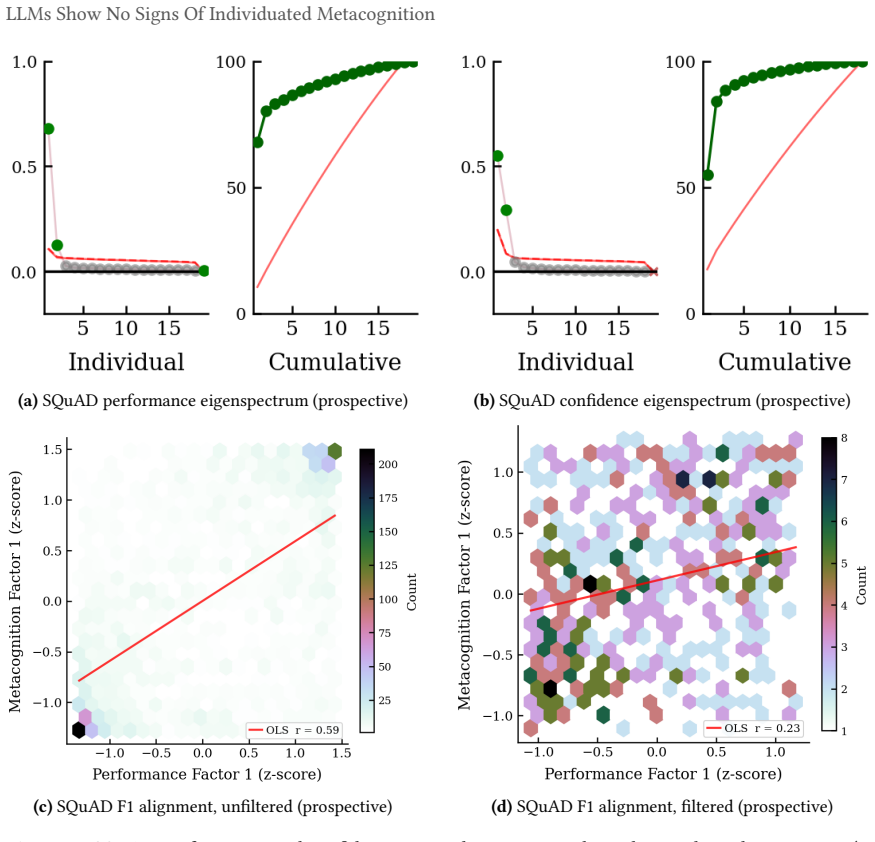
The cross-model confidence matrix is approximately rank-one on factual recall and information retrieval benchmarks, with a single dominant factor capturing most of the latent variance. Models retrieving facts share an item-level difficulty axis and differ mainly in their decision thresholds along it. Across all benchmarks the relationship between confidence and performance collapses once items that all models agree on are removed. Inter-model pairwise calibration is small even where statistically significant, and what remains shrinks to nothing once base-rate differences along the shared factor are controlled for. Mathematical reasoning is the apparent exception, but this turns out to be a c
What carries the argument
Tetrachoric factor analysis on binary confidence judgments paired with pairwise calibration after removal of agreed items.
If this is right
- Confidence-weighted routing in ensembles would not gain from using stated confidence as a signal of capability.
- Selective abstention based on model confidence would not reliably improve task performance.
- Ensemble weighting schemes that rely on confidence scores would see little benefit from that information.
- Mathematical reasoning benchmarks do not measure metacognition when models are allowed to solve the problem in chain of thought.
Where Pith is reading between the lines
- Current LLM confidence may largely reflect properties of the training distribution rather than any model-specific self-assessment.
- Tests of metacognition that avoid verbal reports or chain-of-thought solving would be needed to look for the capacity in other ways.
- High-stakes applications that assume models can accurately flag their own limits may need alternative safeguards if the finding holds.
- The same analysis could be repeated on open-ended generation tasks to check whether the rank-one structure generalizes beyond multiple-choice formats.
Load-bearing premise
That tetrachoric factor analysis on binary confidence judgments combined with removal of agreed items isolates the presence or absence of individuated metacognition rather than base-rate differences or prompt effects.
What would settle it
A set of models in which confidence differences on items where they disagree still predict performance differences after the shared factor and base rates are controlled for.
Figures
read the original abstract
Confidence-weighted routing, selective abstention, and ensemble weighting all assume that a model's stated confidence is informative about its capability on the question being asked. They presume functional metacognition, the capacity to assess one's own capabilities, without exercising them. Aggregate calibration is well studied, with mixed results, but the underlying structure of elicited confidence is less well understood. We decompose binary confidence judgements from 20 frontier Large Language Models (LLMs) across six benchmarks using tetrachoric factor analysis paired with pairwise calibration, asking whether two models that differ in confidence also differ in performance. On factual recall and information retrieval benchmarks the cross-model confidence matrix is approximately rank-one and a single dominant factor captures most of the latent variance. Models retrieving facts share an item-level difficulty axis and differ mainly in their decision thresholds along it. Across all benchmarks the relationship between confidence and performance collapses once items that all models agree on are removed. Inter-model pairwise calibration is small even where statistically significant, and what remains shrinks to nothing once base-rate differences along the shared factor are controlled for. Mathematical reasoning is the apparent exception, but this turns out to be a confound where reasoning models answer questions about their confidence by trying to solve them in their chain of thought, bypassing the sub-symbolic self-knowledge we seek to measure. We find no evidence for significant verbalised individuated metacognition in any tested domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes binary confidence judgments from 20 frontier LLMs across six benchmarks using tetrachoric factor analysis paired with pairwise calibration. It reports that the cross-model confidence matrix is approximately rank-one on factual recall and information retrieval benchmarks (a single dominant factor captures most latent variance), that models differ mainly in decision thresholds along a shared item-difficulty axis, and that the confidence-performance relationship collapses once items on which all models agree are removed. Inter-model pairwise calibration is small and vanishes after controlling for base-rate differences along the shared factor. Mathematical reasoning is treated as a confound arising from chain-of-thought solving. The authors conclude there is no evidence for significant verbalised individuated metacognition in any tested domain.
Significance. If the result holds after full methodological disclosure and explicit controls for confounds, the finding would be significant for LLM evaluation and for downstream applications (confidence-weighted routing, selective abstention, ensemble weighting) that presuppose informative model self-assessment.
major comments (2)
- [Abstract] Abstract: the statistical approach is described only at high level and supplies no details on the exact benchmarks, the list of 20 models, data exclusion criteria, or error controls. This prevents verification that the reported rank-one structure and post-removal collapse support the central claim.
- [Abstract] Abstract: the interpretation that the observed rank-one structure plus vanishing pairwise calibration after agreed-item removal demonstrates absence of individuated metacognition assumes binary judgments primarily reflect either a common difficulty axis or model-specific self-assessment. It is not shown how the tetrachoric model and base-rate controls rule out alternative sources (prompt phrasing, response-format biases, or model-specific guessing thresholds uncorrelated with the shared factor).
minor comments (1)
- The abstract would be clearer if it named the six benchmarks and briefly indicated how the mathematical-reasoning confound was diagnosed.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below. Where the comments identify opportunities for greater clarity, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statistical approach is described only at high level and supplies no details on the exact benchmarks, the list of 20 models, data exclusion criteria, or error controls. This prevents verification that the reported rank-one structure and post-removal collapse support the central claim.
Authors: We agree that the abstract is high-level by design. The full manuscript (Section 3 and Appendix A) specifies the six benchmarks (MMLU, TriviaQA, Natural Questions, HotpotQA, GSM8K, MATH), the exact list of 20 models, the exclusion rule (items on which any model produced no valid binary confidence judgment), and the use of bootstrap resampling (1,000 iterations) for standard errors on factor loadings and tetrachoric correlations. We will expand the abstract to include a concise statement of the benchmarks, model count, and error-control method so that the rank-one claim and post-removal result can be evaluated from the abstract alone. revision: yes
-
Referee: [Abstract] Abstract: the interpretation that the observed rank-one structure plus vanishing pairwise calibration after agreed-item removal demonstrates absence of individuated metacognition assumes binary judgments primarily reflect either a common difficulty axis or model-specific self-assessment. It is not shown how the tetrachoric model and base-rate controls rule out alternative sources (prompt phrasing, response-format biases, or model-specific guessing thresholds uncorrelated with the shared factor).
Authors: The tetrachoric factor model decomposes the observed binary correlations into latent continuous variables; an approximately rank-one solution means that residual covariance after extracting the dominant factor is negligible. Any model-specific guessing threshold or response-format bias uncorrelated with the shared difficulty factor would therefore appear either as a second significant eigenvalue or as non-zero residual pairwise calibration after the base-rate (shared-factor) control is applied. Neither is observed. Because all models received identical prompts, prompt-phrasing effects are absorbed into the common factor rather than generating model-specific residuals. We will add a short paragraph in the Discussion section that makes this logic explicit and notes the assumption that prompt effects are not model-idiosyncratic. revision: partial
Circularity Check
No circularity: empirical decomposition relies on standard factor analysis and external benchmarks
full rationale
The paper applies tetrachoric factor analysis to binary confidence judgments from 20 LLMs on six benchmarks, observes a rank-one structure in the cross-model matrix, and reports that confidence-performance correlations collapse after removing unanimous items and controlling for base rates. These steps use established statistical techniques on external data rather than self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The conclusion of absent individuated metacognition follows directly from the observed empirical patterns without reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Aggarwal, A. Madaan, A. Anand, S. P. Potharaju, S. Mishra, P. Zhou, A. Gupta, D. Rajagopal, K. Kappaganthu, Y. Yang, S. Upadhyay, M. Faruqui, and Mausam. AutoMix : Automatically mixing language models. In Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024. arXiv:2310.12963
-
[2]
The Claude 3 model family: Opus , Sonnet , Haiku
Anthropic. The Claude 3 model family: Opus , Sonnet , Haiku . Anthropic Technical Report, 2024
2024
-
[3]
F. J. Binder, J. Chua, T. Korbak, H. Sleight, J. Hughes, R. Long, E. Perez, M. Turpin, and O. Evans. Looking inward: Language models can learn about themselves by introspection. In Proceedings of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[4]
R. Burnell, H. Hao, A. R. A. Conway, and J. Hern \'a ndez-Orallo. Revealing the structure of language model capabilities. arXiv preprint arXiv:2306.10062, 2023
-
[5]
L. Chen, M. Zaharia, and J. Zou. F rugal GPT : How to use large language models while reducing cost and improving performance. Transactions on Machine Learning Research, 2024
2024
-
[6]
Damani, I
M. Damani, I. Puri, S. Slocum, I. Shenfeld, L. Choshen, Y. Kim, and J. Andreas. Beyond binary rewards: Training LMs to reason about their uncertainty. 2025
2025
-
[7]
DeepSeek-AI . DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 645 0 (8081): 0 633--638, 2025. doi:10.1038/s41586-025-09422-z
-
[8]
S. M. Fleming and H. C. Lau. How to measure metacognition. Frontiers in Human Neuroscience, 8: 0 443, 2014. doi:10.3389/fnhum.2014.00443
-
[9]
B. Gao, F. Song, Z. Yang, Z. Cai, Y. Miao, Q. Dong, L. Li, C. Ma, L. Chen, R. Xu, Z. Tang, B. Wang, D. Zan, S. Quan, G. Zhang, L. Sha, Y. Zhang, X. Ren, T. Liu, and B. Chang. Omni-MATH : A universal olympiad level mathematic benchmark for large language models. In Proceedings of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[10]
Geifman and R
Y. Geifman and R. El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Google . Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
N. Guha, J. Nyarko, D. E. Ho, C. R\' e , A. Chilton, A. Narayana, A. Chohlas-Wood, A. Peters, B. Waldon, D. N. Rockmore, D. Zambrano, D. Talisman, E. Hoque, F. Surani, F. Fagan, G. Sarfaty, G. M. Dickinson, H. Porat, J. Hegland, J. Wu, J. Nudell, J. Niklaus, J. Nay, J. H. Choi, K. Tobia, M. Hagan, M. Ma, M. Livermore, N. Rasumov-Rahe, N. Holzenberger, N. ...
2023
-
[13]
C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), pages 1321--1330, 2017
2017
-
[14]
Hendrycks, C
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Advances in Neural Information Processing Systems 34 (NeurIPS Datasets and Benchmarks Track), 2021
2021
-
[15]
D. Ili\' c and G. E. Gignac. Evidence of interrelated cognitive-like capabilities in large language models: Indications of artificial general intelligence or achievement? Intelligence, 106: 0 101858, 2024. doi:10.1016/j.intell.2024.101858
-
[16]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed. Mistral 7 B . arXiv preprint arXiv:2310.06825, 2023 a
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Jiang, X
D. Jiang, X. Ren, and B. Y. Lin. LLM -blender: Ensembling large language models with pairwise ranking and generative fusion. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), pages 14165--14178, 2023 b
2023
-
[18]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. DasSarma, E. Tran-Johnson, S. Johnston, S. El-Showk, A. Jones, N. Elhage, T. Hume, A. Chen, Y. Bai, S. Bowman, S. Fort, D. Ganguli, D. Hernandez, J. Jacobson, J. Kernion, S. Kravec, L. Lovitt, K. Ndousse, C. Olsson, S. Ringer, D. Amodei, T. Brown, J. Cl...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
A. Kamath, R. Jia, and P. Liang. Selective question answering under domain shift. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5684--5696, 2020. doi:10.18653/v1/2020.acl-main.503
-
[20]
M. G. Kendall. The treatment of ties in ranking problems. Biometrika, 33 0 (3): 0 239--251, 1945. doi:10.2307/2332303
-
[21]
Kipnis, K
A. Kipnis, K. Voudouris, L. M. Schulze Buschoff, and E. Schulz. metabench: A sparse benchmark of reasoning and knowledge in large language models. In Proceedings of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[22]
A. Koriat. Monitoring one's own knowledge during study: A cue-utilization approach to judgments of learning. Journal of Experimental Psychology: General, 126 0 (4): 0 349--370, 1997. doi:10.1037/0096-3445.126.4.349
-
[23]
J. Kruger and D. Dunning. Unskilled and unaware of it: How difficulties in recognizing one's own incompetence lead to inflated self-assessments. Journal of Personality and Social Psychology, 77 0 (6): 0 1121--1134, 1999. doi:10.1037/0022-3514.77.6.1121
-
[24]
L. Kuhn, Y. Gal, and S. Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In Proceedings of the 11th International Conference on Learning Representations (ICLR), 2023
2023
-
[25]
S. Lin, J. Hilton, and O. Evans. Teaching models to express their uncertainty in words. Transactions on Machine Learning Research, 2022
2022
-
[26]
The Llama 3 herd of models, 2024
Llama Team, Meta AI . The Llama 3 herd of models, 2024. Lead author: Aaron Grattafiori
2024
-
[27]
B. Maniscalco and H. Lau. A signal detection theoretic approach for estimating metacognitive sensitivity from confidence ratings. Consciousness and Cognition, 21 0 (1): 0 422--430, 2012. doi:10.1016/j.concog.2011.09.021
-
[28]
T. O. Nelson and L. Narens. Metamemory: A theoretical framework and new findings. In Psychology of Learning and Motivation, volume 26, pages 125--173. Academic Press, 1990. doi:10.1016/S0079-7421(08)60053-5
-
[29]
OpenAI. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
K. Pearson. Mathematical contributions to the theory of evolution. VII . On the correlation of characters not quantitatively measurable. Philosophical Transactions of the Royal Society of London. Series A, 195: 0 1--47, 1900. doi:10.1098/rsta.1900.0022
-
[31]
Pedapati, A
T. Pedapati, A. Dhurandhar, S. Ghosh, S. Dan, and P. Sattigeri. Large language model confidence estimation via black-box access. Transactions on Machine Learning Research (TMLR), 2025
2025
-
[32]
Podolak and R
J. Podolak and R. Verma. Read your own mind: Reasoning helps surface self-confidence signals in LLMs . 2025
2025
-
[33]
Qwen2.5-Coder technical report, 2024
Qwen Team . Qwen2.5-Coder technical report, 2024
2024
-
[34]
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang. SQuAD : 100,000+ questions for machine comprehension of text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2383--2392, 2016. doi:10.18653/v1/D16-1264
-
[35]
Stengel-Eskin, P
E. Stengel-Eskin, P. Hase, and M. Bansal. LACIE : Listener-aware finetuning for confidence calibration in large language models. In Advances in Neural Information Processing Systems 38 (NeurIPS), 2024
2024
-
[36]
K. Tian, E. Mitchell, A. Zhou, A. Sharma, R. Rafailov, H. Yao, C. Finn, and C. D. Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5433--5442, 2023
2023
-
[37]
M. Tian, L. Gao, S. D. Zhang, X. Chen, C. Fan, X. Guo, R. Haas, P. Ji, K. Krongchon, Y. Li, S. Liu, D. Luo, Y. Ma, H. Tong, K. Trinh, C. Tian, Z. Wang, B. Wu, Y. Xiong, S. Yin, M. Zhu, K. Lieret, Y. Lu, G. Liu, Y. Du, T. Tao, O. Press, J. Callan, E. Huerta, and H. Peng. SciCode : A research coding benchmark curated by scientists. In Advances in Neural Inf...
2024
-
[38]
E. Tulving. Memory and consciousness. Canadian Psychology / Psychologie canadienne, 26 0 (1): 0 1--12, 1985. doi:10.1037/h0080017
-
[39]
Ulmer, M
D. Ulmer, M. Gubri, H. Lee, S. Yun, and S. J. Oh. Calibrating large language models using their generations only. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 15440--15459, Bangkok, Thailand, 2024
2024
-
[40]
G. J. G. Upton. Fisher's exact test. Journal of the Royal Statistical Society. Series A (Statistics in Society), 155 0 (3): 0 395--402, 1992. ISSN 09641998, 1467985X
1992
-
[41]
X. Wang, J. Wei, D. Schuurmans, Q. V. Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations (ICLR), 2023
2023
-
[42]
Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. MMLU-Pro : A more robust and challenging multi-task language understanding benchmark. In Advances in Neural Information Processing Systems 37 (NeurIPS Datasets and Benchmarks Track), 2024
2024
-
[43]
Xiong, Z
M. Xiong, Z. Hu, X. Lu, Y. Li, J. Fu, J. He, and B. Hooi. Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs . In Proceedings of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[44]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z. Qiu. Qwen2.5 tec...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Yang, Y.-H
D. Yang, Y.-H. H. Tsai, and M. Yamada. On verbalized confidence scores for LLMs , 2024 b . Poster, ICLR 2025 Workshop QUESTION
2024
-
[46]
D. Yoon, S. Kim, S. Yang, S. Kim, S. Kim, Y. Kim, E. Choi, Y. Kim, and M. Seo. Reasoning models better express their confidence. In Advances in Neural Information Processing Systems 39 (NeurIPS), 2025
2025
-
[47]
X. Zhao, Z. Kang, A. Feng, S. Levine, and D. Song. Learning to reason without external rewards. In Proceedings of the 14th International Conference on Learning Representations (ICLR), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.