SliceWorld: A Predictive and Controllable World-State Model for CT Report Generation
Pith reviewed 2026-06-30 13:53 UTC · model grok-4.3
The pith
SliceWorld encodes prefix CT slices into separable latent states of anatomy, lesion, and uncertainty to support future-slice prediction, factor intervention, and report generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
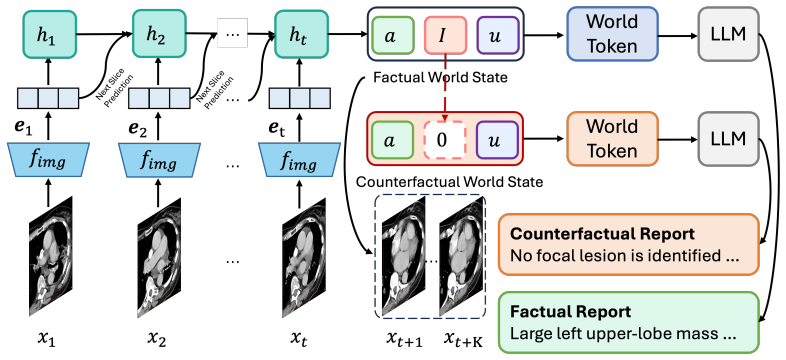
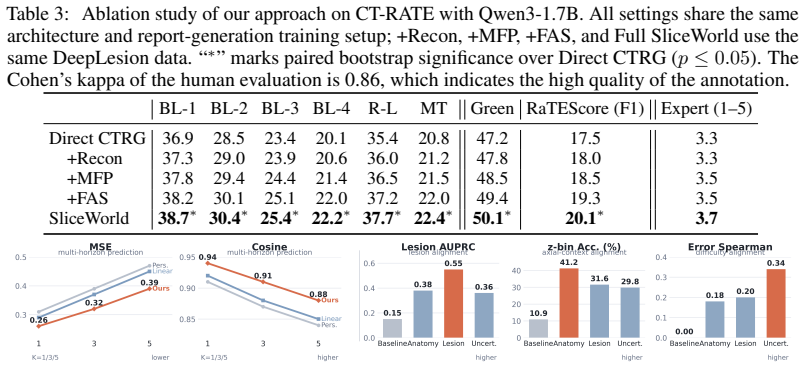
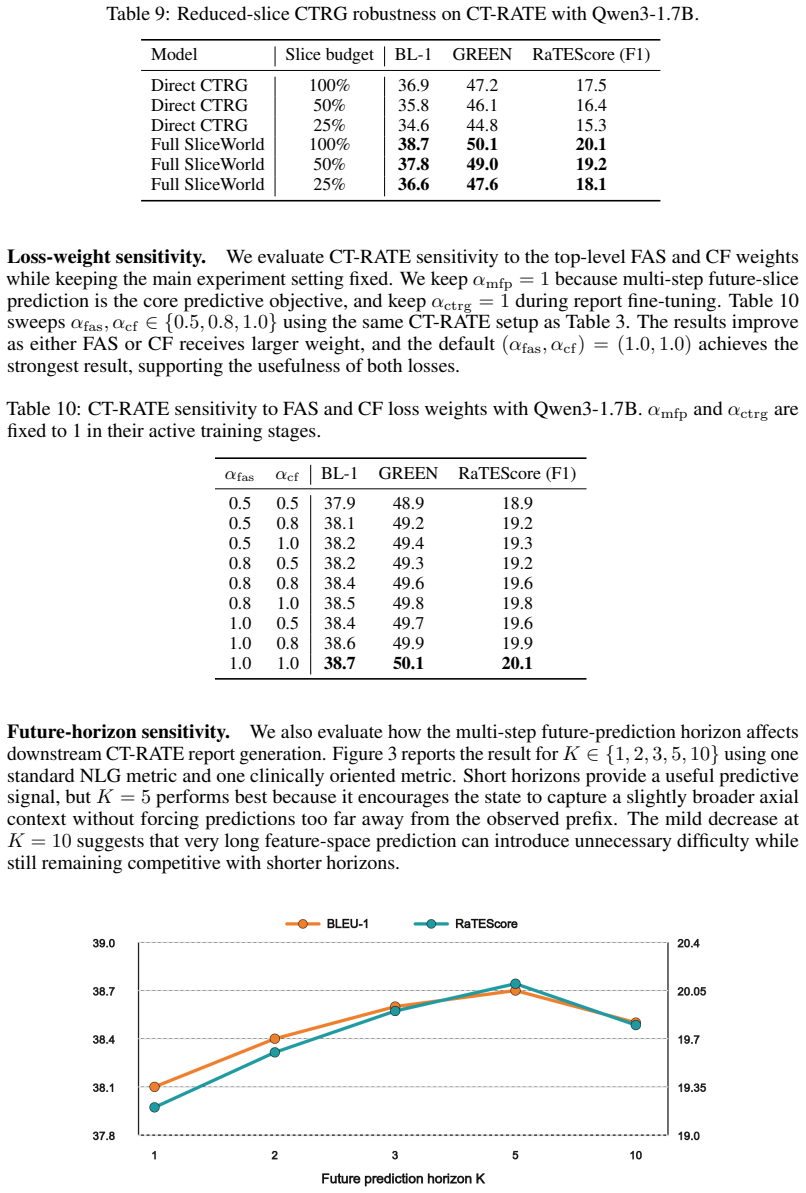
SliceWorld encodes prefix CT evidence into factor-aware latent states containing anatomy, lesion, and uncertainty components, projects these states into world tokens, and uses the tokens for multi-step future-slice feature prediction, lesion-factor intervention, and LLM-based report generation. The model is first pretrained on CT slice sequences with predictive, factor-aware, and counterfactual objectives and then fine-tuned on paired CT-report data, producing improved natural language generation metrics and clinically oriented scores on M3D-Cap and CT-RATE together with measurable multi-horizon prediction, factor alignment, reduced-slice robustness, and selective lesion-sensitive report mod
What carries the argument
Factor-aware latent states (anatomy, lesion, uncertainty components) projected into world tokens that enable prediction, intervention, and generation.
If this is right
- Improved natural language generation metrics and clinically oriented automatic evaluation on M3D-Cap and CT-RATE.
- Multi-horizon future-slice prediction from prefix evidence.
- Measurable alignment between latent factors and clinical variables.
- Maintained report quality when the number of input slices is reduced.
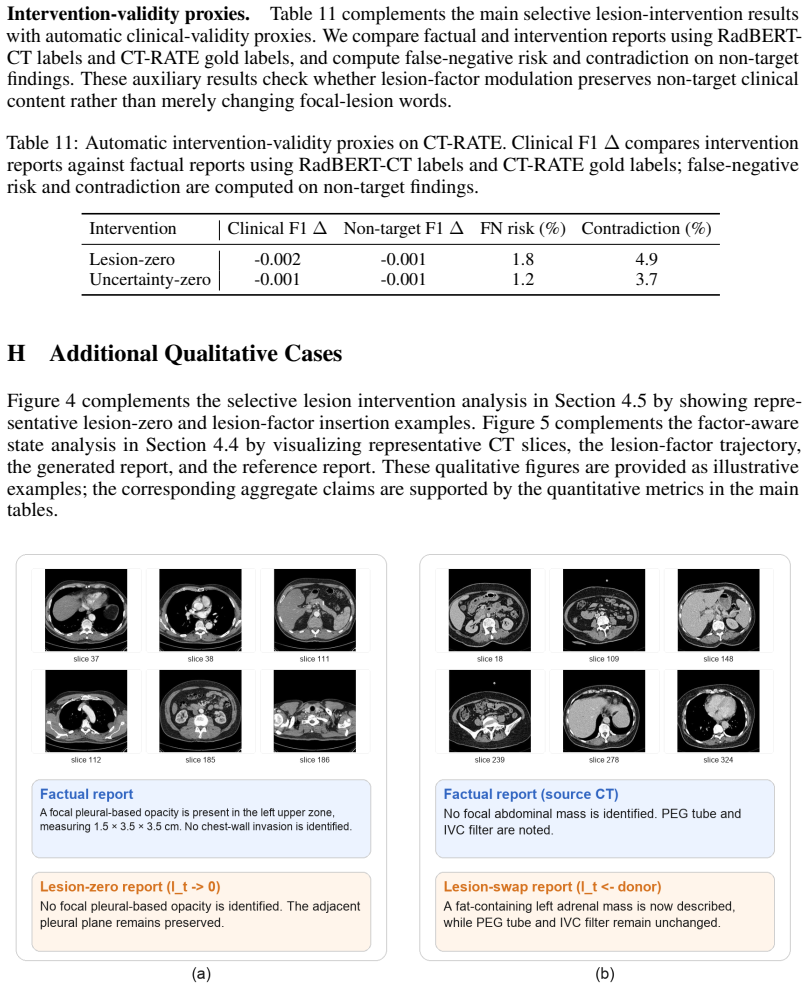
- Selective modulation of reports when lesion-related factors are changed.
Where Pith is reading between the lines
- The same latent-state representation might support 'what-if' queries by radiologists who want to see how a report would change if a lesion were larger or smaller.
- The sequence modeling approach could transfer to other slice-based modalities such as MRI where the ordering axis is spatial rather than temporal.
- Pretraining on unlabeled slice sequences may lower the amount of paired report data needed for acceptable performance.
- If the uncertainty component can be read out separately, it might offer a built-in signal for flagging low-confidence regions in the generated report.
Load-bearing premise
Prefix CT evidence can be encoded into cleanly separable factor-aware latent states whose components do not bleed into each other during projection and use.
What would settle it
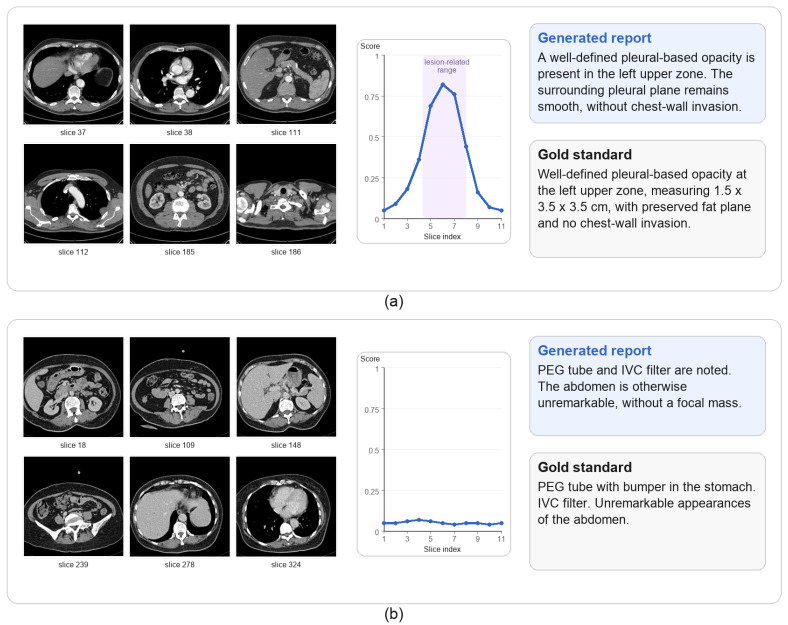
Intervening on the lesion component of the latent state produces no corresponding change in the predicted future-slice features or in the generated report text, as measured by the same clinical metrics used in the paper.
Figures
read the original abstract
CT report generation (CTRG) requires models to summarize three-dimensional anatomical context and pathological findings from hundreds of axial slices. Existing methods typically learn a direct image-to-text mapping, providing limited mechanisms for modeling how CT evidence evolves across slices or how reports respond to controlled changes in latent lesion-related factors. We propose SliceWorld, a CT-specific world-state framework that treats an axial CT scan as an ordered sequence along the z-axis. SliceWorld encodes prefix CT evidence into factor-aware latent states containing anatomy, lesion, and uncertainty components, and projects these states into world tokens used for multi-step future-slice feature prediction, lesion-factor intervention, and LLM-based report generation. The model is first pretrained on CT slice sequences with predictive, factor-aware, and counterfactual objectives, and is then fine-tuned on paired CT-report data. Experiments on M3D-Cap and CT-RATE show that SliceWorld improves natural language generation metrics and clinically oriented automatic evaluation. Further analyses demonstrate multi-horizon future-slice prediction, measurable factor alignment, reduced-slice robustness, and selective lesion-sensitive report modulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SliceWorld, a world-state model for CT report generation (CTRG) that treats axial CT volumes as z-axis sequences. Prefix slices are encoded into factor-aware latent states comprising anatomy, lesion, and uncertainty components; these states are projected to world tokens supporting multi-horizon future-slice prediction, lesion-factor intervention, and LLM-based report generation. The model is pretrained with predictive, factor-aware, and counterfactual objectives before fine-tuning on paired CT-report data. Experiments on M3D-Cap and CT-RATE report gains in NLG metrics and clinical automatic evaluations, plus supporting analyses for multi-horizon prediction, factor alignment, reduced-slice robustness, and selective lesion-sensitive modulation.
Significance. If the claimed factor separability and controllability hold, the work would advance beyond direct image-to-text CTRG by enabling explicit prediction, intervention, and robustness testing in a medical imaging setting. The combination of world-state modeling with LLM report generation and the reported multi-horizon and modulation capabilities would be a substantive contribution to controllable medical report generation.
major comments (2)
- [Abstract] Abstract: The central construction encodes prefix evidence into 'factor-aware latent states containing anatomy, lesion, and uncertainty components' whose projections are asserted to support lesion-factor intervention and selective report modulation. No mechanism (orthogonality penalty, mutual-information term, architectural bottleneck, or explicit loss term) is described that would enforce independence among the three components. This separability is load-bearing for the 'measurable factor alignment' and 'lesion-sensitive report modulation' results; without it, those behaviors could arise from spurious correlations rather than controllable, disentangled states.
- [Abstract] Abstract (pretraining description): The model is 'first pretrained on CT slice sequences with predictive, factor-aware, and counterfactual objectives.' The factor-aware objective is listed but not shown to contain any term that penalizes correlation between anatomy/lesion/uncertainty factors. If the factor-aware loss only supervises individual factors without an independence constraint, the downstream interventional claims rest on an unverified assumption.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for explicit mechanisms supporting factor separability. We address each comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central construction encodes prefix evidence into 'factor-aware latent states containing anatomy, lesion, and uncertainty components' whose projections are asserted to support lesion-factor intervention and selective report modulation. No mechanism (orthogonality penalty, mutual-information term, architectural bottleneck, or explicit loss term) is described that would enforce independence among the three components. This separability is load-bearing for the 'measurable factor alignment' and 'lesion-sensitive report modulation' results; without it, those behaviors could arise from spurious correlations rather than controllable, disentangled states.
Authors: We agree that the current abstract and methods description do not specify an explicit independence constraint. The components are produced by separate projection heads and receive distinct supervision signals under the factor-aware objective, while the counterfactual objective performs targeted interventions on the lesion component. Nevertheless, the absence of a decorrelation term leaves the separability claim open to the interpretation raised. We will revise the manuscript to add an orthogonality penalty to the factor-aware loss, include the updated formulation in the methods, and report an ablation measuring the effect on factor alignment and modulation metrics. revision: yes
-
Referee: [Abstract] Abstract (pretraining description): The model is 'first pretrained on CT slice sequences with predictive, factor-aware, and counterfactual objectives.' The factor-aware objective is listed but not shown to contain any term that penalizes correlation between anatomy/lesion/uncertainty factors. If the factor-aware loss only supervises individual factors without an independence constraint, the downstream interventional claims rest on an unverified assumption.
Authors: The referee correctly notes that the factor-aware objective, as currently described, applies separate supervision to each component without an explicit term that penalizes inter-factor correlation. We will therefore revise the pretraining section to incorporate a correlation penalty (e.g., an orthogonality regularizer) into the factor-aware loss, update the abstract to reflect this change, and add the corresponding experimental results. revision: yes
Circularity Check
No circularity: derivation self-contained against external benchmarks
full rationale
The abstract and description present a pretraining stage using predictive/factor-aware/counterfactual objectives followed by fine-tuning on paired CT-report data, with evaluation on independent datasets (M3D-Cap, CT-RATE). No equations, self-citations, or fitted-parameter renamings are supplied that would reduce any claimed prediction or factor projection to an input by construction. The separability premise is an assumption, not a definitional loop; downstream behaviors are asserted to be measured experimentally rather than forced by the training objective itself. This meets the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18: 368–387, 2024
Phillip Sloan, Philip Clatworthy, Edwin Simpson, and Majid Mirmehdi. Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18: 368–387, 2024
2024
-
[2]
CT2Rep: Automated radiology report generation for 3d medical imaging
Ibrahim Ethem Hamamci, Sezgin Er, and Bjoern Menze. CT2Rep: Automated radiology report generation for 3d medical imaging. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 476–486, 2024
2024
-
[3]
Mvketr: chest ct report generation with multi-view perception and knowledge enhance- ment.IEEE Journal of Biomedical and Health Informatics, 2025
Xiwei Deng, Xianchun He, Jianfeng Bao, Yudan Zhou, Shuhui Cai, Congbo Cai, and Zhong Chen. Mvketr: chest ct report generation with multi-view perception and knowledge enhance- ment.IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[4]
Automatic radiology report generation with deep learning: a comprehensive review of methods and advances.Artificial Intelligence Review, 58(11):344, 2025
Yilin Li, Chao Kong, Guosheng Zhao, and Zijian Zhao. Automatic radiology report generation with deep learning: a comprehensive review of methods and advances.Artificial Intelligence Review, 58(11):344, 2025
2025
-
[5]
A survey of deep-learning-based radiology report generation using multimodal inputs.Medical Image Analysis, 103:103627, 2025
Xinyi Wang, Grazziela Figueredo, Ruizhe Li, Wei Emma Zhang, Weitong Chen, and Xin Chen. A survey of deep-learning-based radiology report generation using multimodal inputs.Medical Image Analysis, 103:103627, 2025
2025
-
[6]
Ct-graph: Hierarchical graph attention network for anatomy-guided ct report generation
Hamza Kalisch, Fabian Hörst, Jens Kleesiek, Ken Herrmann, and Constantin Seibold. Ct-graph: Hierarchical graph attention network for anatomy-guided ct report generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6775–6784, 2025
2025
-
[7]
Large language model with region-guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
Zhixuan Chen, Yequan Bie, Haibo Jin, and Hao Chen. Large language model with region-guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
2025
-
[8]
Yuanhe Tian, Lei Mao, and Yan Song. Recurrent visual feature extraction and stereo attentions for ct report generation.arXiv preprint arXiv:2506.19665, 2025
-
[9]
Feature decomposition via shared low-rank matrix recovery for ct report generation.IEEE Transactions on Medical Imaging, 2025
Yuanhe Tian and Yan Song. Feature decomposition via shared low-rank matrix recovery for ct report generation.IEEE Transactions on Medical Imaging, 2025
2025
-
[10]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Deeplesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning.Journal of medical imaging, 5(3):036501–036501, 2018
Ke Yan, Xiaosong Wang, Le Lu, and Ronald M Summers. Deeplesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning.Journal of medical imaging, 5(3):036501–036501, 2018
2018
-
[13]
Fan Bai, Yuxin Du, Tiejun Huang, Max Q-H Meng, and Bo Zhao. M3D: Advancing 3d medical image analysis with multi-modal large language models.arXiv preprint arXiv:2404.00578, 2024
-
[14]
Generalist foundation models from a multimodal dataset for 3d computed tomography.Nature Biomedical Engineering, pages 1–19, 2026
Ibrahim Ethem Hamamci, Sezgin Er, Chenyu Wang, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Irem Dogan, Omer Faruk Durugol, Benjamin Hou, Suprosanna Shit, et al. Generalist foundation models from a multimodal dataset for 3d computed tomography.Nature Biomedical Engineering, pages 1–19, 2026. 10
2026
-
[15]
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-vqa: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Med-flamingo: a multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. Med-flamingo: a multimodal medical few-shot learner. InMachine Learning for Health (ML4H), pages 353–367, 2023
2023
-
[17]
Towards generalist foundation model for radiology.arXiv preprint arXiv:2308.02463, 2023
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards generalist foundation model for radiology.arXiv preprint arXiv:2308.02463, 2023
-
[18]
Developing generalist foundation models from a multimodal dataset for 3d computed tomography
Ibrahim Ethem Hamamci, Sezgin Er, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Irem Dogan, Muhammed Furkan Dasdelen, Omer Faruk Durugol, Bastian Wittmann, Tamaz Amiranashvili, et al. Developing generalist foundation models from a multimodal dataset for 3d computed tomography. 2024
2024
-
[19]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. volume 1, page 3, 2022
2022
-
[24]
Generating radiology reports via memory-driven transformer
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory-driven transformer. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 1439–1449, 2020
2020
-
[25]
Cross-modal memory networks for radiology report generation
Zhihong Chen, Yaling Shen, Yan Song, and Xiang Wan. Cross-modal memory networks for radiology report generation. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 5904–5914, 2021
2021
-
[26]
Chang Liu, Yuanhe Tian, and Yan Song. A systematic review of deep learning-based research on radiology report generation.arXiv preprint arXiv:2311.14199, 2023
-
[27]
Bootstrapping large language models for radiology report generation
Chang Liu, Yuanhe Tian, Weidong Chen, Yan Song, and Yongdong Zhang. Bootstrapping large language models for radiology report generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18635–18643, 2024
2024
-
[28]
Diffusion networks with task-specific noise control for radiology report generation
Yuanhe Tian, Fei Xia, and Yan Song. Diffusion networks with task-specific noise control for radiology report generation. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1771–1780, 2024
2024
-
[29]
Extractive radiology reporting with memory-based cross-modal representations.IEEE Transactions on Medical Imaging, 2025
Yuanhe Tian, Zexuan Yan, Nenan Lyu, and Yan Song. Extractive radiology reporting with memory-based cross-modal representations.IEEE Transactions on Medical Imaging, 2025
2025
-
[30]
Merlin: a computed tomography vision–language foundation model and dataset.Nature, pages 1–11, 2026
Louis Blankemeier, Ashwin Kumar, Joseph Paul Cohen, Jiaming Liu, Longchao Liu, Dave Van Veen, Syed Jamal Safdar Gardezi, Hongkun Yu, Magdalini Paschali, Zhihong Chen, et al. Merlin: a computed tomography vision–language foundation model and dataset.Nature, pages 1–11, 2026. 11
2026
-
[31]
Scaling self-supervised and cross-modal pretraining for volumetric ct transformers
Cris Claessens, Christiaan Viviers, Giacomo D’Amicantonio, Egor Bondarev, and Fons van der Sommen. Scaling self-supervised and cross-modal pretraining for volumetric ct transformers. arXiv preprint arXiv:2511.17209, 2025
-
[32]
R2gen-mamba: A selective state space model for radiology report generation
Yongheng Sun, Yueh Z Lee, Genevieve A Woodard, Hongtu Zhu, Chunfeng Lian, and Mingxia Liu. R2gen-mamba: A selective state space model for radiology report generation. pages 1–4, 2025
2025
-
[33]
Making the most of text semantics to improve biomedical vision–language processing
Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, et al. Making the most of text semantics to improve biomedical vision–language processing. In European conference on computer vision, pages 1–21, 2022
2022
-
[34]
Learning semantic relationship among instances for image-text matching
Zheren Fu, Zhendong Mao, Yan Song, and Yongdong Zhang. Learning semantic relationship among instances for image-text matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15159–15168, 2023
2023
-
[35]
Improving image captioning via predicting structured concepts
Ting Wang, Weidong Chen, Yuanhe Tian, Yan Song, and Zhendong Mao. Improving image captioning via predicting structured concepts. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 360–370, 2023
2023
-
[36]
Chexworld: Exploring image world modeling for radiograph representation learning
Yang Yue, Yulin Wang, Chenxin Tao, Pan Liu, Shiji Song, and Gao Huang. Chexworld: Exploring image world modeling for radiograph representation learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20778–20788, 2025
2025
-
[37]
BLEU: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[38]
ROUGE: A Package for Automatic Evaluation of Summaries
Chin-Yew Lin. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summa- rization Branches Out, pages 74–81, Barcelona, Spain, July 2004
2004
-
[39]
Meteor: An automatic metric for mt evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pages 65–72, 2005
2005
-
[40]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[41]
Ratescore: A metric for radiology report generation
Weike Zhao, Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Ratescore: A metric for radiology report generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15004–15019, 2024
2024
-
[42]
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Bluethgen, Arne Edward Michalson, Michael Moseley, Curtis Langlotz, Akshay S Chaud- hari, et al. Green: Generative radiology report evaluation and error notation.arXiv preprint arXiv:2405.03595, 2024. A CT-RATE HU-to-Image Preprocessing CT-RATE provides 3D NIfTI volumes who...
-
[43]
The decoder backbones are Qwen3-1.7B, Qwen3-4B, and Ministral-3-3B
The state-factor dimensions are danat = 256 , dlesion = 192 , and dunc = 64 , and the world- token dimension is 512. The decoder backbones are Qwen3-1.7B, Qwen3-4B, and Ministral-3-3B. Qwen3-1.7B has 28 Transformer layers with hidden size 2,048, 16 attention heads, and 8 key-value heads; Qwen3-4B has 36 layers with hidden size 2,560, 32 attention heads, a...
1935
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.