ECHO: Terminal Agents Learn World Models for Free
Pith reviewed 2026-06-30 14:53 UTC · model grok-4.3
The pith
Training CLI agents to predict terminal responses alongside actions doubles task success rates without expert data or extra rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
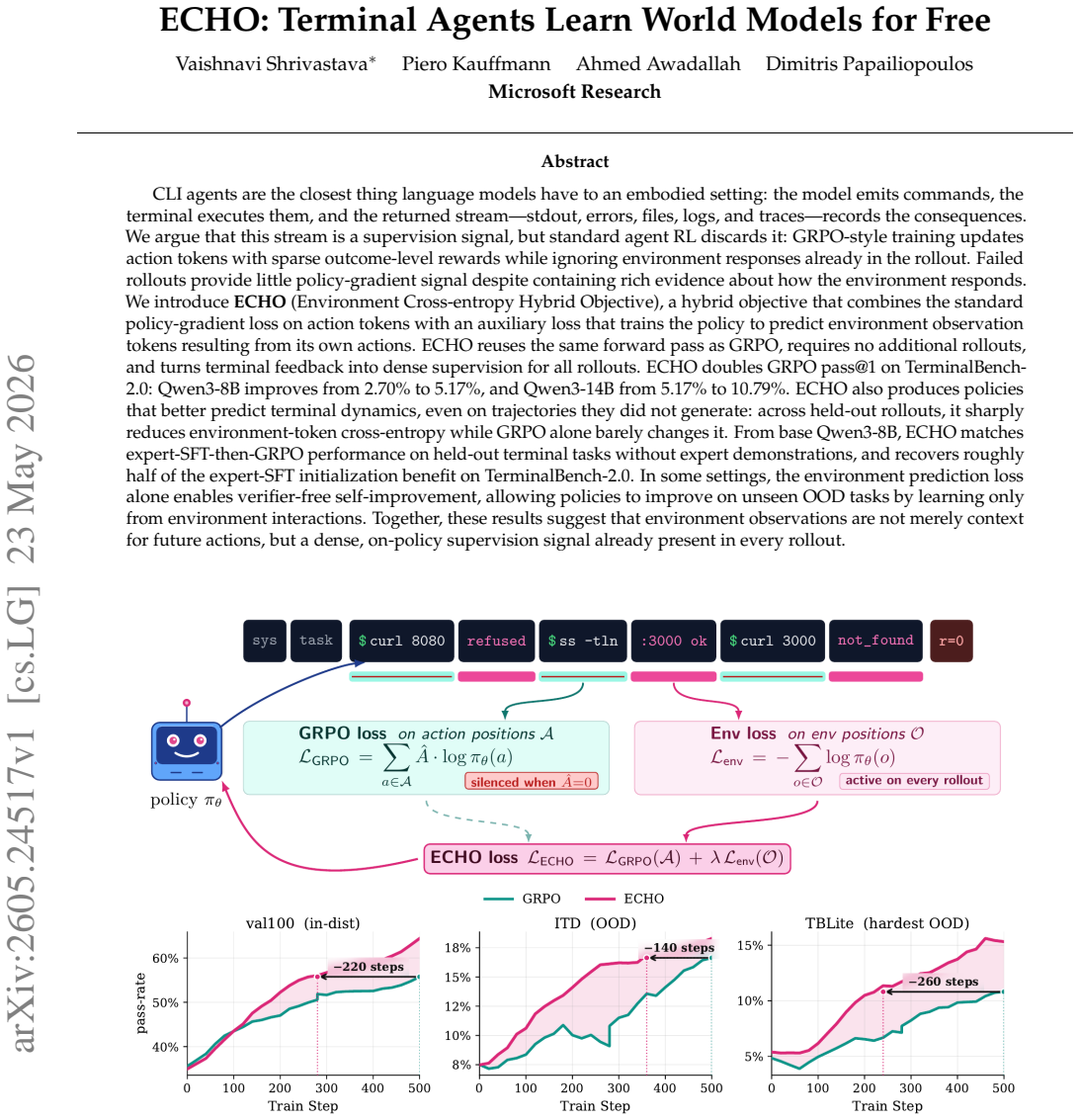
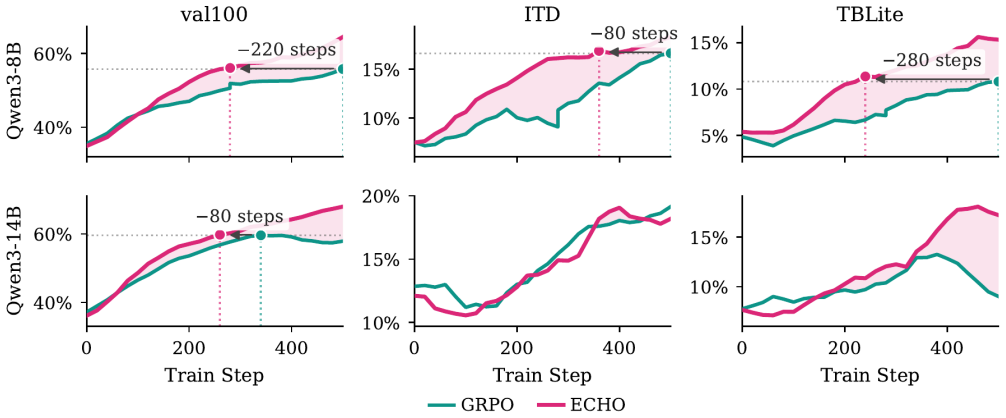
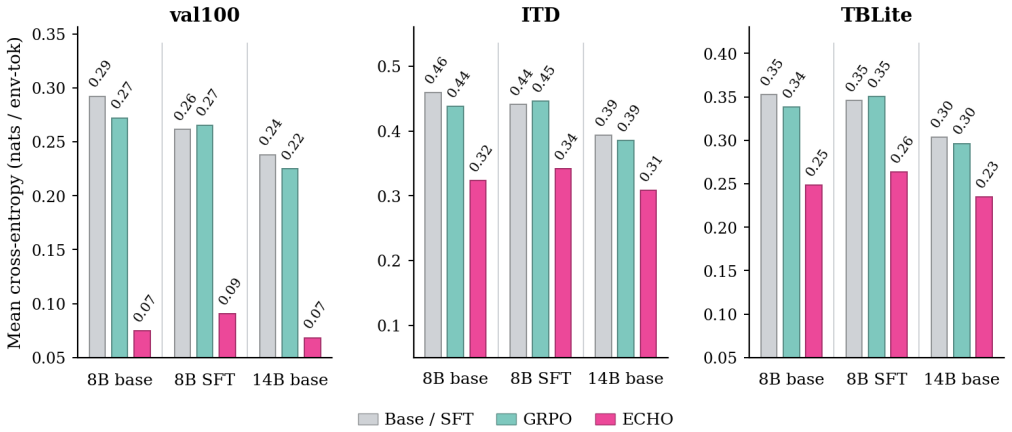
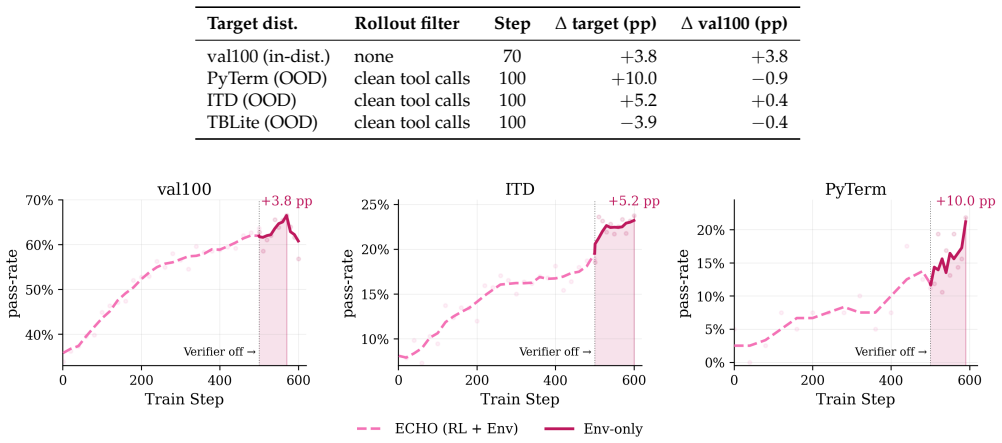
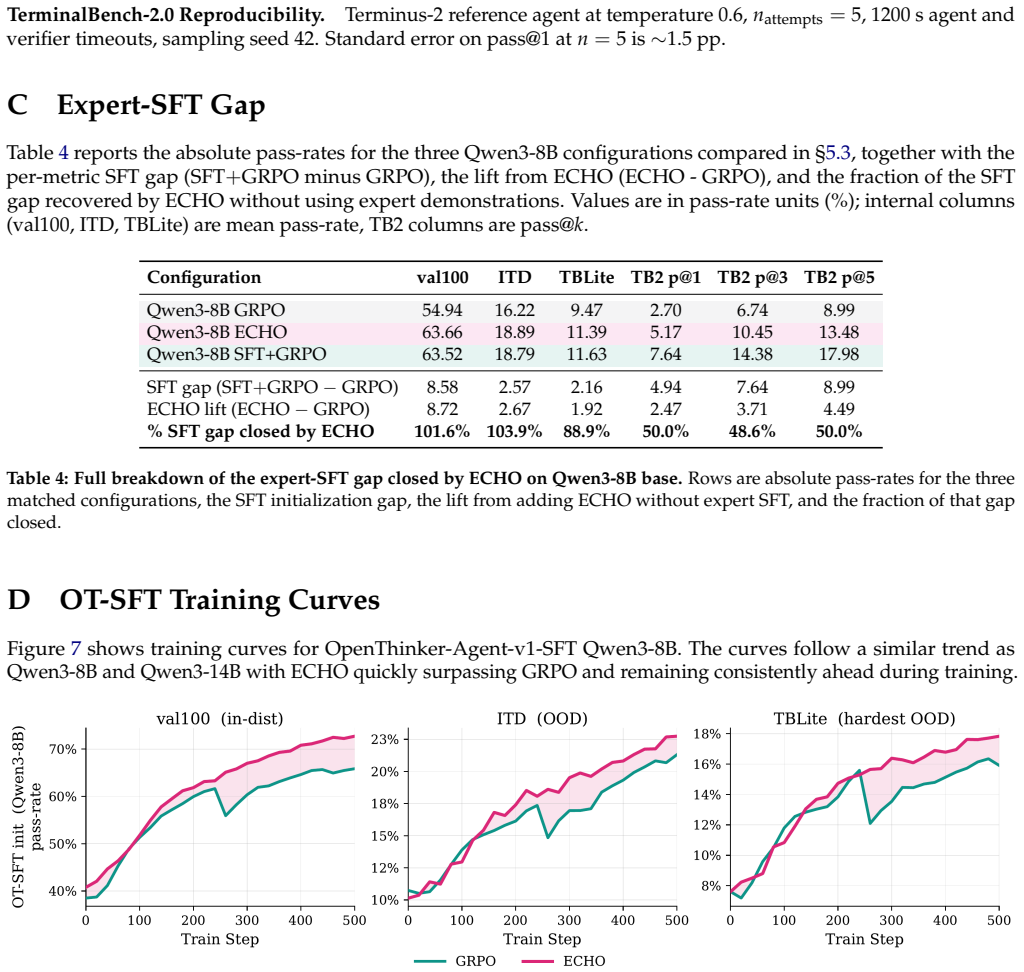
ECHO is a hybrid objective that combines the standard policy-gradient loss on action tokens with an auxiliary cross-entropy loss on environment observation tokens resulting from the agent's own actions. The method reuses the identical forward pass as GRPO, requires no additional rollouts, and converts every terminal response into dense supervision. On TerminalBench-2.0 it raises pass@1 from 2.70% to 5.17% for Qwen3-8B and from 5.17% to 10.79% for Qwen3-14B, sharply lowers environment-token cross-entropy on held-out rollouts, matches expert-SFT-then-GRPO performance without demonstrations, and enables self-improvement on unseen tasks through the prediction loss alone.
What carries the argument
The ECHO hybrid objective, which adds an auxiliary loss training the policy to predict environment observation tokens from its own actions while keeping the original policy-gradient loss.
If this is right
- Policies reach roughly double the pass@1 rate on TerminalBench-2.0 compared with GRPO alone.
- Policies achieve lower cross-entropy when predicting environment tokens on trajectories they did not generate.
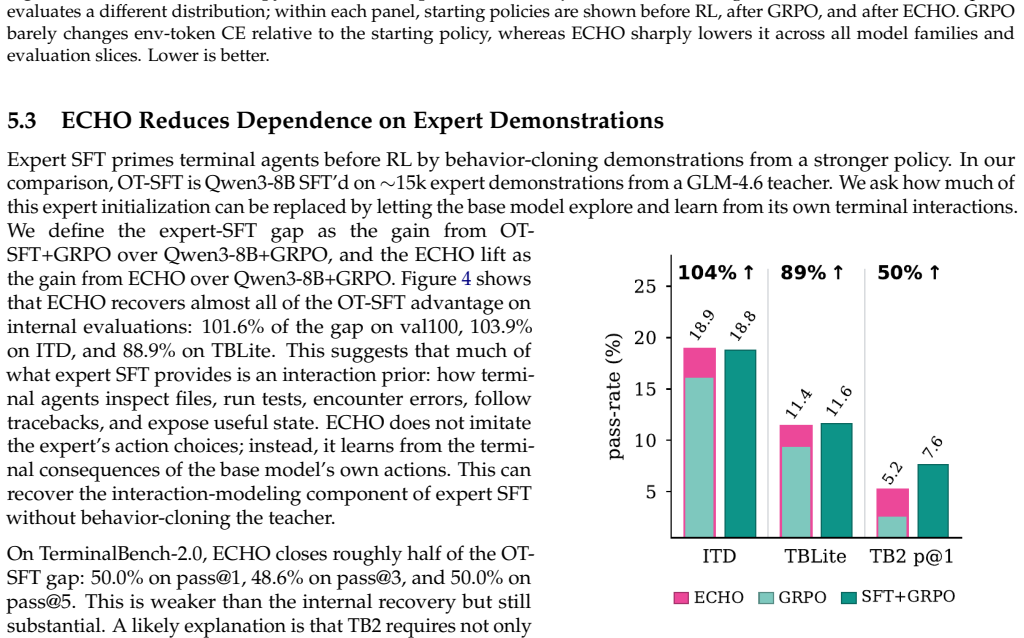
- Performance matches expert-SFT-then-GRPO training while using only base-model rollouts and no expert demonstrations.
- The environment-prediction term alone can produce measurable gains on out-of-distribution tasks without any verifier.
Where Pith is reading between the lines
- The same auxiliary loss could be tested in non-terminal interactive environments where actions produce observable state changes.
- If environment prediction improves action selection, longer-horizon tasks might see larger gains because each rollout supplies more prediction targets.
- The result suggests that many current agent methods discard the primary learning signal already contained in their interaction data.
Load-bearing premise
Predicting environment observation tokens supplies a dense, transferable supervision signal that improves downstream action selection without negative interference or distribution shift.
What would settle it
An ablation in which the environment-prediction loss is added but cross-entropy on held-out rollouts stays the same or rises while task pass@1 still doubles.
Figures
read the original abstract
CLI agents are the closest thing language models have to an embodied setting: the model emits commands, the terminal executes them, and the returned stream -- stdout, errors, files, logs, and traces -- records the consequences. We argue that this stream is a supervision signal, but standard agent RL discards it: GRPO-style training updates action tokens with sparse outcome-level rewards while ignoring environment responses already in the rollout. Failed rollouts provide little policy-gradient signal despite containing rich evidence about how the environment responds. We introduce ECHO (Environment Cross-entropy Hybrid Objective), a hybrid objective that combines the standard policy-gradient loss on action tokens with an auxiliary loss that trains the policy to predict environment observation tokens resulting from its own actions. ECHO reuses the same forward pass as GRPO, requires no additional rollouts, and turns terminal feedback into dense supervision for all rollouts. ECHO doubles GRPO pass@1 on TerminalBench-2.0: Qwen3-8B improves from 2.70% to 5.17%, and Qwen3-14B from 5.17% to 10.79%. ECHO also produces policies that better predict terminal dynamics, even on trajectories they did not generate: across held-out rollouts, it sharply reduces environment-token cross-entropy while GRPO alone barely changes it. From base Qwen3-8B, ECHO matches expert-SFT-then-GRPO performance on held-out terminal tasks without expert demonstrations, and recovers roughly half of the expert-SFT initialization benefit on TerminalBench-2.0. In some settings, the environment prediction loss alone enables verifier-free self-improvement, allowing policies to improve on unseen OOD tasks by learning only from environment interactions. Together, these results suggest that environment observations are not merely context for future actions, but a dense, on-policy supervision signal already present in every rollout.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ECHO, a hybrid objective for training CLI agents that augments standard GRPO policy-gradient loss on action tokens with an auxiliary cross-entropy loss on environment observation tokens produced by the agent's own actions. The method reuses the same forward pass with no extra rollouts. It reports that ECHO doubles GRPO pass@1 on TerminalBench-2.0 (Qwen3-8B: 2.70% to 5.17%; Qwen3-14B: 5.17% to 10.79%), sharply reduces environment-token cross-entropy on held-out rollouts, matches expert-SFT-then-GRPO performance from base models without demonstrations, and enables verifier-free self-improvement on OOD tasks via the environment prediction loss alone.
Significance. If the reported gains are robust and causally driven by the auxiliary loss providing transferable dynamics supervision rather than regularization or loss-scale effects, the result would be significant for agent RL: it converts already-available terminal feedback into dense on-policy signals at negligible extra cost, potentially reducing dependence on expert data or external verifiers in embodied-like settings.
major comments (2)
- [Abstract] Abstract: the claim that the environment prediction loss supplies a 'dense, transferable supervision signal that alters the policy's action distribution in a beneficial way' is load-bearing for the central contribution, yet the abstract provides no ablation that holds total loss magnitude fixed while removing the env-token term; without this, it remains possible that observed pass@1 gains arise from implicit regularization or altered gradient scale rather than learned environment dynamics.
- [Abstract] Abstract: the concrete numerical claims (pass@1 doubling, cross-entropy reductions, matching expert-SFT) are presented without reference to experimental controls, number of independent runs, statistical significance, data splits, or hyperparameter search details; these omissions make it impossible to assess whether the reported improvements are reliable or sensitive to post-hoc choices.
minor comments (1)
- [Abstract] The abstract would benefit from a brief equation or pseudocode sketch of the combined loss to clarify how the two terms are weighted and whether any stop-gradient is applied between heads.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the environment prediction loss supplies a 'dense, transferable supervision signal that alters the policy's action distribution in a beneficial way' is load-bearing for the central contribution, yet the abstract provides no ablation that holds total loss magnitude fixed while removing the env-token term; without this, it remains possible that observed pass@1 gains arise from implicit regularization or altered gradient scale rather than learned environment dynamics.
Authors: We agree that an ablation holding total loss magnitude fixed would more directly isolate the contribution of the environment-token term. The manuscript already reports that ECHO (but not GRPO) produces large reductions in held-out environment-token cross-entropy, which is difficult to explain by generic regularization alone. Nevertheless, to address the concern, we will add an ablation that replaces the environment-token loss with an auxiliary loss of matched scale applied to random or non-environment tokens and report the resulting pass@1 and dynamics metrics. revision: yes
-
Referee: [Abstract] Abstract: the concrete numerical claims (pass@1 doubling, cross-entropy reductions, matching expert-SFT) are presented without reference to experimental controls, number of independent runs, statistical significance, data splits, or hyperparameter search details; these omissions make it impossible to assess whether the reported improvements are reliable or sensitive to post-hoc choices.
Authors: The abstract is intentionally concise; the full experimental protocol—including data splits on TerminalBench-2.0, five independent random seeds for all reported pass@1 numbers, bootstrap confidence intervals, and hyperparameter ranges—is detailed in Section 4 and Appendix B. To improve accessibility we will insert a short clause in the abstract (or a footnote) that points readers to these sections for controls and reproducibility information. revision: partial
Circularity Check
No significant circularity; ECHO's claims rest on empirical comparisons.
full rationale
The paper defines ECHO as a hybrid objective (policy-gradient loss plus auxiliary environment-token cross-entropy) and reports measured improvements in pass@1 and held-out cross-entropy on TerminalBench-2.0. These are direct experimental outcomes against GRPO baselines; no equation, parameter fit, or self-citation is presented as deriving the performance gains by construction. The central premise that environment observations supply transferable supervision is tested rather than assumed into the result, and no load-bearing step reduces to renaming, self-definition, or an imported uniqueness theorem.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Environment observation tokens returned by the terminal constitute a dense, on-policy supervision signal that can improve policy performance when used as an auxiliary prediction target.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2511.16108. FAIR CodeGen team, Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, David Zhang, Kunhao Zheng, Jordi Armengol-Estapé, Pedram Bashiri, Maximilian Beck, Pierre Chambon, Abhishek Charnalia, Chris Cummins, Juliette Decugis, Zacharia...
-
[2]
Kanishk Gandhi, Shivam Garg, Noah D
URLhttps://arxiv.org/abs/2510.02387. Kanishk Gandhi, Shivam Garg, Noah D. Goodman, and Dimitris Papailiopoulos. Endless Terminals: Scaling RL Environments for Terminal Agents,
-
[3]
Goodman, and Dimitris Papailiopoulos
URLhttps://arxiv.org/abs/2601.16443. David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume
-
[4]
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi
URL https://proceedings.neurips.cc/paper_files/paper/ 2018/file/2de5d16682c3c35007e4e92982f1a2ba-Paper.pdf. Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by 10 latent imagination. InInternational Conference on Learning Representations,
2018
-
[5]
doi: 10.1038/s41586-025-08744-2. URL https://doi.org/10.1038/ s41586-025-08744-2. harbor-framework. Harbor: A framework for evaluating and optimizing agents and models in container environ- ments. Software, August
-
[6]
Accessed 2026-05-18
URLhttps://www.harborframework.com/docs/agents/terminus-2. Accessed 2026-05-18. Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement Learning via Self- Distillation,
2026
-
[7]
Reinforcement Learning via Self-Distillation
URLhttps://arxiv.org/abs/2601.20802. Max Jaderberg, Volodymyr Mnih, Wojciech Marian Czarnecki, Tom Schaul, Joel Z. Leibo, David Silver, and Koray Kavukcuoglu. Reinforcement learning with unsupervised auxiliary tasks. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URLhttps://arxiv.org/abs/2402.07102. Mike A Merrill, Alexander Glenn Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zha...
-
[9]
Endless Terminals: Scaling RL Environments for Terminal Agents
URL https://huggingface.co/datasets/ obiwan96/endless-terminals. Associated with Gandhi et al., “Endless Terminals: Scaling RL Environments for Terminal Agents”; accessed 2026-05-18. OpenThoughts-Agent Team. OpenThinker-Agent-v1-SFT. Hugging Face model card, December 2025a. URL https://huggingface.co/open-thoughts/OpenThinker-Agent-v1-SFT. Accessed 2026-0...
2026
-
[10]
Accessed 2026-05-18
URL https://huggingface.co/datasets/ open-thoughts/OpenThoughts-TBLite. Accessed 2026-05-18. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sand- hini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis ...
2026
-
[11]
Dwarkesh Patel
URL https://proceedings.neurips.cc/paper_files/paper/2022/file/ b1efde53be364a73914f58805a001731-Paper-Conference.pdf. Dwarkesh Patel. Ilya sutskever (openai chief scientist) – why next-token prediction could surpass human intel- ligence. Interview by Dwarkesh Patel, Dwarkesh Podcast, March
2022
-
[12]
Transcript, accessed 2026-05-18
URL https://www.dwarkesh.com/p/ ilya-sutskever. Transcript, accessed 2026-05-18. Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. InInternational conference on machine learning, pages 2778–2787. PMLR,
2026
-
[13]
doi: 10.1038/s41586-020-03051-4. URLhttps://doi.org/10.1038/s41586-020-03051-4. Max Schwarzer, Ankesh Anand, Rishab Goel, R Devon Hjelm, Aaron Courville, and Philip Bachman. Data-efficient reinforcement learning with self-predictive representations. InInternational Conference on Learning Representations,
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4
-
[14]
URLhttps://arxiv.org/abs/2007.05929. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models,
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URLhttps://arxiv.org/abs/2402.03300. Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J. Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Andrew and Singh, Aarti and Zanette, Andrea , month = feb, year =
URL https://arxiv.org/ abs/2602.02482. Siyin Wang, Zhaoye Fei, Qinyuan Cheng, Shiduo Zhang, Panpan Cai, Jinlan Fu, and Xipeng Qiu. World modeling makes a better planner: Dual preference optimization for embodied task planning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21518–21537,
-
[17]
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang
URL https://aclanthology.org/2025.acl-long.1044/. Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. OpenClaw-RL: Train Any Agent Simply by Talking,
2025
-
[18]
OpenClaw-RL: Train Any Agent Simply by Talking
URLhttps://arxiv.org/abs/2603.10165. Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun MA, and Bo An. SimpleTIR: End-to-end reinforcement learning for multi-turn tool-integrated reasoning. InThe Fourteenth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URLhttps://arxiv.org/abs/2505.09388. Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
World Action Models are Zero-shot Policies
URL https://arxiv.org/abs/2602.15922. Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, and Yang Gao. Mastering Atari games with limited data. Advances in neural information processing systems, 34:25476–25488,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URL https://proceedings.neurips.cc/ paper_files/paper/2021/file/d5eca8dc3820cad9fe56a3bafda65ca1-Paper.pdf. 12 Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zh...
2021
-
[22]
Agent Learning via Early Experience
URLhttps://arxiv.org/abs/2510.08558. Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar. ArCHer: Training language model agents via hierarchical multi-turn RL,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
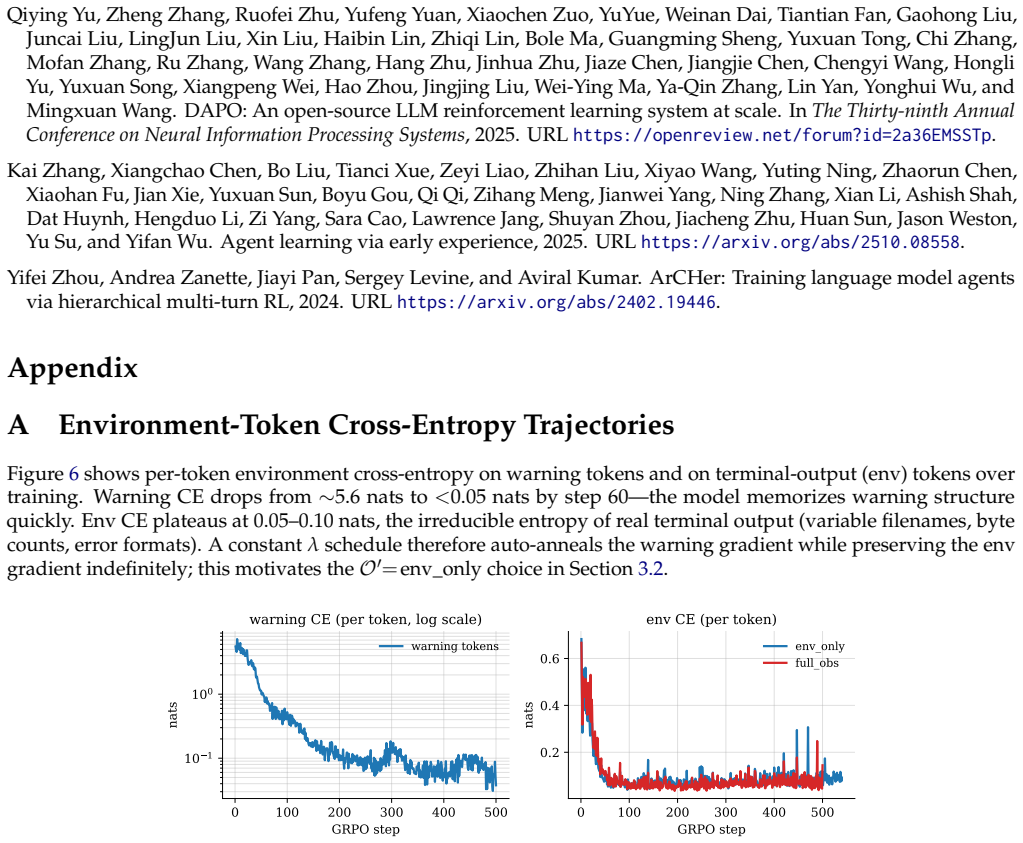
URLhttps://arxiv.org/abs/2402.19446. Appendix A Environment-Token Cross-Entropy Trajectories Figure 6 shows per-token environment cross-entropy on warning tokens and on terminal-output (env) tokens over training. Warning CE drops from ∼5.6 nats to <0.05 nats by step 60—the model memorizes warning structure quickly. Env CE plateaus at 0.05–0.10 nats, the i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.