What Are We Actually Decoding? Source Attribution for Non-Invasive Brain-to-Language Retrieval
Pith reviewed 2026-06-30 14:45 UTC · model grok-4.3
The pith
Brain-to-language retrieval performance must be broken down by source instead of reported as a single number.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
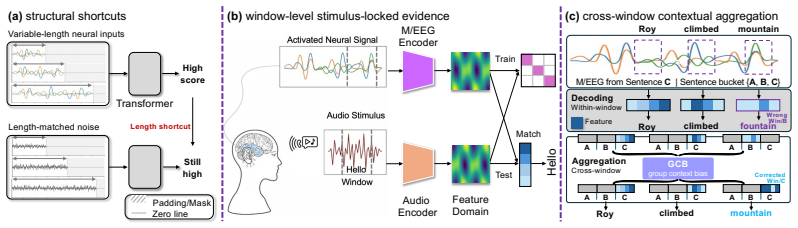
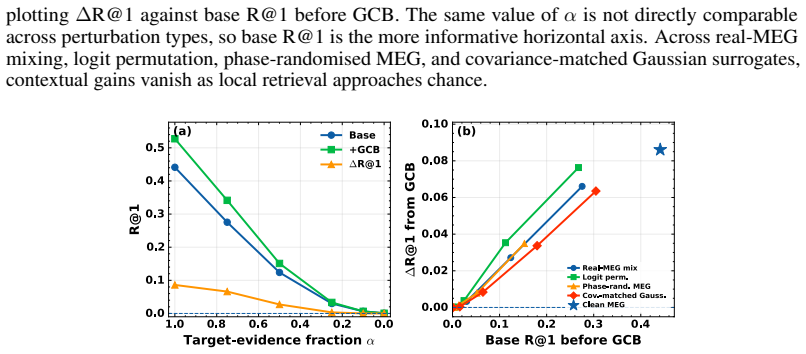
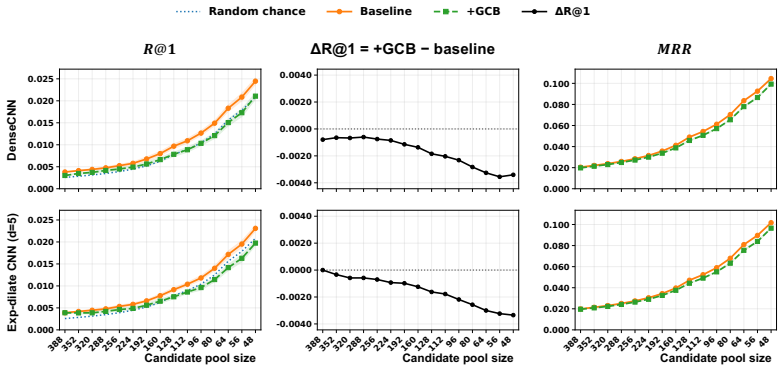
By recasting MEG-to-audio retrieval as a source-auditing task, the work separates performance into structural shortcuts that collapse under fixed-duration and identity-split controls, window-level stimulus-locked evidence that remains measurable once those controls are applied, and cross-window contextual aggregation that can be isolated with an inference-time additive logit bias whose effect vanishes under random perturbations or when local evidence is weak.
What carries the argument
An auditing framework that decomposes apparent retrieval performance into structural shortcuts, window-level stimulus-locked evidence, and cross-window contextual aggregation, with Group Context Bias serving as the measurable intervention for the contextual component.
If this is right
- Structural factors such as variable signal length can produce high retrieval scores in the absence of any neural signal.
- Once structural shortcuts are removed, sentence-level competition remains the main remaining bottleneck even when window-level evidence is present.
- Contextual pooling improves scores only when genuine local evidence exists and disappears under random grouping or weak local signals.
Where Pith is reading between the lines
- The same source-separation logic could be applied to EEG or fMRI language decoding to check whether similar non-neural contributions are present.
- Benchmark reporting standards might shift toward requiring explicit attribution of gains to one of the three sources.
- If contextual aggregation proves robust, future decoders could incorporate explicit sentence-level models to target that source directly.
Load-bearing premise
Fixed-duration windows, stimulus-identity splits, and random-grouping perturbations are enough to isolate the three performance sources without residual confounds from unmodeled interactions between structural and neural components.
What would settle it
If real MEG data still shows the same retrieval advantage over signal-blind noise after the fixed-duration and identity-split controls are applied, the separation into neural versus structural sources would be shown to be incomplete.
Figures
read the original abstract
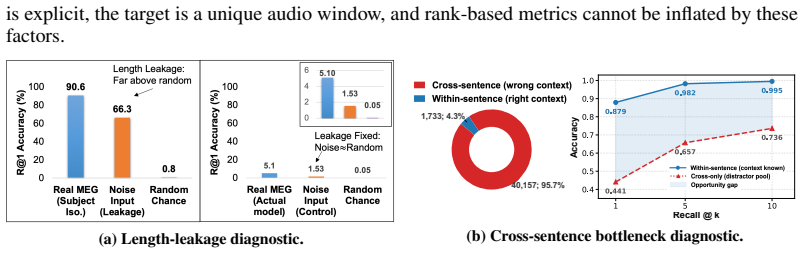
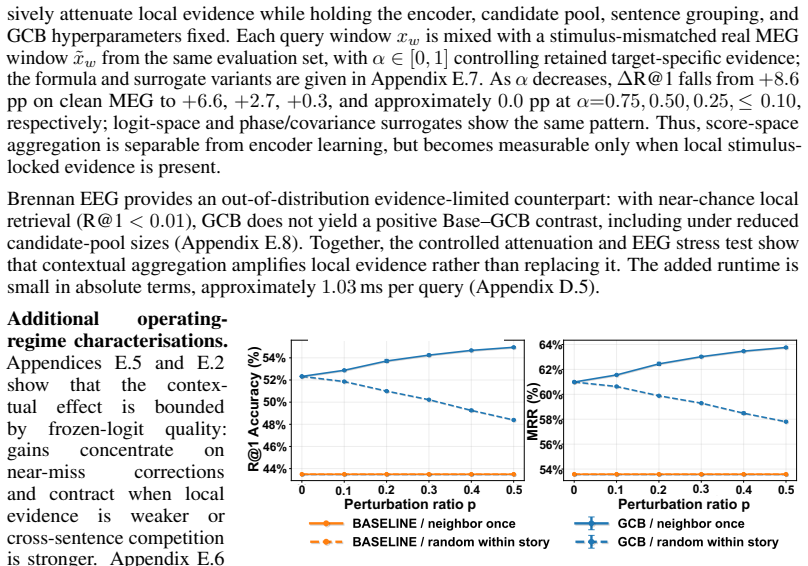
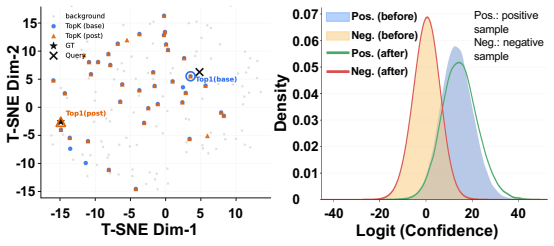
In non-invasive neural language decoding, results can be inflated by sources that are not stimulus-evoked neural evidence: decoder priors, embedding-based metrics, and non-neural structural nuisances such as signal duration. The methodological challenge is therefore attribution: a reported gain is more informative when it can be traced to a specific source. We recast stimulus-locked MEG-to-audio retrieval as an auditing framework that separates apparent performance into three sources - structural shortcuts, window-level stimulus-locked evidence, and cross-window contextual aggregation - and provides a diagnostic for each. Signal-blind Gaussian noise reaches 66.3% Rank@1 (R@1) under variable-length decoding but collapses to near chance once fixed-duration windows and stimulus-identity splits are enforced, isolating structural leakage. Under these controls, fixed-window retrieval recovers measurable MEG-audio discriminability, while an oracle sentence-bucket diagnostic shows that 95.7% of Top-1 errors select the wrong sentence, localising the residual bottleneck to sentence-level competition. We audit this contextual source with Group Context Bias (GCB), an inference-time additive logit bias that pools sentence-consistent evidence across windows while leaving the base retrieval scores and candidate pool fixed. Used as a score-space intervention, GCB makes the contextual source measurable: R@1 shifts from 44% to 52% on Gwilliams and from 22% to 29% on MOUS under the same fixed setting. GCB is auditable under this design: its effect collapses under random-grouping perturbations and vanishes when local evidence is attenuated in MEG or is near chance in EEG, supporting its use as a controlled source-attribution intervention. These results suggest that brain-to-language performance should be source-attributed, not merely reported.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
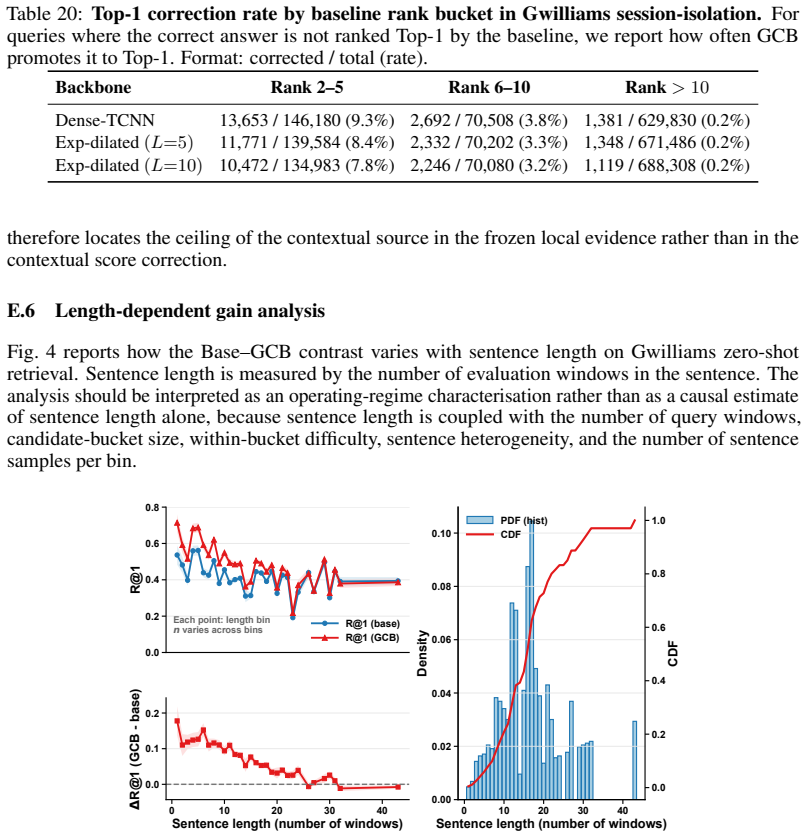
Summary. The manuscript proposes an auditing framework for non-invasive MEG/EEG-to-language retrieval that decomposes reported performance into three sources: structural shortcuts (isolated via signal-blind Gaussian noise, fixed-duration windows, and stimulus-identity splits), window-level stimulus-locked neural evidence, and cross-window contextual aggregation (measured via the Group Context Bias or GCB intervention). It reports concrete diagnostics including noise collapsing to chance under controls, an oracle showing 95.7% of top-1 errors are sentence-level, and GCB lifts of 8 and 7 R@1 points on Gwilliams and MOUS that vanish under random-grouping perturbations or when local evidence is weak.
Significance. If the separation holds, the framework supplies a practical, perturbation-auditable toolkit for source attribution in brain-to-language decoding, directly supporting the claim that gains should be traced rather than aggregated. The external grounding via independent perturbations and cross-modality (MEG/EEG) checks is a strength that reduces circularity risk.
major comments (1)
- [GCB evaluation and perturbation results] The central attribution claim (that GCB isolates contextual aggregation) rests on the assumption that fixed-duration windows plus stimulus-identity splits eliminate all structural-neural interactions. However, the manuscript does not report explicit tests for residual confounds such as duration-dependent neural feature correlations or sentence-bucket statistics interacting with MEG topography; without these, the observed R@1 shifts (44% to 52% on Gwilliams) could partly reflect unmodeled structural leakage rather than pure context.
minor comments (1)
- [Methods] Provide the precise algorithmic definition and hyperparameter settings for the stimulus-identity splits and the oracle sentence-bucket diagnostic to support replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. We address the single major comment below.
read point-by-point responses
-
Referee: The central attribution claim (that GCB isolates contextual aggregation) rests on the assumption that fixed-duration windows plus stimulus-identity splits eliminate all structural-neural interactions. However, the manuscript does not report explicit tests for residual confounds such as duration-dependent neural feature correlations or sentence-bucket statistics interacting with MEG topography; without these, the observed R@1 shifts (44% to 52% on Gwilliams) could partly reflect unmodeled structural leakage rather than pure context.
Authors: We appreciate this concern regarding potential residual confounds. The stimulus-identity splits are constructed such that each unique stimulus appears in only one partition, which by design prevents sentence-bucket statistics from influencing cross-split evaluation. Fixed-duration windows further eliminate duration as a confounding variable. While the manuscript does not include separate correlation analyses between neural features and duration or MEG topography, the signal-blind Gaussian noise control—which preserves all original duration, topography, and any associated correlations—collapses to near-chance performance under the identical fixed-window and identity-split regime. This provides evidence that unmodeled structural-neural interactions are not driving the base retrieval scores or the GCB-induced lifts. We will expand the discussion section to explicitly address these controls and their implications for residual confounds. revision: partial
Circularity Check
No significant circularity; derivation chain relies on independent controls and perturbations
full rationale
The paper separates performance sources using signal-blind Gaussian noise under fixed-duration windows and stimulus-identity splits to isolate structural leakage, then introduces GCB as an additive logit bias at inference time to measure contextual aggregation. Validation occurs via independent perturbations (random grouping, MEG vs EEG attenuation) that cause GCB effects to collapse, without any step reducing to a fitted parameter renamed as prediction or depending on self-citation chains. The framework is self-contained against external benchmarks like chance-level baselines and oracle sentence-bucket diagnostics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Fixed-duration windows and stimulus-identity splits isolate structural leakage from neural evidence without introducing new confounds
- domain assumption The oracle sentence-bucket diagnostic and perturbation tests accurately localize the contextual bottleneck
invented entities (1)
-
Group Context Bias (GCB)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Open vocabulary electroencephalography-to-text decoding and zero-shot sentiment classification
Zhenhailong Wang and Heng Ji. Open vocabulary electroencephalography-to-text decoding and zero-shot sentiment classification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 5350–5358, 2022
2022
-
[2]
DeWave: Discrete encoding of EEG waves for EEG-to-text translation
Yiqun Duan, Jinzhao Zhou, Zhen Wang, Yu-Kai Wang, and Chin-Teng Lin. DeWave: Discrete encoding of EEG waves for EEG-to-text translation. InAdvances in Neural Information Processing Systems, volume 36, pages 9907–9918, 2023
2023
-
[3]
UniCoRN: Unified cognitive signal reconstruction bridging cognitive signals and human language
Nuwa Xi, Sendong Zhao, Haochun Wang, Chi Liu, Bing Qin, and Ting Liu. UniCoRN: Unified cognitive signal reconstruction bridging cognitive signals and human language. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023
2023
-
[4]
MAD: Multi-alignment MEG-to-text decoding, 2024
Yiqian Yang, Hyejeong Jo, Yiqun Duan, Qiang Zhang, Jinni Zhou, Won Hee Lee, Renjing Xu, and Hui Xiong. MAD: Multi-alignment MEG-to-text decoding, 2024
2024
-
[5]
Jilong Li, Zhenxi Song, Jiaqi Wang, Meishan Zhang, Honghai Liu, Min Zhang, and Zhiguo Zhang. BrainECHO: Semantic brain signal decoding through vector-quantized spectrogram reconstruction for whisper-enhanced text generation. InFindings of the Association for Computa- tional Linguistics: ACL 2025, pages 2762–2778, 2025. doi: 10.18653/v1/2025.findings-acl.142
-
[6]
Nature Machine Intelligence , author =
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020. doi: 10.1038/s42256-020-00257-z
-
[7]
Jean-Thomas Baillargeon and Luc Lamontagne. Assessing the impact of sequence length learn- ing on classification tasks for transformer encoder models.arXiv preprint arXiv:2212.08399, 2022
-
[8]
Evaluating EEG-to-text models through noise-based performance analysis.Scientific Reports, 16(1):350,
Hyejeong Jo, Yiqian Yang, Juhyeok Han, Yiqun Duan, Hui Xiong, and Won Hee Lee. Evaluating EEG-to-text models through noise-based performance analysis.Scientific Reports, 16(1):350,
-
[9]
doi: 10.1038/s41598-025-29587-x
-
[10]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating text generation with BERT. InProceedings of the 8th International Conference on Learning Representations, 2020
2020
-
[11]
A fine-grained analysis of BERTScore
Michael Hanna and Ondˇrej Bojar. A fine-grained analysis of BERTScore. InProceedings of the Sixth Conference on Machine Translation, pages 507–517, 2021
2021
-
[12]
Blauch, Yunan Charles Wu, Ryan Glatt, David A
Geoffrey Brookshire, Jake Kasper, Nicholas M. Blauch, Yunan Charles Wu, Ryan Glatt, David A. Merrill, Spencer Gerrol, Keith J. Yoder, Colin Quirk, and Ché Lucero. Data leakage in deep learning studies of translational EEG.Frontiers in Neuroscience, 18:1373515, 2024
2024
-
[13]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V
Congchi Yin, Qian Yu, Zhiwei Fang, Changping Peng, and Piji Li. Rethinking cross-subject data splitting for brain-to-text decoding. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5675–5689, Suzhou, China, November 2025....
-
[14]
Decoding speech perception from non-invasive brain recordings.Nature Machine Intelligence, 5(10):1097–1107, 2023
Alexandre Défossez, Charlotte Caucheteux, Jérémy Rapin, Ori Kabeli, and Jean-Rémi King. Decoding speech perception from non-invasive brain recordings.Nature Machine Intelligence, 5(10):1097–1107, 2023
2023
-
[15]
Stéphane d’Ascoli, Corentin Bel, Jérémy Rapin, Hubert Banville, Yohann Benchetrit, Christophe Pallier, and Jean-Rémi King. Towards decoding individual words from non-invasive brain recordings.Nature Communications, 16(1):10521, 2025. doi: 10.1038/s41467-025-65499-0
-
[16]
Meyer, and Andrea E
Sophie Slaats, Hugo Weissbart, Jan-Mathijs Schoffelen, Antje S. Meyer, and Andrea E. Martin. Delta-band neural responses to individual words are modulated by sentence processing.Journal of Neuroscience, 43(26):4867–4883, 2023. 11
2023
-
[17]
Christian Brodbeck, Shohini Bhattasali, Aura A. L. Cruz Heredia, Philip Resnik, Jonathan Z. Simon, and Ellen Lau. Parallel processing in speech perception with local and global represen- tations of linguistic context.eLife, 11:e72056, 2022
2022
-
[18]
Vinay S. Raghavan and Lucas C. Parra. Neural encoding of linguistic features during natural sentence reading.iScience, 28(7):112798, 2025. doi: 10.1016/j.isci.2025.112798
-
[19]
Aligning semantic in brain and language: A curriculum contrastive method for electroencephalography-to-text generation
Xiachong Feng, Xiaocheng Feng, Bing Qin, and Ting Liu. Aligning semantic in brain and language: A curriculum contrastive method for electroencephalography-to-text generation. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 31:3874–3883, 2023
2023
-
[20]
Belt: boot- strapped eeg-to-language training by natural language supervision.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 32:3278–3288, 2024
Jinzhao Zhou, Yiqun Duan, Yu-Cheng Chang, Yu-Kai Wang, and Chin-Teng Lin. Belt: boot- strapped eeg-to-language training by natural language supervision.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 32:3278–3288, 2024
2024
-
[21]
EEG2TEXT: Open vocabulary EEG-to-text decoding with EEG pre-training and multi-view transformer, 2024
Hanwen Liu, Daniel Hajialigol, Benny Antony, Aiguo Han, and Xuan Wang. EEG2TEXT: Open vocabulary EEG-to-text decoding with EEG pre-training and multi-view transformer, 2024
2024
-
[22]
Thomas and Pavlick, Ellie and Linzen, Tal
R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3428–3448. Association for Computational Linguistics, 2019. doi: 10.18653/v1/P19-1334
-
[23]
Bowman, and Noah A
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman, and Noah A. Smith. Annotation artifacts in natural language inference data. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 2 (Short Papers), pages 107–112. Association...
2018
-
[24]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, page...
2021
-
[25]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 2020
2020
-
[26]
MEGformer: Enhancing speech decoding from brain activity through extended semantic representations
Maria Boyko, Polina Druzhinina, Georgii Kormakov, Aleksandra Beliaeva, and Maxim Sharaev. MEGformer: Enhancing speech decoding from brain activity through extended semantic representations. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 281–290, 2024
2024
-
[27]
The brain’s bitter lesson: Scaling speech decoding with self-supervised learning
Dulhan Jayalath, Gilad Landau, Brendan Shillingford, Mark Woolrich, and Oiwi Parker Jones. The brain’s bitter lesson: Scaling speech decoding with self-supervised learning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference ...
2025
-
[28]
Towards linguistic neural representation learning and sentence retrieval from electroencephalogram recordings
Jinzhao Zhou, Yiqun Duan, Ziyi Zhao, Yu-Cheng Chang, Yu-Kai Wang, Thomas Do, and Chin-Teng Lin. Towards linguistic neural representation learning and sentence retrieval from electroencephalogram recordings. InProceedings of the 1st International Workshop on Brain- Computer Interfaces (BCI) for Multimedia Understanding, pages 19–28, 2024
2024
-
[29]
Brain decoding: Toward real-time reconstruction of visual perception, 2023
Yohann Benchetrit, Hubert Banville, and Jean-Rémi King. Brain decoding: Toward real-time reconstruction of visual perception, 2023
2023
-
[30]
Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
Yonghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun Wang, and Xiaorong Gao. Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023. 12
-
[31]
Ribeiro, Miguel Vasco, Farzaneh Taleb, Mårten Björkman, and Danica Kragic
Nona Rajabi, Antonio H. Ribeiro, Miguel Vasco, Farzaneh Taleb, Mårten Björkman, and Danica Kragic. Human-aligned image models improve visual decoding from the brain. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 51009–51038. PMLR, 2025
2025
-
[32]
Michael P. Broderick, Andrew J. Anderson, Giovanni M. Di Liberto, Michael J. Crosse, and Edmund C. Lalor. Electrophysiological correlates of semantic dissimilarity reflect the comprehension of natural, narrative speech.Current Biology, 28(5):803–809.e3, 2018. doi: 10.1016/j.cub.2018.01.080
-
[33]
Cormack, Charles L
Gordon V . Cormack, Charles L. A. Clarke, and Stefan Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 758–759, 2009
2009
-
[34]
Hu-wbi at bioasq12b phase a: Exploring rank fusion of dense retrievers and re-rankers
O˘guz ¸ Serbetçi, Xing David Wang, and Ulf Leser. Hu-wbi at bioasq12b phase a: Exploring rank fusion of dense retrievers and re-rankers. InProceedings of the Conference and Labs of the Evaluation Forum, Grenoble, France, pages 9–12, 2024
2024
-
[35]
Enhancing retrieval systems with inference-time logical reasoning
Felix Faltings, Wei Wei, and Yujia Bao. Enhancing retrieval systems with inference-time logical reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 449–463, Vienna, Austria, July 2025. Assoc...
-
[36]
Luck.An Introduction to the Event-Related Potential Technique
Steven J. Luck.An Introduction to the Event-Related Potential Technique. MIT Press, Cam- bridge, MA, 2 edition, 2014. ISBN 9780262525855
2014
-
[37]
Anna M. Beres. Time is of the essence: A review of electroencephalography (EEG) and event-related brain potentials (ERPs) in language research.Applied Psychophysiology and Biofeedback, 42(4):247–255, 2017. doi: 10.1007/s10484-017-9371-3
-
[38]
Introducing meg-masc a high-quality magneto-encephalography dataset for evaluating natural speech processing.Scientific data, 10(1):862, 2023
Laura Gwilliams, Graham Flick, Alec Marantz, Liina Pylkkänen, David Poeppel, and Jean-Rémi King. Introducing meg-masc a high-quality magneto-encephalography dataset for evaluating natural speech processing.Scientific data, 10(1):862, 2023
2023
-
[39]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. InAdvances in Neural Information Processing Systems, volume 33, pages 12449–12460, 2020
2020
-
[40]
Unlocking non-invasive brain-to-text
Dulhan Jayalath, Gilad Landau, and Oiwi Parker Jones. Unlocking non-invasive brain-to-text. In2nd Generative AI for Biology Workshop at ICML 2025, 2025. Poster
2025
-
[41]
Jan-Mathijs Schoffelen, Robert Oostenveld, Ngoc H. L. Lam, Julia Uddén, Annika Hultén, and Peter Hagoort. A 204-subject multimodal neuroimaging dataset to study language processing. Scientific Data, 6(1):17, 2019. doi: 10.1038/s41597-019-0020-y
-
[42]
Brennan and John T
Jonathan R. Brennan and John T. Hale. Hierarchical structure guides rapid linguistic predictions during naturalistic listening.PLOS ONE, 14(1):e0207741, 2019
2019
-
[43]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 28492–28518. PMLR, 2023
2023
-
[44]
Samuel Sutton, Michael Braren, Joseph Zubin, and E. Roy John. Evoked-potential correlates of stimulus uncertainty.Science, 150(3700):1187–1188, 1965. doi: 10.1126/science.150.3700. 1187
-
[45]
John Polich. Updating P300: An integrative theory of P3a and P3b.Clinical Neurophysiology, 118(10):2128–2148, 2007. doi: 10.1016/j.clinph.2007.04.019
-
[46]
Marta Kutas and Steven A. Hillyard. Reading senseless sentences: Brain potentials reflect semantic incongruity.Science, 207(4427):203–205, 1980. doi: 10.1126/science.7350657. 13
-
[47]
Object-centric learning with slot attention.Advances in neural information processing systems, 33:11525–11538, 2020
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-centric learning with slot attention.Advances in neural information processing systems, 33:11525–11538, 2020
2020
-
[48]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–4664. PMLR, 2021
2021
-
[49]
Flamingo: A visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: A visual language model for few-shot learning. InAdvances in Neural Information Processing Systems, volume 35, pages 23716–23736, 2022. 14 A Data, assets, and preprocessing A.1 Sentence-...
2022
-
[50]
the short-eared people didn’treally know the secrets of the long ears and had pulled down all the moai statues and destroyed some of the tablets
For each 3 s audio window, we extract hidden activations from layers 14–18, average across layers, and retain the time-resolved representation. We interpolate or resample along time to match the evaluation temporal resolution T=360 , yielding a D×T target with D=1024. Standard waveform preprocessing, including resampling to 16 kHz and waveform normalisati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.