Hypothesis Generation and Inductive Inference in Children and Language Models
Pith reviewed 2026-06-30 13:13 UTC · model grok-4.3
The pith
Children and LLM agents both adapt inductive inference to evidence reliability and observability in a Box Task, though LLMs over-observe and over-comply.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
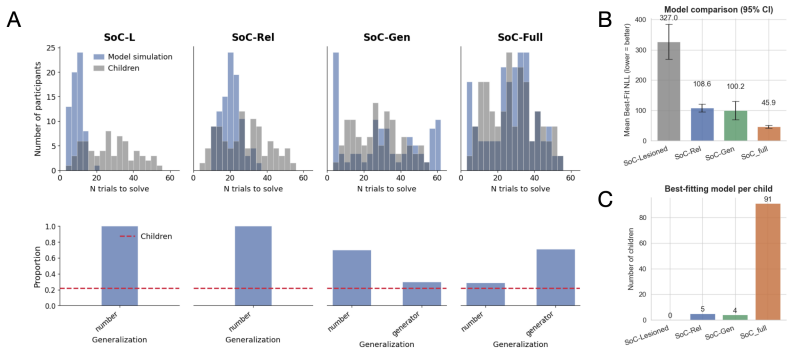
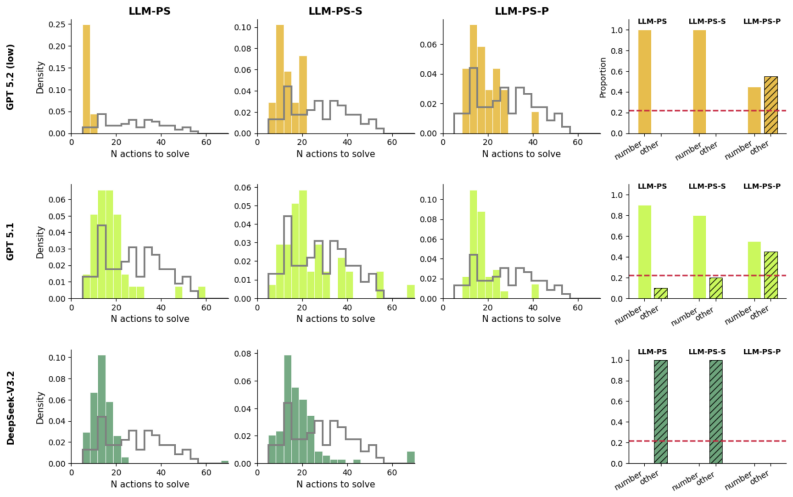
Using the constraint-based formulation, children's behavior is best explained by a combination of subjective evidence reliability and online hypothesis generation, accounting for both their evidence-seeking patterns and their dissociation between task completion and rule generalization. Using the program synthesis formulation, LLM-based agents replicate children's responses to changes in evidence reliability and observability, including discounting unreliable evidence, seeking to resolve partial information, and dissociating between task completion and causal generalization, while tending to over-observe and over-comply relative to children.
What carries the argument
The Box Task formalized as program induction with Bayesian particle-based inference, viewed either as constraint satisfaction over hypotheses or as synthesis of executable programs evaluated against evidence.
If this is right
- Children's evidence-seeking arises from subjective reliability judgments during ongoing hypothesis generation.
- LLM agents can function as controllable model organisms for testing how inference changes with task conditions like observability.
- Both groups separate completing the immediate task from achieving causal generalization under uncertainty.
- Discounting of unreliable evidence occurs in both children and LLMs when reliability cues are present.
Where Pith is reading between the lines
- The similarity in adaptation patterns suggests LLMs could act as proxies for exploring developmental inference mechanisms under controlled manipulations.
- Differences in observation volume point to distinct internal costs for information-seeking between children and current LLMs.
- The dual formalization may allow the same task to probe other forms of uncertainty beyond evidence reliability.
Load-bearing premise
The Box Task and its formalization as program induction with Bayesian particle-based inference provide a faithful model of the underlying inductive processes used by both children and LLM agents.
What would settle it
If children in the Box Task fail to discount unreliable evidence or show no dissociation between task completion and rule generalization when evidence reliability is manipulated, the proposed explanation would not hold.
Figures
read the original abstract
Real world decision-making requires constructing mental models under uncertainty over evidence, over the underlying causal rules, and over the state of the world itself. Which computational principles underpin human inference under such conditions, and do LLM-based agents exhibit similar behavior given matching constraints? We address these questions using an inductive inference Box Task in which participants, human children and LLM-based agents, infer a latent cause through sequential interaction with an uncertain environment. We formalize this task as program induction with Bayesian particle-based inference, admitting two complementary interpretations: (1) as a constraint satisfaction process over hypotheses, and (2) as a program synthesis problem in which hypotheses are executable programs evaluated against evidence. Using the constraint-based formulation, we show that children's behavior is best explained by a combination of subjective evidence reliability and online hypothesis generation, accounting for both their evidence-seeking patterns and their dissociation between task completion and rule generalization. Using the program synthesis formulation, we treat LLM-based agents as model organisms: controllable systems that allow systematic manipulation of task conditions. Across backends, LLM-based agents replicate children's responses to changes in evidence reliability and observability, including discounting unreliable evidence, seeking to resolve partial information, and dissociating between task completion and causal generalization. At the same time, LLM-based agents tend to over-observe and over-comply with instructions relative to children. These results suggest that while children and LLM-based agents adapt similarly to environmental structure, their information-seeking behavior exhibits distinct underlying costs and inductive biases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Box Task for studying inductive inference under uncertainty, formalizing it as program induction via Bayesian particle-based inference with dual interpretations as constraint satisfaction over hypotheses and as executable program synthesis. It claims that children's sequential evidence-seeking and generalization behavior is best explained by subjective evidence reliability combined with online hypothesis generation, and that LLM-based agents, treated as model organisms, replicate children's responses to manipulations of evidence reliability and observability (discounting unreliable evidence, resolving partial information, dissociating task completion from causal generalization) while over-observing and over-complying relative to children.
Significance. If the formalization and behavioral mappings hold, the work offers a computational account of inductive processes in children and establishes LLMs as controllable systems for testing cognitive hypotheses, with the program-synthesis view enabling systematic condition manipulations. The explicit dual formalization and focus on information-seeking costs versus inductive biases are strengths that could inform both developmental psychology and AI alignment research.
major comments (3)
- [Abstract and §3] Abstract and §3 (constraint-based formulation): The claim that children's behavior is 'best explained' by subjective evidence reliability plus online hypothesis generation is load-bearing for the central contribution, yet the manuscript provides no quantitative model-comparison results, likelihood ratios, or alternative baselines (e.g., standard Bayesian updating without online generation or fixed-reliability models) to establish superiority over other accounts.
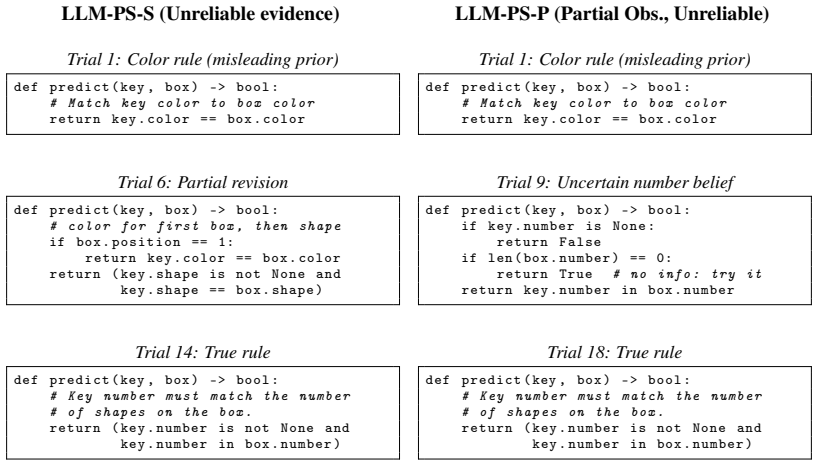
- [Abstract and Results] Abstract and Results (program-synthesis formulation): The assertion that LLM agents replicate children's responses to evidence reliability and observability changes rests on the assumption that the particle-filter hypothesis space and evidence-weighting dynamics match the effective computation in prompted LLMs; without reported process-level validation, ablation of the particle filter, or comparison to non-Bayesian LLM prompting strategies, the replication claim does not yet follow from the observed behavioral matches.
- [Methods] Methods (Box Task formalization): The load-bearing modeling assumption that the Box Task and its Bayesian particle-based program-induction formalization faithfully capture the inductive processes of both children and LLMs lacks reported checks against confounds such as verbal-report alignment, eye-movement data, or alternative task decompositions; if this mapping does not hold, neither the 'best explanation' nor the cross-agent replication conclusions are secured.
minor comments (2)
- [Abstract] Abstract: 'Across backends' is stated without naming the specific LLM families or versions used, which limits reproducibility assessment.
- [Results] The dissociation between task completion and causal generalization is described qualitatively; a table or figure quantifying the effect sizes across conditions would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our modeling and claims. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (constraint-based formulation): The claim that children's behavior is 'best explained' by subjective evidence reliability plus online hypothesis generation is load-bearing for the central contribution, yet the manuscript provides no quantitative model-comparison results, likelihood ratios, or alternative baselines (e.g., standard Bayesian updating without online generation or fixed-reliability models) to establish superiority over other accounts.
Authors: We agree that the 'best explained' phrasing would be strengthened by quantitative comparisons. The current results show that the model accounts for sequential evidence-seeking and the observed dissociation between task completion and generalization—patterns not predicted by standard Bayesian updating without online generation. In revision we will add likelihood-based model comparisons against the suggested baselines (fixed-reliability and non-online variants) to provide the requested quantitative support. revision: yes
-
Referee: [Abstract and Results] Abstract and Results (program-synthesis formulation): The assertion that LLM agents replicate children's responses to evidence reliability and observability changes rests on the assumption that the particle-filter hypothesis space and evidence-weighting dynamics match the effective computation in prompted LLMs; without reported process-level validation, ablation of the particle filter, or comparison to non-Bayesian LLM prompting strategies, the replication claim does not yet follow from the observed behavioral matches.
Authors: The replication claim is restricted to behavioral outcomes under identical task manipulations. We did not conduct process-level validation or ablations because prompted LLMs do not expose internal hypothesis spaces or particle-filter dynamics. We will revise the text to clarify that the reported matches are behavioral only, to discuss the limitations of this approach, and to note the absence of comparisons to non-Bayesian prompting strategies. revision: partial
-
Referee: [Methods] Methods (Box Task formalization): The load-bearing modeling assumption that the Box Task and its Bayesian particle-based program-induction formalization faithfully capture the inductive processes of both children and LLMs lacks reported checks against confounds such as verbal-report alignment, eye-movement data, or alternative task decompositions; if this mapping does not hold, neither the 'best explanation' nor the cross-agent replication conclusions are secured.
Authors: The formalization is supported by its ability to generate precise, testable predictions that match the key empirical dissociations in both populations. The study did not collect eye-movement data or additional verbal-report alignment measures. We will expand the Methods and Discussion sections to address potential confounds explicitly and to clarify the scope of the mapping, while acknowledging that direct process-level checks remain for future work. revision: partial
Circularity Check
No circularity: modeling choice and behavioral comparison are independent of target claims
full rationale
The paper selects a formalization (program induction + Bayesian particle filter) as an interpretive lens for the Box Task, then reports how children's and LLM agents' observed behavior aligns with predictions from that lens under manipulated evidence reliability and observability. This is a standard modeling assumption followed by empirical comparison, not a self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations, uniqueness theorems, or ansatzes are shown reducing the central claims to their own inputs by construction. The derivation chain therefore remains self-contained against external behavioral data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Using games to understand the mind.Nature human behaviour, 8(6):1035–1043, 2024
Kelsey Allen, Franziska Brändle, Matthew Botvinick, Judith E Fan, Samuel J Gershman, Alison Gopnik, Thomas L Griffiths, Joshua K Hartshorne, Tobias U Hauser, Mark K Ho, et al. Using games to understand the mind.Nature human behaviour, 8(6):1035–1043, 2024
2024
-
[2]
DeepCoder: Learning to Write Programs
Matej Balog, Alexander L Gaunt, Marc Brockschmidt, Sebastian Nowozin, and Daniel Tarlow. Deepcoder: Learning to write programs.arXiv preprint arXiv:1611.01989, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Win-stay, lose-sample: A simple sequential algorithm for approximating bayesian inference.Cognitive psychology, 74:35–65, 2014
Elizabeth Bonawitz, Stephanie Denison, Alison Gopnik, and Thomas L Griffiths. Win-stay, lose-sample: A simple sequential algorithm for approximating bayesian inference.Cognitive psychology, 74:35–65, 2014
2014
-
[4]
Probabilistic models, learning algorithms, and response variability: sampling in cognitive development.Trends in cognitive sciences, 18(10):497–500, 2014
Elizabeth Bonawitz, Stephanie Denison, Thomas L Griffiths, and Alison Gopnik. Probabilistic models, learning algorithms, and response variability: sampling in cognitive development.Trends in cognitive sciences, 18(10):497–500, 2014
2014
-
[5]
Active inductive inference in children and adults: A constructivist perspective
Neil R Bramley and Fei Xu. Active inductive inference in children and adults: A constructivist perspective. Cognition, 238:105471, 2023
2023
-
[6]
Formalizing neurath’s ship: Approximate algorithms for online causal learning.Psychological review, 124(3):301, 2017
Neil R Bramley, Peter Dayan, Thomas L Griffiths, and David A Lagnado. Formalizing neurath’s ship: Approximate algorithms for online causal learning.Psychological review, 124(3):301, 2017
2017
-
[7]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.CoRR, abs/1911.01547, 2019. URL http://arxiv. org/abs/1911.01547
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[8]
Building machines that learn and think with people.Nature human behaviour, 8(10):1851–1863, 2024
Katherine M Collins, Ilia Sucholutsky, Umang Bhatt, Kartik Chandra, Lionel Wong, Mina Lee, Cedegao E Zhang, Tan Zhi-Xuan, Mark Ho, Vikash Mansinghka, et al. Building machines that learn and think with people.Nature human behaviour, 8(10):1851–1863, 2024. 10
2024
-
[9]
Generating code world models with large language models guided by monte carlo tree search
Nicola Dainese, Matteo Merler, Minttu Alakuijala, and Pekka Marttinen. Generating code world models with large language models guided by monte carlo tree search. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://arxiv.org/abs/2405.15383
-
[10]
Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. Sequential monte carlo samplers.Journal of the Royal Statistical Society Series B: Statistical Methodology, 68(3):411–436, 05 2006. ISSN 1369-7412. doi: 10. 1111/j.1467-9868.2006.00553.x. URLhttps://doi.org/10.1111/j.1467-9868.2006.00553.x
-
[11]
Rational variability in children’s causal inferences: The sampling hypothesis.Cognition, 126(2):285–300, 2013
Stephanie Denison, Elizabeth Bonawitz, Alison Gopnik, and Thomas L Griffiths. Rational variability in children’s causal inferences: The sampling hypothesis.Cognition, 126(2):285–300, 2013
2013
-
[12]
Openly accessible llms can help us to understand human cognition.Nature Human Behaviour, 7(11):1825–1827, 2023
Michael C Frank. Openly accessible llms can help us to understand human cognition.Nature Human Behaviour, 7(11):1825–1827, 2023
2023
-
[13]
A rational analysis of rule-based concept learning.Cognitive science, 32(1):108–154, 2008
Noah D Goodman, Joshua B Tenenbaum, Jacob Feldman, and Thomas L Griffiths. A rational analysis of rule-based concept learning.Cognitive science, 32(1):108–154, 2008
2008
-
[14]
Childhood as a solution to explore–exploit tensions.Philosophical Transactions of the Royal Society B, 375(1803):20190502, 2020
Alison Gopnik. Childhood as a solution to explore–exploit tensions.Philosophical Transactions of the Royal Society B, 375(1803):20190502, 2020
2020
-
[15]
A theory of causal learning in children: causal maps and bayes nets.Psychological review, 111(1):3, 2004
Alison Gopnik, Clark Glymour, David M Sobel, Laura E Schulz, Tamar Kushnir, and David Danks. A theory of causal learning in children: causal maps and bayes nets.Psychological review, 111(1):3, 2004
2004
-
[16]
Bayesian inference.The Oxford handbook of thinking and reasoning, pages 22–35, 2012
Thomas L Griffiths, Joshua B Tenenbaum, and Charles Kemp. Bayesian inference.The Oxford handbook of thinking and reasoning, pages 22–35, 2012
2012
-
[17]
Sumit Gulwani. Automating string processing in spreadsheets using input-output examples.SIGPLAN Not., 46(1):317–330, January 2011. ISSN 0362-1340. doi: 10.1145/1925844.1926423. URL https: //doi.org/10.1145/1925844.1926423
-
[18]
Muggleton, Ute Schmid, and Benjamin Zorn
Sumit Gulwani, José Hernández-Orallo, Emanuel Kitzelmann, Stephen H. Muggleton, Ute Schmid, and Benjamin Zorn. Inductive programming meets the real world.Commun. ACM, 58(11):90–99, October
-
[19]
ISSN 0001-0782. doi: 10.1145/2736282. URLhttps://doi.org/10.1145/2736282
-
[20]
Number 6
Philip Nicholas Johnson-Laird.Mental models: Towards a cognitive science of language, inference, and consciousness. Number 6. Harvard University Press, 1983
1983
-
[21]
Littman, and Anthony R
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1-2):99–134, 1998
1998
-
[22]
Structured statistical models of inductive reasoning.Psychological review, 116(1):20, 2009
Charles Kemp and Joshua B Tenenbaum. Structured statistical models of inductive reasoning.Psychological review, 116(1):20, 2009
2009
-
[23]
Human-level concept learning through probabilistic program induction.Science, 350(6266):1332–1338, 2015
Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum. Human-level concept learning through probabilistic program induction.Science, 350(6266):1332–1338, 2015
2015
-
[24]
Is programming by example solved by llms? InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA,
Wen-Ding Li and Kevin Ellis. Is programming by example solved by llms? InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA,
-
[25]
ISBN 9798331314385
Curran Associates Inc. ISBN 9798331314385
-
[26]
On a measure of the information provided by an experiment.The Annals of Mathematical Statistics, 27(4):986–1005, 1956
Dennis V Lindley. On a measure of the information provided by an experiment.The Annals of Mathematical Statistics, 27(4):986–1005, 1956
1956
-
[27]
David Marr.Vision: A Computational Investigation into the Human Representation and Processing of Visual Information. W. H. Freeman, 1982
1982
-
[28]
PhD thesis, MIT, 2011
Steven Thomas Piantadosi.Learning and the language of thought. PhD thesis, MIT, 2011
2011
-
[29]
Doing experiments and revising rules with natural language and probabilistic reasoning.Advances in Neural Information Processing Systems, 37:53102–53137, 2024
Top Piriyakulkij, Cassidy Langenfeld, Tuan Anh Le, and Kevin Ellis. Doing experiments and revising rules with natural language and probabilistic reasoning.Advances in Neural Information Processing Systems, 37:53102–53137, 2024
2024
-
[30]
Poe-world: Compositional world modeling with products of programmatic experts.Advances in Neural Information Processing Systems (NeurIPS), 2025
Wasu Top Piriyakulkij, Yichao Liang, Hao Tang, Adrian Weller, Marta Kryven, and Kevin Ellis. Poe-world: Compositional world modeling with products of programmatic experts.Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[31]
Phenomenal yet puzzling: Testing inductive reasoning capabilities of language models with hypothesis refinement
Linlu Qiu, Liwei Jiang, Ximing Lu, Melanie Sclar, Valentina Pyatkin, Chandra Bhagavatula, Bailin Wang, Yoon Kim, Yejin Choi, Nouha Dziri, and Xiang Ren. Phenomenal yet puzzling: Testing inductive reasoning capabilities of language models with hypothesis refinement. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openre...
2024
-
[32]
Girls persist more but divest less from ineffective teaching than boys.Journal of Experimental Psychology: General, 2024
Mia Radovanovic, Ece Yucer, and Jessica A Sommerville. Girls persist more but divest less from ineffective teaching than boys.Journal of Experimental Psychology: General, 2024
2024
-
[33]
Modern bayesian experimental design.Statistical Science, 39(1):100–114, 2024
Tom Rainforth, Adam Foster, Desi R Ivanova, and Freddie Bickford Smith. Modern bayesian experimental design.Statistical Science, 39(1):100–114, 2024
2024
-
[34]
PhD thesis, Massachusetts Institute of Technology, 2020
Joshua Stewart Rule.The child as hacker: building more human-like models of learning. PhD thesis, Massachusetts Institute of Technology, 2020
2020
-
[35]
A behavioral model of rational choice.The quarterly journal of economics, pages 99–118, 1955
Herbert A Simon. A behavioral model of rational choice.The quarterly journal of economics, pages 99–118, 1955
1955
-
[36]
Oxford University Press, 2023
Christopher Summerfield.Natural General Intelligence: How understanding the brain can help us build AI. Oxford University Press, 2023
2023
-
[37]
Hao Tang, Darren Key, and Kevin Ellis. Worldcoder, a model-based llm agent: Building world models by writing code and interacting with the environment.Advances in Neural Information Processing Systems, 37:70148–70212, 2024
2024
-
[38]
Tasks for aligning human and machine planning.Current Opinion in Behavioral Sciences, 29:127–133, 2019
Bas van Opheusden and Wei Ji Ma. Tasks for aligning human and machine planning.Current Opinion in Behavioral Sciences, 29:127–133, 2019
2019
-
[39]
One and done? optimal decisions from very few samples.Cognitive science, 38(4):599–637, 2014
Edward Vul, Noah Goodman, Thomas L Griffiths, and Joshua B Tenenbaum. One and done? optimal decisions from very few samples.Cognitive science, 38(4):599–637, 2014
2014
-
[40]
Hypothesis search: Inductive reasoning with language models
Ruocheng Wang, Eric Zelikman, Gabriel Poesia, Yewen Pu, Nick Haber, and Noah Goodman. Hypothesis search: Inductive reasoning with language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=G7UtIGQmjm
2024
-
[41]
Re- Act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Irina Shafran, Karthik Narasimhan, and Yuan Cao. Re- Act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[42]
Lance Ying, Katherine M Collins, Prafull Sharma, Cedric Colas, Kaiya Ivy Zhao, Adrian Weller, Zenna Tavares, Phillip Isola, Samuel J Gershman, Jacob D Andreas, et al. Assessing adaptive world models in machines with novel games.URL https://arxiv.org/abs/2507.12821, 2025. A The Box Task Setup The Box Task environment is introduced in [30]. Below we summari...
-
[43]
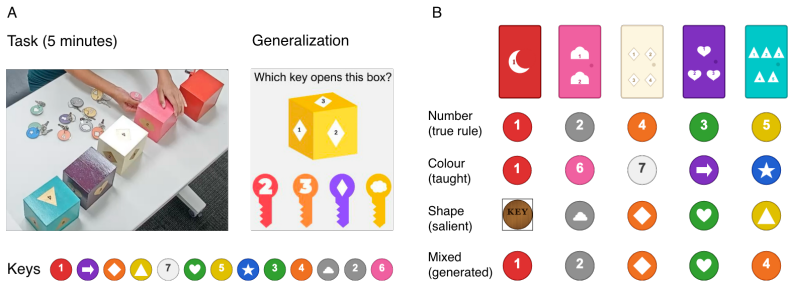
Practice: Participants tried plain keys on a plain practice box to familiarize themselves with the key action, including both correct and incorrect keys
-
[44]
This demonstration was confounded: for the red box only, the correct key happened to match both color and number
Instruction: Children viewed an instructional video in which a teacher demonstrated an in- correct color-matching rule, using a red-fobbed key to open the red box. This demonstration was confounded: for the red box only, the correct key happened to match both color and number. For all other boxes, color-matched keys were incorrect. The teacher communicate...
-
[45]
All 13 keys were placed in a single pile
Test: The five boxes were arranged in a fixed order in front of the participant. All 13 keys were placed in a single pile. Children were instructed to open all five boxes within a 5-minute time limit, working independently. The experimenter remained present but provided no feedback. Boxes could be picked up and examined. The test ended upon opening all fi...
-
[46]
1" and "2
Generalization: Four forced-choice trials using novel box images were presented on a tablet screen. For each box, four keys were presented: a color-matched key, a shape-matched key, a number-matched key (correct), and a number foil. Children selected which key they believed would open the box. 12 Box Task Environment.The boxes were uniquely colored physic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.