SemanticZip: A Pilot Framework for Lossy Text Compression with LLMs as Semantic Decompressors
Pith reviewed 2026-06-30 14:41 UTC · model grok-4.3
The pith
SemanticZip introduces lossy text compression where LLMs decompress compact codes to recover task-relevant semantic commitments while protecting exact parts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that LLM-mediated decompression can be formalized using a protected/lossy packet architecture, allowing evaluation of recoverability across representation regimes, and that the viable approach is to keep safety-critical commitments protected while semantically zipping predictable low-risk context.
What carries the argument
The protected/lossy packet architecture that separates exact safety-critical text from compressible semantic codes decompressed by an LLM.
If this is right
- Task-relevant semantic commitments can be recovered with weighted atom recall above 0.8 in several tested regimes.
- Token reductions of 19% to 46% are achievable depending on the representation chosen.
- Safety-critical text remains unchanged while low-risk context is replaced by compact codes.
- The framework provides metrics like Critical Atom Recall and tokenizer gain for comparing different codes.
- Different formats such as prose, JSON, and emoji yield distinct trade-offs between compression and fidelity.
Where Pith is reading between the lines
- Applying the protected/lossy split to real documents like reports or logs could reduce storage while maintaining key facts.
- Future tests on diverse, non-author-constructed texts would check if the observed recoverability holds more broadly.
- The method might integrate with retrieval systems where only semantic summaries are stored for context.
- Risk assessment models could automatically decide which parts of text to protect versus zip.
Load-bearing premise
The five author-constructed diagnostic cases are representative enough to evaluate recoverability of task-relevant semantic commitments across the six representation regimes.
What would settle it
If evaluations on a broader set of independently created documents show that no representation regime achieves weighted atom recall above 0.7 while providing meaningful token savings, the practical utility of the framework would be called into question.
Figures
read the original abstract
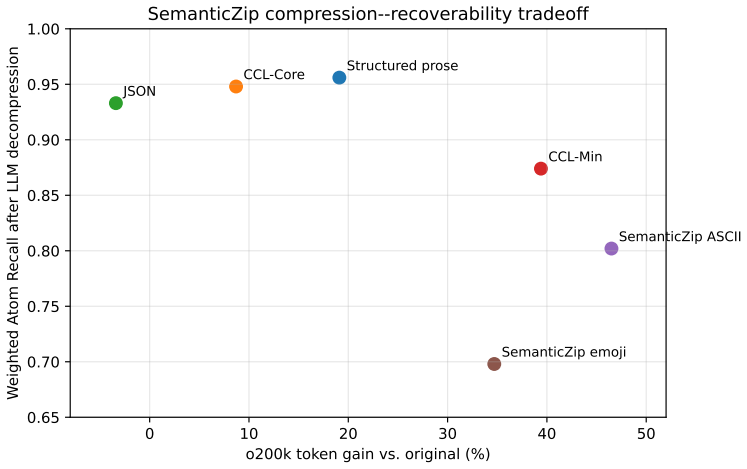
Text compression for large language model (LLM) systems is usually framed as token deletion, retrieval, summarization, or exact reconstruction. We study a more aggressive but explicitly lossy setting: compress text into compact codes that an LLM can expand into task-relevant meaning. We call this setting SemanticZip. Unlike lossless compression, SemanticZip does not require byte-identical reconstruction; unlike ordinary summarization, it treats model-based decompression as part of the codec and evaluates whether task-relevant semantic commitments are recovered. This paper is a pilot framework, not a benchmark claim. We formalize LLM-mediated decompression, define a protected/lossy packet architecture, and evaluate six representation regimes over five author-constructed diagnostic cases: structured prose, JSON, CCL-Core, CCL-Min, SemanticZip ASCII, and SemanticZip emoji. An independent decoder LLM reconstructs typed semantic atoms from each compressed representation, and we score Critical Atom Recall, Weighted Atom Recall, precision, and tokenizer gain. In this pilot, structured prose has the highest recoverability, with WAR = 0.956 and 19.1% o200k_base token gain. CCL-Min is the strongest balanced point, with 39.4% token gain and WAR = 0.874. SemanticZip ASCII provides the largest useful compression, with 46.5% token gain and WAR = 0.802, while emoji-heavy SemanticZip performs worse on both compression and recovery. The main contribution is not the claim that these numbers establish a universal frontier. Rather, we introduce a reproducible experimental interface for studying lossy, LLM-decompressible text codes and a design principle: safety-critical and exact commitments should remain protected, while predictable low-risk context may be semantically zipped.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce SemanticZip, a pilot framework for lossy text compression where LLMs serve as semantic decompressors. It formalizes the decompression process, defines a protected/lossy packet architecture, and evaluates six representation regimes (structured prose, JSON, CCL-Core, CCL-Min, SemanticZip ASCII, SemanticZip emoji) across five author-constructed diagnostic cases. Metrics reported include Critical Atom Recall, Weighted Atom Recall (WAR), precision, and tokenizer gain. Structured prose achieves the highest WAR of 0.956 with 19.1% token gain, while SemanticZip ASCII offers 46.5% gain with WAR 0.802. The primary contribution is positioned as a reproducible experimental interface and the design principle that safety-critical commitments should be protected while low-risk context can be semantically zipped.
Significance. If the framework holds, it offers a novel approach to studying lossy compression tailored for LLM systems by treating decompression as part of the codec. This could be significant for developing efficient context management strategies in LLM applications. The work explicitly frames itself as a pilot without claiming generalizability, which strengthens its position. Credit is given for providing a reproducible experimental interface and a clear design principle separating protected and lossy packets. The evaluation on diagnostic cases demonstrates the concept without overclaiming.
minor comments (2)
- [Abstract] Abstract: the notation '19.1% o200k_base token gain' is unclear; specify the tokenizer or base model referenced (e.g., gpt-4o-200k).
- Ensure acronyms such as CCL-Core and CCL-Min are expanded on first use in the main body, as they are not defined in the abstract.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work as a pilot framework, for crediting the reproducible experimental interface and the protected/lossy packet design principle, and for recommending minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The paper is a pilot framework that introduces a reproducible experimental interface and a protected/lossy packet design principle. It evaluates six representation regimes on five author-constructed diagnostic cases using explicitly defined metrics (Critical Atom Recall, WAR, etc.) without equations, derivations, fitted-parameter predictions, or self-citations. The contribution is scoped to the interface and principle rather than any generalization claim, so no load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
protected/lossy packet architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Schmidt, Jesse Spencer-Smith, and Jules White
Henry Gilbert, Michael Sandborn, Douglas C. Schmidt, Jesse Spencer-Smith, and Jules White. Semantic compression with large language models. arXiv preprint arXiv:2304.12512, 2023. https://arxiv. org/abs/2304.12512
-
[2]
Language Modeling Is Compression
Gr´egoire Del´etang, Anian Ruoss, Paul-Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, Marcus Hutter, and Joel Veness. Language modeling is compression. arXiv preprint arXiv:2309.10668, 2023. https: //arxiv.org/abs/2309.10668
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
LLMLingua: Compressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LLMLingua: Compressing prompts for accelerated inference of large language models. InProceedings of EMNLP, 2023. https: //aclanthology.org/2023.emnlp-main.825/
2023
-
[4]
LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. InProceedings of ACL, 2024.https://arxiv.org/abs/2310.06839
-
[5]
Selective Context: Compress your input to ChatGPT or other LLMs
Yucheng Li. Selective Context: Compress your input to ChatGPT or other LLMs. 2023. https: //github.com/liyucheng09/Selective_Context
2023
-
[6]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. https://aclanthology.org/2024.tacl-1. 9/
2024
-
[7]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, Sebastian Riedel, and Douwe Kiela. 12 Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, 2020.https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560, 2023. https: //arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Natalia Trukhina and Vadim Vashkelis. Compress the context, keep the commitments: A formal framework for verifiable LLM context compression. arXiv preprint arXiv:2605.17304, 2026. https: //arxiv.org/abs/2605.17304
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
JSON Schema validation: A vocabulary for structural valida- tion of JSON
JSON Schema Organization. JSON Schema validation: A vocabulary for structural valida- tion of JSON. Draft 2020-12, 2020. https://json-schema.org/draft/2020-12/ json-schema-validation
2020
-
[11]
JavaScript Object Notation (JSON) Patch
Paul Bryan and Mark Nottingham. JavaScript Object Notation (JSON) Patch. RFC 6902, Internet Engineering Task Force, 2013.https://datatracker.ietf.org/doc/html/rfc6902
2013
-
[12]
Tuning the decision threshold for class prediction
Scikit-learn developers. Tuning the decision threshold for class prediction. scikit- learn User Guide. https://scikit-learn.org/stable/modules/classification_ threshold.html
-
[13]
Jesse Dodge, Suchin Gururangan, Dallas Card, Roy Schwartz, and Noah A. Smith. Show your work: Improved reporting of experimental results.EMNLP-IJCNLP, 2019. See also NLP Reproducibility Checklist. https://www.jessedodge.ai/NLP_Reproducibility_Checklist_V1.2. pdf
2019
-
[14]
Reproducibility in NLP: What have we learned from the checklist?Findings of ACL, 2023
Ian Magnusson, Akshita Bhagia, Valentin Hofmann, Luca Soldaini, Oyvind Tafjord, Peter West, Kyle Lo, Dirk Groeneveld, Kyle Richardson, Ashish Sabharwal, Iz Beltagy, and Jesse Dodge. Reproducibility in NLP: What have we learned from the checklist?Findings of ACL, 2023. https://aclanthology. org/2023.findings-acl.809/
2023
-
[15]
Beyond accuracy: Behav- ioral testing of NLP models with CheckList.ACL, 2020
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behav- ioral testing of NLP models with CheckList.ACL, 2020. https://aclanthology.org/2020. acl-main.442/. 13
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.