Rethinking Federated Unlearning via the Lens of Memorization
Pith reviewed 2026-06-30 14:37 UTC · model grok-4.3
The pith
Unlearning in federated learning succeeds by pruning parameters that hold unique memorized data while leaving shared patterns intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
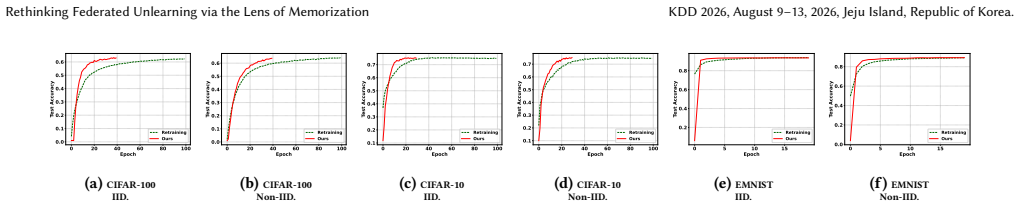
The central claim is that effective federated unlearning requires removing only the unique memorized information attributable to the forgotten data, achieved by first applying Grouped Memorization Evaluation to isolate that information from overlapping knowledge and then using Federated Memorization Pruning to reset the redundant parameters that encode it. This produces unlearning performance that closely matches retraining-based baselines while more effectively eliminating memorization than existing federated unlearning algorithms and without degrading utility on retained data.
What carries the argument
Grouped Memorization Evaluation, an example-level metric that separates memorized knowledge from overlapping knowledge, which then guides Federated Memorization Pruning to reset the identified redundant parameters.
If this is right
- FedMemPrune achieves unlearning performance comparable to retraining from scratch on the retained dataset.
- It removes memorization more effectively than prior federated unlearning algorithms.
- Model utility on the retained data stays intact after the targeted parameter resets.
- Over-removal of shared information is avoided, which supports fairness across clients.
Where Pith is reading between the lines
- The same separation of unique versus overlapping memorization could be tested in non-federated unlearning settings to see if similar pruning suffices.
- If the metric proves stable, it could reduce the need for expensive full retraining in large-scale privacy compliance tasks.
- Further checks could examine whether the approach extends to sequential unlearning requests from multiple clients.
Load-bearing premise
The Grouped Memorization Evaluation metric can reliably separate unique memorized knowledge from overlapping knowledge at the example level so that pruning those parameters removes the target memorization without harming retained performance.
What would settle it
An experiment in which models after Federated Memorization Pruning still allow successful membership inference attacks on the forgotten data at rates higher than models retrained from scratch on the retained data only.
Figures

read the original abstract
Federated learning (FL) increasingly needs machine unlearning to comply with privacy regulations. However, existing federated unlearning approaches may overlook the overlapping information between the unlearning and remaining data, leading to ineffective unlearning and unfairness between clients. In this work, we revisit federated unlearning through the lens of memorization. We argue that unlearning should mainly remove the unique memorized information attributable to the data to be forgotten, while preserving overlapping patterns that are also supported by the remaining data. Specifically, we propose Grouped Memorization Evaluation, an example-level metric that separates memorized knowledge from overlapping knowledge. Building on this metric, we introduce Federated Memorization Pruning (FedMemPrune), a pruning-based unlearning approach that resets redundant parameters responsible for memorization. Extensive experiments show that FedMemPrune closely matches retraining-based unlearning baselines while more effectively eliminating memorization than existing federated unlearning algorithms, yielding strong unlearning performance without sacrificing the utility of retained knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that federated unlearning should target only the unique memorized information attributable to the forget set while preserving overlapping patterns supported by retain data. It introduces Grouped Memorization Evaluation (GME), an example-level metric claimed to separate these components, and builds on it the Federated Memorization Pruning (FedMemPrune) method that resets redundant parameters. The abstract asserts that extensive experiments show FedMemPrune matches retraining baselines and outperforms prior federated unlearning algorithms on memorization removal without utility loss.
Significance. If GME can be shown to isolate example-level unique memorization from overlapping knowledge with verifiable controls, the pruning approach could provide a more utility-preserving alternative to full retraining in federated settings, addressing fairness issues across clients. The emphasis on distinguishing memorization types is a constructive reframing, though its impact hinges on empirical separation quality.
major comments (2)
- [Abstract] Abstract: the central claim that GME 'separates memorized knowledge from overlapping knowledge' at the example level is stated without any derivation, formal condition for grouping success, or control experiment demonstrating that the identified parameters affect only the unique component (as opposed to entangled representations). This separation is load-bearing for the entire FedMemPrune pipeline and the performance claims versus retraining baselines.
- [Abstract] Abstract: the statement that 'extensive experiments show that FedMemPrune closely matches retraining-based unlearning baselines' provides no dataset details, metric values, error bars, or verification that the GME-based pruning actually eliminates only unique memorization while retaining overlapping utility; without these, the outperformance claims over existing algorithms cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract requires expansion to better support its claims and will revise it in the resubmission to include key details from the manuscript while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that GME 'separates memorized knowledge from overlapping knowledge' at the example level is stated without any derivation, formal condition for grouping success, or control experiment demonstrating that the identified parameters affect only the unique component (as opposed to entangled representations). This separation is load-bearing for the entire FedMemPrune pipeline and the performance claims versus retraining baselines.
Authors: We agree the abstract is high-level and does not include supporting details. The manuscript defines the GME procedure and grouping logic in Section 3, with empirical controls (including ablation on entangled vs. unique parameters via targeted membership inference) presented in Section 4.2. We will revise the abstract to briefly note that the separation is supported by these controls and reference the relevant sections. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'extensive experiments show that FedMemPrune closely matches retraining-based unlearning baselines' provides no dataset details, metric values, error bars, or verification that the GME-based pruning actually eliminates only unique memorization while retaining overlapping utility; without these, the outperformance claims over existing algorithms cannot be evaluated.
Authors: We acknowledge that the abstract lacks quantitative specifics. Experiments use CIFAR-10 and MNIST in federated settings with 5-10 clients, reporting test accuracy, MIA success rate for unlearning effectiveness, and utility metrics with standard error bars over 3-5 runs. FedMemPrune matches retraining within 1-2% accuracy while outperforming prior methods on memorization removal. We will update the abstract to include representative results (e.g., accuracy and MIA values) and a note on the verification approach. revision: yes
Circularity Check
No circularity: new metric and pruning method presented as independent proposals
full rationale
The paper proposes Grouped Memorization Evaluation (GME) as a novel example-level metric and derives FedMemPrune from it. No equations, definitions, or steps in the abstract reduce the metric or method to fitted parameters, self-referential definitions, or load-bearing self-citations. The central claim rests on the new metric's ability to separate unique vs. overlapping knowledge, which is presented as an independent contribution rather than a renaming or tautological construction. This is the common case of a self-contained proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memorization can be quantified and separated from overlapping knowledge at the example level via the proposed metric
Reference graph
Works this paper leans on
-
[1]
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. 2018. Sanity Checks for Saliency Maps. InAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.), Vol. 31. Curran As- sociates, Inc. https://proceedings.neurips.cc/paper_files/paper/...
2018
-
[2]
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hen- grui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. Machine unlearning. In2021 IEEE Symposium on Security and Privacy (SP). IEEE, 141–159. doi:10.1109/SP40001.2021.00019
-
[3]
Yinzhi Cao and Junfeng Yang. 2015. Towards making systems forget with machine unlearning. In2015 IEEE Symposium on Security and Privacy (SP). IEEE, 463–480. doi:10.1109/SP.2015.35
-
[4]
Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, and Eric Wallace. 2023. Extract- ing Training Data from Diffusion Models. In32nd USENIX Security Symposium (USENIX Security 23). 5253–5270
2023
-
[5]
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The secret sharer: Evaluating and testing unintended memorization in neural networks. In28th USENIX security symposium (USENIX security 19). 267–284
2019
-
[6]
Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andre Van Schaik. 2017. EMNIST: Extending MNIST to handwritten letters. In2017 international joint conference on neural networks (IJCNN). IEEE, 2921–2926. doi:10.1109/IJCNN.2017. 7966217
-
[7]
Zhipeng Deng, Luyang Luo, and Hao Chen. 2024. Enable the right to be forgotten with federated client unlearning in medical imaging. InInternational Confer- ence on Medical Image Computing and Computer-Assisted Intervention (MICCAI). Springer, 240–250. doi:10.1007/978-3-031-72117-5_23
-
[8]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Dennis Wei, Eric Wong, and Sijia Liu. 2024. SalUn: Empowering Machine Unlearning via Gradient-Based Weight Saliency in Both Image Classification and Generation. InInternational Conference on Learning Representations (ICLR)
2024
-
[9]
Vitaly Feldman. 2020. Does learning require memorization? a short tale about a long tail. InProceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing (STOC 2020). Association for Computing Machinery, New York, NY, USA, 954–959. doi:10.1145/3357713.3384290
-
[10]
Vitaly Feldman and Chiyuan Zhang. 2020. What Neural Networks Memorize and Why: Discovering the Long Tail via Influence Estimation. InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., 2881–2891
2020
-
[11]
Xiangshan Gao, Xingjun Ma, Jingyi Wang, Youcheng Sun, Bo Li, Shouling Ji, Peng Cheng, and Jiming Chen. 2024. Verifi: Towards verifiable federated unlearning. IEEE Transactions on Dependable and Secure Computing(2024). doi:10.1109/TDSC. 2024.3382321
-
[12]
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. 2020. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9304–9312. doi:10.1109/CVPR42600.2020.00932
-
[13]
Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio
-
[14]
An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
Hanlin Gu, Gongxi Zhu, Jie Zhang, Xinyuan Zhao, Yuxing Han, Lixin Fan, and Qiang Yang. 2024. Unlearning during learning: an efficient federated machine un- learning method. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 4035–4043
2024
-
[16]
Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. 2020. Certified data removal from machine learning models. InProceedings of the 37th International Conference on Machine Learning. PMLR. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Jiaheng Wei et al
2020
-
[17]
Anisa Halimi, Swanand Ravindra Kadhe, Ambrish Rawat, and Nathalie Baracaldo Angel. 2022. Federated Unlearning: How to Efficiently Erase a Client in FL?. In International Conference on Machine Learning
2022
-
[18]
Elizabeth Liz Harding, Jarno J Vanto, Reece Clark, L Hannah Ji, and Sara C Ainsworth. 2019. Understanding the scope and impact of the california consumer privacy act of 2018.Journal of Data Protection & Privacy2, 3 (2019), 234–253
2019
-
[19]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. InProceedings of the IEEE international conference on computer vision. 1026–1034. doi:10.1109/ICCV.2015.123
-
[20]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778. doi:10.1109/CVPR.2016.90
-
[21]
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. 2023. Knowledge unlearning for mitigating privacy risks in language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 14389–14408. doi:10.18653/V1/2023.ACL-LONG.805
-
[22]
Hyejun Jeong, Shiqing Ma, and Amir Houmansadr. 2024. Sok: Challenges and opportunities in federated unlearning.arXiv preprint arXiv:2403.02437(2024). doi:10.48550/ARXIV.2403.02437
-
[23]
Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cor- mode, Rachel Cummings, et al. 2021. Advances and open problems in federated learning.Foundations and trends®in machine learning14, 1–2 (2021), 1–210. doi:10.1561/2200000083
- [24]
-
[25]
Brendan McMahan, Daniel Ramage, and Peter Richtárik
Jakub Konečný, H. Brendan McMahan, Daniel Ramage, and Peter Richtárik
-
[26]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
Federated Optimization: Distributed Machine Learning for On-Device Intelligence. doi:10.48550/arXiv.1610.02527
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.02527
-
[27]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[28]
Na Li, Chunyi Zhou, Yansong Gao, Hui Chen, Zhi Zhang, Boyu Kuang, and Anmin Fu. 2025. Machine unlearning: Taxonomy, metrics, applications, challenges, and prospects.IEEE Transactions on Neural Networks and Learning Systems(2025). doi:10.1109/TNNLS.2025.3530988
- [29]
- [30]
-
[31]
Gaoyang Liu, Xiaoqiang Ma, Yang Yang, Chen Wang, and Jiangchuan Liu. 2021. Federaser: Enabling efficient client-level data removal from federated learning models. In2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS). IEEE, 1–10. doi:10.1109/IWQOS52092.2021.9521274
-
[32]
Yi Liu, Lei Xu, Xingliang Yuan, Cong Wang, and Bo Li. 2022. The right to be forgotten in federated learning: An efficient realization with rapid retraining. InIEEE INFOCOM 2022-IEEE Conference on Computer Communications. IEEE, 1749–1758. doi:10.1109/INFOCOM48880.2022.9796721
-
[33]
Ziyao Liu, Yu Jiang, Jiyuan Shen, Minyi Peng, Kwok-Yan Lam, Xingliang Yuan, and Xiaoning Liu. 2024. A survey on federated unlearning: Challenges, methods, and future directions.Comput. Surveys57, 1 (2024), 1–38. doi:10.1145/3679014
-
[34]
Pratyush Maini, Michael Curtis Mozer, Hanie Sedghi, Zachary Chase Lipton, J Zico Kolter, and Chiyuan Zhang. 2023. Can Neural Network Memorization Be Localized?. InInternational Conference on Machine Learning. PMLR, 23536–23557
2023
-
[35]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics. PMLR, 1273–1282
2017
-
[36]
Zibin Pan, Zhichao Wang, Chi Li, Kaiyan Zheng, Boqi Wang, Xiaoying Tang, and Junhua Zhao. 2025. Federated unlearning with gradient descent and conflict mitigation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 19804–19812. doi:10.1609/AAAI.V39I19.34181
-
[37]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE interna- tional conference on computer vision. 618–626
2017
-
[38]
Thanveer Shaik, Xiaohui Tao, Lin Li, Haoran Xie, Taotao Cai, Xiaofeng Zhu, and Qing Li. 2024. FRAMU: Attention-based machine unlearning using federated reinforcement learning.IEEE Transactions on Knowledge and Data Engineering (2024)
2024
-
[39]
Jiaqi Shao, Tao Lin, Xuanyu Cao, and Bing Luo. 2024. Federated unlearning: a perspective of stability and fairness.arXiv preprint arXiv:2402.01276(2024). doi:10.48550/ARXIV.2402.01276
-
[40]
Reza Shokri and Vitaly Shmatikov. 2015. Privacy-Preserving Deep Learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (CCS ’15). Association for Computing Machinery, New York, NY, USA, 1310–1321. doi:10.1145/2810103.2813687
-
[41]
K Simonyan, A Vedaldi, and A Zisserman. 2014. Deep inside convolutional net- works: visualising image classification models and saliency maps. International Conference on Learning Representations
2014
-
[42]
K Simonyan and A Zisserman. 2015. Very deep convolutional networks for large- scale image recognition. InInternational Conference on Learning Representations (ICLR)
2015
- [43]
-
[44]
Anvith Thudi, Hengrui Jia, Ilia Shumailov, and Nicolas Papernot. 2022. On the necessity of auditable algorithmic definitions for machine unlearning. In31st USENIX security symposium (USENIX Security 22). 4007–4022
2022
-
[45]
Reihaneh Torkzadehmahani, Reza Nasirigerdeh, Georgios Kaissis, Daniel Rueck- ert, Gintare Karolina Dziugaite, and Eleni Triantafillou. 2025. Improved Localized Machine Unlearning Through the Lens of Memorization.Transactions on Machine Learning Research(2025)
2025
-
[46]
2017.The EU General Data Protection Regulation (GDPR): A Practical Guide
Paul Voigt and Axel von dem Bussche. 2017.The EU General Data Protection Regulation (GDPR): A Practical Guide. Springer International Publishing. doi:10. 1007/978-3-319-57960-3
2017
-
[47]
Junxiao Wang, Song Guo, Xin Xie, and Heng Qi. 2022. Federated unlearning via class-discriminative pruning. InProceedings of the ACM web conference. 622–632. doi:10.1145/3485447.3512222
-
[48]
Weiqi Wang, Zhiyi Tian, Chenhan Zhang, An Liu, and Shui Yu. 2023. Bfu: Bayesian federated unlearning with parameter self-sharing. InProceedings of the 2023 ACM Asia Conference on Computer and Communications Security. 567–578
2023
-
[49]
Weiqi Wang, Zhiyi Tian, Chenhan Zhang, and Shui Yu. 2024. Machine unlearning: A comprehensive survey.arXiv preprint arXiv:2405.07406(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Paul L Williams and Randall D Beer. 2010. Nonnegative decomposition of multi- variate information.arXiv preprint arXiv:1004.2515(2010)
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [51]
-
[52]
Binchi Zhang, Zihan Chen, Cong Shen, and Jundong Li. 2024. Verification of machine unlearning is fragile. (2024), 58717–58738
2024
-
[53]
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals
-
[54]
Understanding deep learning (still) requires rethinking generalization. Commun. ACM64, 3 (2021), 107–115. doi:10.1145/3446776
-
[55]
Lefeng Zhang, Tianqing Zhu, Haibin Zhang, Ping Xiong, and Wanlei Zhou. 2023. Fedrecovery: Differentially private machine unlearning for federated learning frameworks.IEEE Transactions on Information Forensics and Security18 (2023), 4732–4746. doi:10.1109/TIFS.2023.3297905
-
[56]
Yian Zhao, Pengfei Wang, Heng Qi, Jianguo Huang, Zongzheng Wei, and Qiang Zhang. 2023. Federated unlearning with momentum degradation.IEEE Internet of Things Journal11, 5 (2023), 8860–8870. doi:10.1109/JIOT.2023.3321594 Rethinking Federated Unlearning via the Lens of Memorization KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Appendix A Stat...
-
[57]
This suggests that these retrained models do not exhibit similarity in parameter space
Additionally, in Figure G6b, the cosine similarities be- tween retrained models approaches0. This suggests that these retrained models do not exhibit similarity in parameter space. • The distance between the retrained models is not sig- nificant compared to the original model.For example, in Figure G6a, the L2 distance between the retrained model no.0 and...
2026
-
[58]
resetting redundant parameters with respect to the remaining dataset. For the first strategy, resetting the important parameters asso- ciated with the unlearning dataset followed by fine-tuning on the remaining dataset can achieve unlearning, as shown in Appendix F.3. This works because the fine-tuning stage helps the model to relearn overlapping informat...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.