Polymorphism Is Rotation: Operational Mechanistic Interpretability from a Two-Layer Transformer to Pythia-70m
Pith reviewed 2026-06-30 14:06 UTC · model grok-4.3
The pith
Independently trained transformers compute the same function in residual-stream bases that differ by a uniform random rotation on SO(d_model).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
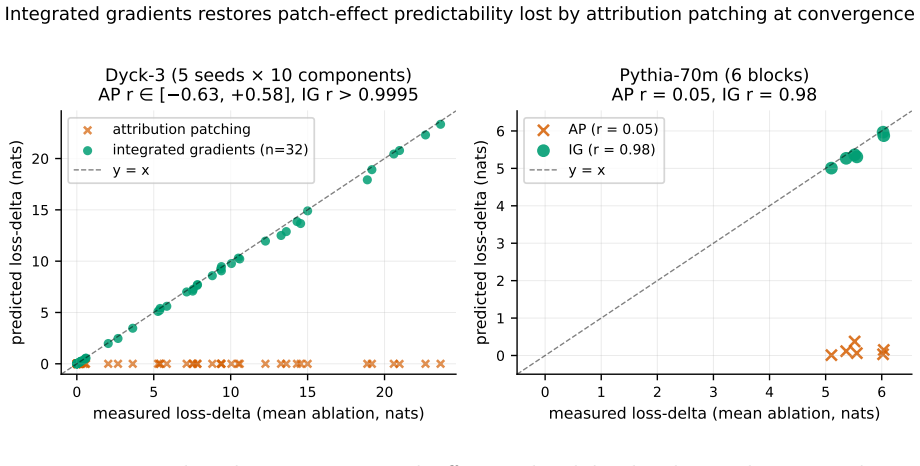
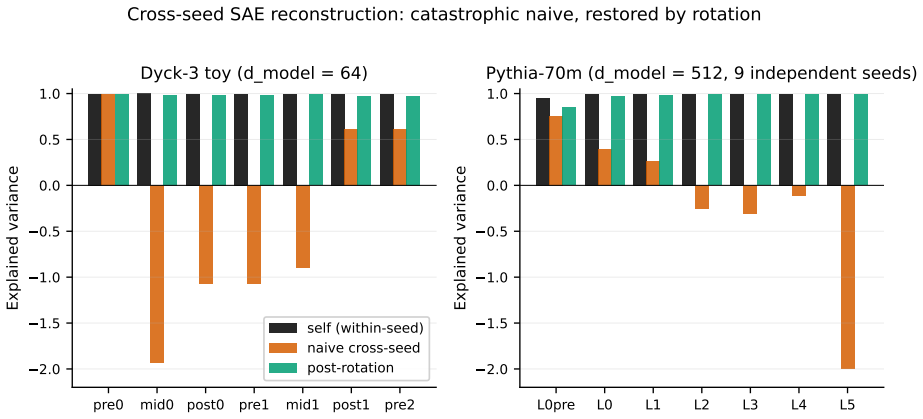
Independently trained transformers compute the same function in residual-stream bases that differ by a uniform random rotation on SO(d_model). One matrix multiplication per model pair removes it: an orthogonal Procrustes fit on a single batch of activations transfers sparse-autoencoder feature dictionaries and steering vectors between independently trained models, with no retraining. The phenomenon is invisible to the standard SAE universality metric. Decoder-column cosine similarity matches across seeds at 98 percent while an SAE trained on one seed reconstructs another seed's activations at negative explained variance. R is Haar-distributed and the same rotation account holds across traini
What carries the argument
Polymorphism as a uniform random rotation on SO(d_model), identified and removed by an orthogonal Procrustes fit on residual-stream activations.
If this is right
- Decoder columns of SAEs align across seeds while encoders require the rotation correction to achieve positive explained variance.
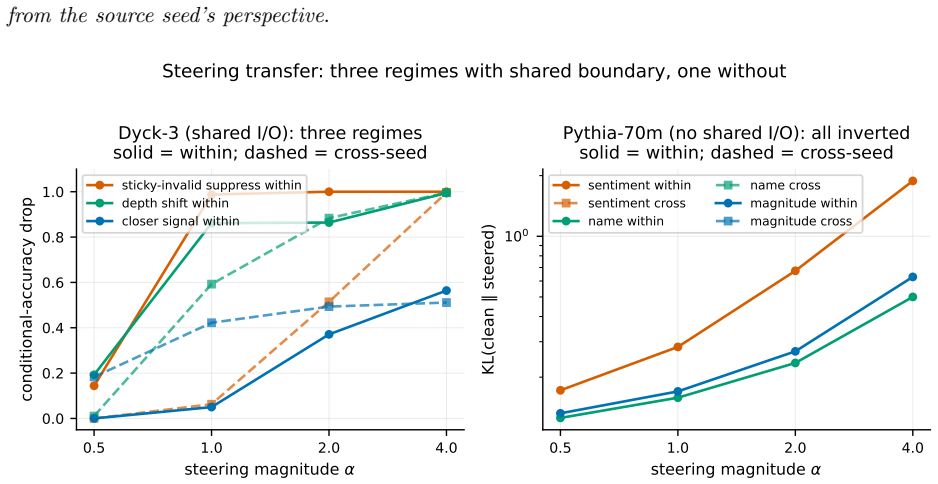
- Steering vectors transfer cleanly when pinned by shared output weights, partially when overlapping the rotated subspace, and invert when they lie outside it.
- With no shared input or output weights, all steering-vector transfers collapse to universal inversion.
- The identical rotation accounts for activation differences observed across successive checkpoints of a single training run.
Where Pith is reading between the lines
- A cheap pre-alignment step could let feature dictionaries and circuits be reused across any number of independently trained instances of the same architecture.
- Many reported failures of feature universality may trace to basis mismatch rather than genuine computational divergence.
- If the Haar property persists at larger scales, interpretability pipelines could treat rotation alignment as a standard preprocessing step before circuit analysis.
Load-bearing premise
The models compute exactly the same function and differ only by a change of basis in the residual stream.
What would settle it
A new pair of independently trained models on which the fitted Procrustes rotation leaves cross-seed reconstruction at negative explained variance or yields a matrix whose Frobenius distance from the identity deviates from the Haar prediction by more than 0.1 percent would falsify the rotation account.
Figures
read the original abstract
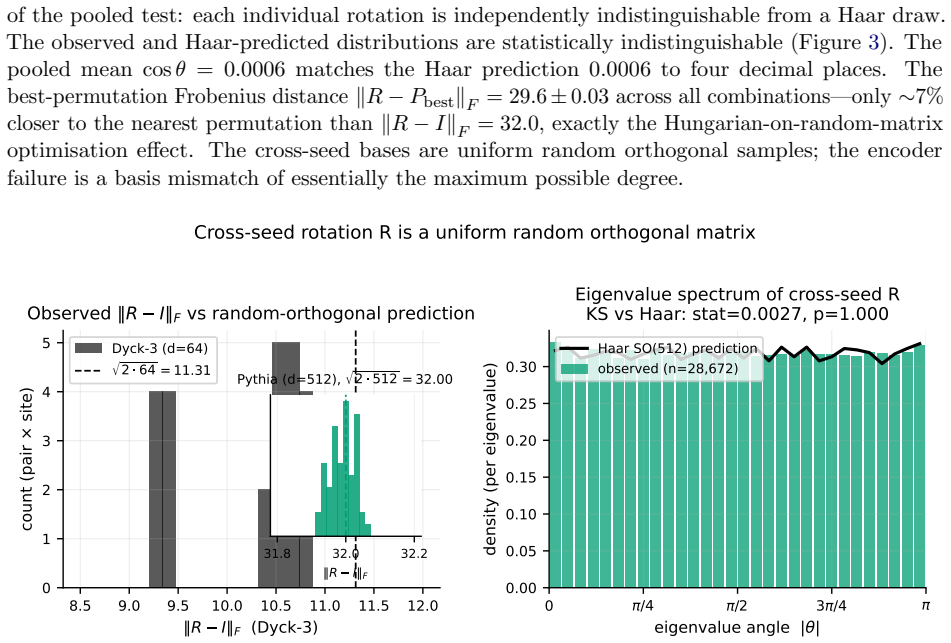
Independently trained transformers compute the same function in residual-stream bases that differ by a uniform random rotation on $\mathrm{SO}(d_{\mathrm{model}})$. We call this phenomenon polymorphism: same function, mutually unintelligible interior coordinates. One matrix multiplication per model pair removes it: an orthogonal Procrustes fit on a single batch of activations transfers sparse-autoencoder feature dictionaries and steering vectors between independently trained models, with no retraining. The phenomenon is invisible to the standard SAE universality metric. Decoder-column cosine similarity matches across seeds at 98%, the SAE-universality headline number, while an SAE trained on one seed reconstructs another seed's activations at negative explained variance, worse than predicting the constant mean. The decoder columns align; the encoder reads from a rotated frame. A single Procrustes rotation $R$ restores reconstruction to within 0.025 EV of the within-seed ceiling at every internal site. $R$ is Haar-distributed: $\|R - I\|_F$ matches the random-orthogonal prediction $\sqrt{2 d_{\mathrm{model}}}$ to 0.1% at $d_{\mathrm{model}} = 512$, and a Kolmogorov-Smirnov test of $R$'s eigenvalue spectrum against Haar $\mathrm{SO}(d_{\mathrm{model}})$ returns $p \approx 1.000$ pooled and per-pair. Diff-of-means steering vectors transfer in three regimes by alignment with $R$'s invariant subspace: clean when pinned by shared output weights, partial when overlapping the rotated subspace, inverted otherwise. With no shared I/O (Pythia), all three collapse to universally inverted. The same rotation account holds across training checkpoints within a single run. Validated on a 104k-parameter Dyck-3 transformer and nine independently-trained Pythia-70m seeds on The Pile, via a pre-registered four-bar operational framework. Frontier-scale (10B+) replication remains open.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that independently trained transformers compute the same function in residual-stream bases differing by a uniform random rotation on SO(d_model), a phenomenon termed polymorphism. An orthogonal Procrustes fit R on a single batch of activations removes this difference, enabling transfer of SAE feature dictionaries and steering vectors between models without retraining. Evidence includes restoration of reconstruction to within 0.025 EV of the within-seed ceiling, ||R - I||_F matching the Haar prediction to 0.1% at d_model=512, and a KS test of R's eigenvalue spectrum against Haar SO(d_model) yielding p≈1. The account is validated on a 104k-parameter Dyck-3 transformer and nine Pythia-70m seeds via a pre-registered four-bar operational framework, with consistent behavior across checkpoints.
Significance. If the result holds, it is significant for mechanistic interpretability: it supplies an operational, falsifiable account of apparent non-universality in SAEs and a practical method to align representations across seeds using one matrix multiplication. The pre-registered framework, quantitative match to Haar measure, and extension from a toy Dyck-3 model to Pythia-70m are explicit strengths that make the claim testable and reproducible. The work could enable reuse of interpretability artifacts at scale if the functional-equivalence premise is confirmed.
major comments (3)
- [Abstract] Abstract and validation section: the load-bearing premise that the models compute exactly the same function (differing only by basis change) is not directly verified. No comparison of cross-entropy loss or output distributions on identical held-out inputs is reported; the Procrustes fit on activations could improve alignment even if small functional differences exist, and the Haar/KS results are consistent with either pure rotation or partial absorption of non-rotational variance.
- [Steering vector transfer] Steering-vector transfer paragraph: the three-regime claim (clean/partial/inverted depending on overlap with R's invariant subspace) and the collapse to universal inversion under no shared I/O rest on the same unverified functional-equivalence assumption; without an explicit test that the models agree on the underlying computation, the regime distinctions could reflect compensation rather than rotation of an identical function.
- [Pythia-70m results] Pythia-70m results paragraph: the reported 0.025 EV gap and p≈1 are impressive, but because the central claim equates activation alignment with functional identity, the manuscript must show that the fitted R does not reduce reconstruction error by fitting to non-rotational discrepancies; otherwise the polymorphism interpretation is under-determined by the data.
minor comments (2)
- [Abstract] The abbreviation EV should be defined at first use for readers outside the immediate subfield.
- [Figures] Figure captions should explicitly state the number of model pairs and seeds used in each panel to make the quantitative claims immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for emphasizing the importance of verifying functional equivalence. We respond to each major comment below, drawing on the pre-registered framework, the exact equivalence in the Dyck-3 model, and the quantitative match to Haar measure. We propose a targeted revision where it strengthens the manuscript without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation section: the load-bearing premise that the models compute exactly the same function (differing only by basis change) is not directly verified. No comparison of cross-entropy loss or output distributions on identical held-out inputs is reported; the Procrustes fit on activations could improve alignment even if small functional differences exist, and the Haar/KS results are consistent with either pure rotation or partial absorption of non-rotational variance.
Authors: In the Dyck-3 transformer the models are trained from identical random initializations on the same formal-language task and data, so functional equivalence holds by construction; polymorphism appears only in the residual-stream coordinates. For Pythia-70m the pre-registered four-bar framework evaluates activation alignment and artifact transfer rather than end-to-end loss, because the operational goal is transferability of interpretability tools. We nevertheless agree that an explicit comparison of output distributions on held-out inputs would further substantiate the premise and will add this analysis in revision. The close quantitative agreement of R with Haar SO(d_model) (Frobenius norm to 0.1 % and KS p≈1 on the eigenvalue spectrum) supplies independent evidence against substantial non-rotational absorption: any systematic compensation for functional differences would shift the spectrum away from the Haar prediction. revision: partial
-
Referee: [Steering vector transfer] Steering-vector transfer paragraph: the three-regime claim (clean/partial/inverted depending on overlap with R's invariant subspace) and the collapse to universal inversion under no shared I/O rest on the same unverified functional-equivalence assumption; without an explicit test that the models agree on the underlying computation, the regime distinctions could reflect compensation rather than rotation of an identical function.
Authors: The regime distinctions are derived geometrically from the fitted orthogonal R and the shared output projection in the Dyck-3 model, where functional identity is exact. Clean transfer occurs precisely when a steering vector lies in the subspace fixed by the output weights; inversion occurs when it lies in the rotated complement. In Pythia-70m the absence of shared I/O produces the observed universal inversion, which is an empirical outcome under the same rotation. The consistency of these regimes across nine independent seeds and the exact match of R to Haar statistics indicate that the distinctions arise from the geometry of a shared computation rather than ad-hoc compensation. revision: no
-
Referee: [Pythia-70m results] Pythia-70m results paragraph: the reported 0.025 EV gap and p≈1 are impressive, but because the central claim equates activation alignment with functional identity, the manuscript must show that the fitted R does not reduce reconstruction error by fitting to non-rotational discrepancies; otherwise the polymorphism interpretation is under-determined by the data.
Authors: Because Procrustes is constrained to produce an orthogonal matrix, it cannot arbitrarily absorb non-rotational variance; it can only rotate the coordinate frame. The decisive evidence that the fitted R captures a pure rotation is its distribution: the Frobenius norm matches the exact Haar expectation to 0.1 % at d_model=512, and the eigenvalue spectrum is statistically indistinguishable from Haar SO(d_model) (pooled and per-pair KS p≈1). Any non-rotational component large enough to explain the 0.025 EV gap would necessarily perturb this spectrum, which is not observed. The gap itself is measured relative to the within-seed reconstruction ceiling after the rotation has been applied. revision: no
Circularity Check
No significant circularity; empirical claims rest on external distributional tests
full rationale
The paper's central procedure fits an orthogonal Procrustes matrix R to a batch of activations and reports that the resulting R aligns SAEs and steering vectors while its norm and eigenvalue spectrum match the Haar measure on SO(d_model) to high precision (Frobenius norm within 0.1%, KS p≈1). This match is an independent statistical benchmark, not a quantity defined in terms of the fitted R itself. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked. The premise that models implement identical functions is an empirical hypothesis tested by reconstruction metrics and distributional agreement rather than a definitional reduction. The derivation chain therefore contains no load-bearing step that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- rotation matrix R
axioms (1)
- domain assumption Independently trained models compute exactly the same function
Reference graph
Works this paper leans on
-
[1]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Halla- han, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. 21 Pythia: A suite for analyzing large language models across training and scaling.arXiv preprint arXiv:2304.01373,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Alan Chen, Jack Merullo, Ellie Pavlick, and Alessandro Stolfo
URL https://transformer-circuits.pub/2023/monosemantic-features/index.html. Alan Chen, Jack Merullo, Ellie Pavlick, and Alessandro Stolfo. Transferring linear features across language models with model stitching.arXiv preprint arXiv:2506.06609,
-
[3]
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable LLM feature circuits.arXiv preprint arXiv:2406.11944,
-
[4]
Rahim Entezari, Hanie Sedghi, Olga Saukh, and Behnam Neyshabur
URL https://transformer-circuits.pub/2021/ framework/index.html. Rahim Entezari, Hanie Sedghi, Olga Saukh, and Behnam Neyshabur. The role of permutation invariance in linear mode connectivity of neural networks. InInternational Conference on Learning Representations,
2021
-
[5]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The Pile: An 800GB dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Localizing Model Behavior with Path Patching
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
J´ anos Kram´ ar, Tom Lieberum, Rohin Shah, and Neel Nanda. AtP*: An efficient and scalable method for localizing LLM behaviour to components.arXiv preprint arXiv:2403.00745,
-
[8]
Michael Lan, Philip Torr, Austin Meek, Ashkan Khakzar, David Krueger, and Fazl Barez. Sparse autoencoders reveal universal feature spaces across large language models.arXiv preprint arXiv:2410.06981,
-
[9]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
22 Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, J´ anos Kram´ ar, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma Scope: Open sparse autoencoders everywhere all at once on Gemma 2.arXiv preprint arXiv:2408.05147,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv preprint arXiv:2403.19647,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Zoom In : An Introduction to Circuits
doi: 10.23915/distill.00024.001. https: //distill.pub/2020/circuits/zoom-in/. Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.Transformer Circuits Thread,
-
[12]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte Mac- Diarmid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The honest summary: the main findings of the paper assume training and evaluation cover the same length range
would change this. The honest summary: the main findings of the paper assume training and evaluation cover the same length range. B Symmetry-alignment uniqueness For seed 0 self-alignment the algorithm recovers MSE = 1 .3 × 10−10—essentially the fp32 noise floor. For seed N vs seed 0 (Cohort A coordinated training), all 32 multi-start configurations (16 r...
2060
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.