Who judges the judges? Governance from metrics: a runtime framework for continuous LLM compliance monitoring
Pith reviewed 2026-06-30 12:51 UTC · model grok-4.3
The pith
Regulatory compliance for LLMs emerges as a continuous runtime signal from a panel of specialized judges rather than one-time binary audits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
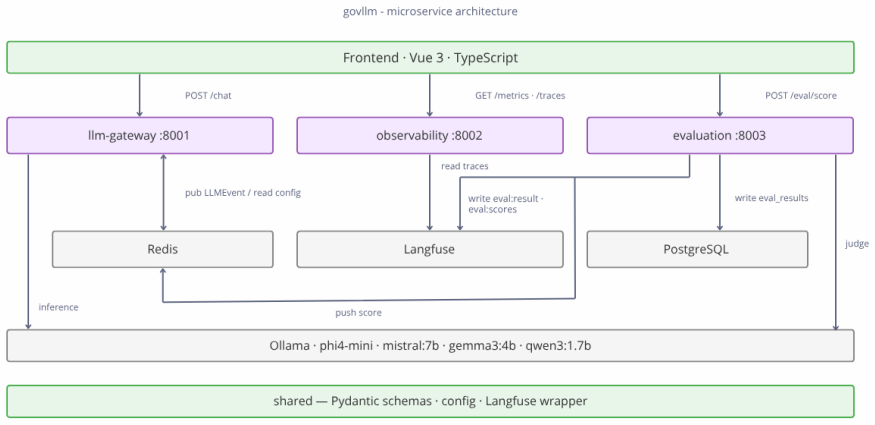
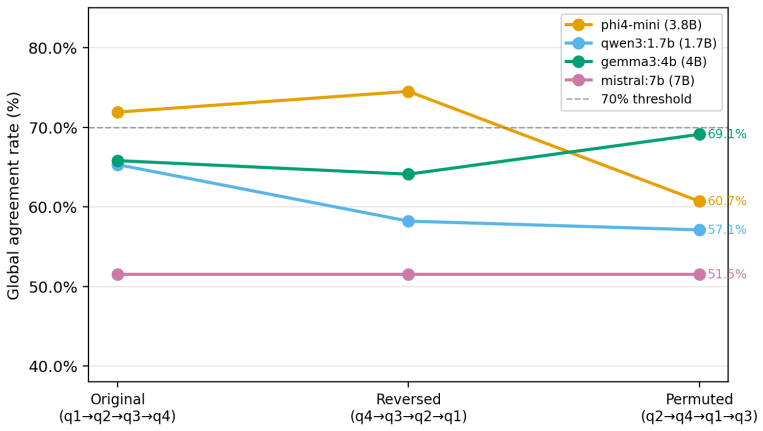
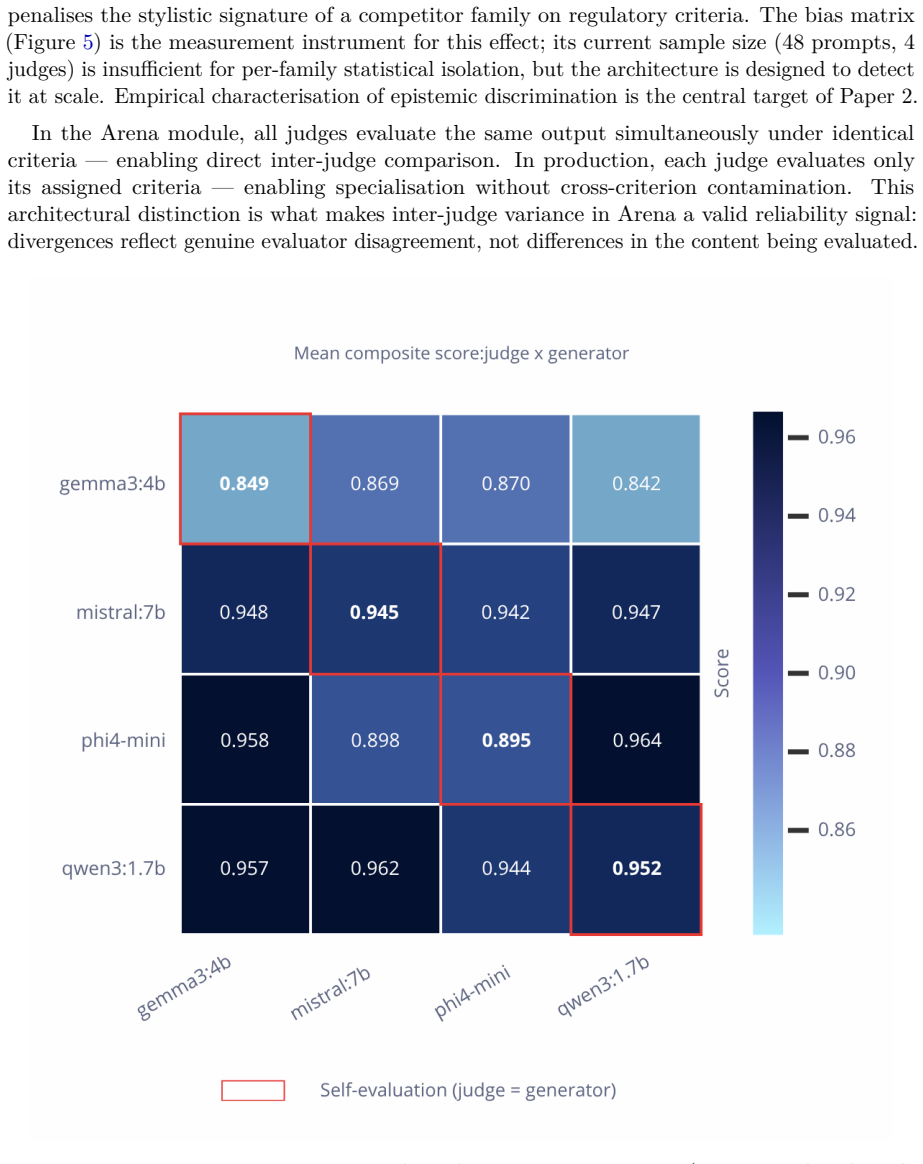
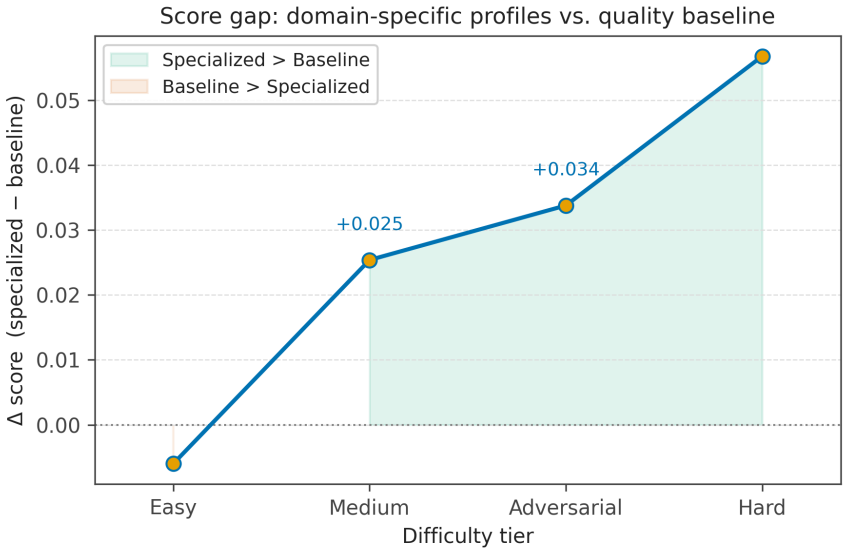
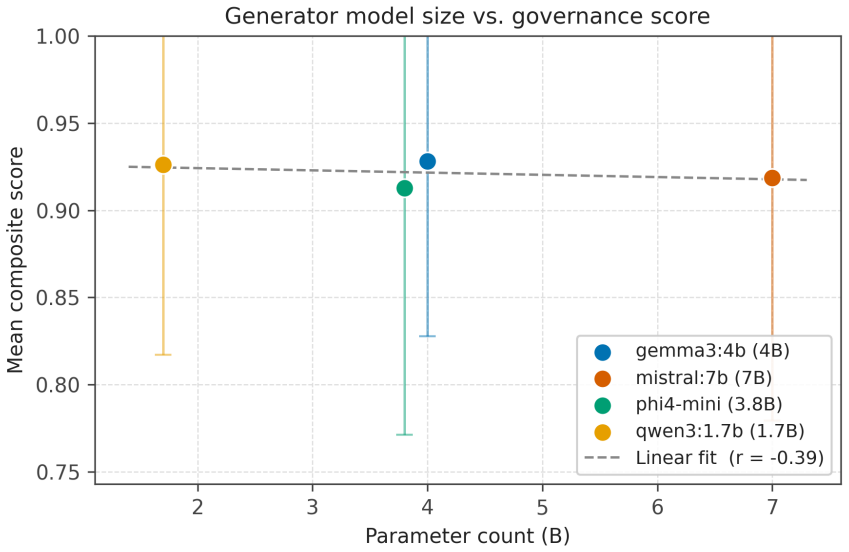
The central claim is that governance from metrics derives regulatory compliance as a continuous signal from runtime observability. The govllm framework implements a governance-driven routing architecture in which model selection is based on accumulated compliance scores from a panel of regulatory judges specialized per criterion, with inter-judge disagreement reframed as a regulatory uncertainty signal that warrants human arbitration rather than treated as noise. Validation on 49 annotated prompt-response pairs across five criteria using four small on-premise models shows agreement rates from 51.5% to 69.1%, with no model dominating and documented structural failure modes plus position bias
What carries the argument
The panel of regulatory judges, LLM evaluators specialized per criterion such as EU AI Act, GDPR, ANSSI and accessibility, whose accumulated compliance scores determine routing and whose disagreements are reframed as actionable uncertainty signals.
If this is right
- Model selection in deployed systems is driven by accumulated compliance scores instead of latency or cost.
- Inter-judge disagreement becomes an explicit signal that triggers human arbitration.
- Three structural failure modes in small regulatory judges are identified and can be mitigated in the design.
- Position bias in judges is quantified and can be tested across question-order conditions to improve reliability.
Where Pith is reading between the lines
- Production systems could use the framework to flag compliance drift automatically before external audits are triggered.
- The judge-panel approach might scale to additional regulatory domains if the uncertainty signal remains predictive outside the five tested criteria.
- Accounting for position bias in advance could raise effective agreement rates and reduce unnecessary human reviews.
Load-bearing premise
That inter-judge disagreement among the regulatory LLM evaluators can be reliably reframed as a regulatory uncertainty signal warranting human arbitration and that the observed agreement rates generalize to production drift detection.
What would settle it
A live deployment in which accumulated compliance scores and disagreement rates show no correlation with subsequently detected regulatory violations or emergent behavioral drift.
Figures


read the original abstract
Current approaches to AI compliance treat conformity as a binary, audit-time verdict rather than a continuous, measurable property of production systems. We argue that this compliance fiction is structurally ill-suited to the requirements of the EU AI Act, which demands ongoing human oversight and the detection of emergent behavioural drift in deployed systems. We introduce governance from metrics, a principle whereby regulatory compliance is derived as a continuous signal from runtime observability rather than from static assessments. Building on this principle, we present govllm, an open-source framework implementing a governance-driven routing architecture in which model selection is determined by accumulated compliance scores rather than by latency or cost alone. Central to our approach is a panel of regulatory judges - LLM evaluators specialised per criterion (EU AI Act, GDPR, ANSSI, accessibility) - whose inter-judge disagreement we reframe not as noise but as a regulatory uncertainty signal warranting human arbitration. We validate this approach through a ground truth corpus of 49 annotated prompt/response pairs across five regulatory criteria, evaluated by four small language models (SLMs, 1.7B-7B parameters) running fully on-premise. Agreement rates range from 51.5% (mistral:7b) to 69.1% (phi4-mini), with no single model dominating across all criteria - empirically motivating the Profile-as-jury design. We further document three structural failure modes in small regulatory judges and a judge-specific position bias that degrades agreement by up to 25 percentage points across three question-order conditions (original, reversed, permuted). govllm is released as open-source software to support reproducible AI governance research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that binary, audit-time compliance assessments are ill-suited to the EU AI Act's demands for ongoing oversight and drift detection. It introduces the principle of 'governance from metrics,' whereby compliance is treated as a continuous runtime signal, and presents the open-source govllm framework implementing a governance-driven routing architecture. In this architecture, model selection is driven by accumulated compliance scores from a panel of specialized regulatory judges (on-premise SLMs per criterion), with inter-judge disagreement reframed as a regulatory uncertainty signal warranting human arbitration rather than noise. The approach is validated on a 49-pair ground-truth corpus across five criteria, with reported agreement rates of 51.5% (mistral:7b) to 69.1% (phi4-mini), no single model dominating, and position bias degrading agreement by up to 25 points under order permutations.
Significance. If the central empirical claims hold under stronger validation, the work could provide a reproducible, on-premise framework for continuous LLM compliance monitoring that aligns with regulatory needs for human oversight. The open-source release and fully on-premise SLM evaluation (1.7B–7B parameters) are explicit strengths that anchor external reproducibility and reduce reliance on proprietary APIs.
major comments (3)
- [Abstract] Abstract and presumed validation section: The central claim that inter-judge disagreement constitutes a usable regulatory uncertainty signal warranting human arbitration rests on the 49-pair corpus, yet the manuscript reports only raw agreement percentages (51.5–69.1%) with no error bars, statistical significance tests, or correlation analysis linking disagreement magnitude to actual compliance violations or human arbitration outcomes.
- [Abstract] Abstract: No baseline routing experiments are described comparing governance-driven selection (accumulated compliance scores) against standard latency/cost-based routing, nor are there results showing improved compliance or drift detection in simulated production traffic; this is load-bearing for the claim that the jury design and disagreement signal improve upon existing practice.
- [Abstract] Abstract: The ground-truth corpus construction is not detailed (selection criteria for the 49 pairs, annotation protocol, or inter-annotator agreement among human labels), making it impossible to assess whether the observed agreement rates and position bias generalize beyond this specific set or support production drift detection.
minor comments (1)
- The abstract could more explicitly separate the conceptual contribution (governance from metrics) from the empirical validation results to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the empirical presentation can be strengthened. We respond to each major comment below, proposing targeted revisions to the abstract and validation sections while preserving the paper's scope as a framework introduction with foundational judge-agreement validation.
read point-by-point responses
-
Referee: [Abstract] Abstract and presumed validation section: The central claim that inter-judge disagreement constitutes a usable regulatory uncertainty signal warranting human arbitration rests on the 49-pair corpus, yet the manuscript reports only raw agreement percentages (51.5–69.1%) with no error bars, statistical significance tests, or correlation analysis linking disagreement magnitude to actual compliance violations or human arbitration outcomes.
Authors: We agree the presentation of results can be improved. The 49-pair corpus is modest by design to enable fully on-premise replication; we will add bootstrap 95% confidence intervals around each agreement rate and a note on the absence of graded human uncertainty labels that would enable correlation analysis. Formal significance testing across models will be included where sample sizes permit without inflating Type I error. These additions will be made in the revised validation section and referenced from the abstract. revision: yes
-
Referee: [Abstract] Abstract: No baseline routing experiments are described comparing governance-driven selection (accumulated compliance scores) against standard latency/cost-based routing, nor are there results showing improved compliance or drift detection in simulated production traffic; this is load-bearing for the claim that the jury design and disagreement signal improve upon existing practice.
Authors: The current validation deliberately isolates the jury mechanism and disagreement signal rather than end-to-end routing performance. We will revise the abstract and discussion to explicitly delimit the contribution to judge reliability and position-bias analysis, removing any implication of demonstrated routing superiority. A dedicated paragraph on planned production-traffic benchmarks will be added. We maintain that the jury design is a necessary prerequisite step before such comparisons. revision: partial
-
Referee: [Abstract] Abstract: The ground-truth corpus construction is not detailed (selection criteria for the 49 pairs, annotation protocol, or inter-annotator agreement among human labels), making it impossible to assess whether the observed agreement rates and position bias generalize beyond this specific set or support production drift detection.
Authors: The full manuscript contains a methods subsection on corpus construction (sampling from public regulatory prompt sets, two-expert annotation protocol, and Cohen's κ = 0.78). We will expand the abstract to include these key details (pair selection criteria, annotation protocol summary, and inter-annotator agreement) and add a sentence on limitations for drift detection. This will make the validation scope transparent without altering the reported numbers. revision: yes
Circularity Check
No significant circularity in the empirical framework
full rationale
The paper introduces 'governance from metrics' as a principle and presents govllm as an empirical framework validated on a 49-pair ground-truth corpus with four on-premise SLMs. No equations, predictions, or first-principles derivations are claimed that reduce compliance scores or uncertainty signals to fitted parameters defined by the same data. The reframing of inter-judge disagreement is presented as a design choice motivated by observed agreement rates (51.5-69.1%) rather than derived from self-citations or self-definitions. The open-source release and on-premise execution supply external reproducibility anchors, rendering the work self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Small language models (1.7B-7B) can produce usable compliance evaluations for EU AI Act, GDPR, ANSSI and accessibility criteria when run on-premise.
- ad hoc to paper Inter-judge disagreement constitutes a regulatory uncertainty signal that warrants human arbitration rather than being treated as noise.
invented entities (1)
-
regulatory judges (LLM evaluators specialised per criterion)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Provisional Agreement on the Digital Omnibus: Amendments to Regulation (EU) 2024/1689 (AI Act),
Council of the European Union and European Parliament. Provisional Agreement on the Digital Omnibus: Amendments to Regulation (EU) 2024/1689 (AI Act),
2024
-
[2]
Provisional agreement reached 7 May 2026, pending formal ratification
URL https://www.consilium.europa.eu/en/press/press-releases/2026/05/07/ artificial-intelligence-council-and-parliament-agree-to-simplify-and-streamline-rules/ . Provisional agreement reached 7 May 2026, pending formal ratification. Krrish Dholakia and Ishaan Jaffer. LiteLLM: Call all LLM APIs using the OpenAI format,
2026
-
[3]
Joseph Enguehard, Morgane Van Ermengem, Kate Atkinson, Sujeong Cha, Arijit Ghosh Chowd- hury, Prashanth Kallur Ramaswamy, Jeremy Roghair, Hannah R
URLhttps://github.com/BerriAI/litellm. Joseph Enguehard, Morgane Van Ermengem, Kate Atkinson, Sujeong Cha, Arijit Ghosh Chowd- hury, Prashanth Kallur Ramaswamy, Jeremy Roghair, Hannah R. Marlowe, Carina Suzana Negreanu, Kitty Boxall, and Diana Mincu. LeMAJ (Legal LLM-as-a-Judge): Bridging Legal Reasoning and LLM Evaluation. InProceedings of the Natural Le...
2025
-
[4]
European Commission, AI Office
URLhttps://arxiv.org/abs/2510.07243. European Commission, AI Office. Draft Guidelines on the Implementation of the Transparency Obligations for Certain AI Systems under Article 50 of the AI Act,
-
[5]
39 European Parliament and Council of the European Union
URL https://digital-strategy.ec.europa.eu/en/consultations/ consultation-draft-guidelines-transparency-obligations-under-ai-act. 39 European Parliament and Council of the European Union. Regulation (EU) 2024/1689 — Artificial Intelligence Act,
2024
-
[7]
URLhttps://arxiv.org/abs/2411.15594. Pratik Jayarao, Himanshu Gupta, Neeraj Varshney, and Chaitanya Dwivedi. Thinking Small Models are Efficient LLM Judges.arXiv preprint arXiv:2509.13332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Explicit Reasoning Makes Better Judges: A Systematic Study on Accuracy, Efficiency, and Robustness
URL https: //arxiv.org/abs/2509.13332. Jaehun Jung, Faeze Brahman, and Yejin Choi. Trust or Escalate: LLM Judges with Provable Guarantees for Human Agreement. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
-
[11]
URLhttps://arxiv.org/abs/2604.04604. OWASP Foundation. OWASP Top 10 for Large Language Model Applications,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URLhttps: //arxiv.org/abs/2602.06669. Pat Verga, Sebastian Hofstätter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models.arXiv preprint arXiv:2404.18796,
-
[14]
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
URLhttps://arxiv.org/abs/2404.18796. Jiannan Xu, Gujie Li, and Jane Yi Jiang. AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights.arXiv preprint arXiv:2509.00462,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URLhttps://arxiv.org/ abs/2509.00462. 41
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.