From Theory to Decision Rule: Calibrating the Noisy-Label Crossover for Vision-Language Model Weak Supervision Across Three Medical-Imaging Benchmarks
Pith reviewed 2026-06-30 12:55 UTC · model grok-4.3
The pith
Noisy-label theory's predicted crossover, where weak labels from vision-language models stop helping and start hurting, occurs at specific gold-label counts on three medical imaging benchmarks and yields a practical decision rule.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
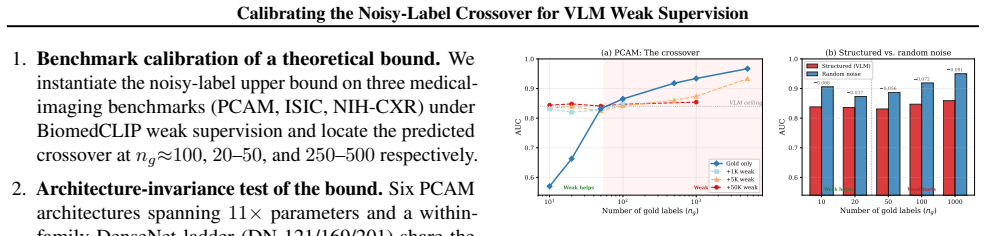
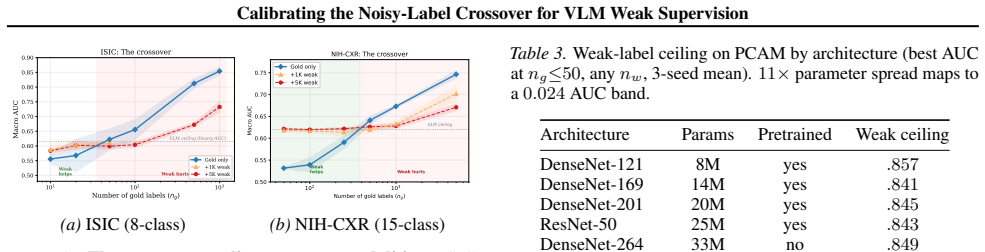
Classical noisy-label theory predicts a sharp crossover: once a gold-trained classifier matches the labeler, weak labels stop helping and start hurting. This paper calibrates the location of that crossover for BiomedCLIP weak labels on PCAM (~100 gold examples), ISIC (20-50), and NIH-CXR (250-500); above the crossover, weak labels degrade AUC by up to 0.10. The location is architecture-invariant for four of five pretrained models, and a within-family DenseNet sweep indicates the labeler, not the student, is the dominant constraint. The calibration supports a decision rule operable from 10-20 gold labels.
What carries the argument
The crossover point from noisy-label theory, located by comparing gold-only AUC to VLM accuracy on a small gold set.
If this is right
- Weak labels above the calibrated crossover degrade AUC by up to 0.10 on the three benchmarks.
- The crossover location remains consistent across four of five pretrained architectures spanning an 11x parameter range.
- A within-family DenseNet sweep confirms the labeler rather than the student model sets the binding constraint.
- The decision rule allows practitioners to decide whether to use weak labels from only 10-20 gold examples.
- Structured noise produces a sign flip on NIH-CXR, indicating that the rate-only formulation of the bound requires refinement such as label-space projection.
Where Pith is reading between the lines
- The same calibration procedure could be applied to non-medical image datasets to test whether similar crossover locations emerge.
- Future benchmarks could systematically vary structured noise to quantify how much it shifts the crossover beyond the rate-only prediction.
- Improving the upstream VLM labeler accuracy would be expected to move the crossover to higher gold-label counts, extending the regime where weak labels remain useful.
- The architecture invariance suggests that once the labeler is fixed, further student-model scaling brings diminishing returns for weak-supervision decisions.
Load-bearing premise
The classical noisy-label bound applies directly to BiomedCLIP-generated labels on these medical datasets without additional unmodeled factors such as structured noise or domain-specific label correlations altering the crossover location.
What would settle it
Observing that the decision rule fails to predict the point at which adding more weak labels begins to degrade AUC on a held-out medical imaging task, or that the structured-vs-random noise sign flip does not appear, would falsify the calibration.
Figures
read the original abstract
Classical noisy-label theory predicts that downstream performance under weak supervision is bounded above by the labeler's accuracy, implying a sharp crossover: once a gold-trained classifier matches the labeler, weak labels stop helping and start hurting. The prediction is theoretical; what is missing is a benchmark calibration that turns it into an instance-level statement for modern foundation-model labelers. We provide such a calibration for BiomedCLIP-generated weak labels on three medical-imaging benchmarks (PCAM, ISIC, NIH-CXR) and six downstream architectures spanning an 11x parameter range. The crossover predicted by theory appears at ng~100 on PCAM, 20-50 on ISIC, and 250-500 on NIH-CXR; weak labels above the crossover degrade AUC by up to -0.10. The location is architecture-invariant for four of five pretrained architectures, and a within-family DenseNet sweep (2.5x parameters, identical pretraining) supports the view that the labeler, not the student, is the dominant constraint. The calibration in turn produces a decision rule operable from 10-20 gold labels: compare gold-only AUC to VLM accuracy on the user's gold set. A structured-vs-random noise sign flip on NIH-CXR shows that the rate-only formulation of the bound is incomplete and identifies a concrete refinement (label-space projection) that future benchmarks can be designed to test.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript calibrates classical noisy-label theory to BiomedCLIP-generated weak labels across PCAM, ISIC, and NIH-CXR benchmarks. It reports theory-predicted crossover points at ng≈100 (PCAM), 20-50 (ISIC), and 250-500 (NIH-CXR) where weak labels transition from improving to degrading downstream AUC (by up to -0.10). The location is claimed architecture-invariant for four of five pretrained models; a within-family DenseNet sweep is used to argue that the labeler, not the student, is the dominant constraint. From the calibration the authors derive a practical decision rule operable from 10-20 gold labels: compare gold-only AUC against VLM accuracy on the same small set. The abstract also reports a structured-vs-random noise sign-flip on NIH-CXR showing that the rate-only bound is incomplete.
Significance. If the reported crossovers and decision rule prove robust, the work supplies a concrete, low-data method for deciding when VLM weak supervision is beneficial in medical imaging, directly linking theory to an instance-level rule. The architecture-invariance result and the explicit demonstration that noise structure can reverse degradation are strengths that could guide future benchmark design. The absence of error bars, statistical tests, and full exclusion criteria in the presented claims, however, limits immediate applicability.
major comments (2)
- [Abstract] Abstract: the crossover points (ng≈100, 20-50, 250-500) and the -0.10 AUC degradation are stated as concrete numeric results, yet no error bars, confidence intervals, or description of the statistical procedure used to locate the crossovers from held-out gold data are supplied. This directly affects the load-bearing claim that the decision rule can be operated from 10-20 gold labels.
- [Abstract] Abstract: the paper itself reports a structured-vs-random noise sign flip on NIH-CXR that demonstrates the rate-only formulation is incomplete and that domain-specific label correlations can reverse expected degradation. The derived decision rule nevertheless treats the classical bound as directly predictive without specifying how the rule would be adjusted when noise structure differs from the BiomedCLIP error pattern observed here; this undermines the generality of the calibration for the three benchmarks.
minor comments (1)
- [Abstract] Abstract: the six downstream architectures spanning an 11× parameter range are referenced but not enumerated, nor are the per-architecture AUC tables or the exact DenseNet family sweep results provided in the summary.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: Abstract: the crossover points (ng≈100, 20-50, 250-500) and the -0.10 AUC degradation are stated as concrete numeric results, yet no error bars, confidence intervals, or description of the statistical procedure used to locate the crossovers from held-out gold data are supplied. This directly affects the load-bearing claim that the decision rule can be operated from 10-20 gold labels.
Authors: We agree that the absence of error bars and a description of the statistical procedure limits the strength of the claims in the abstract. The crossovers were identified by locating the intersection of the gold-only and weak-supervision AUC curves on held-out gold data, but this procedure and associated uncertainty were not reported. In the revised manuscript we will add bootstrap confidence intervals for each crossover point (ng) and include a concise description of the identification procedure in both the abstract and methods section. revision: yes
-
Referee: Abstract: the paper itself reports a structured-vs-random noise sign flip on NIH-CXR that demonstrates the rate-only formulation is incomplete and that domain-specific label correlations can reverse expected degradation. The derived decision rule nevertheless treats the classical bound as directly predictive without specifying how the rule would be adjusted when noise structure differs from the BiomedCLIP error pattern observed here; this undermines the generality of the calibration for the three benchmarks.
Authors: We acknowledge that the NIH-CXR sign-flip experiment explicitly shows the rate-only bound is incomplete under structured noise. The decision rule is presented as a practical heuristic calibrated to the observed BiomedCLIP error patterns on the three benchmarks rather than a universal predictor. In the revision we will clarify the scope of the rule, state that it applies under noise structures similar to those observed here, and note that label-space projection (as suggested by the sign-flip result) offers one route for adjustment when correlations differ; we will also flag this as an open direction for future benchmark design. revision: yes
Circularity Check
No significant circularity; empirical calibration is self-contained
full rationale
The paper reports measured crossover locations (ng~100 on PCAM, etc.) obtained by direct comparison of gold-only AUC against VLM accuracy on held-out gold sets. No equation or derivation reduces the reported crossover or decision rule to a fitted parameter by construction. The classical bound is invoked only as background motivation; the paper explicitly notes its incompleteness via the NIH-CXR sign-flip observation rather than assuming it forces the result. No self-citations are load-bearing, and the architecture-invariance claim rests on the experimental sweep, not on renaming or self-definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Classical noisy-label theory predicts that downstream performance is bounded above by the labeler's accuracy, producing a sharp crossover once a gold-trained classifier matches the labeler.
Reference graph
Works this paper leans on
-
[1]
and Verleysen, M
Frénay, B. and Verleysen, M. Classification in the presence of label noise: a survey.IEEE Transactions on Neural Networks and Learning Systems, 25(5):845–869, 2014
2014
-
[2]
S., Ravikumar, P., and Tewari, A
Natarajan, N., Dhillon, I. S., Ravikumar, P., and Tewari, A. Learning with noisy labels. InAdvances in Neural Information Processing Systems, volume 26, 2013. 4 Calibrating the Noisy-Label Crossover for VLM Weak Supervision
2013
-
[3]
K., Nock, R., and Qu, L
Patrini, G., Rozza, A., Menon, A. K., Nock, R., and Qu, L. Making deep neural networks robust to label noise: A loss correction approach. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2233–2241, 2017
2017
-
[4]
J., De Sa, C
Ratner, A. J., De Sa, C. M., Wu, S., Selsam, D., and Ré, C. Data programming: Creating large training sets, quickly. InAdvances in Neural Information Processing Systems, volume 29, 2016
2016
-
[5]
D., Kurakin, A., Zhang, H., and Raffel, C
Cubuk, E. D., Kurakin, A., Zhang, H., and Raffel, C. FixMatch: Simplifying semi-supervised learning with consistency and confidence. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2020
2020
-
[6]
Song, H., Kim, M., Park, D., Shin, Y ., and Lee, J.- G. Learning from noisy labels with deep neural net- works: A survey.IEEE Transactions on Neural Networks and Learning Systems, 34(11):8135–8153, 2022. doi: 10.1109/TNNLS.2022.3152527
-
[7]
Xie, Q., Luong, M.-T., Hovy, E., and Le, Q. V . Self-training with Noisy Student improves ImageNet classification. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10687–10698, 2020
2020
-
[8]
BiomedCLIP: A multimodal biomedical foun- dation model pretrained from fifteen million scientific image-text pairs
Poon, H. BiomedCLIP: A multimodal biomedical foun- dation model pretrained from fifteen million scientific image-text pairs. 2024
2024
-
[9]
VLM-CPL: Consensus pseudo la- bels from vision-language models for annotation-free pathological image classification.IEEE Transactions on Medical Imaging, 2024
Zhong, L., Huang, Z., Liu, Y ., Liao, W., Zhang, S., Wang, G., and Zhang, S. VLM-CPL: Consensus pseudo la- bels from vision-language models for annotation-free pathological image classification.IEEE Transactions on Medical Imaging, 2024. 5
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.