Cross-Domain Energy-Guided Diffusion Generation for Off-Dynamics Reinforcement Learning
Pith reviewed 2026-06-30 11:41 UTC · model grok-4.3
The pith
Energy guidance lets a diffusion model trained on source trajectories produce adapted samples that improve target-domain planning and policy learning under mismatched dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
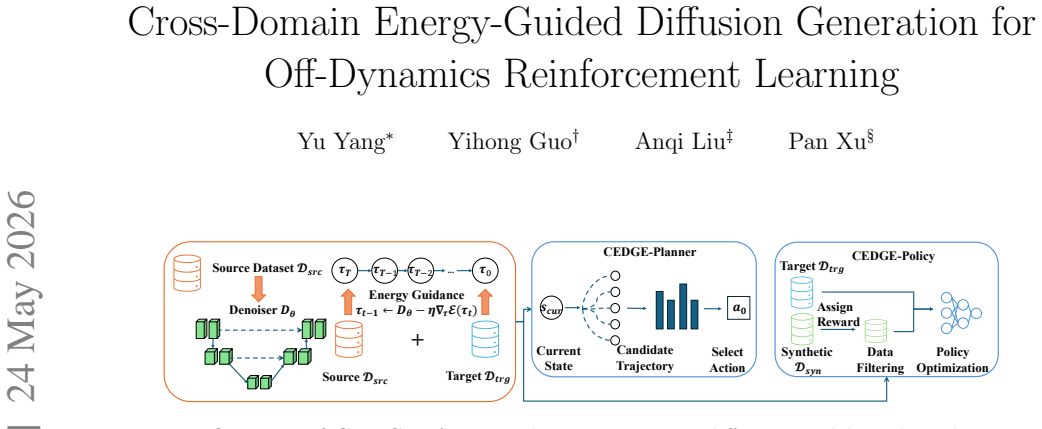
CEDGE trains a trajectory diffusion model on source-domain trajectories and adapts the generated samples to the target domain through energy guidance derived by minimizing the distribution mismatch between the source and desired target-domain trajectories; this guidance is decomposed into return, domain, and behavior energy components. The resulting energy-guided trajectories serve both for direct planning and as synthetic data that improves downstream target policy learning. Because adaptation occurs through guidance rather than retraining, the framework adapts efficiently to new target dynamics.
What carries the argument
The decomposed energy guidance that steers source-trained diffusion trajectories toward target-domain distributions by balancing return, domain, and behavior mismatch terms.
If this is right
- Trajectory-level generation avoids the error accumulation that occurs with transition-level model-based methods over long horizons.
- The adapted trajectories can be used directly for diffusion planning under dynamics shifts.
- The same trajectories serve as synthetic data that improves downstream target policy learning.
- Adaptation to new target dynamics requires only energy guidance and does not necessitate retraining the diffusion model.
Where Pith is reading between the lines
- The same guidance decomposition could be applied to other generative models besides diffusion to handle domain shifts in sequential decision tasks.
- If the energy terms interact in ways not captured by the current decomposition, performance may degrade on tasks with very large dynamics gaps.
- Combining the generated trajectories with limited online interaction in the target domain offers a natural next step for further coverage improvement.
Load-bearing premise
The energy guidance derived from minimizing the distribution mismatch between source and target trajectories can be decomposed into return, domain, and behavior components that produce useful adapted trajectories without introducing new errors or biases.
What would settle it
An experiment in which policies trained on CEDGE-generated trajectories show no improvement or degrade relative to policies trained only on filtered source data across the ODRL benchmark tasks would falsify the central claim.
Figures
read the original abstract
Off-dynamics offline reinforcement learning seeks to learn a target-domain policy from a large source dataset and a limited target dataset under mismatched transition dynamics. Existing approaches such as reward augmentation and data filtering are constrained to the source dataset and cannot synthesize new target behavior to improve coverage beyond the collected source trajectories. While recent model-based methods attempt to address this by learning target-aware dynamics, the generated experience is constructed only at the transition level, which leads to accumulated errors over long horizons. These limitations necessitate a shift toward trajectory-level generation for off-dynamics offline RL. We propose CEDGE, a Cross-domain Energy-guided Diffusion GEneration framework. CEDGE trains a trajectory diffusion model on source-domain trajectories and adapts the generated samples to the target domain through energy guidance. This guidance is derived by minimizing the distribution mismatch between the source and desired target-domain trajectories and is decomposed into return, domain, and behavior energy components. The resulting energy-guided trajectories are useful both for direct planning and as synthetic data for policy learning. Since target adaptation is achieved via energy guidance rather than retraining the diffusion model, CEDGE can be efficiently adapted to new target dynamics compared to previous methods. Experiments on the ODRL benchmark demonstrate that trajectory-level energy-guided generation improves diffusion planning under dynamics shifts and produces synthetic data that improves downstream target policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CEDGE, a framework for off-dynamics offline RL that trains a trajectory diffusion model on source-domain data and adapts generated trajectories to the target domain via energy guidance. The guidance is obtained by minimizing source-target distribution mismatch and is decomposed into return, domain, and behavior energy components; the adapted trajectories are used both for direct planning and as synthetic data to improve target policy learning. Experiments on the ODRL benchmark are claimed to show improvements over prior methods, with the key advantage that adaptation occurs via guidance rather than model retraining.
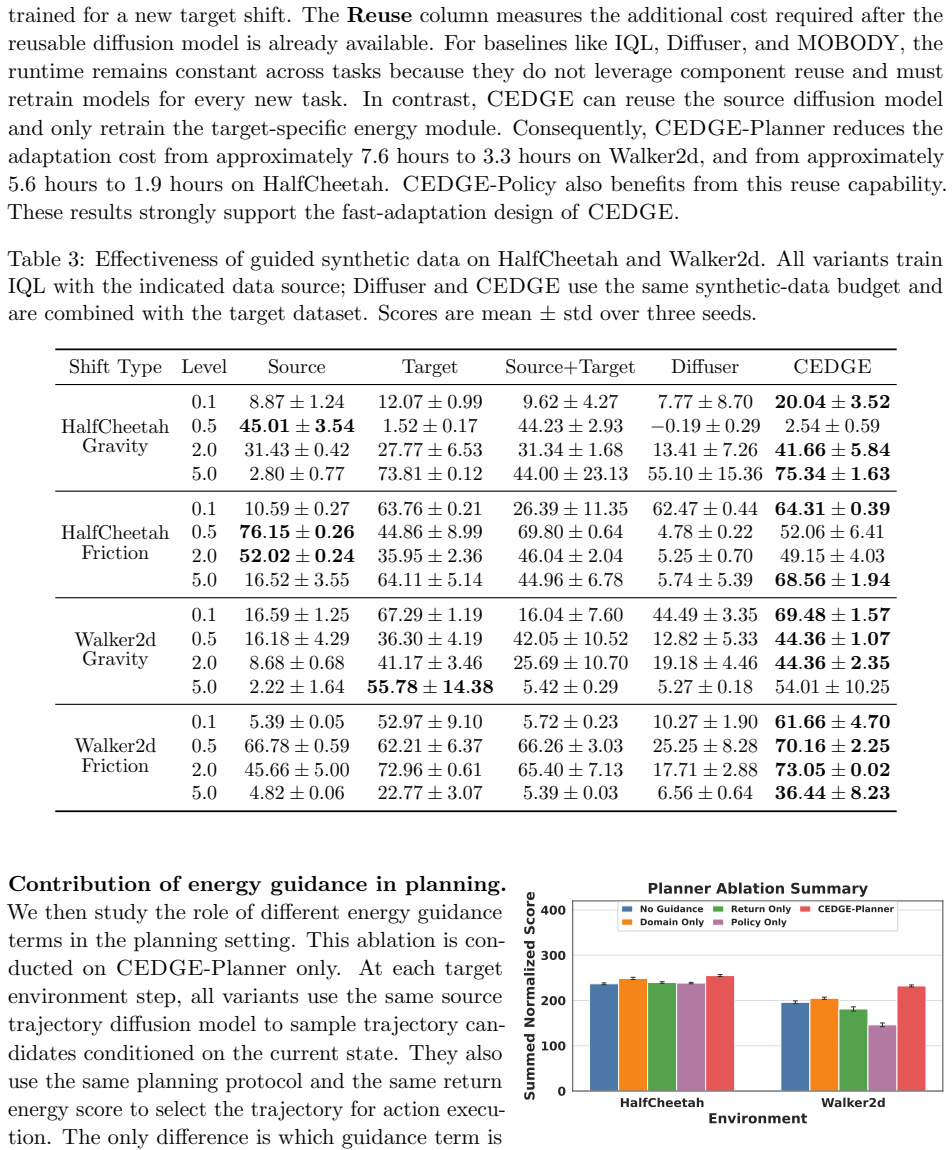
Significance. If the energy-guided decomposition produces trajectories that faithfully reduce domain mismatch without introducing new biases or error accumulation, the approach would advance model-based off-dynamics RL by enabling long-horizon synthetic data generation beyond what source datasets or transition-level models can achieve, while supporting efficient target adaptation.
major comments (2)
- [CEDGE method description] The central claim rests on the premise that source-target trajectory mismatch can be minimized by additively decomposing the energy guidance into independent return, domain, and behavior components whose joint optimization recovers (or bounds) the target measure. No derivation establishing this equivalence (e.g., via an exact identity with KL divergence, Wasserstein distance, or other discrepancy) is provided; the construction therefore risks correcting some mismatch dimensions while distorting others, especially over long horizons.
- [Experiments section] The experimental claim that trajectory-level energy-guided generation improves diffusion planning and downstream policy learning on the ODRL benchmark is stated without accompanying equations, implementation details, error bars, or ablation results that would allow verification of the contribution of each energy component.
minor comments (2)
- The abstract (and by extension the manuscript) contains no equations, pseudocode, or hyperparameter details, which hinders technical evaluation of the energy functions and guidance schedule.
- Notation for the three energy components is introduced without explicit functional forms or weighting scheme, making it difficult to assess orthogonality assumptions.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [CEDGE method description] The central claim rests on the premise that source-target trajectory mismatch can be minimized by additively decomposing the energy guidance into independent return, domain, and behavior components whose joint optimization recovers (or bounds) the target measure. No derivation establishing this equivalence (e.g., via an exact identity with KL divergence, Wasserstein distance, or other discrepancy) is provided; the construction therefore risks correcting some mismatch dimensions while distorting others, especially over long horizons.
Authors: We appreciate the referee drawing attention to the theoretical grounding of the decomposition. The energy terms are constructed to address orthogonal aspects of the trajectory distribution (return alignment, dynamics shift, and behavioral consistency) under the assumption that their additive combination approximates the desired target measure. While the current manuscript motivates this decomposition via the structure of the energy function and supports it empirically, we acknowledge that an explicit derivation equating the sum to a particular divergence (or providing a rigorous bound) is not supplied. In the revision we will add a dedicated paragraph in Section 3 that clarifies the approximation argument and, where possible, states the conditions under which the joint optimization reduces domain mismatch without introducing uncontrolled distortion. revision: partial
-
Referee: [Experiments section] The experimental claim that trajectory-level energy-guided generation improves diffusion planning and downstream policy learning on the ODRL benchmark is stated without accompanying equations, implementation details, error bars, or ablation results that would allow verification of the contribution of each energy component.
Authors: We agree that the experimental presentation requires additional rigor for reproducibility and for isolating the contribution of each energy term. In the revised manuscript we will (i) include the explicit equations for the return, domain, and behavior energy functions, (ii) provide full implementation details (network architectures, optimizer settings, guidance scales, and sampling procedures), (iii) report performance with standard error bars computed over multiple random seeds, and (iv) add ablation studies that systematically disable or vary each energy component while measuring effects on both planning success and downstream policy learning. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe CEDGE's energy-guided diffusion approach, including decomposition of guidance into return/domain/behavior components derived from source-target mismatch minimization. However, no equations, derivations, or self-citations are exhibited that reduce any claimed prediction or result to its inputs by construction. The framework applies existing diffusion and energy concepts to off-dynamics RL without shown self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. Empirical claims rest on ODRL benchmark experiments rather than tautological reductions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Weights for return, domain, and behavior energy components
axioms (1)
- domain assumption Energy guidance obtained by minimizing distribution mismatch between source and target trajectories can be decomposed into return, domain, and behavior components that produce useful adapted samples
invented entities (1)
-
Cross-domain energy-guided trajectory diffusion
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ajay, A. , Du, Y. , Gupta, A. , Tenenbaum, J. B. , Jaakkola, T. S. and Agrawal, P. (2023). Is conditional generative modeling all you need for decision making? In The Eleventh International Conference on Learning Representations. ://openreview.net/forum?id=sP1fo2K9DFG
2023
-
[2]
, Kim, J
Chung, H. , Kim, J. , Mccann, M. T. , Klasky, M. L. and Ye, J. C. (2023). Diffusion posterior sampling for general noisy inverse problems. In The Eleventh International Conference on Learning Representations. ://openreview.net/forum?id=OnD9zGAGT0k
2023
-
[3]
Eysenbach, B. , Asawa, S. , Chaudhari, S. , Levine, S. and Salakhutdinov, R. (2020). Off-dynamics reinforcement learning: Training for transfer with domain classifiers. arXiv preprint arXiv:2006.13916
-
[4]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Fu, J. , Kumar, A. , Nachum, O. , Tucker, G. and Levine, S. (2020). D4rl: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
and Gu, S
Fujimoto, S. and Gu, S. S. (2021). A minimalist approach to offline reinforcement learning. Advances in neural information processing systems 34 20132--20145
2021
-
[6]
, Wang, Y
Guo, Y. , Wang, Y. , Shi, Y. , Xu, P. and Liu, A. (2024). Off-dynamics reinforcement learning via domain adaptation and reward augmented imitation. In Advances in Neural Information Processing Systems, vol. 37
2024
-
[7]
, Yang, Y
Guo, Y. , Yang, Y. , Xu, P. and Liu, A. (2026). MOBODY : Model-based off-dynamics offline reinforcement learning. In The Fourteenth International Conference on Learning Representations. ://openreview.net/forum?id=7c0YS3cuno
2026
-
[8]
, Zhou, A
Haarnoja, T. , Zhou, A. , Abbeel, P. and Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning. PMLR
2018
-
[9]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Hansen-Estruch, P. , Kostrikov, I. , Janner, M. , Kuba, J. G. and Levine, S. (2023). Idql: Implicit q-learning as an actor-critic method with diffusion policies. arXiv preprint arXiv:2304.10573
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [10]
-
[11]
, Jain, A
Ho, J. , Jain, A. and Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems 33 6840--6851
2020
- [12]
-
[13]
Janner, M. , Du, Y. , Tenenbaum, J. B. and Levine, S. (2022). Planning with diffusion for flexible behavior synthesis. arXiv preprint arXiv:2205.09991
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Kaelbling, L. P. , Littman, M. L. and Moore, A. W. (1996). Reinforcement learning: A survey. Journal of artificial intelligence research 4 237--285
1996
-
[15]
, Aittala, M
Karras, T. , Aittala, M. , Aila, T. and Laine, S. (2022). Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems 35 26565--26577
2022
-
[16]
, Wang, H
Kong, L. , Wang, H. , Wang, T. , XIONG, G. and Tambe, M. (2025). Composite flow matching for reinforcement learning with shifted-dynamics data. In Advances in Neural Information Processing Systems (D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi and N. Chen, eds.), vol. 38. Curran Associates, Inc. ://proceedings.neurips.cc/paper_files/p...
2025
-
[17]
Offline Reinforcement Learning with Implicit Q-Learning
Kostrikov, I. , Nair, A. and Levine, S. (2021). Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Levine, S. (2018). Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Liu, J. , Zhang, H. and Wang, D. (2022). Dara: Dynamics-aware reward augmentation in offline reinforcement learning. arXiv preprint arXiv:2203.06662
-
[20]
, Zhang, Z
Liu, J. , Zhang, Z. , Wei, Z. , Zhuang, Z. , Kang, Y. , Gai, S. and Wang, D. (2024 a ). Beyond ood state actions: Supported cross-domain offline reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38
2024
-
[21]
, Liu, T.-S
Liu, X.-H. , Liu, T.-S. , Jiang, S. , Chen, R. , Zhang, Z. , Chen, X. and Yu, Y. (2024 b ). Energy-guided diffusion sampling for offline-to-online reinforcement learning. In Proceedings of the 41st International Conference on Machine Learning
2024
- [22]
-
[23]
and Xu, P
Liu, Z. and Xu, P. (2024). Distributionally robust off-dynamics reinforcement learning: Provable efficiency with linear function approximation. In International Conference on Artificial Intelligence and Statistics. PMLR
2024
-
[24]
, Ball, P
Lu, C. , Ball, P. , Teh, Y. W. and Parker-Holder, J. (2023 a ). Synthetic experience replay. Advances in Neural Information Processing Systems 36 46323--46344
2023
-
[25]
, Chen, H
Lu, C. , Chen, H. , Chen, J. , Su, H. , Li, C. and Zhu, J. (2023 b ). Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. In International Conference on Machine Learning. PMLR
2023
-
[26]
, Han, D
Lu, H. , Han, D. , Shen, Y. and Li, D. (2025). What makes a good diffusion planner for decision making? In The Thirteenth International Conference on Learning Representations
2025
-
[27]
Lyu, J., Ma, X., Li, X., and Lu, Z
Lyu, J. , Bai, C. , Yang, J. , Lu, Z. and Li, X. (2024 a ). Cross-domain policy adaptation by capturing representation mismatch. arXiv preprint arXiv:2405.15369
-
[28]
Lyu, J. , Xu, K. , Xu, J. , Yang, J.-W. , Zhang, Z. , Bai, C. , Lu, Z. , Li, X. et al. (2024 b ). Odrl: A benchmark for off-dynamics reinforcement learning. Advances in Neural Information Processing Systems 37 59859--59911
2024
-
[29]
, Yan, M
Lyu, J. , Yan, M. , Qiao, Z. , Liu, R. , Ma, X. , Ye, D. , Yang, J.-W. , Lu, Z. and Li, X. (2025). Cross-domain offline policy adaptation with optimal transport and dataset constraint. In The Thirteenth International Conference on Learning Representations
2025
-
[30]
, Meng, C
Song, J. , Meng, C. and Ermon, S. (2021 a ). Denoising diffusion implicit models. In International Conference on Learning Representations. ://openreview.net/forum?id=St1giarCHLP
2021
-
[31]
, Sohl-Dickstein, J
Song, Y. , Sohl-Dickstein, J. , Kingma, D. P. , Kumar, A. , Ermon, S. and Poole, B. (2021 b ). Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations. ://openreview.net/forum?id=PxTIG12RRHS
2021
- [32]
-
[33]
, Yang, Y
Wang, R. , Yang, Y. , Liu, Z. , Zhou, D. and Xu, P. (2026). Return augmented decision transformer for off-dynamics reinforcement learning. Transactions on Machine Learning Research . ://openreview.net/forum?id=QDVOr5J9Xp
2026
-
[34]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Wang, Z. , Hunt, J. J. and Zhou, M. (2022). Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [35]
- [36]
-
[37]
, Bai, C
Xu, K. , Bai, C. , Ma, X. , Wang, D. , Zhao, B. , Wang, Z. , Li, X. and Li, W. (2023). Cross-domain policy adaptation via value-guided data filtering. Advances in Neural Information Processing Systems 36 73395--73421
2023
-
[38]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type url volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := ...
-
[39]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.