Towards a Universal Causal Reasoner
Pith reviewed 2026-06-30 12:21 UTC · model grok-4.3
The pith
Finetuning LLMs on 66.6K UniCo instances yields 22.9% gains on 18 causal query types and 20.2% better faithfulness in real-world tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
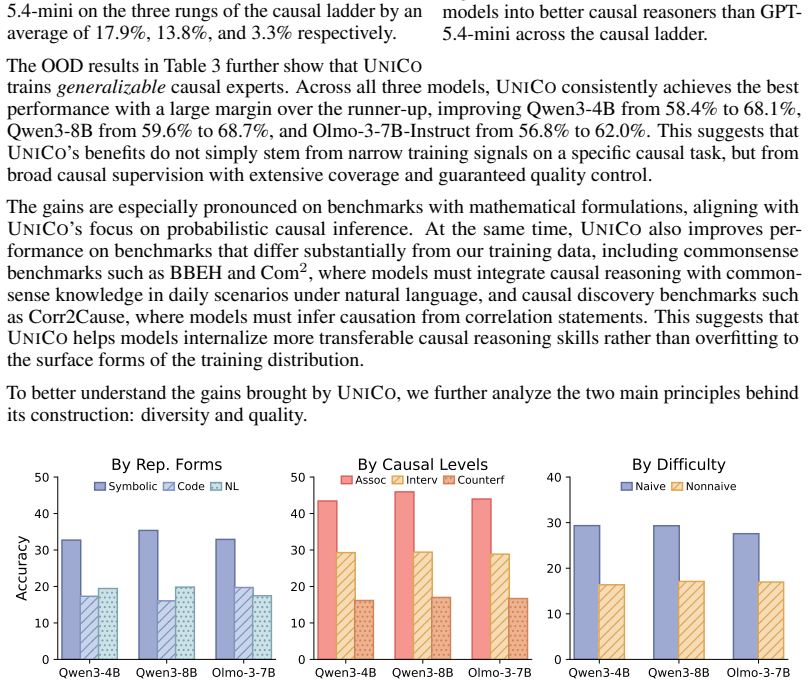
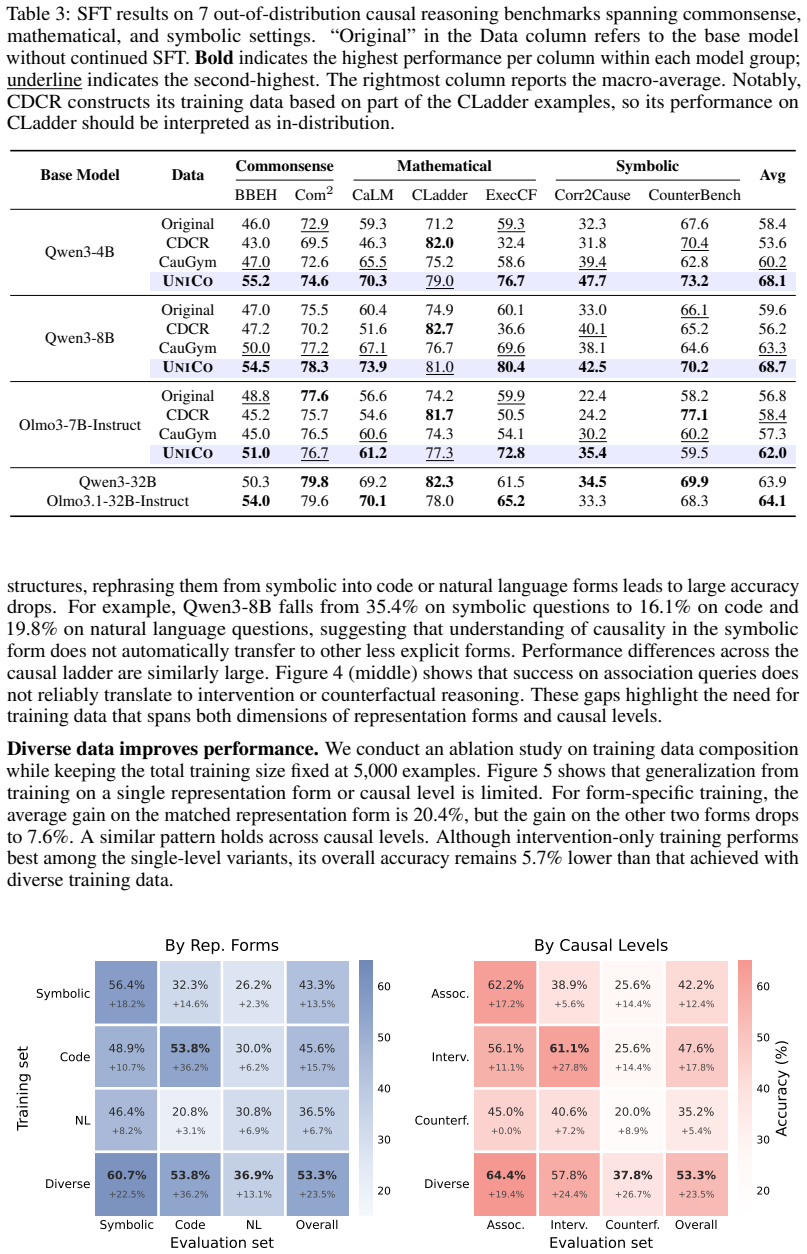
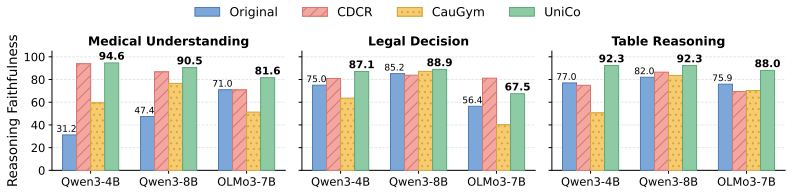
UniCo supplies scalable, high-quality training data that covers every rung of Pearl's Causal Ladder in multiple surface forms; supervised finetuning on this data produces models whose causal reasoning improves 22.9% on the 18 in-distribution types, 8.1% on out-of-distribution benchmarks, and 20.2% in faithfulness metrics on medical, legal, and tabular problems.
What carries the argument
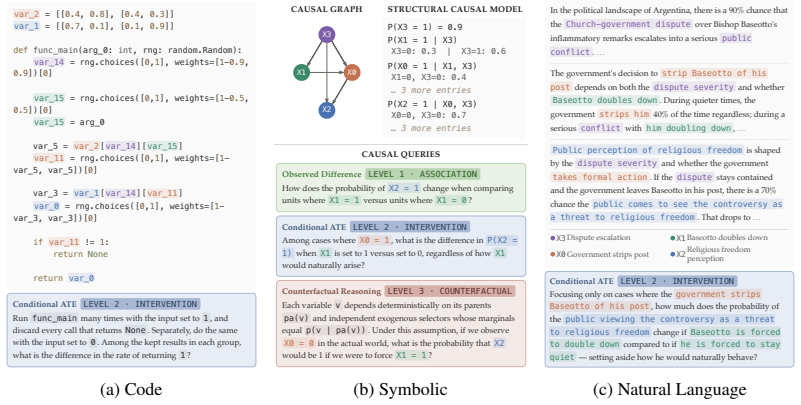
UniCo, a data-generation pipeline that enumerates 18 causal query types, translates symbolic instances into code and natural language, and filters outputs using exact causal inference to eliminate shortcuts.
If this is right
- Average 22.9% improvement across all 18 in-distribution causal query types after finetuning.
- 8.1% higher performance than prior causal data frameworks on seven established out-of-distribution benchmarks.
- 20.2% average increase in faithfulness of reasoning traces on medical, legal, and tabular tasks.
- Causality-centered training equips models with a causal mindset that appears in general reasoning tasks.
Where Pith is reading between the lines
- The same data-generation approach could be applied to produce causal training sets for additional domains such as scientific hypothesis testing.
- Models trained this way may show reduced reliance on spurious correlations even on tasks that do not explicitly mention causality.
- Extending UniCo to generate multi-step or counterfactual chains could further test whether the causal mindset scales to longer reasoning horizons.
Load-bearing premise
That gains measured on the 18 query types and existing benchmarks will transfer to faithful causal reasoning in arbitrary open-ended real-world tasks without extra safeguards or domain adaptation.
What would settle it
A new collection of open-ended medical, legal, or tabular scenarios in which UniCo-trained models produce incorrect causal inferences at rates no lower than the base models.
Figures


read the original abstract
Despite the importance of causal reasoning, training LLMs to reason causally remains underexplored. Existing data efforts mostly focus on benchmarking LLMs on specific aspects of causality, making them less suitable for training generalizable causal reasoners. To address this, we propose UniCo, a data generation framework that both (1) addresses 18 causal query types across Pearl's Causal Ladder and (2) translates natively symbolic examples into code and natural language forms to simulate real-world use cases where causal terms are not explicitly specified. To ensure data quality, UniCo grounds answers with exact causal inference and filters cases with reasoning shortcuts. Upon supervised finetuning with 66.6K UniCo-generated instances, Qwen3-4B, Qwen3-8B and Olmo-3-7B-Instruct achieve an average of 22.9% improvements across all 18 in-distribution query types, and 8.1% over state-of-the-art causal data generation frameworks on 7 established causal benchmarks outside the training distribution. More importantly, in real-world medical understanding, legal decision, and tabular reasoning, UniCo-trained models consistently display more faithful reasoning traces, outperforming the base models by an average of 20.2% in faithfulness metrics. These suggest that causality-centered training not only strengthens causal reasoning, but also equips LLMs with a causal mindset in general reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniCo, a data generation framework that produces 66.6K training instances covering 18 causal query types across Pearl's Causal Ladder. Symbolic examples are translated into natural language and code to simulate real-world scenarios; answers are grounded via exact causal inference and cases with reasoning shortcuts are filtered. Supervised fine-tuning of Qwen3-4B, Qwen3-8B and Olmo-3-7B-Instruct on this data yields reported average gains of 22.9% across the 18 in-distribution query types, 8.1% over prior causal data frameworks on 7 external benchmarks, and 20.2% in faithfulness metrics on real-world medical, legal and tabular tasks.
Significance. If the data-generation claims hold, the work would supply a scalable resource for training LLMs with a causal mindset that generalizes beyond benchmarks, with direct relevance to high-stakes domains. The evaluation design—held-out benchmarks plus separate real-world tasks—avoids circularity and provides evidence of out-of-distribution transfer; the broad coverage of Pearl's ladder is a further strength.
major comments (3)
- [Abstract] Abstract: The central claim that performance gains arise from 'exact causal inference' grounding and 'reasoning shortcut' filtering is load-bearing, yet the manuscript supplies no operational definition, algorithm, pseudocode or post-translation validation procedure for either step. Without these details the 22.9%, 8.1% and 20.2% deltas cannot be attributed to causal understanding rather than data volume or generic instruction effects.
- [Results] Results section (reporting on 66.6K instances and percentage improvements): All quantitative claims are presented without error bars, confidence intervals, dataset statistics (e.g., per-query-type counts), or ablation studies that isolate the filtering/grounding components from simply scaling instruction data.
- [Evaluation on real-world tasks] Real-world task evaluation: The assertion of 'more faithful reasoning traces' on medical, legal and tabular problems rests on faithfulness metrics whose computation, inter-annotator agreement and grounding against verifiable causal structures are not specified, undermining the claim that gains reflect a causal mindset rather than surface-level improvements.
minor comments (1)
- [Abstract] The abstract refers to 'state-of-the-art causal data generation frameworks' without explicit citations in the provided text; these should be listed with precise references.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which will help improve the clarity and rigor of our manuscript. We provide point-by-point responses to the major comments below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that performance gains arise from 'exact causal inference' grounding and 'reasoning shortcut' filtering is load-bearing, yet the manuscript supplies no operational definition, algorithm, pseudocode or post-translation validation procedure for either step. Without these details the 22.9%, 8.1% and 20.2% deltas cannot be attributed to causal understanding rather than data volume or generic instruction effects.
Authors: We acknowledge the referee's concern regarding the lack of detailed operational definitions in the abstract. While the full manuscript describes the data generation process in Section 3, we agree that explicit algorithms and pseudocode are necessary to substantiate the claims. In the revised manuscript, we will add pseudocode for the exact causal inference grounding step, which uses the do-operator and intervention on the causal graph for each query type, and for the reasoning shortcut filtering, which identifies and removes instances where the answer is determinable via non-causal heuristics such as keyword matching. We will also include examples of post-translation validation. These changes will strengthen the link between the reported performance gains and the causal components of UniCo. revision: yes
-
Referee: [Results] Results section (reporting on 66.6K instances and percentage improvements): All quantitative claims are presented without error bars, confidence intervals, dataset statistics (e.g., per-query-type counts), or ablation studies that isolate the filtering/grounding components from simply scaling instruction data.
Authors: We agree that the results would benefit from additional statistical rigor and ablations. We will update the Results section to include error bars based on multiple training runs, a breakdown of the 66.6K instances by query type, and ablation experiments that compare models trained on the full UniCo dataset versus subsets without the grounding or filtering steps. This will help demonstrate that the gains are not solely due to increased data volume. revision: yes
-
Referee: [Evaluation on real-world tasks] Real-world task evaluation: The assertion of 'more faithful reasoning traces' on medical, legal and tabular problems rests on faithfulness metrics whose computation, inter-annotator agreement and grounding against verifiable causal structures are not specified, undermining the claim that gains reflect a causal mindset rather than surface-level improvements.
Authors: The referee raises a valid point about the specification of the faithfulness evaluation. We will revise the corresponding section to provide a detailed description of the faithfulness metric computation, including the criteria used by annotators, the inter-annotator agreement scores (which we will compute if not already reported), and how the metrics are anchored to verifiable causal structures in each domain. This will clarify that the improvements reflect enhanced causal reasoning rather than superficial changes. revision: partial
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper proposes the UniCo data-generation framework, generates 66.6K instances covering 18 causal query types, performs supervised finetuning, and reports accuracy/faithfulness gains on held-out in-distribution query types plus 7 external causal benchmarks and separate real-world medical/legal/tabular tasks. All reported deltas are measured on quantities defined outside the training loop (standard benchmarks, human faithfulness annotations). No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain. The filtering and grounding steps are described at a high level but do not reduce any performance claim to a tautology by construction. The evaluation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Supervised finetuning on synthetic causal examples improves both in-distribution causal query performance and out-of-distribution faithfulness in downstream tasks
- domain assumption Exact causal inference can be used to ground answers and filter reasoning shortcuts in generated data
invented entities (1)
-
UniCo data generation framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=DZjbL9BuHs. Poster. K. Lu and T. M. Lab. On-policy distillation.Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation. T. Olmo, A. Ettinger, A. Bertsch, B. Kuehl, D. Graham, D. Heineman, D. Groeneveld, F. Brahman, F. Timbers, H. Ivison, et al. Olmo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.64434/tml.20251026 2025
-
[2]
Preprint available on arXiv. K. Xiong, X. Ding, Y . Cao, Y . Yan, L. Du, Y . Zhang, J. Gao, J. Liu, B. Qin, and T. Liu. Com2: A causal-guided benchmark for exploring complex commonsense reasoning in large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16119–16140, 2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/ 2025
-
[3]
counterfactual
Com2 [Xiong et al., 2025] is a causal-guided benchmark for complex commonsense reasoning, where examples are constructed around causal event graphs and scenario modifications. After quality inspection, we decide to only use its “counterfactual” and “decision” subsets for their advanced verifiability, resulting in991examples altogether. The reported metric isF1
2025
-
[4]
causal judgment
BBEH[Kazemi et al., 2025] is a broad reasoning benchmark designed to extend BIG-Bench Hard with more difficult tasks that probe similar reasoning capabilities. We only use its causal understanding subset, which includes200examples: 142 under the “causal judgment” task and 58 under the “necessary and sufficient conditions” task. The reported metric isaccuracy
2025
-
[5]
We include both two subsets: a comprehensive V1 subset and a backdoor-only V2 subset
CounterBench[Chen et al., 2025b] evaluates counterfactual reasoning under formal causal rules, with questions designed around diverse causal structures and counterfactual query forms. We include both two subsets: a comprehensive V1 subset and a backdoor-only V2 subset. This gives 1,200examples altogether, and the reported metric isaccuracy
-
[6]
We only take its test split, with1,162examples
Corr2Cause[Jin et al., 2024] tests whether models can infer causal relations from correlational statements, aiming to isolate causal inference from commonsense retrieval. We only take its test split, with1,162examples. Due to strong label imbalance, we report theF1metric
2024
-
[7]
We take all of its examples, resulting in 10,112examples altogether
CLadder[Jin et al., 2023] assesses formal causal reasoning in natural language across graph-based association, intervention, and counterfactual queries. We take all of its examples, resulting in 10,112examples altogether. The reported metric isaccuracy
2023
-
[8]
We only take its if-else test split in the code domain, with500examples altogether
Executable Counterfactuals[Vashishtha et al., 2026] operationalizes counterfactual reasoning through executable code and math problems that require explicit counterfactual reasoning steps. We only take its if-else test split in the code domain, with500examples altogether. Since each question may have multiple answers, the reported metric isF1
2026
-
[9]
We only take CaLM- Lite, a publicly available lightweight version
CaLM[Chen et al., 2024] is a comprehensive causal evaluation benchmark that organizes causal targets, adaptations, metrics, and error analyses across a broad design space. We only take CaLM- Lite, a publicly available lightweight version. Moreover, we exclude subsets that use data from the other six benchmarks, leaving3,900examples altogether. The reporte...
2024
-
[10]
For each question, the sampling budget for each model is 2
SFT response curation.We curate SFT responses with rejection sampling based on an ensemble of three strong open-source LLMs [Zhang et al., 2025]: Qwen3-32B, Olmo-3.1-32B-Instruct, and Qwen3.5-27B. For each question, the sampling budget for each model is 2. If multiple sampled responses lead to the correct final answer, we randomly select one of them. If n...
2025
-
[11]
SFT training.We use LlamaFactory [Zheng et al., 2024] for Qwen3-4B and Qwen3-8B, and use the Axolotl Framework3 for Olmo-3-7B-Instruct. Notably, for all Qwen3 experiments throughout this work, we follow prior paradigms [Hübotter et al., 2026] by adopting the instruct mode (i.e., 3https://docs.axolotl.ai/ 26 setting enable_thinking=False when applying the ...
2024
-
[12]
medical understanding
Evaluation.We use the vLLM framework [Kwon et al., 2023] for evaluation. Throughout all experiments in this work, we adopt temperature=0.7, top_p=0.8 for Qwen3 models and temperature=0.6, top_p=0.95 for Olmo-3 models, following their respective recommended practices. For proprietary models such as GPT-5.4-mini (Table 2), they are evaluated with no extra t...
2023
-
[13]
Map each symbolic node in the causal graph to a real-world entity, as listed below: ```json <entity_interpretation_json> ```
-
[14]
In light of this, you should articulate the question under the provided context in a highly natural manner like a real piece of narrative
The ultimate goal of such conversion is to make it necessary for test takers to carefully read through the natural language question in order to understand all the causal and probabilistic relationships among entities, instead of easily spotting them at first glance. In light of this, you should articulate the question under the provided context in a high...
-
[15]
force",
Note that the conversion only alters how the causal question is expressed, but the underlying causal semantics must be preserved exactly. More specifically, ALL the provided causal relationships between entities and ALL the listed probability conditions MUST still occur in the converted question, so that it still has the same final numerical answer as the...
-
[16]
Output ONLY the converted natural- language question text itself
You should be moderately concise and NOT verbose. Output ONLY the converted natural- language question text itself. Do NOT include any preamble, explanation, commentary, quotation marks, or markdown formatting around the question. 31 For longer examples, we also use a three-step variant that decomposes Prompt 1 into two calls: first assign only real-world...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.