X-Foresight: A Joint Vision-Action Causal Forecasting Network via Predictive World Modeling
Pith reviewed 2026-06-30 12:03 UTC · model grok-4.3
The pith
X-Foresight integrates chunk-wise video forecasting into VLA models to learn physical dynamics and long-term causality for improved planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
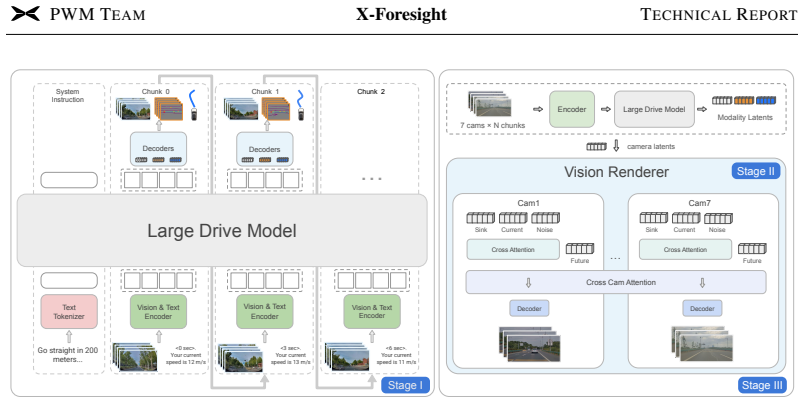
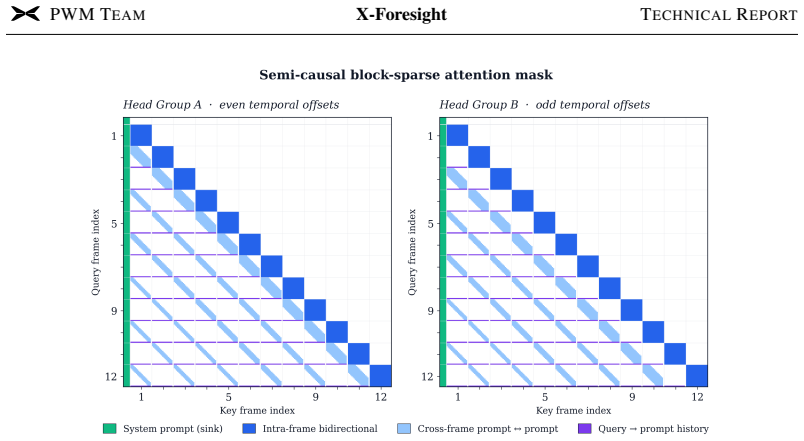
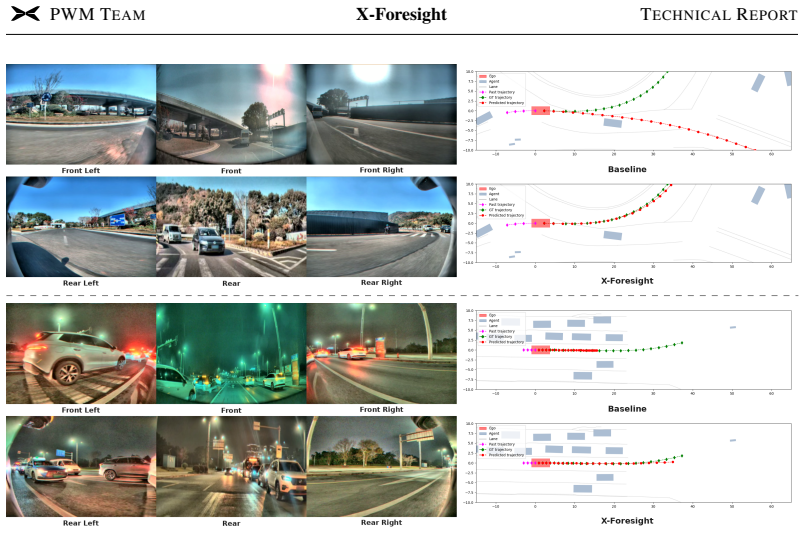
X-Foresight is a predictive world model placed inside a VLA network that uses a long-horizon chunk-wise auto-regressive strategy to forecast future video, thereby internalizing physical dynamics and causality; dense frames within chunks handle instantaneous motion while sparse transitions between chunks capture longer causal structure, and the same representations support real-time action control.
What carries the argument
The long-horizon chunk-wise auto-regressive strategy that predicts semantically distant chunks instead of adjacent frames, keeping dense intra-chunk frames for short-term dynamics and sparse inter-chunk transitions for long-term causality.
If this is right
- VLA models gain internal knowledge of physical dynamics without separate pre-training stages.
- Planning success rates rise while video generation quality stays high.
- Curriculum lengthening of prediction horizons stabilizes training for longer sequences.
- Focusing supervision on ego-motion and behavior signals improves attention to safety-critical future segments.
- A separate diffusion renderer can be attached to produce photorealistic output without changing the forecasting core.
Where Pith is reading between the lines
- The chunk separation idea could be tested on non-driving video domains such as manipulation or navigation in unstructured environments.
- The same architecture might reduce reliance on real-world interaction data by allowing more efficient use of passive video for pre-training.
- If the importance sampling heuristic proves general, similar signals could be derived from other sensor streams to guide long-horizon supervision.
Load-bearing premise
Predicting semantically distant chunks rather than adjacent frames will avoid trivial repetition while still letting the model learn both immediate motion and extended causal relationships through the chunk structure.
What would settle it
A controlled comparison on the same planning benchmarks in which a standard next-frame VLA baseline achieves equal or higher success rates than the chunk-wise version would falsify the central claim.
Figures



read the original abstract
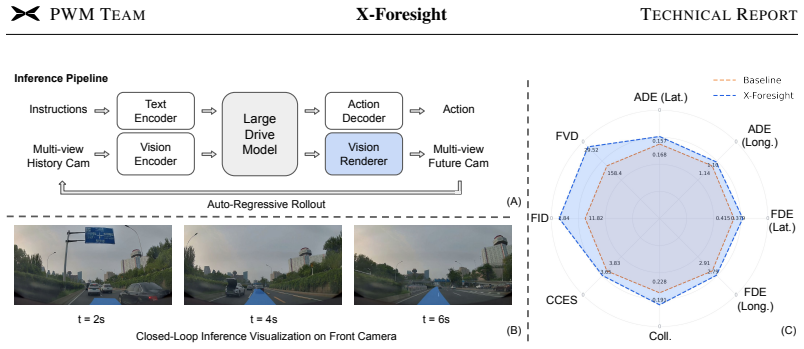
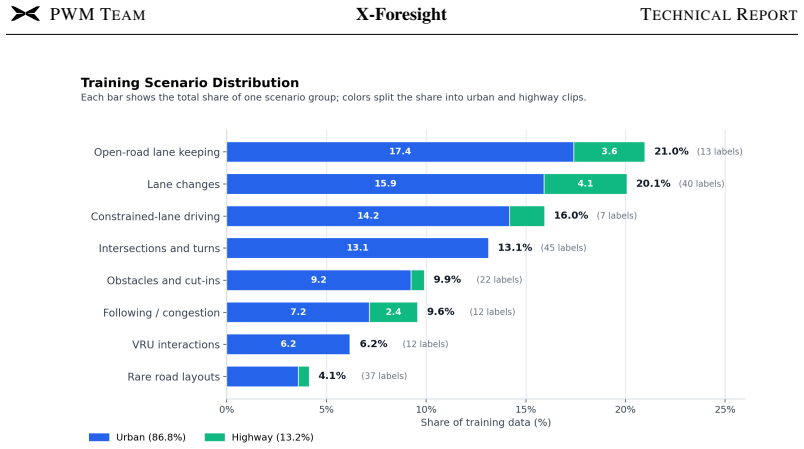
Physical world knowledge resides mainly in videos. Equipping Vision-Language-Action (VLA) models with such knowledge is fundamental for safe and generalizable planning. Predictive world modeling enables VLA to internalize physical dynamics and long-term causality by predicting future video from past observations. However, naive next-frame prediction faces two challenges: 1) unlike semantically distinct text tokens, video tokens are low-entropy and redundant, causing prediction to degenerate into trivial extrapolation. 2) world modeling poses a temporal dilemma: dense prediction captures instantaneous dynamics, but cannot efficiently model long-horizon causality. To learn world knowledge effectively, we introduce X-Foresight, a predictive world model integrated directly into the VLA architecture to jointly learn world modeling and real-time action control. At its core lies a long-horizon chunk-wise auto-regressive strategy that addresses both challenges: by predicting semantically distant chunks rather than adjacent frames, it escapes trivial extrapolation, while preserving dense intra-chunk frames for instantaneous dynamics and sparse inter-chunk transitions for long-term causality. A curriculum learning schedule progressively extends prediction horizons and stabilizes long-horizon training. To capture long-term causality effectively, we present temporal importance sampling, which concentrates supervision on safety-critical chunks identified by ego-motion and behavioral signals. We further delegate photorealistic synthesis to a diffusion-based multi-view renderer, improving photorealistic appearance. Comprehensive experiments demonstrate that X-Foresight significantly outperforms VLA baselines in planning performance while maintaining strong generative fidelity, establishing a robust paradigm for world-knowledge-driven autonomous systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes X-Foresight, a predictive world model integrated into Vision-Language-Action (VLA) architectures. It introduces a long-horizon chunk-wise auto-regressive prediction strategy that predicts semantically distant chunks (with dense intra-chunk frames and sparse inter-chunk transitions), a curriculum learning schedule to extend horizons, temporal importance sampling focused on safety-critical chunks via ego-motion and behavioral signals, and delegation of photorealistic synthesis to a diffusion-based multi-view renderer. The central claim is that this joint vision-action causal forecasting approach enables effective internalization of physical dynamics and long-term causality, yielding significantly better planning performance than VLA baselines while preserving generative fidelity.
Significance. If the experimental claims hold, the work could advance world-knowledge-driven autonomous systems by providing a concrete mechanism to overcome low-entropy video prediction degeneracy and the dense-vs-long-horizon tradeoff in VLA models.
major comments (1)
- [Abstract] Abstract: the claim that X-Foresight 'significantly outperforms VLA baselines in planning performance' is presented without any quantitative results, baselines, metrics, ablation studies, or experimental setup, preventing any evaluation of whether the chunk-wise strategy, curriculum, or importance sampling produces the asserted gains or reduces to self-referential signals.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater specificity in the abstract. The manuscript's experimental section provides the requested quantitative support, but we agree the abstract can be strengthened by incorporating key results to better contextualize the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that X-Foresight 'significantly outperforms VLA baselines in planning performance' is presented without any quantitative results, baselines, metrics, ablation studies, or experimental setup, preventing any evaluation of whether the chunk-wise strategy, curriculum, or importance sampling produces the asserted gains or reduces to self-referential signals.
Authors: The abstract is intentionally concise and summarizes the core findings, with full quantitative details—including specific planning metrics (e.g., success rates on long-horizon tasks), baseline comparisons (standard VLA models), ablation studies isolating the chunk-wise autoregressive prediction, curriculum schedule, and temporal importance sampling, plus experimental setups—provided in Sections 4 (Experiments) and 5 (Ablations). These results demonstrate that the gains arise from the proposed mechanisms rather than self-referential signals, as ablations show performance drops when components are removed. To address the concern directly, we will revise the abstract to include 1-2 key quantitative highlights (e.g., relative improvement percentages) while preserving its brevity. revision: yes
Circularity Check
No significant circularity; derivation self-contained in abstract
full rationale
The provided abstract describes a chunk-wise autoregressive strategy, curriculum learning, and temporal importance sampling as architectural choices for addressing next-frame prediction issues, but contains no equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems. No load-bearing step reduces by construction to its inputs; the central claim of outperformance is presented as an empirical result rather than a definitional equivalence. Without equations or self-referential derivations in the given text, the derivation chain remains independent of the inputs it claims to predict.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Situation Perception: A Necessary Primitive to Artificial Superintelligence
Situation perception is proposed as a necessary primitive for artificial superintelligence, requiring abstract prediction, long-term compressed memory, and objective-guided active learning.
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15619–15629, 2023
2023
-
[2]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
2024
-
[3]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[4]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InInternational Conference on Learning Representations, volume 2024, pages 35549–35562, 2024
2024
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model.arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Yuan Gao, Chen Chen, Tianrong Chen, and Jiatao Gu. One layer is enough: Adapting pretrained visual encoders for image generation.ArXiv, 2512.07829, 2025
-
[8]
Block Sparse Attention.https://github.com/mit-han-lab/Block-Sparse-Attention, 2024
Junxian Guo, Haotian Tang, Shang Yang, Zhekai Zhang, Zhijian Liu, and Song Han. Block Sparse Attention.https://github.com/mit-han-lab/Block-Sparse-Attention, 2024
2024
-
[9]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
2017
-
[10]
Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Information Processing Systems (NeurIPS), 38:167283–167308, 2026
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Information Processing Systems (NeurIPS), 38:167283–167308, 2026
2026
-
[11]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Marble: World Labs Spatial Intelligence.https://www.worldlabs.ai/, 2026
World Labs. Marble: World Labs Spatial Intelligence.https://www.worldlabs.ai/, 2026. 18 PWM TEAMX-ForesightTECHNICALREPORT
2026
-
[13]
Radial attention: O(nlogn) sparse attention with energy decay for long video generation
Xingyang Li, Muyang Li, Tianle Cai, Haocheng Xi, Shuo Yang, Yujun Lin, Lvmin Zhang, Songlin Yang, Jinbo Hu, Kelly Peng, et al. Radial attention: O(nlogn) sparse attention with energy decay for long video generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[14]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[15]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023
2023
-
[16]
SVG: Latent diffusion model without variational autoencoder.arXiv:2510.15301, 2025
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. SVG: Latent diffusion model without variational autoencoder.arXiv:2510.15301, 2025
-
[17]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
XPeng VLA 2.0.https://www.xpeng.com, 2026
XPeng Inc. XPeng VLA 2.0.https://www.xpeng.com, 2026
2026
-
[20]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22963–22974, 2025
2025
-
[21]
Helios: Real real-time long video generation model.arXiv preprint arXiv:2603.04379, 2026
Shenghai Yuan, Yuanyang Yin, Zongjian Li, Xinwei Huang, Xiao Yang, and Li Yuan. Helios: Real real-time long video generation model.arXiv:2603.04379, 2026
-
[22]
Chaoda Zheng, Sean Li, Jinhao Deng, Zhennan Wang, Shijia Chen, Liqiang Xiao, Ziheng Chi, Hongbin Lin, Kangjie Chen, Boyang Wang, et al. X-world: Controllable ego-centric multi-camera world models for scalable end-to-end driving.arXiv:2603.19979, 2026
-
[23]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), pages 2165–2183. PMLR, 2023. 19
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.