Mitigating Object Hallucinations in Vision-Language Models through Region-Aware Attention Recalibration
Pith reviewed 2026-06-30 11:34 UTC · model grok-4.3
The pith
A training-free region-aware attention recalibration reduces object hallucinations in vision-language models by anchoring to statistical midpoints and modulating penalties from head disagreements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
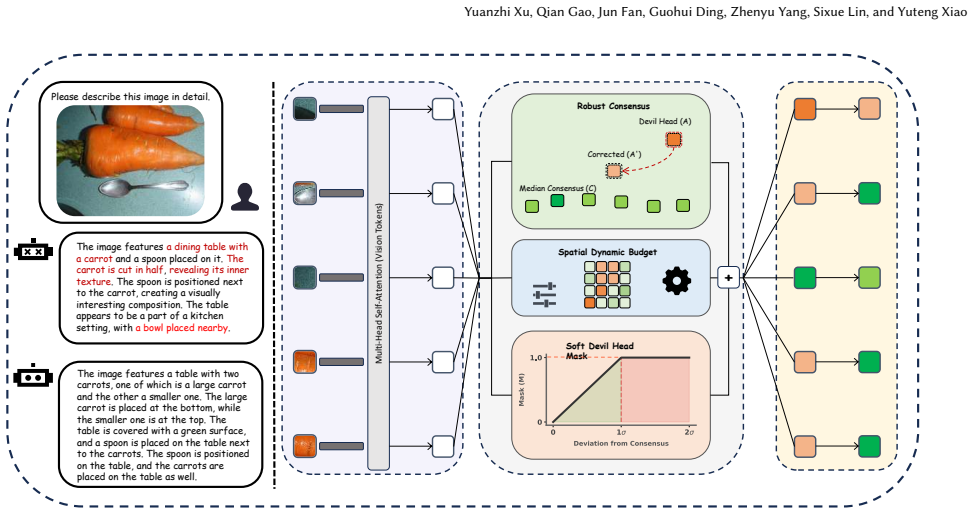
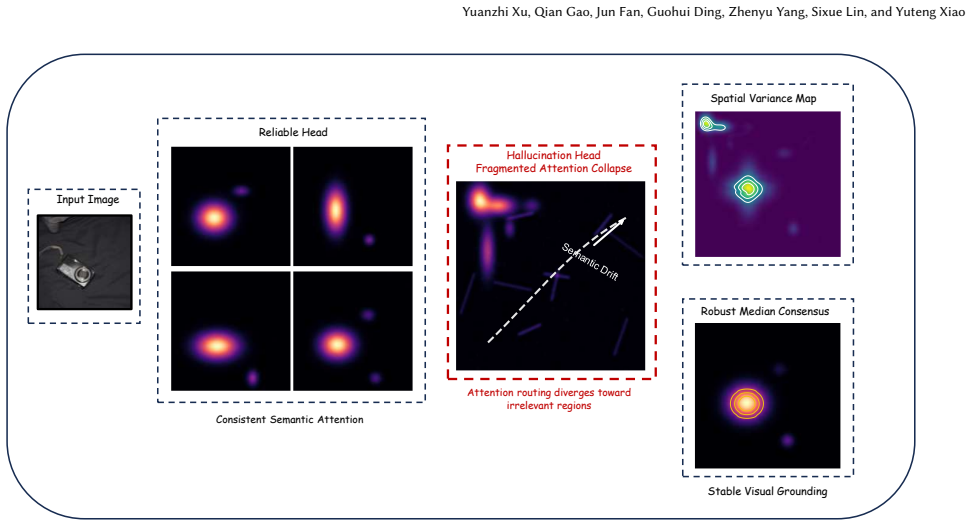
The central claim is that an outlier-resistant statistical midpoint across attention heads serves as a reliable anchor for visual representations, and inter-head disagreement mapped across regions can dynamically set intervention levels for continuous penalty modulation that suppresses hallucination-inducing attention paths, thereby rectifying visual-semantic misalignments without compromising generative fluency or language priors.
What carries the argument
Region-aware adaptive weighting mechanism that computes an outlier-resistant statistical midpoint across attention heads as a stable anchor and uses inter-head disagreement across regions to determine continuous penalty modulation for suppressing problematic attention paths.
If this is right
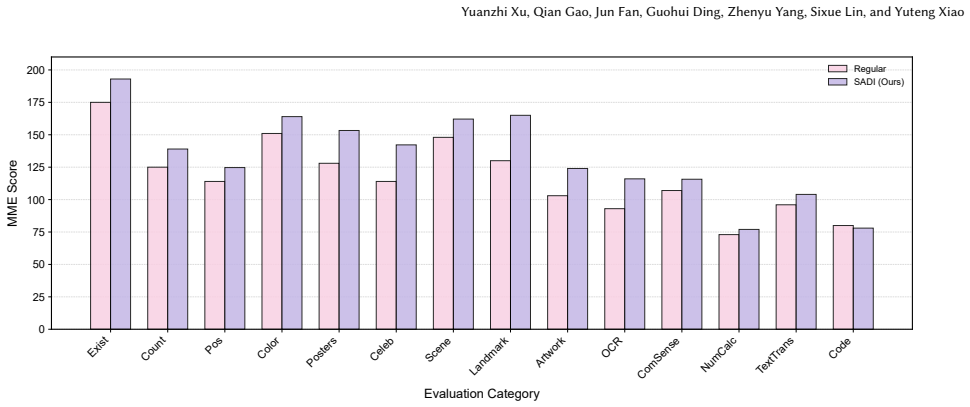
- Substantially reduces both instance-level and sentence-level object hallucinations.
- Achieves state-of-the-art performance on CHAIR, POPE, and MME benchmarks compared to contemporary baselines.
- Operates as a training-free inference strategy, preserving computational efficiency.
- Maintains generative fluency and language priors by avoiding abrupt truncations or fine-tuning.
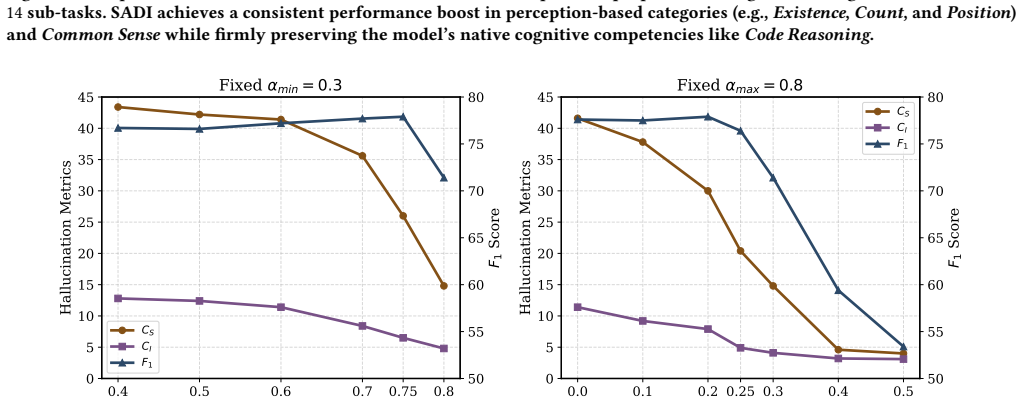
- Provides algorithmic robustness through dynamic, region-specific interventions.
Where Pith is reading between the lines
- If the method works, it could be extended to other types of hallucinations beyond objects, such as attribute or relation errors.
- The approach suggests that attention head disagreements can serve as a general signal for detecting semantic drift in multimodal models.
- Future work might test whether this recalibration affects performance on tasks requiring high creativity or long-context reasoning.
- Applying similar statistical anchoring to other model components like feed-forward layers could yield further gains.
Load-bearing premise
That combining an outlier-resistant midpoint across heads with regional inter-head disagreement reliably identifies hallucination paths and that continuous penalty modulation fixes misalignments without creating new errors or harming fluency.
What would settle it
A test on the CHAIR or POPE benchmark where the method increases the hallucination rate or decreases fluency metrics relative to the unadjusted baseline model.
Figures

read the original abstract
The generation of factually incorrect objects, commonly known as object hallucination, remains a persistent challenge in Large Vision-Language Models (LVLMs). Current approaches to address this issue - ranging from expensive data-driven fine-tuning and high-latency contrastive decoding to rigid attention head truncation - frequently compromise either computational efficiency or the continuity of the model's feature space. To overcome these limitations, we introduce a novel, training-free inference strategy that operates as a region-aware adaptive weighting mechanism to dynamically correct semantic drift without relying on abrupt heuristic truncations. By computing an outlier-resistant statistical midpoint across various attention heads, we establish a stable anchor for reliable visual representations. We then utilize the inter-head disagreement mapped across regions to dynamically determine intervention budgets, gently suppressing hallucination-inducing attention paths through a continuous penalty modulation. This recalibration process effectively rectifies visual-semantic misalignments while fully preserving generative fluency and language priors. Comprehensive evaluations on standard multimodal benchmarks, including CHAIR, POPE, and MME, reveal that our strategy substantially curtails both instance- and sentence-level hallucinations. The results demonstrate state-of-the-art performance against contemporary baselines, confirming our method's efficiency and algorithmic robustness. Our code will be public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a training-free inference strategy for mitigating object hallucinations in large vision-language models (LVLMs). The method performs region-aware attention recalibration by first computing an outlier-resistant statistical midpoint across attention heads to establish a stable visual anchor, then mapping inter-head disagreement across regions to set dynamic intervention budgets, and finally applying continuous penalty modulation to suppress hallucination-inducing attention paths. This is claimed to correct visual-semantic misalignments while preserving generative fluency and language priors. Comprehensive evaluations on CHAIR, POPE, and MME benchmarks are reported to show substantial reductions in both instance- and sentence-level hallucinations, achieving state-of-the-art performance relative to contemporary baselines.
Significance. If the reported performance gains hold under full scrutiny, the approach would offer a computationally lightweight, training-free alternative to fine-tuning or contrastive decoding methods that often trade off efficiency or fluency. The explicit commitment to public code release strengthens reproducibility and enables direct verification of the statistical midpoint and disagreement-based budget mechanisms.
minor comments (2)
- [Abstract] The abstract states that the method 'fully preserv[es] generative fluency and language priors' but provides no quantitative metrics (e.g., perplexity, fluency scores, or human preference rates) to support this claim; adding such numbers in §4 or Table X would make the preservation claim verifiable.
- [Abstract] The description of 'outlier-resistant statistical midpoint' and 'inter-head disagreement mapped across regions' is given at a high level; explicit definitions (e.g., which robust estimator is used, how regions are delineated) would clarify the pipeline before the results section.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our training-free region-aware attention recalibration approach and for acknowledging its potential as a lightweight alternative to fine-tuning or contrastive methods. The recommendation of 'uncertain' is noted, but no specific major comments were provided in the report for us to address point-by-point.
Circularity Check
No significant circularity
full rationale
The paper presents a training-free inference-time recalibration that computes an outlier-resistant statistical midpoint across attention heads and uses inter-head disagreement to set continuous penalty budgets. These quantities are defined directly from the model's internal activations on a given input; the subsequent evaluations on CHAIR, POPE and MME are external benchmarks whose labels are not used to fit any parameter inside the method. No equation or claim reduces by construction to a fitted value or to a self-citation chain; the derivation chain remains self-contained and falsifiable against independent data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention heads contain separable reliable and hallucination-inducing signals that can be isolated via statistical midpoint and inter-head disagreement.
Reference graph
Works this paper leans on
-
[1]
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, and Shijian Lu. 2025. Mitigating object hallucinations in large vision-language models with assembly of global and local attention. In Proceedings of the Computer Vision and Pattern Recognition Conference. 29915– 29926
2025
-
[2]
Jiaqi Bai, Hongcheng Guo, Zhongyuan Peng, Jian Yang, Zhoujun Li, Mohan Li, and Zhihong Tian. 2025. Mitigating hallucinations in large vision-language models by adaptively constraining information flow. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23442–23450
2025
-
[3]
Junzhe Chen, Tianshu Zhang, Shiyu Huang, Yuwei Niu, Linfeng Zhang, Lijie Wen, and Xuming Hu. 2025. Ict: Image-object cross-level trusted intervention for mitigating object hallucination in large vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference. Computer Vision Foundation / IEEE, 4209–4221
2025
-
[4]
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao
-
[5]
Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Jianing Yang, David F Fouhey, Joyce Chai, and Shengyi Qian. 2024. Multi-object hallucination in vision language models.Advances in Neural Information Processing Systems37 (2024), 44393–44418
2024
-
[7]
Zhaorun Chen, Zhuokai Zhao, Hongyin Luo, Huaxiu Yao, Bo Li, and Jiawei Zhou
-
[8]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Halc: Object hallucination reduction via adaptive focal-contrast decoding. arXiv preprint arXiv:2403.00425(2024)
-
[9]
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023)2, 3 (2023), 6
2023
-
[10]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. 2023. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models.CoRRabs/2306.13394 (2023). arXiv:2306.13394 doi:10.48550/ ARXIV.2306.13394
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva
- [12]
-
[13]
Anisha Gunjal, Jihan Yin, and Erhan Bas. 2024. Detecting and preventing hallu- cinations in large vision language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 18135–18143
2024
-
[14]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. OPERA: Alleviating Hal- lucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2024...
-
[15]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang
-
[16]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 25004– 25014
-
[17]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Mitigating Object Hallucinations in Vision-Language Models through Region-Aware Attention Recalibration Conference on Computer ...
2024
-
[18]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 292–305
2023
-
[19]
Zhuowei Li, Haizhou Shi, Yunhe Gao, Di Liu, Zhenting Wang, Yuxiao Chen, Ting Liu, Long Zhao, Hao Wang, and Dimitris N Metaxas. 2025. The hidden life of tokens: Reducing hallucination of large vision-language models via visual information steering.arXiv preprint arXiv:2502.03628(2025)
-
[20]
Tian Liang, Yuetian Du, Jing Huang, Ming Kong, Luyuan Chen, Yadong Li, Siye Chen, and Qiang Zhu. 2025. Mole: Decoding by mixture of layer experts alleviates hallucination in large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 18684–18692
2025
-
[21]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
2014
-
[22]
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang
-
[23]
InInternational Conference on Learning Representations, Vol
Mitigating hallucination in large multi-modal models via robust instruction tuning. InInternational Conference on Learning Representations, Vol. 2024. 57689– 57733
2024
-
[24]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 26296–26306
2024
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Asso- ciates Inc., Red Hook, NY, USA, Article 1516, 25 pages
2023
-
[26]
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. 2024. A survey on hallucination in large vision-language models.arXiv preprint arXiv:2402.00253(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Shi Liu, Kecheng Zheng, and Wei Chen. 2024. Paying more attention to im- age: A training-free method for alleviating hallucination in lvlms. InEuropean Conference on Computer Vision. Springer, 125–140
2024
-
[28]
Guangtao Lyu, Qi Liu, Chenghao Xu, Jiexi Yan, Muli Yang, Xueting Li, Fen Fang, and Cheng Deng. 2026. Revealing and Enhancing Core Visual Regions: Harnessing Internal Attention Dynamics for Hallucination Mitigation in LVLMs. arXiv:2602.15556 [cs.CV] https://arxiv.org/abs/2602.15556
-
[29]
Xinyu Lyu, Beitao Chen, Lianli Gao, Jingkuan Song, and Heng T Shen. 2024. Alleviating hallucinations in large vision-language models through hallucination- induced optimization.Advances in Neural Information Processing Systems37 (2024), 122811–122832
2024
-
[30]
Erik Nielsen, Elia Cunegatti, Marcus Vukojevic, and Giovanni Iacca. 2026. Hal- lucination as an Anomaly: Dynamic Intervention via Probabilistic Circuits. arXiv:2605.05953 [cs.CL] https://arxiv.org/abs/2605.05953
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Eunkyu Park, Minyeong Kim, and Gunhee Kim. 2025. Halloc: Token-level localization of hallucinations for vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 29893–29903
2025
- [32]
-
[33]
Yeji Park, Deokyeong Lee, Junsuk Choe, and Buru Chang. 2025. Convis: Con- trastive decoding with hallucination visualization for mitigating hallucinations in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 6434–6442
2025
-
[34]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 4035–4045
2018
-
[35]
Sreetama Sarkar, Yue Che, Alex Gavin, Peter Anthony Beerel, and Souvik Kundu
-
[36]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Mitigating hallucinations in vision-language models through image-guided head suppression. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 12492–12511
2025
- [37]
-
[38]
Jingran Su, Jingfan Chen, Hongxin Li, Yuntao Chen, Li Qing, and Zhaoxiang Zhang. 2025. Activation steering decoding: Mitigating hallucination in large vision-language models through bidirectional hidden state intervention. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers). 12964–12974
2025
- [39]
-
[40]
Xiaoxi Sun, Jianxin Liang, Yueqian Wang, Huishuai Zhang, and Dongyan Zhao
-
[41]
InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence
Understanding visual detail hallucinations of large vision-language models. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence. 1900–1908
1900
-
[42]
Feilong Tang, Chengzhi Liu, Zhongxing Xu, Ming Hu, Zile Huang, Haochen Xue, Ziyang Chen, Zelin Peng, Zhiwei Yang, Sijin Zhou, et al. 2025. Seeing far and clearly: Mitigating hallucinations in mllms with attention causal decoding. In Proceedings of the Computer Vision and Pattern Recognition Conference. 26147– 26159
2025
-
[43]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv 2023.arXiv preprint arXiv:2302.1397110 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[45]
Weixuan Wang, Jingyuan Yang, and Wei Peng. 2025. Semantics-adaptive ac- tivation intervention for llms via dynamic steering vectors. InInternational Conference on Learning Representations, Vol. 2025. 79334–79351
2025
-
[46]
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Fangxun Shu, Hao Jiang, and Linchao Zhu. 2025. Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25543–25551
2025
-
[47]
Le Yang, Ziwei Zheng, Boxu Chen, Zhengyu Zhao, Chenhao Lin, and Chao Shen
-
[48]
Nullu: Mitigating object hallucinations in large vision-language models via halluspace projection.URL https://arxiv. org/abs/2412.13817(2025)
-
[49]
Tianyun Yang, Ziniu Li, Juan Cao, and Chang Xu. 2025. Understanding and mitigating hallucination in large vision-language models via modular attribu- tion and intervention. InThe Thirteenth International Conference on Learning Representations
2025
-
[50]
Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, and Dongsheng Li. 2025. Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10610–10620
2025
-
[51]
Liu Yu, Zhonghao Chen, Ping Kuang, Zhikun Feng, Fan Zhou, Lan Wang, and Gillian Dobbie. 2026. Causally-Grounded Dual-Path Attention Intervention for Object Hallucination Mitigation in LVLMs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 36021–36029
2026
-
[52]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al . 2024. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13807–13816
2024
- [53]
-
[54]
Zhiyuan Zhao, Bin Wang, Linke Ouyang, Xiaoyi Dong, Jiaqi Wang, and Conghui He. 2023. Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization.CoRRabs/2311.16839 (2023). arXiv:2311.16839 doi:10.48550/ARXIV.2311.16839
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.16839 2023
-
[55]
Weihong Zhong, Xiaocheng Feng, Liang Zhao, Qiming Li, Lei Huang, Yuxuan Gu, Weitao Ma, Yuan Xu, and Bing Qin. 2024. Investigating and mitigating the multimodal hallucination snowballing in large vision-language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11991–12011
2024
-
[56]
Deyao Zhu, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny, et al. 2024. Minigpt- 4: Enhancing vision-language understanding with advanced large language models. InInternational Conference on Learning Representations, Vol. 2024. Open- Review.net, 18378–18394
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.