D3S2: Diffusion-Guided Dataset Distillation for Semantic Segmentation
Pith reviewed 2026-06-30 12:19 UTC · model grok-4.3
The pith
Diffusion-guided synthesis creates 1% sized semantic segmentation datasets that train models to 25-35% mIoU, beating random selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
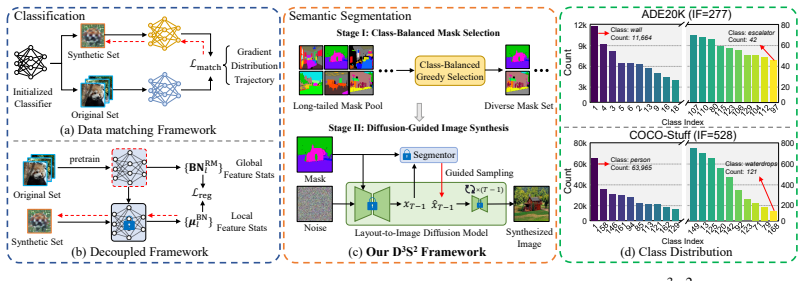
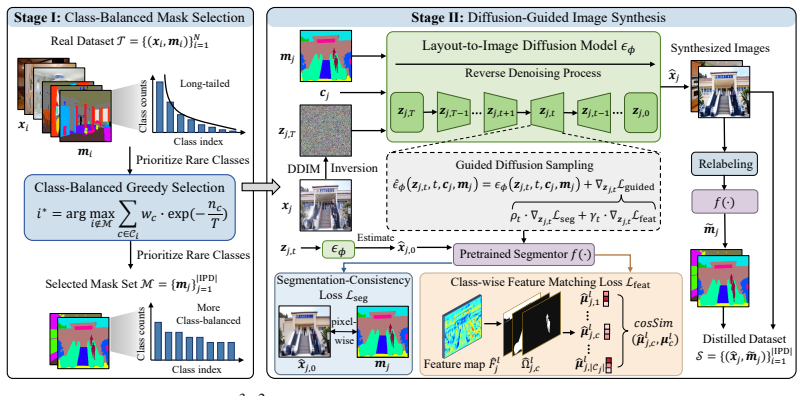
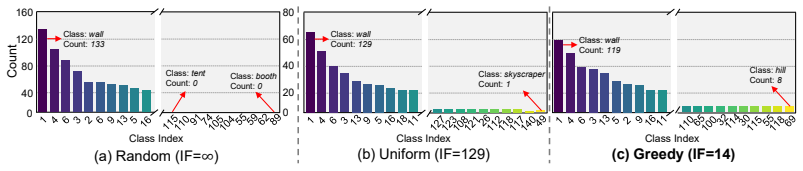
D3S2 performs dataset distillation for semantic segmentation through a two-stage pipeline: Class-Balanced Mask Selection builds a compact, representative mask collection by prioritizing rare classes via a greedy algorithm, and Diffusion-Guided Image Synthesis conditions a pretrained layout-to-image diffusion model on those masks while applying segmentation-consistency loss for pixel alignment and class-wise feature matching loss for per-class statistics across layers, thereby producing aligned synthetic image-label pairs at 1% of original size.
What carries the argument
Guided diffusion sampling that combines a segmentation-consistency loss with a class-wise feature matching loss inside a pretrained layout-to-image diffusion model conditioned on selected masks.
If this is right
- At 1% compression the distilled sets yield 24.99% mIoU on ADE20K and 35.49% mIoU on COCO-Stuff using Mask2Former with Swin-S backbone.
- The same sets outperform random selection by 9.34% on ADE20K and 5.70% on COCO-Stuff under identical training protocols.
- Conditioning the diffusion model directly on selected masks automatically satisfies pixel-wise image-label alignment without extra post-processing.
- The greedy class-balanced mask selection mitigates long-tailed distributions that otherwise degrade distillation quality.
Where Pith is reading between the lines
- The same mask-selection plus guided-diffusion pattern could be tested on other dense tasks such as instance segmentation or panoptic segmentation by swapping the downstream model.
- Replacing the current pretrained diffusion backbone with a higher-capacity or domain-adapted model would be a direct way to measure further gains without altering the rest of the pipeline.
- The class-balanced selection step might transfer to non-diffusion distillation methods for classification if the objective is rewritten in terms of image-level rather than mask-level statistics.
Load-bearing premise
A pretrained layout-to-image diffusion model can generate images whose pixel-level statistics remain useful for segmentation training once the two guided sampling objectives are applied.
What would settle it
If a Mask2Former model trained from scratch on the 1% D3S2 set for ADE20K records mIoU no higher than the 15.65% achieved by random selection, the performance advantage of the guided synthesis would be refuted.
Figures


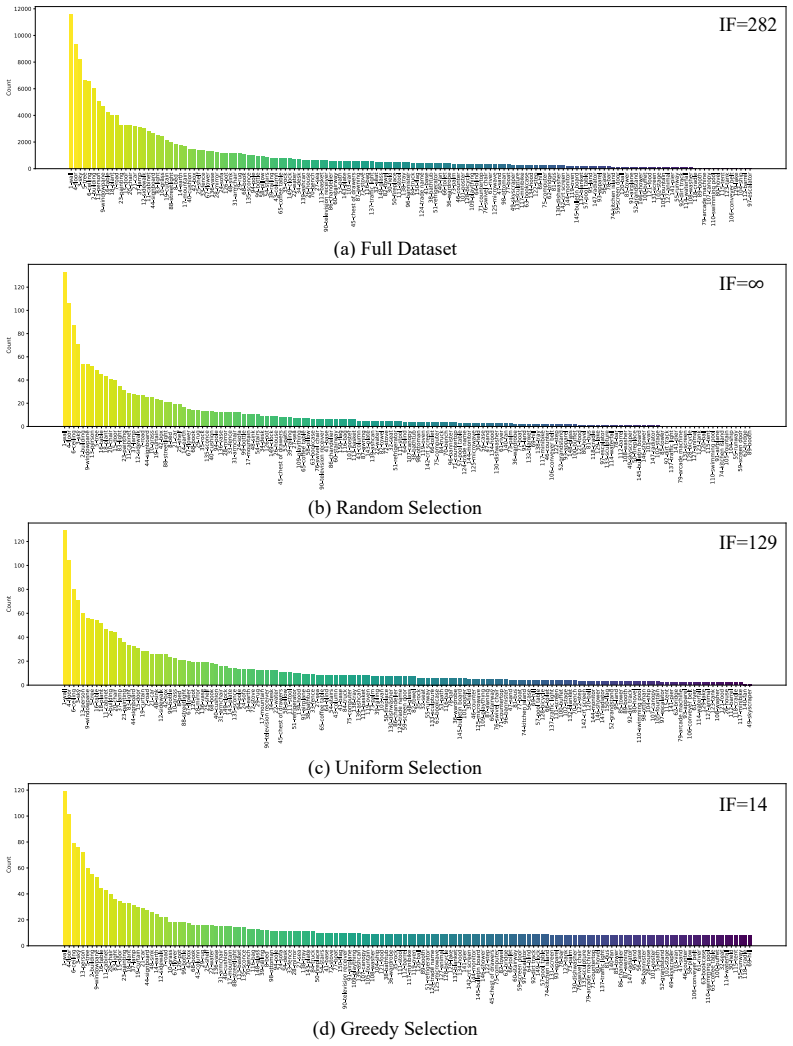
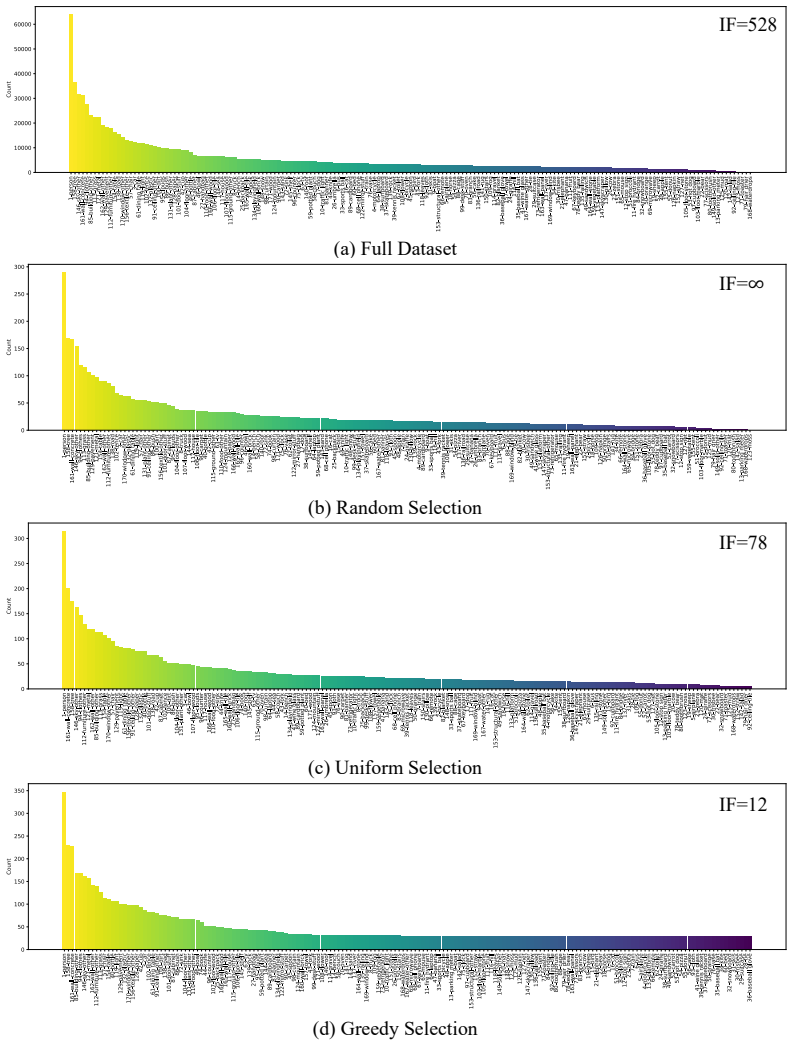


read the original abstract
Dataset distillation (DD) aims to compress large-scale datasets into compact synthetic sets while preserving training efficacy. However, existing studies mainly focus on image classification, leaving dense prediction tasks such as semantic segmentation largely underexplored. In this work, we identify three key challenges for segmentation DD: (i) long-tailed class imbalance, (ii) the need for strict pixel-wise alignment between images and dense labels, and (iii) the high computational cost of optimizing high-resolution data with complex models. To address these challenges, we propose D3S2, a Diffusion-guided Dataset Distillation framework for Semantic Segmentation. Our method adopts a two-stage design. In Class-Balanced Mask Selection, we construct a representative mask set via a greedy strategy that prioritizes underrepresented classes. In Diffusion-Guided Image Synthesis, we employ a pretrained layout-to-image diffusion model to generate images conditioned on the selected masks, naturally ensuring spatial alignment. To further enhance the training utility of synthesized data, we introduce guided diffusion sampling with two complementary objectives: a segmentation-consistency loss for pixel-level alignment, and a class-wise feature matching loss for aligning per-class feature statistics across layers. Extensive experiments demonstrate the superiority of D3S2. Notably, at an extremely compression rate of 1%, our method achieves 24.99% and 35.49% mIoU on ADE20K and COCO-Stuff with Mask2Former (Swin-S), outperforming random selection by 9.34% and 5.70%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes D3S2, a two-stage diffusion-guided dataset distillation framework for semantic segmentation. It first performs Class-Balanced Mask Selection via a greedy strategy to handle long-tailed imbalance, then uses a pretrained layout-to-image diffusion model for Diffusion-Guided Image Synthesis conditioned on the masks, augmented by a segmentation-consistency loss for pixel alignment and a class-wise feature matching loss for per-class statistics. The central claim is that at 1% compression this yields 24.99% mIoU on ADE20K and 35.49% mIoU on COCO-Stuff with Mask2Former (Swin-S), outperforming random selection by 9.34% and 5.70%.
Significance. If the results hold after proper validation, the work would be a meaningful contribution by extending dataset distillation to dense prediction tasks and demonstrating how diffusion priors plus targeted guidance can address alignment and imbalance issues. The two-stage design and dual guidance objectives are directly motivated by the stated challenges and could influence future work on synthetic data for segmentation.
major comments (2)
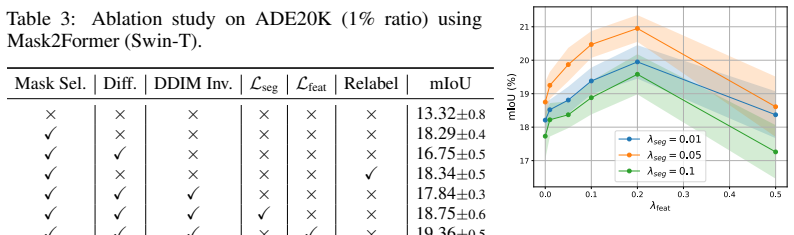
- [Diffusion-Guided Image Synthesis] Diffusion-Guided Image Synthesis: the performance claims rest on the assumption that the segmentation-consistency loss plus class-wise feature matching loss produce images whose pixel-level and per-class statistics remain useful for downstream Mask2Former training, yet no ablations (e.g., removing each loss), distribution-matching metrics, or checks for introduced artifacts are described to verify this step.
- [Experimental results] Experimental results: the reported mIoU values (24.99% ADE20K, 35.49% COCO-Stuff) and gains over random selection are given without experimental protocol details, number of runs, standard deviations, or component ablations, preventing assessment of whether the outperformance is reliable or reproducible.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive experiments demonstrate the superiority' is used without any mention of the number of baselines, variance, or ablation structure, which reduces clarity even for a high-level summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation of the synthesis stage and experimental reporting. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: Diffusion-Guided Image Synthesis: the performance claims rest on the assumption that the segmentation-consistency loss plus class-wise feature matching loss produce images whose pixel-level and per-class statistics remain useful for downstream Mask2Former training, yet no ablations (e.g., removing each loss), distribution-matching metrics, or checks for introduced artifacts are described to verify this step.
Authors: We agree that the current manuscript lacks explicit ablations and quantitative checks for the guidance losses. In the revised version we will add a dedicated ablation table that removes the segmentation-consistency loss and the class-wise feature matching loss individually, reporting the resulting mIoU drop on ADE20K and COCO-Stuff. We will also include qualitative side-by-side visualizations of synthesized images with and without each loss to inspect for artifacts, and will report per-class feature L2 distances between real and synthetic sets as a distribution-matching metric where space allows. revision: yes
-
Referee: Experimental results: the reported mIoU values (24.99% ADE20K, 35.49% COCO-Stuff) and gains over random selection are given without experimental protocol details, number of runs, standard deviations, or component ablations, preventing assessment of whether the outperformance is reliable or reproducible.
Authors: We acknowledge that the submitted manuscript omits these details. All reported numbers were obtained by training Mask2Former (Swin-S) for the standard 160k iterations on the distilled sets using the official codebase and hyperparameters from the original Mask2Former paper. Results are means over three independent runs with different random seeds; we will add means and standard deviations to all tables. We will also expand the experiments section with a component ablation table that isolates the contribution of Class-Balanced Mask Selection and each guidance loss. revision: yes
Circularity Check
No circularity: empirical results from external pretrained model and downstream evaluation
full rationale
The paper presents a two-stage empirical pipeline (Class-Balanced Mask Selection followed by Diffusion-Guided Image Synthesis with segmentation-consistency and class-wise feature matching losses) whose core output is measured mIoU on held-out real validation sets using Mask2Former. No equations define a target quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing premise reduces to a self-citation. The diffusion model is an external pretrained artifact; the reported 24.99% / 35.49% mIoU figures are experimental measurements, not quantities constructed by the method's own definitions. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bansal, H.-M
A. Bansal, H.-M. Chu, A. Schwarzschild, S. Sengupta, M. Goldblum, J. Geiping, and T. Gold- stein. Universal guidance for diffusion models. InCVPR, 2023
2023
-
[2]
Caesar, J
H. Caesar, J. Uijlings, and V . Ferrari. Coco-stuff: Thing and stuff classes in context. InCVPR, 2018
2018
-
[3]
F. M. Castro, M. J. Marín-Jiménez, N. Guil, C. Schmid, and K. Alahari. End-to-end incremental learning. InECCV, 2018
2018
-
[4]
Cazenavette, T
G. Cazenavette, T. Wang, A. Torralba, A. A. Efros, and J.-Y . Zhu. Dataset distillation by matching training trajectories. InCVPR, 2022
2022
-
[5]
Cazenavette, T
G. Cazenavette, T. Wang, A. Torralba, A. A. Efros, and J.-Y . Zhu. Generalizing dataset distillation via deep generative prior. InCVPR, 2023
2023
- [6]
-
[7]
M. Chen, J. Du, B. Huang, Y . Wang, X. Zhang, and W. Wang. Influence-guided diffusion for dataset distillation. InICLR, 2025
2025
-
[8]
Y . Chen, M. Welling, and A. Smola. Super-samples from kernel herding.arXiv preprint arXiv:1203.3472, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[9]
Cheng, I
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar. Masked-attention mask transformer for universal image segmentation. InCVPR, 2022
2022
-
[10]
J. Cui, R. Wang, S. Si, and C.-J. Hsieh. Scaling up dataset distillation to imagenet-1k with constant memory. InICLR, 2023
2023
-
[11]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, 2009
2009
-
[12]
J. Geng, Z. Chen, Y . Wang, H. Woisetschläger, S. Schimmler, R. Mayer, Z. Zhao, and C. Rong. A survey on dataset distillation: approaches, applications and future directions. InIJCAI, 2023
2023
-
[13]
J. Gu, S. Vahidian, V . Kungurtsev, H. Wang, W. Jiang, Y . You, and Y . Chen. Efficient dataset distillation via minimax diffusion. InCVPR, 2024
2024
-
[14]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
2020
-
[15]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
S. K. A. Khatib, A. ElHagry, S. Shao, and Z. Shen. Od3: Optimization-free dataset distillation for object detection.arXiv preprint arXiv:2506.01942, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
J.-H. Kim, J. Kim, S. J. Oh, S. Yun, H. Song, J. Jeong, J.-W. Ha, and H. O. Song. Dataset condensation via efficient synthetic-data parameterization. InICLR, 2022
2022
-
[18]
Krizhevsky and G
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[19]
N. Loo, R. Hasani, A. Amini, and D. Rus. Efficient dataset distillation using random feature approximation. InNeurIPS, 2022
2022
- [20]
-
[21]
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InAAAI, 2024
2024
- [22]
-
[23]
D. Qi, J. Li, J. Peng, B. Zhao, S. Dou, J. Li, J. Zhang, Y . Wang, C. Wang, and C. Zhao. Fetch and forge: Efficient dataset condensation for object detection. InNeurIPS, 2024
2024
-
[24]
Rebuffi, A
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert. icarl: Incremental classifier and representation learning. InCVPR, 2017
2017
-
[25]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[26]
J. A. C. Santiago, P. Tirupattur, G. K. Nayak, G. Liu, and M. Shah. Mgd3: Mode-guided dataset distillation using diffusion models. InICLR, 2025
2025
-
[27]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
O. Sener and S. Savarese. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
S. Shao, Z. Yin, M. Zhou, X. Zhang, and Z. Shen. Generalized large-scale data condensation via various backbone and statistical matching. InCVPR, 2024
2024
-
[30]
S. Shao, Z. Zhou, H. Chen, and Z. Shen. Elucidating the design space of dataset condensation. InNeurIPS, 2024
2024
-
[31]
Z. Shen, A. Sherif, Z. Yin, and S. Shao. Delt: A simple diversity-driven earlylate training for dataset distillation. InCVPR, 2025
2025
-
[32]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[33]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[34]
D. Su, J. Hou, W. Gao, Y . Tian, and B. Tang. D 4m: Dataset distillation via disentangled diffusion model. InCVPR, 2024
2024
-
[35]
D. Su, H. Wu, H. Chen, Y . Shi, Y . Wang, X. Ye, and J. Zhu. Diffusion models as dataset distillation priors.arXiv preprint arXiv:2510.17421, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
P. Sun, B. Shi, D. Yu, and T. Lin. On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm. InCVPR, 2024
2024
-
[37]
H. Wang, L. Zhang, W. Liu, D. Jiang, W. Wei, and C. Ding. Jodiffusion: Jointly diffusing image with pixel-level annotations for semantic segmentation promotion. InAAAI, 2026
2026
-
[38]
H. Wang, Z. Zhao, J. Wu, Y . Shang, G. Liu, and Y . Yan. Cao2: Rectifying inconsistencies in diffusion-based dataset distillation. InICCV, 2025
2025
-
[39]
K. Wang, J. Gu, J. Gu, H. Zhang, D. Zhou, Z. Zhu, W. Jiang, and Y . You. Dim: Distilling dataset into generative model. InECCV, 2024
2024
-
[40]
K. Wang, B. Zhao, X. Peng, Z. Zhu, S. Yang, S. Wang, G. Huang, H. Bilen, X. Wang, and Y . You. Cafe: Learning to condense dataset by aligning features. InCVPR, 2022
2022
-
[41]
T. Wang, J.-Y . Zhu, A. Torralba, and A. A. Efros. Dataset distillation.arXiv preprint arXiv:1811.10959, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. InNeurIPS, 2021
2021
-
[43]
H. Xue, Z. Huang, Q. Sun, L. Song, and W. Zhang. Freestyle layout-to-image synthesis. In CVPR, 2023
2023
-
[44]
Z. Yin, E. Xing, and Z. Shen. Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective. InNeurIPS, 2023. 11
2023
-
[45]
J. Yu, Y . Wang, C. Zhao, B. Ghanem, and J. Zhang. Freedom: Training-free energy-guided conditional diffusion model. InICCV, 2023
2023
-
[46]
R. Yu, S. Liu, and X. Wang. Dataset distillation: A comprehensive review.IEEE TPAMI, 46:150–170, 2023
2023
-
[47]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. InICCV, 2023
2023
-
[48]
Zhao and H
B. Zhao and H. Bilen. Dataset condensation with differentiable siamese augmentation. InICLR, 2021
2021
-
[49]
Zhao and H
B. Zhao and H. Bilen. Dataset condensation with distribution matching. InWACV, 2023
2023
-
[50]
B. Zhao, K. R. Mopuri, and H. Bilen. Dataset condensation with gradient matching. InICLR, 2021
2021
-
[51]
G. Zhao, G. Li, Y . Qin, and Y . Yu. Improved distribution matching for dataset condensation. In CVPR, 2023
2023
-
[52]
B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba. Scene parsing through ade20k dataset. InCVPR, 2017
2017
-
[53]
Y . Zhou, E. Nezhadarya, and J. Ba. Dataset distillation using neural feature regression. In NeurIPS, 2022
2022
-
[54]
Limitations
Y . Zou, G. Li, D. Su, Z. Wang, J. Yu, and C. Zhang. Dataset distillation via vision-language category prototype. InICCV, 2025. A More Details on Guided Diffusion Sampling Diffusion models [14, 33] learn a parameterized data distribution through a forward noising and reverse denoising process. Given a clean sample z0, the forward process gradually perturb...
2025
-
[55]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.