WorldCraft: From Camera Navigation to Object Manipulation in Interactive Video World Models
Pith reviewed 2026-06-30 12:00 UTC · model grok-4.3
The pith
WorldCraft adds object manipulation to video world models by injecting camera-invariant trajectories through a spatial pathway while keeping camera navigation intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
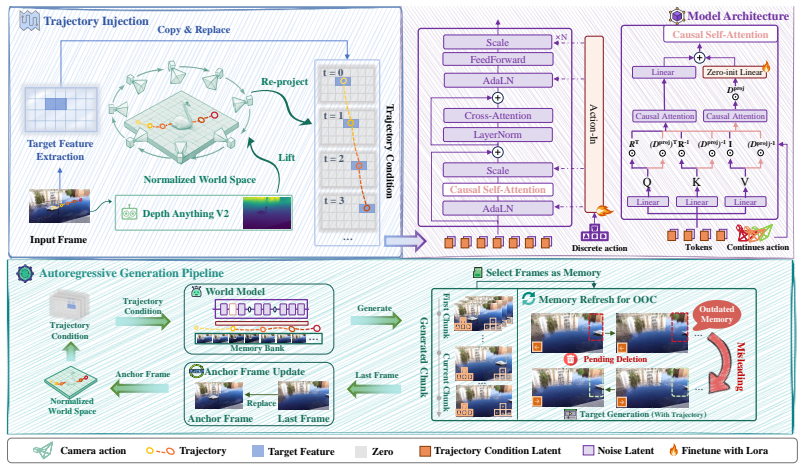
WorldCraft demonstrates that a pretrained video world model can be given object-level trajectory control by representing user paths in a camera-invariant world frame via Normalized World Trajectory, routing that signal through Spatial-Pathway LoRA into the model's spatial pathway, and anchoring the resulting state with Trajectory-Anchored State Persistence so that moved objects remain consistent across autoregressive steps even when they leave the camera view.
What carries the argument
The trajectory-centric control pipeline: Normalized World Trajectory (NWT) for camera-invariant motion representation, Spatial-Pathway LoRA (SP-LoRA) for injecting the object signal, and Trajectory-Anchored State Persistence (TASP) for maintaining updated object positions in autoregressive memory.
If this is right
- Users can draw an object path and receive video in which that object follows the path while the camera continues to move independently.
- Camera navigation performance on the original tasks remains unchanged after the object-control addition.
- Objects retain their updated world positions across long sequences that include periods when they are off-screen.
- The same model handles both camera and object actions without separate fine-tuning branches.
Where Pith is reading between the lines
- The same modular injection could be tried for other object actions such as rotation or scaling by extending the trajectory representation.
- State persistence across camera excursions suggests these models could support multi-step planning tasks that require remembering object locations outside the current view.
- Because the adaptation targets only the spatial pathway, similar LoRA-based extensions might add other control signals without retraining the entire model.
- The separation of world-space motion from screen-space displacement could be tested in settings where camera motion is more erratic than the training distribution.
Load-bearing premise
The pretrained video world model already contains a usable spatial-control pathway that can accept the added world-trajectory signal via SP-LoRA without degrading its camera navigation performance.
What would settle it
A direct comparison showing that camera-only navigation quality drops after SP-LoRA training, or that generated frames fail to place the selected object at the positions dictated by the user-drawn world trajectory.
Figures




read the original abstract
Recent video-based world models have made pixel-space environments interactive at the camera level: users can navigate viewpoints while the model generates coherent visual continuations. Yet their action spaces remain incomplete: users can move the camera, but cannot act on individual objects. Since real-world interaction is inherently object-centric, such models remain closer to passive scene observers than truly manipulable environments. We present WorldCraft, a framework that expands interactive video world models from camera navigation to object-level trajectory actions. Given a user click and a sketched path, WorldCraft generates future frames in which the selected object follows the prescribed trajectory while the camera continues to navigate the scene. WorldCraft achieves this through a trajectory-centric control pipeline: First, Normalized World Trajectory (NWT) represents user-drawn motion in a camera-invariant world coordinate system and dynamically re-projects it under the current camera pose, separating object motion from camera-induced screen-space displacement; Spatial-Pathway LoRA (SP-LoRA) then injects this world-space signal through the model's spatial-control pathway, adding object manipulation capability while preserving the pretrained camera controller; finally, Trajectory-Anchored State Persistence (TASP) treats the world trajectory as a persistent spatial state and refreshes autoregressive memory after trajectory-conditioned generation, allowing moved objects to reappear at their updated positions after leaving the camera view. Experiments show that WorldCraft enables accurate object control, preserves the video-based world model's camera fidelity under camera-only evaluation, and maintains object state across long autoregressive rollouts with off-camera excursions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WorldCraft, a framework that extends pretrained video-based world models from camera navigation to object-level manipulation. It proposes three components: Normalized World Trajectory (NWT) to represent user-specified object paths in a camera-invariant world coordinate system that is dynamically re-projected; Spatial-Pathway LoRA (SP-LoRA) to inject the trajectory signal into the model's spatial-control pathway while leaving the camera controller intact; and Trajectory-Anchored State Persistence (TASP) to treat the world trajectory as persistent state and refresh autoregressive memory so that moved objects reappear correctly after off-camera excursions. Experiments are claimed to demonstrate accurate object control, preserved camera fidelity under camera-only evaluation, and stable object state over long rollouts.
Significance. If the three components deliver the stated outcomes without post-hoc tuning or hidden degradation of the base model, the work would meaningfully advance interactive video world models toward object-centric control, addressing a clear gap between current camera-only navigation and real-world manipulation needs. The explicit separation of object motion from camera motion via NWT and the state-persistence mechanism are conceptually clean contributions that could be adopted more broadly if the preservation property is rigorously shown.
major comments (2)
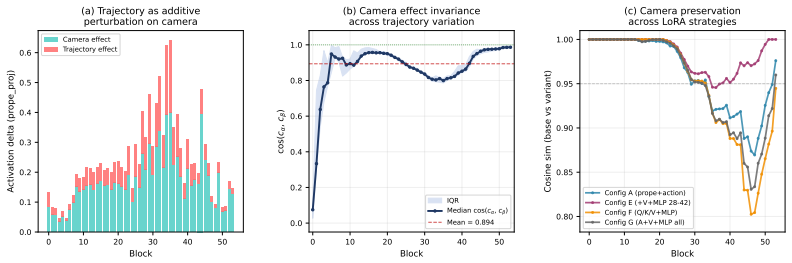
- [Abstract] Abstract: the central claim that SP-LoRA 'preserves the pretrained camera controller' and that 'camera fidelity' is maintained under camera-only evaluation rests on the unverified assumption that the LoRA update applied to the spatial pathway does not alter weights or activations used by the camera-navigation pathway. No ablation isolating camera-only performance before versus after SP-LoRA training is described, leaving open the possibility that shared parameters or representation shifts degrade camera control even when object control succeeds.
- [Abstract] Abstract (experiments paragraph): the three performance claims (accurate object control, preserved camera fidelity, maintained object state across long rollouts) are asserted without reference to quantitative metrics, baselines, or ablation tables that would allow verification that the outcomes are not the result of post-hoc tuning or selective evaluation. This makes it impossible to assess whether the method components actually deliver the stated results.
minor comments (1)
- [Abstract] The abstract introduces several new acronyms (NWT, SP-LoRA, TASP) without a brief parenthetical expansion on first use, which reduces immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our submission. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SP-LoRA 'preserves the pretrained camera controller' and that 'camera fidelity' is maintained under camera-only evaluation rests on the unverified assumption that the LoRA update applied to the spatial pathway does not alter weights or activations used by the camera-navigation pathway. No ablation isolating camera-only performance before versus after SP-LoRA training is described, leaving open the possibility that shared parameters or representation shifts degrade camera control even when object control succeeds.
Authors: We acknowledge the concern. The manuscript reports camera-only evaluation results after SP-LoRA training to demonstrate preserved fidelity, but does not include an explicit before-versus-after ablation on the same metrics. We will add this ablation (comparing camera navigation performance pre- and post-training) to the Experiments section and update the abstract to reference it, ensuring the preservation claim is rigorously supported. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): the three performance claims (accurate object control, preserved camera fidelity, maintained object state across long rollouts) are asserted without reference to quantitative metrics, baselines, or ablation tables that would allow verification that the outcomes are not the result of post-hoc tuning or selective evaluation. This makes it impossible to assess whether the method components actually deliver the stated results.
Authors: The full manuscript's Experiments section contains the supporting quantitative metrics, baselines, and ablation studies for the three claims. To address the abstract's lack of explicit references, we will revise the abstract to cite the specific tables and figures (e.g., object control accuracy in Table 2, camera fidelity in Figure 4, long-rollout state persistence in Table 3) so readers can directly locate the verification. revision: yes
Circularity Check
No circularity: method components are introduced by definition with no fitted predictions or self-citation reductions
full rationale
The paper defines three new components (Normalized World Trajectory, Spatial-Pathway LoRA, Trajectory-Anchored State Persistence) as a control pipeline to extend camera navigation to object manipulation. These are presented as engineering choices rather than derived predictions. No equations appear that reduce a claimed result to a fitted parameter or prior self-citation; the abstract and method description contain no quantitative fits, uniqueness theorems, or ansatzes justified by author overlap. The central claims rest on the explicit definitions of the pipeline plus experimental evaluation, remaining self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gamegen-x: Interactive open-world game video generation
GameGen-X Authors. Gamegen-x: Interactive open-world game video generation. arXiv preprint arXiv:2411.00769, 2024
-
[2]
Genie 3: A large-scale foundation world model
Google DeepMind. Genie 3: A large-scale foundation world model. Technical report, DeepMind, 2024
2024
-
[3]
David Ha and Jürgen Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. In International Conference on Learning Representations (ICLR) , 2020
2020
-
[5]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Y angyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Y eo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Hu, Y elong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Y elong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
2022
-
[8]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, et al. Vipe: Video pose engine for 3d geometric perception. arXiv preprint arXiv:2508.10934, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Vbench++: Comprehensive and versatile benchmark suite for video generative models
Ziqi Huang et al. Vbench++: Comprehensive and versatile benchmark suite for video generative models. arXiv preprint, 2024
2024
-
[10]
Cotracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea V edaldi, and Christian Rup- precht. Cotracker: It is better to track together. In Proceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[11]
Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid his- tory condition
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Y uan Zhou, Shuai Shao, Tianbao Y u, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid his- tory condition. volume 2, page 6, 2025
2025
-
[12]
Dora: Weight-decomposed low-rank adaptation
Shih-Y ang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Y u-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In F orty-first International Conference on Machine Learning, 2024
2024
-
[13]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Ming- min Chi, Y u Qiao, and Kaipeng Zhang. Y ume: An interactive world generation model. arXiv preprint arXiv:2507.17744, 2025
-
[14]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) , 2023
2023
-
[15]
Sam 2: Segment anything in images and videos
Nikhila Ravi, V alentin Gabeur, Y uan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan V asudev Al- wala, Nicolas Carion, Chao-Y uan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos. In International Confe...
2025
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Tencent Hunyuan. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Least-squares estimation of transformation parameters between two point patterns
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence , 13(4):376–380, 1991
1991
-
[18]
Diffusion models are real-time game engines
Dani V alevski, Y aniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. In International Conference on Learning Representations (ICLR) , 2025
2025
-
[19]
Wan-move: Wan move anything
Wan-Move Authors. Wan-move: Wan move anything. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[20]
Drivedreamer: Towards real-world-drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-drive world models for autonomous driving. In European conference on computer vision (ECCV), pages 55–72. Springer, 2024
2024
-
[21]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing , 13(4):600–612, 2004
2004
-
[22]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Y uan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. In ACM SIGGRAPH, 2024
2024
-
[23]
Worldplay: Interactive video generation with autoregressive world models
WorldPlay Team. Worldplay: Interactive video generation with autoregressive world models. 2025. Tencent Hunyuan
2025
-
[24]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. In Conference on robot learning (CoRL) , pages 2226–2240. PMLR, 2023
2023
-
[25]
Draganything: Motion control for anything using entity representation
Weijia Wu, Zhuang Li, Y uchao Gu, Rui Zhao, Y efei He, David Junhao Zhang, Mike Zheng Shou, Y an Li, Tingting Gao, and Di Zhang. Draganything: Motion control for anything using entity representation. In Proceedings of the European Conference on Computer Vision (ECCV) , 2024
2024
-
[26]
Depth anything v2
Lihe Y ang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2. In Advances in Neural Information Processing Systems (NeurIPS) , 2024
2024
-
[27]
Learning interactive real-world simulators
Sherry Y ang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. In International Con- ference on Learning Representations (ICLR) , 2024. Outstanding Paper Award
2024
-
[28]
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Drag- nuwa: Fine-grained control in video generation by integrating text, image, and trajectory. arXiv preprint arXiv:2308.08089, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In IEEE/CVF International Conference on Computer Vision (ICCV), pages 22963–22974, 2025
2025
-
[30]
Camera source
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable ef- fectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 586–595, 2018. A Progressive training The shared spatial pathway identified in § 3.4 implies that trajectory training...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.