Trust-Aware Joint Feature-Prediction Discrepancy for Robust Domain Adaptation
Pith reviewed 2026-06-30 11:53 UTC · model grok-4.3
The pith
Domain adaptation improves when feature and prediction divergences are weighted by per-sample trust from entropy and prototype similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that domain discrepancy should be modeled through the Joint Feature-Prediction Discrepancy, a formulation that jointly measures representation divergence and prediction divergence while scaling each by sample-specific trust; trust combines uncertainty-aware values from prediction entropy with semantic-alignment values from prototype similarity in feature space, so that adaptation prioritizes confident and consistent samples and produces estimates that correlate with target error.
What carries the argument
Joint Feature-Prediction Discrepancy (JFPD), a unified formulation that jointly captures representation divergence and prediction divergence while weighting their contributions by sample-specific trust.
If this is right
- Adaptation focuses alignment on trustworthy samples and down-weights noisy or ambiguous ones.
- The resulting discrepancy estimates correlate with actual target-domain error.
- The integrated training objective guides models toward trustworthy regions of the target domain.
- The framework produces consistent performance gains over prior single-perspective methods on standard benchmarks.
Where Pith is reading between the lines
- The same trust weighting could be applied to other alignment objectives beyond the specific discrepancy used here.
- If trust scores prove stable across tasks, they might serve as a general filter for selecting pseudo-labels in semi-supervised settings.
- The observed correlation between discrepancy and error opens the possibility of using the measure itself to monitor adaptation progress without target labels.
Load-bearing premise
Sample-specific trust derived from prediction entropy and prototype similarity accurately identifies reliable signals for alignment under domain shift.
What would settle it
A controlled test in which samples assigned high trust still produce high target-domain error rates, or in which the trust-weighted method shows no gain over unweighted baselines on the same benchmarks.
Figures

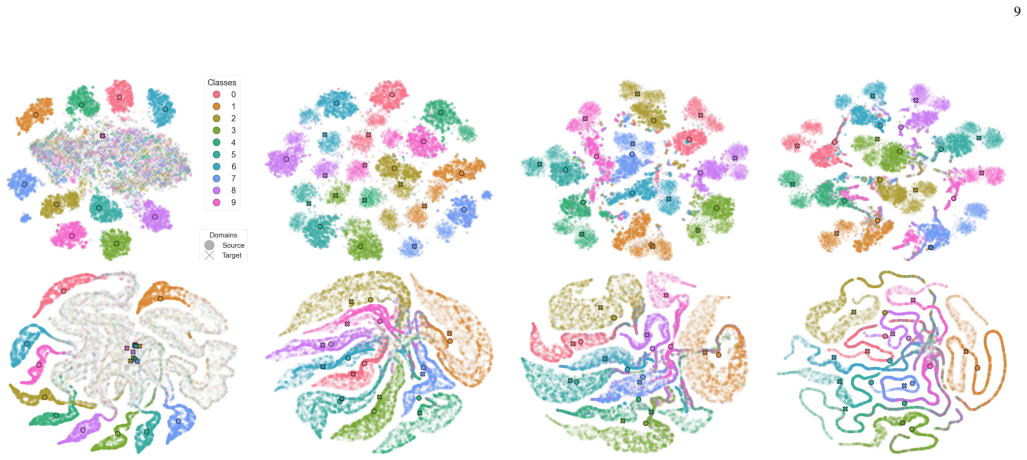

read the original abstract
Domain adaptation aims to mitigate performance degradation caused by distribution shifts between a labeled source domain and an unlabeled or sparsely labeled target domain. Most existing approaches estimate domain discrepancy either in feature space or in prediction space. However, these single-perspective strategies overlook a critical problem under domain shift: the reliability of the signals used for alignment. In practice, both learned representations and semantic predictions may become unreliable, and treating all target samples equally can lead to misleading alignment and suboptimal transfer. We introduce trust-aware domain adaptation, a principled framework that models domain discrepancy through the reliability of feature and prediction signals. Central to our approach is the Joint Feature-Prediction Discrepancy (JFPD), a unified formulation that jointly captures representation divergence and prediction divergence while weighting their contributions by sample-specific trust. Trust is quantified via two complementary mechanisms: uncertainty-aware trust, derived from prediction entropy to suppress unreliable predictions, and semantic-alignment trust, computed from prototype similarity in feature space to emphasize well-aligned representations. By prioritizing confident and semantically consistent samples while down-weighting noisy or ambiguous ones, JFPD provides a reliability-aware estimate of domain discrepancy. We further integrate JFPD into a training objective that guides adaptation toward trustworthy regions of the target domain. Experiments on standard benchmarks demonstrate that the proposed framework consistently achieves superior adaptation performance and yields discrepancy estimates that correlate with target-domain error. This work addresses, for the first time, the importance of modeling trust in the interaction between features and predictions for domain adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a trust-aware domain adaptation framework that introduces the Joint Feature-Prediction Discrepancy (JFPD) to jointly measure representation and prediction divergences while weighting contributions by sample-specific trust. Trust is computed via uncertainty-aware trust (from prediction entropy) and semantic-alignment trust (from prototype similarity in feature space). The method integrates JFPD into a training objective to prioritize reliable target samples and is evaluated on standard benchmarks, claiming superior adaptation performance and discrepancy estimates that correlate with target-domain error.
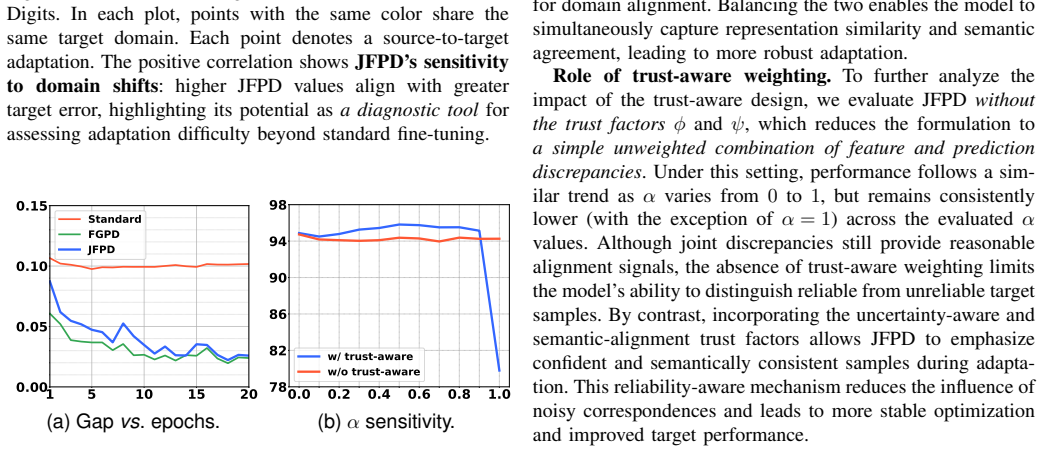
Significance. If the trust weighting proves robust, the work could meaningfully advance domain adaptation by addressing signal reliability under shift, a practical concern in many CV applications. The reported correlation between JFPD estimates and target error is a positive empirical contribution. The unified formulation of feature and prediction discrepancies is conceptually appealing, though its advantage over separate discrepancy measures requires verification in the full derivations.
major comments (1)
- [Abstract (trust mechanisms description)] The trust mechanisms (prediction entropy and prototype similarity) are computed from the current feature extractor and classifier, which are precisely the components being adapted under domain shift. This creates a potential circularity risk where erroneous predictions or misaligned prototypes on the target could be reinforced rather than suppressed. The central claim that JFPD yields a reliability-aware discrepancy estimate is load-bearing on this assumption holding; the abstract provides no independent validation anchor (e.g., source-only hold-out or oracle) to break the loop. This issue must be addressed with a concrete analysis or experiment in the methods or experiments section.
minor comments (1)
- [Abstract] The abstract states that experiments demonstrate correlation with target-domain error but provides no quantitative details (e.g., Pearson coefficient or specific benchmark values); adding these would strengthen the significance paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding potential circularity in the trust mechanisms. We address the concern point-by-point below and will revise the manuscript to incorporate additional analysis.
read point-by-point responses
-
Referee: The trust mechanisms (prediction entropy and prototype similarity) are computed from the current feature extractor and classifier, which are precisely the components being adapted under domain shift. This creates a potential circularity risk where erroneous predictions or misaligned prototypes on the target could be reinforced rather than suppressed. The central claim that JFPD yields a reliability-aware discrepancy estimate is load-bearing on this assumption holding; the abstract provides no independent validation anchor (e.g., source-only hold-out or oracle) to break the loop. This issue must be addressed with a concrete analysis or experiment in the methods or experiments section.
Authors: We acknowledge the validity of this concern: trust signals derived from the adapting model could in principle reinforce errors under severe shift. Our framework attempts to mitigate this via complementary mechanisms—entropy-based down-weighting of uncertain predictions and prototype similarity that can be anchored to source-domain class prototypes with exponential moving averages—but these are internal design choices rather than an external validation anchor. To directly address the referee’s request, we will add a new diagnostic experiment in the revised manuscript: (1) an oracle-trust baseline computed with ground-truth target labels (used only for analysis) to quantify how closely our estimated trust tracks true reliability, and (2) a source-only hold-out comparison that freezes the initial model to compute JFPD before any target adaptation begins. These results, together with an updated abstract sentence referencing the robustness analysis, will appear in the Methods and Experiments sections. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines JFPD as a weighted combination of feature and prediction discrepancies using trust scores from standard prediction entropy and prototype similarity. These are presented as direct computations from the model outputs without any shown fitting procedure, self-referential equations, or load-bearing self-citations that would reduce the central claim to its own inputs by construction. No equations are provided that equate a 'prediction' to a fitted parameter, and the trust mechanisms rely on conventional uncertainty and similarity concepts rather than ansatzes or uniqueness theorems imported from prior author work. The derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of distribution shift between labeled source and unlabeled target domains requiring alignment.
Reference graph
Works this paper leans on
-
[1]
Deep visual domain adaptation: A survey,
M. Wang and W. Deng, “Deep visual domain adaptation: A survey,” Neurocomputing, vol. 312, pp. 135–153, 2018
2018
-
[2]
Domain adaptation via transfer component analysis,
S. J. Pan, I. W. Tsang, J. T. Kwok, and Q. Yang, “Domain adaptation via transfer component analysis,”IEEE Transactions on Neural Networks, vol. 22, no. 2, pp. 199–210, 2010. 11
2010
-
[3]
A comprehensive survey on source-free domain adaptation,
J. Li, Z. Yu, Z. Du, L. Zhu, and H. T. Shen, “A comprehensive survey on source-free domain adaptation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5743–5762, 2024
2024
-
[4]
Domain adaptation for medical image analysis: a survey,
H. Guan and M. Liu, “Domain adaptation for medical image analysis: a survey,”IEEE Transactions on Biomedical Engineering, vol. 69, no. 3, pp. 1173–1185, 2021
2021
-
[5]
Unsuper- vised domain adaptation for medical imaging segmentation with self- ensembling,
C. S. Perone, P. Ballester, R. C. Barros, and J. Cohen-Adad, “Unsuper- vised domain adaptation for medical imaging segmentation with self- ensembling,”NeuroImage, vol. 194, pp. 1–11, 2019
2019
-
[6]
Pixel and feature level based domain adaptation for object detection in autonomous driving,
Y . Shan, W. F. Lu, and C. M. Chew, “Pixel and feature level based domain adaptation for object detection in autonomous driving,”Neuro- computing, vol. 367, pp. 31–38, 2019
2019
-
[7]
Flow dynamics correction for action recogni- tion,
L. Wang and P. Koniusz, “Flow dynamics correction for action recogni- tion,” inICASSP 2024-2024 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 3795– 3799
2024
-
[8]
High-order tensor pooling with atten- tion for action recognition,
L. Wang, K. Sun, and P. Koniusz, “High-order tensor pooling with atten- tion for action recognition,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 3885–3889
2024
-
[9]
The journey of action recognition,
X. Ding and L. Wang, “The journey of action recognition,” in Companion Proceedings of the ACM Web Conference 2025, ser. WWW ’25 Companion. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3701716. 3717746
-
[10]
Quo vadis, anomaly detection? llms and vlms in the spotlight,
——, “Quo vadis, anomaly detection? llms and vlms in the spotlight,” arXiv preprint arXiv:2412.18298, 2024
-
[11]
Motion meets Attention: Video motion prompts,
Q. Chen, L. Wang, P. Koniusz, and T. Gedeon, “Motion meets Attention: Video motion prompts,” inProceedings of the 16th Asian Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 260. PMLR, 2025, pp. 591–606
2025
-
[12]
Advancing video anomaly detection: A concise review and a new dataset,
L. Zhu, L. Wang, A. Raj, T. Gedeon, and C. Chen, “Advancing video anomaly detection: A concise review and a new dataset,” inAdvances in Neural Information Processing Systems, vol. 37. Curran Associates, Inc., 2024, pp. 89 943–89 977
2024
-
[13]
Taylor videos for action recognition,
L. Wang, X. Yuan, T. Gedeon, and L. Zheng, “Taylor videos for action recognition,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol
-
[14]
52 117–52 133
PMLR, 2024, pp. 52 117–52 133
2024
-
[15]
Learnable expansion of graph operators for multi-modal feature fusion,
D. Ding, L. Wang, L. Zhu, T. Gedeon, and P. Koniusz, “Learnable expansion of graph operators for multi-modal feature fusion,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=SMZqIOSdlN
2025
-
[16]
Do language models understand time?
X. Ding and L. Wang, “Do language models understand time?”arXiv preprint arXiv:2412.13845, 2024
-
[17]
Semi-supervised domain adaptation with source label adaptation,
Y .-C. Yu and H.-T. Lin, “Semi-supervised domain adaptation with source label adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 24 100– 24 109
2023
-
[18]
A brief review of domain adaptation,
A. Farahani, S. V oghoei, K. Rasheed, and H. R. Arabnia, “A brief review of domain adaptation,”Advances in data science and information engineering: proceedings from ICDATA 2020 and IKE 2020, pp. 877– 894, 2021
2020
-
[19]
Joint domain alignment and discriminative feature learning for unsupervised deep domain adapta- tion,
C. Chen, Z. Chen, B. Jiang, and X. Jin, “Joint domain alignment and discriminative feature learning for unsupervised deep domain adapta- tion,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 3296–3303
2019
-
[20]
Ssf-dan: Separated semantic feature based domain adaptation network for semantic segmentation,
L. Du, J. Tan, H. Yang, J. Feng, X. Xue, Q. Zheng, X. Ye, and X. Zhang, “Ssf-dan: Separated semantic feature based domain adaptation network for semantic segmentation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 982– 991
2019
-
[21]
Semantic-aware message broad- casting for efficient unsupervised domain adaptation,
X. Li, C. Lan, G. Wei, and Z. Chen, “Semantic-aware message broad- casting for efficient unsupervised domain adaptation,”IEEE Transac- tions on Image Processing, vol. 33, pp. 5340–5353, 2024
2024
-
[22]
Rethinking maximum mean discrepancy for visual domain adaptation,
W. Wang, H. Li, Z. Ding, F. Nie, J. Chen, X. Dong, and Z. Wang, “Rethinking maximum mean discrepancy for visual domain adaptation,” IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 1, pp. 264–277, 2021
2021
-
[23]
R ´enyi divergence and kullback-leibler divergence,
T. Van Erven and P. Harremos, “R ´enyi divergence and kullback-leibler divergence,”IEEE Transactions on Information Theory, vol. 60, no. 7, pp. 3797–3820, 2014
2014
-
[24]
Jensen-shannon divergence and hilbert space embedding,
B. Fuglede and F. Topsoe, “Jensen-shannon divergence and hilbert space embedding,” inInternational Symposium on Information Theory (ISIT), 2004, pp. 1–6
2004
-
[25]
Conditional adversarial domain adaptation,
M. Long, Z. Cao, J. Wang, and M. I. Jordan, “Conditional adversarial domain adaptation,”Advances in Neural Information Processing Sys- tems, vol. 31, pp. 1–11, 2018
2018
-
[26]
Graph your own prompt,
X. Ding, L. Wang, P. Koniusz, and Y . Gao, “Graph your own prompt,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https: //openreview.net/forum?id=7tXGIbrIA5
2025
-
[27]
Trust- aware conditional adversarial domain adaptation with feature norm alignment,
J. Dan, T. Jin, H. Chi, S. Dong, H. Xie, K. Cao, and X. Yang, “Trust- aware conditional adversarial domain adaptation with feature norm alignment,”Neural Networks, vol. 168, pp. 518–530, 2023
2023
-
[28]
Learning transferable features with deep adaptation networks,
M. Long, Y . Cao, J. Wang, and M. Jordan, “Learning transferable features with deep adaptation networks,” inInternational Conference on Machine Learning. PMLR, 2015, pp. 97–105
2015
-
[29]
Deep transfer learning with joint adaptation networks,
M. Long, H. Zhu, J. Wang, and M. I. Jordan, “Deep transfer learning with joint adaptation networks,” inInternational Conference on Machine Learning. PMLR, 2017, pp. 2208–2217
2017
-
[30]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Lavi- olette, M. March, and V . Lempitsky, “Domain-adversarial training of neural networks,”Journal of Machine Learning Research, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[31]
Gradually vanishing bridge for adversarial domain adaptation,
S. Cui, S. Wang, J. Zhuo, C. Su, Q. Huang, and Q. Tian, “Gradually vanishing bridge for adversarial domain adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 12 455–12 464
2020
-
[32]
Semi-supervised learning by entropy minimization,
Y . Grandvalet and Y . Bengio, “Semi-supervised learning by entropy minimization,”Advances in Neural Information Processing Systems, vol. 17, pp. 1–8, 2004
2004
-
[33]
Transferable attention for domain adaptation,
X. Wang, L. Li, W. Ye, M. Long, and J. Wang, “Transferable attention for domain adaptation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 5345–5352
2019
-
[34]
Fixbi: Bridging domain spaces for unsupervised domain adaptation,
J. Na, H. Jung, H. J. Chang, and W. Hwang, “Fixbi: Bridging domain spaces for unsupervised domain adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 1094–1103
2021
-
[35]
Seen-da: Semantic entropy guided domain- aware attention for domain adaptive object detection,
H. Li, R. Zhang, H. Yao, X. Zhang, Y . Hao, X. Song, S. Peng, Y . Zhao, C. Zhao, Y . Wuet al., “Seen-da: Semantic entropy guided domain- aware attention for domain adaptive object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 25 465–25 475
2025
-
[36]
Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation,
J. Liang, D. Hu, and J. Feng, “Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 6028–6039
2020
-
[37]
Tent: Fully test-time adaptation by entropy minimization,
D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell, “Tent: Fully test-time adaptation by entropy minimization,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=uXl3bZLkr3c
2021
-
[38]
Confidence score for source- free unsupervised domain adaptation,
J. Lee, D. Jung, J. Yim, and S. Yoon, “Confidence score for source- free unsupervised domain adaptation,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 12 365–12 377
2022
-
[39]
A theory of learning from different domains,
S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan, “A theory of learning from different domains,”Machine Learning, vol. 79, no. 1-2, pp. 151–175, 2010
2010
-
[40]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[41]
Minent: Minimum entropy for self-supervised representation learning,
S. Li, F. Liu, Z. Hao, L. Jiao, X. Liu, and Y . Guo, “Minent: Minimum entropy for self-supervised representation learning,”Pattern Recognition, vol. 138, p. 109364, 2023
2023
-
[42]
Larger norm more transferable: An adaptive feature norm approach for unsupervised domain adaptation,
R. Xu, G. Li, J. Yang, and L. Lin, “Larger norm more transferable: An adaptive feature norm approach for unsupervised domain adaptation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1426–1435
2019
-
[43]
Domain conditioned adaptation network,
S. Li, C. Liu, Q. Lin, B. Xie, Z. Ding, G. Huang, and J. Tang, “Domain conditioned adaptation network,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 386–11 393
2020
-
[44]
Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations,
S. Cui, S. Wang, J. Zhuo, L. Li, Q. Huang, and Q. Tian, “Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3941–3950
2020
-
[45]
One-shot domain adaptation for face genera- tion,
C. Yang and S.-N. Lim, “One-shot domain adaptation for face genera- tion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5921–5930
2020
-
[46]
Domain adaptation with auxiliary target domain-oriented classifier,
J. Liang, D. Hu, and J. Feng, “Domain adaptation with auxiliary target domain-oriented classifier,” inProceedings of the IEEE/CVF Conference 12 on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 16 632– 16 642
2021
-
[47]
DUET: Dual-perspective pseudo labeling and uncertainty-aware exploration & exploitation training for source-free domain adaptation,
J. Y . Lee, J. H. Park, G. Lee, B. Kim, M. H. Cha, H. Nam, J. H. Jeon, H. Lee, and S. I. Cho, “DUET: Dual-perspective pseudo labeling and uncertainty-aware exploration & exploitation training for source-free domain adaptation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/...
2025
-
[48]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=YicbFdNTTy
2021
-
[49]
CDTrans: Cross-domain transformer for unsupervised domain adaptation,
T. Xu, W. Chen, P. W ANG, F. Wang, H. Li, and R. Jin, “CDTrans: Cross-domain transformer for unsupervised domain adaptation,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=XGzk5OKWFFc
2022
-
[50]
Tvt: Transferable vision transformer for unsupervised domain adaptation,
J. Yang, J. Liu, N. Xu, and J. Huang, “Tvt: Transferable vision transformer for unsupervised domain adaptation,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 520–530
2023
-
[51]
Safe self-refinement for transformer-based domain adaptation,
T. Sun, C. Lu, T. Zhang, and H. Ling, “Safe self-refinement for transformer-based domain adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 7191–7200
2022
-
[52]
Dcst: Dual cross-supervision for transformer-based unsupervised domain adaptation,
Y . Cheng, P. Yao, L. Xu, M. Chen, P. Liu, P. Shao, S. Shen, and R. X. Xu, “Dcst: Dual cross-supervision for transformer-based unsupervised domain adaptation,”Neural Networks, vol. 181, p. 106749, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0893608024006737
2025
-
[53]
Target self-guided framework for unsupervised domain adaptation,
J. Li, Z. Li, and S. L ¨u, “Target self-guided framework for unsupervised domain adaptation,”Pattern Recognition, vol. 177, p. 113390, 2026
2026
-
[54]
Feature fusion transferability aware transformer for unsupervised domain adaptation,
X. Yu, Z. Huang, and Z. Zhang, “Feature fusion transferability aware transformer for unsupervised domain adaptation,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 6752–6761
2025
-
[55]
Cross-domain gradient discrepancy minimization for unsupervised domain adaptation,
Z. Du, J. Li, H. Su, L. Zhu, and K. Lu, “Cross-domain gradient discrepancy minimization for unsupervised domain adaptation,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 3937–3946
2021
-
[56]
Contrastive adap- tation network for unsupervised domain adaptation,
G. Kang, L. Jiang, Y . Yang, and A. G. Hauptmann, “Contrastive adap- tation network for unsupervised domain adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4893–4902
2019
-
[57]
Reducing distributional uncertainty by mutual information maximisation and trans- ferable feature learning,
J. Gao, Y . Hua, G. Hu, C. Wang, and N. M. Robertson, “Reducing distributional uncertainty by mutual information maximisation and trans- ferable feature learning,” inEuropean Conference on Computer Vision (ECCV), 2020, pp. 587–605
2020
-
[58]
Semantic concentration for domain adaptation,
S. Li, M. Xie, F. Lv, C. H. Liu, J. Liang, C. Qin, and W. Li, “Semantic concentration for domain adaptation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9102– 9111
2021
-
[59]
Deep struc- ture alignment network for scalable unsupervised domain adaptation,
Y . Wang, H. Meng, Z. Zhou, M. Ding, and W. Zeng, “Deep struc- ture alignment network for scalable unsupervised domain adaptation,” Knowledge-Based Systems, p. 115641, 2026
2026
-
[60]
Gradient-based learning applied to document recognition,
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[61]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Nget al., “Reading digits in natural images with unsupervised feature learning,” inNIPS workshop on deep learning and unsupervised feature learning, vol. 2011, no. 2, 2011, pp. 1–9
2011
-
[62]
A database for handwritten text recognition research,
J. J. Hull, “A database for handwritten text recognition research,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 16, no. 5, pp. 550–554, 1994
1994
-
[63]
Effects of degradations on deep neural network architectures,
P. Roy, S. Ghosh, S. Bhattacharya, and U. Pal, “Effects of degradations on deep neural network architectures,”arXiv preprint arXiv:1807.10108, 2018
-
[64]
Deep hashing network for unsupervised domain adaptation,
H. Venkateswara, J. Eusebio, S. Chakraborty, and S. Panchanathan, “Deep hashing network for unsupervised domain adaptation,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5018–5027
2017
-
[65]
VisDA: The Visual Domain Adaptation Challenge
X. Peng, B. Usman, N. Kaushik, J. Hoffman, D. Wang, and K. Saenko, “Visda: The visual domain adaptation challenge,”arXiv preprint arXiv:1710.06924, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[66]
Moment matching for multi-source domain adaptation,
X. Peng, Q. Bai, X. Xia, Z. Huang, K. Saenko, and B. Wang, “Moment matching for multi-source domain adaptation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1406–1415. Xi Dingreceived the M.S. degree in machine learning from the Australian National University (ANU) in 2025. He is currently a research intern ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.