AME-TS: Anchored Mixture-of-Experts for Time Series Forecasting
Pith reviewed 2026-06-30 12:31 UTC · model grok-4.3
The pith
Anchoring Mixture-of-Experts routing with a soft structural prior derived from series descriptors lets time series models achieve better accuracy and efficiency through structure-aligned expert specialization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
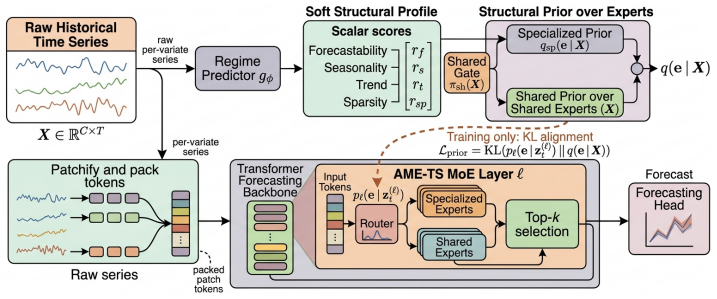
AME-TS is a structure-guided sparse time series foundation model that uses a lightweight regime predictor to estimate series-level descriptors including forecastability, seasonality, trend, and sparsity, maps those estimates to a soft structural prior over experts, and employs the prior to guide token-level routing during training, thereby producing structure-aligned expert specialization that yields a strong accuracy-efficiency tradeoff across model scales while delivering more interpretable routing geometry and more stable specialization during fine-tuning.
What carries the argument
The anchored routing mechanism that converts estimated temporal descriptors into a soft prior over experts to condition Mixture-of-Experts token routing and encourage structure-aligned specialization.
If this is right
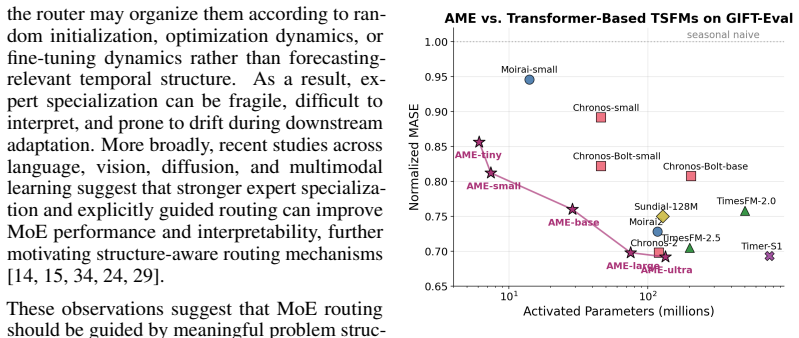
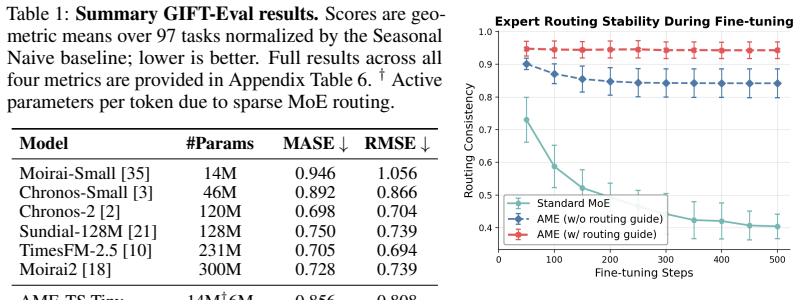
- AME-TS substantially outperforms existing time series foundation models at small model scales while activating substantially fewer parameters.
- At larger scales the model remains competitive with the strongest existing models.
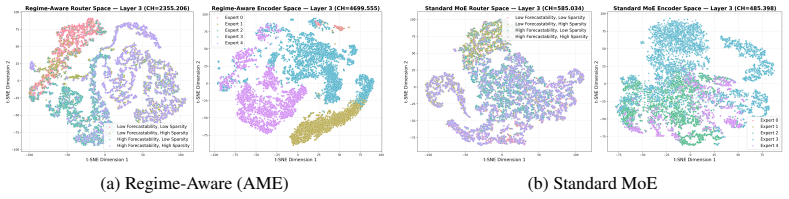
- The learned routing geometry is more interpretable than that of standard Mixture-of-Experts.
- Expert specialization stays substantially more stable during fine-tuning on new data compared with unanchored routing.
Where Pith is reading between the lines
- The same descriptor-to-prior step could be applied to other sequence tasks that contain heterogeneous structure, such as multivariate forecasting or change-point detection.
- Making the regime predictor jointly trainable with the rest of the model might tighten the alignment between estimated descriptors and final routing decisions.
- In production systems the distribution of activated experts could serve as an online indicator of shifts in the underlying temporal regimes without requiring separate monitoring models.
Load-bearing premise
A lightweight regime predictor can reliably estimate series-level descriptors such as forecastability, seasonality, trend, and sparsity, and mapping those estimates to a soft structural prior will produce stable, structure-aligned expert specialization that survives downstream fine-tuning.
What would settle it
Training a standard Mixture-of-Experts model without the structural prior on the same benchmark and data, then observing no gain in accuracy or reduction in active parameters at small scales and no improvement in routing stability during fine-tuning, would falsify the benefit of the anchoring step.
Figures
read the original abstract
Time series forecasting models are increasingly scaled through large Transformer backbones, yet most existing approaches process all series through a shared dense computation path despite substantial heterogeneity in temporal structure. Mixture-of-Experts (MoE) offers a natural alternative by enabling conditional computation, but standard MoE routing leaves expert specialization weakly identified and often unstable during downstream adaptation. We propose AME-TS, a structure-guided sparse time series foundation model that aligns expert routing with interpretable temporal structure. AME-TS first uses a lightweight regime predictor to estimate series-level descriptors, including forecastability, seasonality, trend, and sparsity, and maps them to a soft structural prior over experts. This series-level prior guides token-level routing during training, encouraging structure-aligned specialization. On the GIFT-Eval benchmark, AME-TS delivers a strong accuracy-efficiency tradeoff across model scales: it substantially outperforms existing time series foundation models at small model scales and remains competitive with the strongest models at larger scales, while activating substantially fewer parameters through sparse routing. We further show that AME-TS learns more interpretable routing geometry and substantially more stable expert specialization than standard MoE during fine-tuning on the M5 dataset. These results suggest that structure-aware routing is an effective and reliable way to realize the benefits of sparse expert models for time series forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AME-TS, a Mixture-of-Experts architecture for time series forecasting that employs a lightweight regime predictor to estimate series-level descriptors (forecastability, seasonality, trend, sparsity) and derives a soft structural prior to guide token-level expert routing. The central claims are that this yields a strong accuracy-efficiency tradeoff on the GIFT-Eval benchmark across model scales (outperforming small foundation models and remaining competitive at larger scales while activating fewer parameters) and produces more interpretable and stable expert specialization than standard MoE during fine-tuning on M5.
Significance. If the empirical claims are substantiated, the work would offer a concrete mechanism for aligning sparse routing with temporal structure in time series foundation models, addressing a recognized source of instability in MoE adaptation while preserving efficiency gains.
major comments (3)
- [Abstract] Abstract: the headline GIFT-Eval accuracy-efficiency claims and the M5 stability result are asserted without any description of experimental protocol, baseline implementations, statistical tests, number of runs, or ablation studies, so the contribution of the structural prior cannot be isolated or verified from the given text.
- [Method description] Method description (regime predictor and prior construction): no quantitative evaluation of the regime predictor's accuracy on the estimated descriptors (e.g., correlation with ground-truth seasonality or forecastability) is reported, leaving the premise that these estimates produce a usable soft prior untested and load-bearing for the specialization claim.
- [Experiments] Experiments (GIFT-Eval and M5 sections): the manuscript supplies no ablation that removes or randomizes the structural prior while keeping the regime predictor and backbone fixed, nor any analysis of routing geometry (e.g., expert activation histograms or routing entropy) with versus without the prior; without these, attribution of the reported gains to structure-aware routing rather than other factors remains unsupported.
minor comments (2)
- [Method] Clarify the precise mathematical form of the soft structural prior and its integration into the router (e.g., whether it is added to logits, used as a multiplicative bias, or incorporated via a separate loss term).
- [Method] Provide the exact definition and implementation details of the lightweight regime predictor (architecture, input features, training objective).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, indicating planned revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline GIFT-Eval accuracy-efficiency claims and the M5 stability result are asserted without any description of experimental protocol, baseline implementations, statistical tests, number of runs, or ablation studies, so the contribution of the structural prior cannot be isolated or verified from the given text.
Authors: The abstract is intentionally concise per venue norms. Full details on the GIFT-Eval and M5 protocols, baselines, statistical tests, run counts, and ablations appear in Section 4. We will revise the abstract to add one sentence referencing the multi-run evaluation protocol and benchmark details to improve traceability without exceeding length limits. revision: partial
-
Referee: [Method description] Method description (regime predictor and prior construction): no quantitative evaluation of the regime predictor's accuracy on the estimated descriptors (e.g., correlation with ground-truth seasonality or forecastability) is reported, leaving the premise that these estimates produce a usable soft prior untested and load-bearing for the specialization claim.
Authors: We agree this evaluation would strengthen the premise. The manuscript does not currently report direct accuracy or correlation metrics for the regime predictor against ground-truth descriptors. We will add a quantitative assessment (e.g., correlations on datasets with known seasonality/forecastability labels) in a revised methods subsection. revision: yes
-
Referee: [Experiments] Experiments (GIFT-Eval and M5 sections): the manuscript supplies no ablation that removes or randomizes the structural prior while keeping the regime predictor and backbone fixed, nor any analysis of routing geometry (e.g., expert activation histograms or routing entropy) with versus without the prior; without these, attribution of the reported gains to structure-aware routing rather than other factors remains unsupported.
Authors: This is a substantive concern. While the paper compares against standard MoE, it lacks the requested controlled ablation of the structural prior (regime predictor and backbone fixed) and routing geometry metrics. We will add both the ablation study and routing entropy/activation histogram comparisons in the revised experiments section to better isolate the prior's contribution. revision: yes
Circularity Check
No circularity detected; claims rest on empirical benchmark results rather than definitional reductions
full rationale
The manuscript proposes an architectural modification (lightweight regime predictor producing series-level descriptors mapped to a soft prior for MoE routing) and reports empirical results on GIFT-Eval and M5. No equations, fitted parameters, or self-citations are shown that would make any performance claim equivalent to its inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- regime predictor parameters
axioms (1)
- standard math Standard Mixture-of-Experts routing assumptions hold (softmax gating, top-k selection).
invented entities (1)
-
structural prior over experts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gift-eval: General time series forecasting model evaluation.arXiv preprint arXiv:2410.10393, 2024
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. Gift-eval: A benchmark for general time series forecasting model evaluation. arXiv preprint arXiv:2410.10393, 2024
-
[2]
Chronos-2: From Univariate to Universal Forecasting
Abdul Fatir Ansari, Oleksandr Shchur, Jaris Küken, Andreas Auer, Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, et al. Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Andreas Auer, Patrick Podest, Daniel Klotz, Sebastian Böck, Günter Klambauer, and Sepp Hochreiter. Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning.arXiv preprint arXiv:2505.23719, 2025
-
[5]
Deep learning for time series forecasting: Tutorial and literature survey.ACM Computing Surveys, 55(6):1–36, 2022
Konstantinos Benidis, Syama Sundar Rangapuram, Valentin Flunkert, Yuyang Wang, Danielle Maddix, Caner Turkmen, Jan Gasthaus, Michael Bohlke-Schneider, David Salinas, Lorenzo Stella, et al. Deep learning for time series forecasting: Tutorial and literature survey.ACM Computing Surveys, 55(6):1–36, 2022
2022
-
[6]
A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[7]
Conversational time series foundation models: Towards explainable and effective forecasting
Defu Cao, Michael Gee, Jinbo Liu, Hengxuan Wang, Wei Yang, Rui Wang, and Yan Liu. Conversational time series foundation models: Towards explainable and effective forecasting. arXiv preprint arXiv:2512.16022, 2025
-
[8]
Stl: A seasonal-trend decomposition.J
Robert B Cleveland, William S Cleveland, Jean E McRae, Irma Terpenning, et al. Stl: A seasonal-trend decomposition.J. off. Stat, 6(1):3–73, 1990
1990
-
[9]
Deepseekmoe: Towards ultimate expert specializa- tion in mixture-of-experts language models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. Deepseekmoe: Towards ultimate expert specializa- tion in mixture-of-experts language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1280–1297, 2024
2024
-
[10]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InForty-first international conference on machine learning, 2024
2024
-
[11]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[12]
Monash Time Series Forecasting Archive.arXiv preprint arXiv:2105.06643, 2021
Rakshitha Godahewa, Christoph Bergmeir, Geoffrey I Webb, Rob J Hyndman, and Pablo Montero-Manso. Monash time series forecasting archive.arXiv preprint arXiv:2105.06643, 2021
-
[13]
Forecastable component analysis
Georg Goerg. Forecastable component analysis. InInternational conference on machine learning, pages 64–72. PMLR, 2013
2013
-
[14]
Advancing expert specialization for better moe
Hongcan Guo, Haolang Lu, Guoshun Nan, Bolun Chu, Jialin Zhuang, Yuan Yang, Wenhao Che, Xinye Cao, Sicong Leng, Qimei Cui, et al. Advancing expert specialization for better moe. arXiv preprint arXiv:2505.22323, 2025
-
[15]
Guiding mixture-of-experts with temporal multimodal interactions
Xing Han, Hsing-Huan Chung, Joydeep Ghosh, Paul Pu Liang, and Suchi Saria. Guiding mixture-of-experts with temporal multimodal interactions. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[16]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021
2021
-
[18]
Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
Chenghao Liu, Taha Aksu, Juncheng Liu, Xu Liu, Hanshu Yan, Quang Pham, Silvio Savarese, Doyen Sahoo, Caiming Xiong, and Junnan Li. Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
-
[19]
Xu Liu, Juncheng Liu, Gerald Woo, Taha Aksu, Yuxuan Liang, Roger Zimmermann, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. Moirai-moe: Empowering time series foundation models with sparse mixture of experts.arXiv preprint arXiv:2410.10469, 2024
-
[20]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Sundial: A Family of Highly Capable Time Series Foundation Models
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Sundial: A family of highly capable time series foundation models. arXiv preprint arXiv:2502.00816, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
M5 accuracy competi- tion: Results, findings, and conclusions.International journal of forecasting, 38(4):1346–1364, 2022
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. M5 accuracy competi- tion: Results, findings, and conclusions.International journal of forecasting, 38(4):1346–1364, 2022
2022
-
[23]
Switch-neRF: Learning scene decomposition with mixture of experts for large-scale neural radiance fields
Zhenxing MI and Dan Xu. Switch-neRF: Learning scene decomposition with mixture of experts for large-scale neural radiance fields. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[24]
Chengxi Min, Wei Wang, Yahui Liu, Weixin Ye, Enver Sangineto, Qi Wang, and Yao Zhao. Guiding the experts: Semantic priors for efficient and focused moe routing.arXiv preprint arXiv:2505.18586, 2025
-
[25]
Time series prediction using deep learning methods in healthcare.ACM Transactions on Management Information Systems, 14(1):1–29, 2023
Mohammad Amin Morid, Olivia R Liu Sheng, and Joseph Dunbar. Time series prediction using deep learning methods in healthcare.ACM Transactions on Management Information Systems, 14(1):1–29, 2023
2023
-
[26]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[27]
fev-bench: A Realistic Benchmark for Time Series Forecasting
Oleksandr Shchur, Abdul Fatir Ansari, Caner Turkmen, Lorenzo Stella, Nick Erickson, Pablo Guerron, Michael Bohlke-Schneider, and Yuyang Wang. fev-bench: A realistic benchmark for time series forecasting.arXiv preprint arXiv:2509.26468, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
MoME: Mixture of multimodal experts for generalist multimodal large language models
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. MoME: Mixture of multimodal experts for generalist multimodal large language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[29]
Mixture-of-experts meets instruction tuning: A winning combination for large language models
Sheng Shen, Le Hou, Yanqi Zhou, Nan Du, Shayne Longpre, Jason Wei, Hyung Won Chung, Barret Zoph, William Fedus, Xinyun Chen, Tu Vu, Yuexin Wu, Wuyang Chen, Albert Webson, Yunxuan Li, Vincent Y Zhao, Hongkun Yu, Kurt Keutzer, Trevor Darrell, and Denny Zhou. Mixture-of-experts meets instruction tuning: A winning combination for large language models. InThe ...
2024
-
[30]
Time- moe: Billion-scale time series foundation models with mixture of experts
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, and Ming Jin. Time- moe: Billion-scale time series foundation models with mixture of experts. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[31]
Towards physics- informed deep learning for turbulent flow prediction
Rui Wang, Karthik Kashinath, Mustafa Mustafa, Adrian Albert, and Rose Yu. Towards physics- informed deep learning for turbulent flow prediction. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1457–1466, 2020
2020
-
[32]
Time series forecastability measures.KDD 2025 Workshop on AI for Supply Chain, 2025
Rui Wang, Steven Klee, and Alexis Roos. Time series forecastability measures.KDD 2025 Workshop on AI for Supply Chain, 2025. 11
2025
-
[33]
An improved index for clustering validation based on silhouette index and calinski-harabasz index
Xu Wang and Yusheng Xu. An improved index for clustering validation based on silhouette index and calinski-harabasz index. InIOP conference series: materials science and engineering, volume 569, page 052024. IOP Publishing, 2019
2019
-
[34]
Routing matters in moe: Scaling diffusion transformers with explicit routing guidance
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Yujin Han, Zhekai Chen, Jiayu Wang, Difan Zou, Xihui Liu, Yingya Zhang, Yu Liu, and Hongming Shan. Routing matters in moe: Scaling diffusion transformers with explicit routing guidance. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[35]
Unified training of universal time series forecasting transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. InForty-first International Conference on Machine Learning, 2024
2024
-
[36]
Multi-head mixture-of-experts
Xun Wu, Shaohan Huang, Wenhui Wang, Shuming Ma, Li Dong, and Furu Wei. Multi-head mixture-of-experts. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[37]
Samoe: Parameter efficient moe language models via self-adaptive expert combination, 2023
Minjia Zhang, Conglong Li, Xiaoxia Wu, Zhewei Yao, and Yuxiong He. Samoe: Parameter efficient moe language models via self-adaptive expert combination, 2023
2023
-
[38]
MoV A: Adapting mixture of vision experts to multimodal context
Zhuofan Zong, Bingqi Ma, Dazhong Shen, Guanglu Song, Hao Shao, Dongzhi Jiang, Hongsheng Li, and Yu Liu. MoV A: Adapting mixture of vision experts to multimodal context. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 12 A Additional Experimental and Implementation Details A.1 Model Architecture Details We evaluate fiv...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.