JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
Pith reviewed 2026-06-30 11:13 UTC · model grok-4.3
The pith
Comparative judgments recover the intended quality ordering substantially better than rubrics in a benchmark of legal tasks annotated by practicing attorneys.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
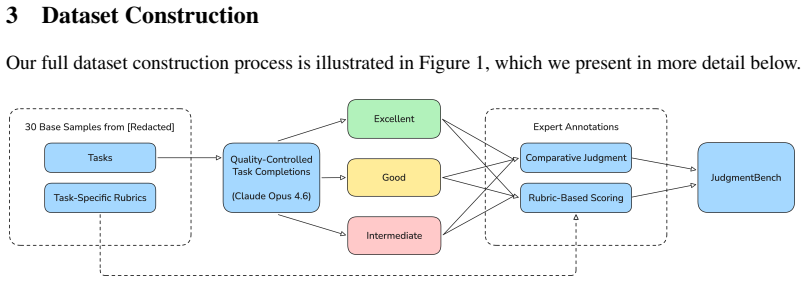
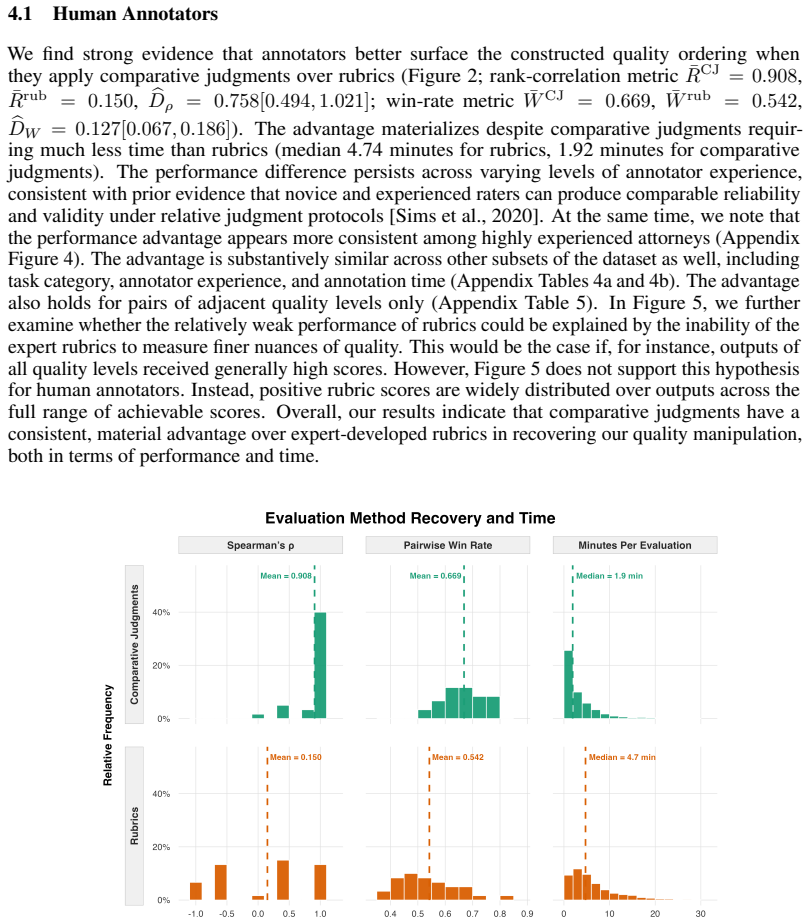
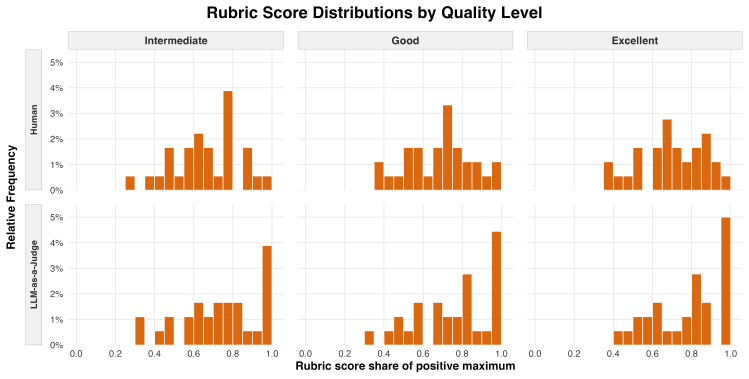
Using LLM-generated outputs at three constructed quality levels, comparative judgments recover the intended quality ordering substantially better than rubrics under both a per-task rank-correlation metric (mean Spearman's rank correlation of 0.908 vs. 0.150, estimated difference = 0.758 [0.494, 1.021]) and a per-judgment pairwise win-rate metric (0.669 vs. 0.542, estimated difference = 0.127 [0.067, 0.186]), while requiring less than half the annotation time. The patterns hold for human annotators and LLM autograders. The annotations come from practicing attorneys on 30 real-world legal tasks with LLM outputs at three quality levels.
What carries the argument
The JudgmentBench dataset, which pairs rubric scores and pairwise preference judgments elicited from the same experts on the same items.
If this is right
- Comparative judgments provide a more reliable signal than rubrics for recovering intended quality orderings.
- Pairwise methods require less than half the annotation time of rubric scoring.
- The advantage of comparative judgments appears for both human experts and LLM autograders.
- The paired dataset structure enables research on how to elicit and aggregate expert judgments in domains without verifiable ground truth.
Where Pith is reading between the lines
- The method could be tested in other high-expertise domains such as medicine to check whether the advantage generalizes beyond law.
- The dataset could be used to compare different aggregation techniques for turning multiple pairwise judgments into overall rankings.
- Repeating the comparison with outputs from additional models or with varying numbers of quality levels would test the robustness of the observed gap.
Load-bearing premise
The three constructed quality levels of the LLM-generated outputs accurately represent distinct, ordered tiers of quality that experts can reliably distinguish.
What would settle it
A study in which the same experts judge outputs whose quality levels are independently verified by objective external criteria and the performance gap between the two methods disappears.
Figures

read the original abstract
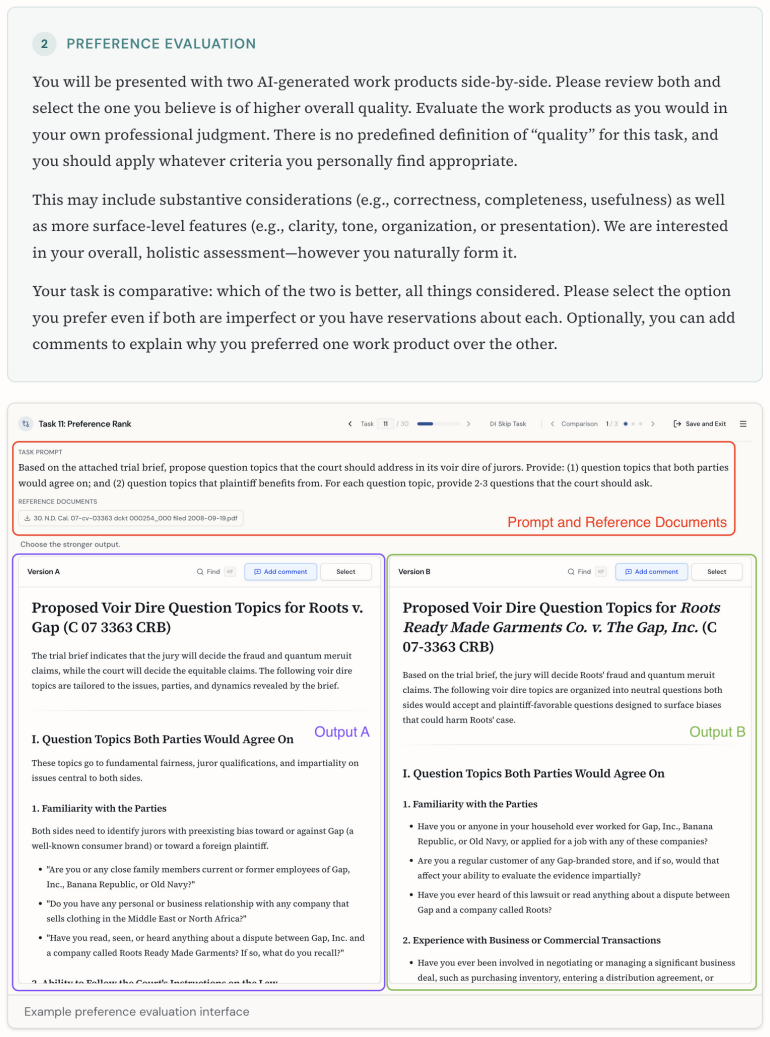
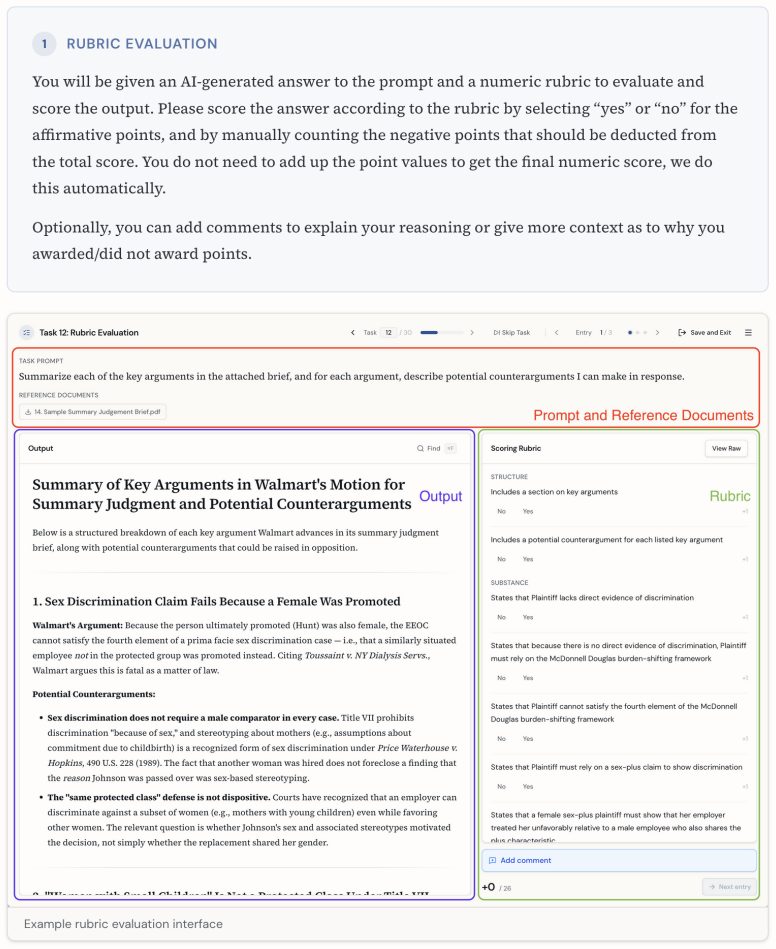
Two methodologies dominate current practices of benchmarking: rubric-based scoring evaluates items against predefined criteria, whereas comparative judgment elicits pairwise preferences between outputs. Although both methodologies are widely used, the choice between them is rarely justified. We release JudgmentBench, a benchmark of 30 real-world legal tasks, paired with 1,539 rubric scores and 1,530 pairwise preference judgments collected from practicing attorneys--including at major U.S. law firms--with substantial experience. The annotations constitute the first publicly available dataset in a high-expertise domain in which both supervision signals are elicited from the same experts on the same items. Using LLM-generated outputs at three constructed quality levels, we provide an initial empirical comparison: comparative judgments recover the intended quality ordering substantially better than rubrics under both a per-task rank-correlation metric (mean Spearman's rank correlation of 0.908 vs. 0.150, estimated difference = 0.758 [0.494, 1.021]) and a per-judgment pairwise win-rate metric (0.669 vs. 0.542, estimated difference = 0.127 [0.067, 0.186]), while requiring less than half the annotation time. The patterns hold for human annotators and LLM autograders. Beyond this initial comparison, the paired structure of the dataset supports a broader research agenda on how expert judgment should be elicited, aggregated, and used as supervision in domains without verifiable ground truth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JudgmentBench, a dataset of 30 real-world legal tasks with 1,539 rubric scores and 1,530 pairwise preference judgments collected from practicing attorneys. Using LLM-generated outputs at three author-constructed quality levels, it compares rubric-based and comparative judgment methods, reporting that pairwise preferences recover the intended ordering substantially better (mean Spearman's rank correlation 0.908 vs. 0.150; pairwise win-rate 0.669 vs. 0.542) while requiring less annotation time. The patterns are stated to hold for both human annotators and LLM autograders, and the paired dataset is released to support research on judgment elicitation in domains without verifiable ground truth.
Significance. If the three constructed quality tiers are shown to be reliably distinguishable, the work supplies the first public paired dataset of rubric and preference annotations from the same high-expertise annotators on identical items, offering concrete evidence favoring comparative judgment for LLM output evaluation in legal domains and a resource for studying aggregation and supervision. The release of the dataset itself constitutes a reusable contribution independent of the comparative result.
major comments (2)
- [Abstract] Abstract: the headline metrics (Spearman's ρ = 0.908 vs. 0.150; win-rate 0.669 vs. 0.542) measure recovery of three author-defined quality tiers produced by prompting LLMs at different quality levels; no independent verification is described that experts, shown outputs blind to tier labels, assign ratings or rankings that separate the three groups with low overlap.
- [Dataset construction (LLM output generation)] The paper treats the three constructed tiers as ground truth for both the rank-correlation and win-rate calculations, yet provides no test that the tiers differ on rubric dimensions independently of the generation prompts; if the separation is an artifact of prompting, both recovery statistics become uninterpretable as evidence about real-world quality assessment.
minor comments (1)
- Ensure that the exact numbers of rubric scores (1,539) and pairwise judgments (1,530) are reported consistently in the main text and any tables that break down the annotations by task or annotator.
Simulated Author's Rebuttal
We thank the referee for highlighting the distinction between constructed tiers and independently verified quality differences. We address both major comments below by clarifying the scope of our claims and proposing targeted revisions. No standing objections remain after these clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline metrics (Spearman's ρ = 0.908 vs. 0.150; win-rate 0.669 vs. 0.542) measure recovery of three author-defined quality tiers produced by prompting LLMs at different quality levels; no independent verification is described that experts, shown outputs blind to tier labels, assign ratings or rankings that separate the three groups with low overlap.
Authors: We agree the manuscript does not include a blind expert verification step in which annotators rate or rank outputs without knowledge of the generation tier. The reported metrics specifically measure recovery of the intended ordering induced by the three prompt variants. We will revise the abstract to replace 'intended quality ordering' with explicit language stating that the tiers are prompt-constructed and that the experiment evaluates recovery of those constructions rather than independently validated real-world quality distinctions. A new limitations paragraph will be added noting the absence of blind separation tests. revision: yes
-
Referee: [Dataset construction (LLM output generation)] The paper treats the three constructed tiers as ground truth for both the rank-correlation and win-rate calculations, yet provides no test that the tiers differ on rubric dimensions independently of the generation prompts; if the separation is an artifact of prompting, both recovery statistics become uninterpretable as evidence about real-world quality assessment.
Authors: The paper explicitly labels the tiers as 'constructed' and frames the metrics as recovery of the intended ordering. No additional test (e.g., expert rubric ratings collected blind to tier or independent of the generation prompts) was performed to confirm separation on rubric dimensions. We will expand the dataset-construction section with the exact prompt templates used for each tier and add discussion text acknowledging that the results demonstrate comparative judgment's advantage at recovering prompt-induced differences, which may or may not generalize to intrinsic quality differences. This limitation will also be noted in the revised abstract. revision: yes
Circularity Check
No significant circularity; purely empirical comparison on constructed benchmark
full rationale
The paper reports an empirical study that constructs three quality tiers via LLM prompting, elicits rubric scores and pairwise judgments from experts on the same items, and computes direct recovery metrics (Spearman's rho and win-rate) against the author-defined ordering. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The central results are straightforward statistical comparisons on held-out data and do not reduce to self-referential definitions or load-bearing self-citations. This is a standard empirical design whose validity rests on the benchmark construction assumption rather than any circular reduction in the reported chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Practicing attorneys with substantial experience provide reliable and consistent judgments on legal task quality.
- domain assumption The three constructed quality levels of LLM outputs correspond to meaningfully distinct tiers that experts can distinguish.
Reference graph
Works this paper leans on
-
[1]
doi: 10.3389/feduc.2018.00022. URL https://www.frontiersin.org/journals/edu cation/articles/10.3389/feduc.2018.00022/full. 10 Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Katz, and Nikolaos Aletras. LexGLUE: A benchmark dataset for legal language understanding in English. In Smaranda Muresan, Preslav Nakov, and...
-
[2]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.474. Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A. Smith. All that’s ‘human’ is not gold: Evaluating human evaluation of generated text. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 1...
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/N18-2017. Harvey Team. Introducing BigLaw Bench, 2024. URL https://www.harvey.ai/blog/introdu cing-biglaw-bench. Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. LLM-rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. ...
-
[4]
doi: 10.18653/v1/2023.emnlp-main.844. Richard Kimbell. Evolving project e-scape for national assessment.International Journal of Technology and Design Education, 22(2):135–155, May 2012. ISSN 1573-1804. doi: 10.1007/s1 0798-011-9190-4. URLhttps://doi.org/10.1007/s10798-011-9190-4. Richard Kimbell. Examining the reliability of Adaptive Comparative Judgemen...
-
[5]
URLhttps://openreview.net/forum?id=iO4LZibEqW. Dengcan Liu, Fengkai Yang, Xiaohan Wang, Shurui Yan, Jiajun Chai, Jiahao Li, Yikun Ban, Zhendong Mao, Wei Lin, and Guojun Yin. CDRRM: Contrast-driven rubric generation for reliable and interpretable reward modeling, 2026. URLhttps://arxiv.org/abs/2603.08035. Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang,...
-
[6]
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
doi: 10.3102/0013189X023002005. Jesutofunmi A. Omiye, Haiwen Gui, Shawheen J. Rezaei, James Zou, and Roxana Daneshjou. Large Language Models in Medicine: The Potentials and Pitfalls: A Narrative Review.Annals of Internal Medicine, 177(2):210–220, 2024. doi: 10.7326/M23-2772. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mish...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3102/0013189x023002005 2024
-
[7]
URLhttps://arxiv.org/abs/2601.03986. arXiv:2601.03986 [cs]. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. Advances in Neural Information Processing Systems, 36:53728–53741, 2023. doi: 10.52202/075 280-2338. URL https://...
-
[8]
arXiv preprint arXiv:2504.14716 , year =
doi: 10.48550/arxiv.2504.14716. URL https://openreview.net/forum?id=uyX5Vn ow3U. Vals AI. Vals Legal AI Report. Vals AI, February 2025. URL https://www.vals.ai/industry -reports/vlair-2-27-25. Accessed: 2026-05-02. Tine van Daal, Marije Lesterhuis, Liesje Coertjens, Marie-Thérèse van de Kamp, Vincent Donche, and Sven De Maeyer. The Complexity of Assessing...
-
[9]
Change of Control Provisions in Salesforce MSA
**Open with a descriptive title line** summarizing the topic of your response (e.g., "Change of Control Provisions in Salesforce MSA" or "Ratification of Defective Corporate Acts Under Delaware Law")
-
[10]
Based on my review of the agreement, here is a summary of the shareholder approval required to vary the rights of shares
**Begin with a brief framing sentence** (1-3 sentences) that orients the reader to what follows --- e.g., "Based on my review of the agreement, here is a summary of the shareholder approval required to vary the rights of shares." Do not write a long preamble or restate the question at length
-
[11]
**Organize the body into numbered sections with descriptive headings.** Use a clear hierarchy: - Top-level sections: numbered (1, 2, 3... or I, II, III...) with bold descriptive titles - Subsections: lettered (A, B, C...) or sub-numbered (1., 2., 3...) with their own descriptive titles - Keep heading titles short and informative
-
[12]
this is not legal advice,
**End with a closing element.** Every response should conclude with one or more of: - A **Summary Table** consolidating key findings - **Key Takeaways** or **Key Observations** (a short numbered or bulleted list of the most important points) - A **Conclusion** section (2-5 sentences) - **Practical Considerations** or **Practical Steps** (actionable guidan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.