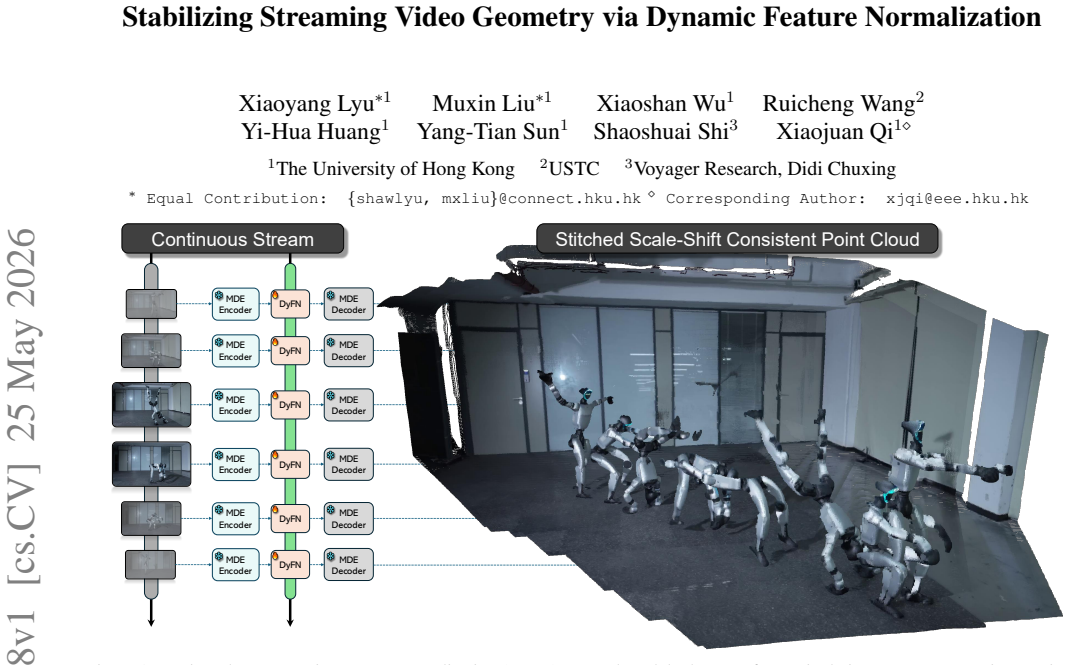
Stabilizing Streaming Video Geometry via Dynamic Feature Normalization
Pith reviewed 2026-06-29 23:12 UTC · model grok-4.3
The pith
Dynamic Feature Normalization stabilizes scale and shift in streaming monocular depth by modulating latent feature statistics over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
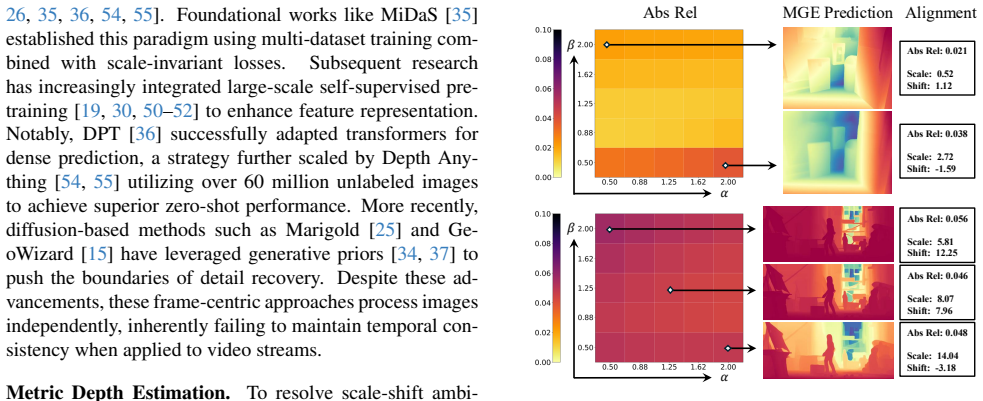
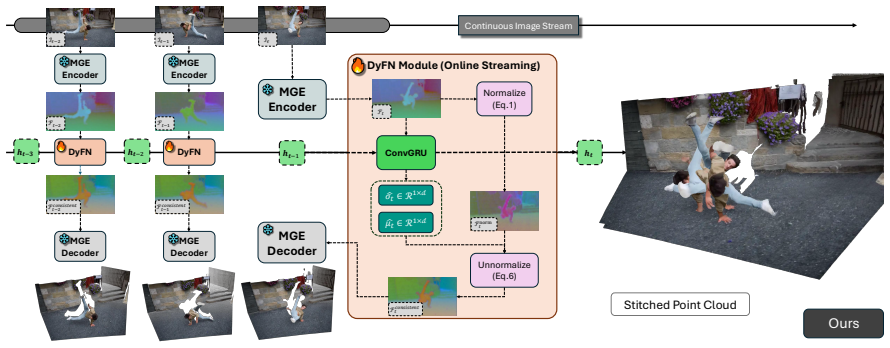
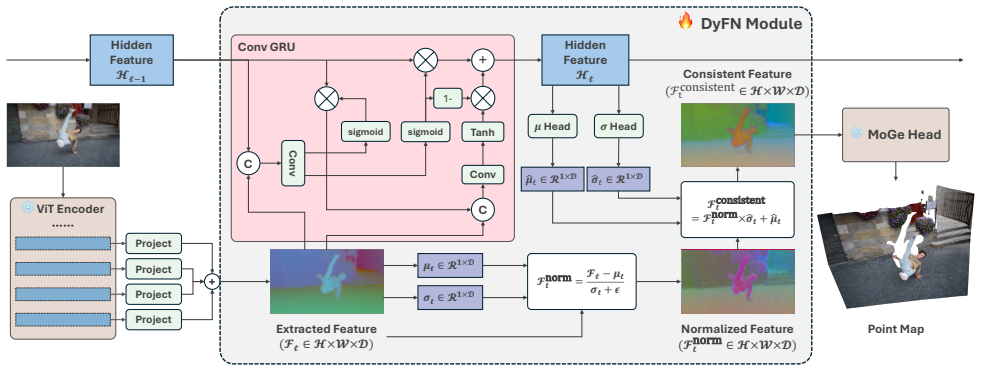
Fluctuations in the mean and variance of latent features cause scale-shift drifting in depth predictions from streaming input. Dynamic Feature Normalization (DyFN) is a causal recurrent module that dynamically modulates these statistics to produce stable geometry estimates. Adapting pretrained models by training only DyFN yields state-of-the-art temporal stability on four benchmarks, outperforming prior streaming methods by up to 14 percent and some non-causal baselines.
What carries the argument
Dynamic Feature Normalization (DyFN), a lightweight causal recurrent module that dynamically and robustly modulates feature statistics to maintain stable geometry over time.
If this is right
- Temporal artifacts such as disjointed layering and positional jitter are eliminated.
- Single-image accuracy is preserved while gaining temporal consistency.
- Only 2% additional parameters are finetuned with the backbone frozen.
- Performance improves over prior streaming methods by up to 14% and exceeds some heavier non-causal video baselines.
Where Pith is reading between the lines
- The same normalization principle could extend to stabilizing other monocular outputs like surface normals in continuous video.
- DyFN-style adaptation might lower compute costs when deploying geometry models on resource-limited streaming devices.
- Longer video sequences with varying motion could test whether the causal design holds without future-frame information.
Load-bearing premise
Fluctuations in latent feature statistics are the root cause of temporal instability in predicted depth scale and shift.
What would settle it
A controlled test where feature mean and variance are artificially stabilized across frames in a baseline model without DyFN, checking if temporal consistency improves to match DyFN levels.
Figures




read the original abstract
Consistent 3D geometry estimation from streaming RGB input is crucial for real-world applications such as autonomous driving, embodied AI, and large-scale reconstruction. While modern monocular geometry foundation models achieve strong single-image accuracy, they exhibit severe temporal inconsistency on continuous input, notably dominated by scale--shift drifting. Through targeted empirical analysis, we trace this instability to its root cause: fluctuations in latent feature statistics, whose mean and variance directly determine the predicted depth's scale and shift. Building on this insight, we introduce Dynamic Feature Normalization (DyFN), a lightweight, causal recurrent module that dynamically and robustly modulates feature statistics to maintain stable geometry over time. We adapt powerful pretrained monocular geometry models for streaming by finetuning only DyFN, a mere 2\% additional parameters, while keeping the backbone frozen, thereby achieving temporal consistency without compromising single-image accuracy. Extensive experiments across four benchmarks show that DyFN effectively eliminates temporal artifacts such as disjointed layering and positional jitter, and achieves state-of-the-art temporal stability, improving over prior streaming methods by up to 14\% and even outperforming heavier non-causal video baselines. Project Page: https://shawlyu.github.io/DyFN
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that temporal instability (scale-shift drifting, disjointed layering, positional jitter) in monocular depth estimation on streaming video arises from fluctuations in the mean and variance of latent features, which directly control the predicted depth's scale and shift. It introduces Dynamic Feature Normalization (DyFN), a lightweight causal recurrent module that dynamically modulates these statistics. The approach freezes a pretrained monocular geometry backbone and finetunes only the DyFN module (2% additional parameters) to achieve temporal consistency while preserving single-frame accuracy. Experiments on four benchmarks report that DyFN eliminates the listed artifacts, yields state-of-the-art temporal stability, improves over prior streaming methods by up to 14%, and even surpasses some heavier non-causal video baselines.
Significance. If the empirical support for the root-cause analysis and the reported gains hold under scrutiny, the work offers a practical, low-overhead route to adapt strong single-image geometry foundation models to streaming settings. The emphasis on causality, minimal parameter count, and retention of single-frame performance is directly relevant to autonomous driving, embodied AI, and large-scale reconstruction. The explicit attribution of instability to feature-statistic fluctuations, if substantiated, supplies a reusable diagnostic insight for similar normalization-sensitive tasks.
minor comments (3)
- [Abstract] Abstract: the phrase 'targeted empirical analysis' that traces the root cause would be more informative if it briefly referenced the key diagnostic experiment or figure that isolates feature-statistic fluctuations from other possible sources of drift.
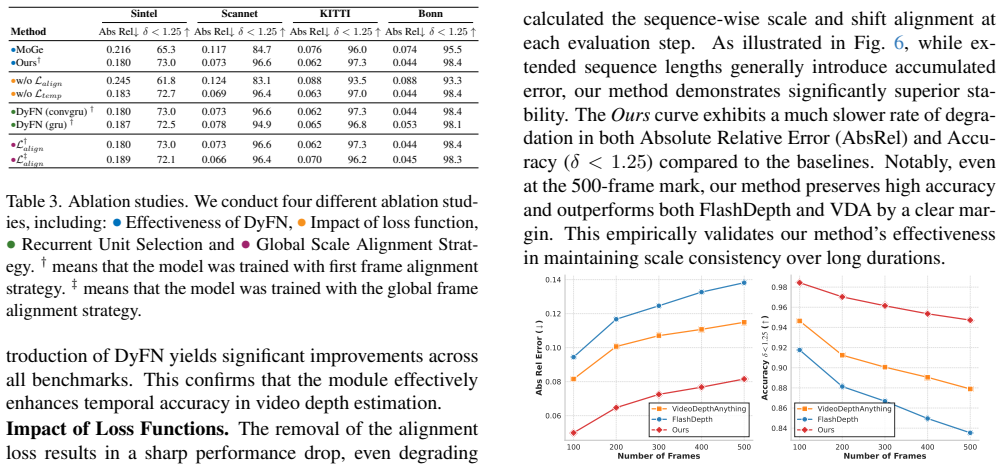
- [§4] §4 (Experiments): confirm that all quantitative tables report the same backbone, identical data splits, and either standard deviations across runs or error bars; the 'up to 14%' improvement claim requires this context to be fully interpretable.
- [Figure 3] Figure 3 or equivalent (qualitative results): add side-by-side temporal sequences with explicit frame indices so readers can directly verify the claimed elimination of disjointed layering and jitter.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its practical relevance for streaming applications, and the recommendation for minor revision. We are pleased that the attribution of temporal instability to latent feature statistics and the efficiency of DyFN (2% parameters, causal, single-frame accuracy preserved) were viewed favorably.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claim rests on an empirical observation (fluctuations in latent feature statistics cause scale-shift drift) identified via targeted analysis, followed by introduction of a lightweight recurrent module (DyFN) trained to stabilize those statistics while freezing the backbone. No equations, predictions, or first-principles results are presented that reduce by construction to fitted parameters or self-defined quantities; the method is an additive empirical intervention whose performance is evaluated externally on benchmarks. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The derivation is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fluctuations in latent feature statistics are the root cause of scale-shift drifting in streaming depth predictions.
invented entities (1)
-
Dynamic Feature Normalization (DyFN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Delving deeper into convolutional networks for learning video representations
Nicolas Ballas, Yao Li, Chris Pal, and Aaron Courville. Delving deeper into convolutional networks for learning video representations. InInternational Conference on Learn- ing Representations (ICLR), 2016. 3, 5
2016
-
[2]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M ¨uller. Zoedepth: Zero-shot trans- fer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
1–a model zoo for robust monocular relative depth estimation
Reiner Birkl, Diana Wofk, and Matthias M ¨uller. Midas v3.1 – a model zoo for robust monocular relative depth estimation. arXiv preprint arXiv:2307.14460, 2023. 2, 4
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Depth pro: Sharp monocular metric depth in less than a second
Alexey Bochkovskiy, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. InThe Thirteenth International Conference on Learning Representations, 2025. 6
2025
-
[6]
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation. InEuropean Conf. on Computer Vision (ECCV), pages 611– 625, 2012. 6, 2
2012
-
[7]
Must3r: Multi-view network for stereo 3d recon- struction
Yohann Cabon, Lucas Stoffl, Leonid Antsfeld, Gabriela Csurka, Boris Chidlovskii, Jerome Revaud, and Vincent Leroy. Must3r: Multi-view network for stereo 3d recon- struction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1050–1060, 2025. 3
2025
-
[8]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zi- long Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. arXiv preprint arXiv:2501.12375, 2025. 3
-
[9]
Video depth any- thing: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zi- long Huang, Jiashi Feng, and Bingyi Kang. Video depth any- thing: Consistent depth estimation for super-long videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22831–22840, 2025. 8
2025
-
[10]
TTT3R: 3D Reconstruction as Test-Time Training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Ttt3r: 3d reconstruction as test-time training. arXiv preprint arXiv:2509.26645, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Gene Chou, Wenqi Xian, Guandao Yang, Mohamed Ab- delfattah, Bharath Hariharan, Noah Snavely, Ning Yu, and Paul Debevec. Flashdepth: Real-time streaming video depth estimation at 2k resolution.arXiv preprint arXiv:2504.07093, 2025. 2, 3, 6, 8
-
[12]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 6, 8, 2
2017
-
[13]
Omnidata: A scalable pipeline for making multi- task mid-level vision datasets from 3d scans
Ainaz Eftekhar, Alexander Sax, Jitendra Malik, and Amir Zamir. Omnidata: A scalable pipeline for making multi- task mid-level vision datasets from 3d scans. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 10786–10796, 2021. 2
2021
-
[14]
Mid-air: A multi-modal dataset for extremely low altitude drone flights
Michael Fonder and Marc Van Droogenbroeck. Mid-air: A multi-modal dataset for extremely low altitude drone flights. InConference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2019. 2
2019
-
[15]
Geowiz- ard: Unleashing the diffusion priors for 3d geometry esti- mation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowiz- ard: Unleashing the diffusion priors for 3d geometry esti- mation from a single image. InEuropean Conference on Computer Vision, pages 241–258. Springer, 2024. 3
2024
-
[16]
Vision meets robotics: The kitti dataset.Interna- tional Journal of Robotics Research (IJRR), 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.Interna- tional Journal of Robotics Research (IJRR), 2013. 6, 2
2013
-
[17]
Mamba: Linear-time sequence mod- eling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence mod- eling with selective state spaces. InFirst conference on lan- guage modeling, 2024. 3
2024
-
[18]
Depth any camera: Zero-shot metric depth estimation from any camera
Yuliang Guo, Sparsh Garg, S Mahdi H Miangoleh, Xinyu Huang, and Liu Ren. Depth any camera: Zero-shot metric depth estimation from any camera. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26996–27006, 2025. 3
2025
-
[19]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 3
2022
-
[20]
Long short-term memory.Neural Comput., 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short-term memory.Neural Comput., 9(8):1735–1780, 1997. 3
1997
-
[21]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10579–10596, 2024. 3
2024
-
[22]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos.arXiv preprint arXiv:2409.02095, 2024. 2, 3, 6
-
[23]
Dy- namicstereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Dy- namicstereo: Consistent dynamic depth from stereo videos. CVPR, 2023. 2
2023
-
[24]
Video depth without video models.arXiv preprint arXiv:2411.19189, 2024
Bingxin Ke, Dominik Narnhofer, Shengyu Huang, Lei Ke, Torben Peters, Katerina Fragkiadaki, Anton Obukhov, and Konrad Schindler. Video depth without video models.arXiv preprint arXiv:2411.19189, 2024. 3
-
[25]
Repurpos- ing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Met- zger, Rodrigo Caye Daudt, and Konrad Schindler. Repurpos- ing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9492– 9502, 2024. 3, 6
2024
-
[26]
Megadepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single- view depth prediction from internet photos. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018. 3
2041
-
[27]
Spring: A high-resolution high- detail dataset and benchmark for scene flow, optical flow and stereo
Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Yaroslava Nali- vayko, and Andr ´es Bruhn. Spring: A high-resolution high- detail dataset and benchmark for scene flow, optical flow and stereo. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[28]
Mast3r-slam: Real-time dense slam with 3d reconstruction priors
Riku Murai, Eric Dexheimer, and Andrew J Davison. Mast3r-slam: Real-time dense slam with 3d reconstruction priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025. 3
2025
-
[29]
3d ken burns effect from a single image.ACM Transactions on Graphics, 38(6):184:1–184:15, 2019
Simon Niklaus, Long Mai, Jimei Yang, and Feng Liu. 3d ken burns effect from a single image.ACM Transactions on Graphics, 38(6):184:1–184:15, 2019. 2
2019
-
[30]
Maxime Oquab, Timoth ´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Rus- sell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang- Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nico- las Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patri...
2023
-
[31]
Palazzolo, J
E. Palazzolo, J. Behley, P. Lottes, P. Gigu `ere, and C. Stach- niss. ReFusion: 3D Reconstruction in Dynamic Environ- ments for RGB-D Cameras Exploiting Residuals. InPro- ceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2019. 6, 2
2019
-
[32]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10106–10116, 2024. 1, 3
2024
-
[33]
Unidepthv2: Universal monocular metric depth estimation made simpler, 2025
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler, 2025. 3
2025
-
[34]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Ren ´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020. 1, 3
2020
-
[36]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 3
2021
-
[37]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 3
2022
-
[38]
Learning temporally consistent video depth from video diffusion priors, 2024
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Vitor Guizilini, Yue Wang, Matteo Poggi, and Yiyi Liao. Learning temporally consistent video depth from video diffusion priors, 2024. 2, 3, 6
2024
-
[39]
Yang-Tian Sun, Xin Yu, Zehuan Huang, Yi-Hua Huang, Yuan-Chen Guo, Ziyi Yang, Yan-Pei Cao, and Xiaojuan Qi. Unigeo: Taming video diffusion for unified consistent ge- ometry estimation.arXiv preprint arXiv:2505.24521, 2025. 3
-
[40]
Temporal attention unit: To- wards efficient spatiotemporal predictive learning
Cheng Tan, Zhangyang Gao, Lirong Wu, Yongjie Xu, Jun Xia, Siyuan Li, and Stan Z Li. Temporal attention unit: To- wards efficient spatiotemporal predictive learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18770–18782, 2023. 3
2023
-
[41]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
3D Reconstruction with Spatial Memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Vggt: Visual geometry grounded transformer.arXiv preprint arXiv:2503.11651, 2025
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer.arXiv preprint arXiv:2503.11651, 2025. 3, 6
-
[44]
Irs: A large naturalis- tic indoor robotics stereo dataset to train deep models for disparity and surface normal estimation, 2021
Qiang Wang, Shizhen Zheng, Qingsong Yan, Fei Deng, Kaiyong Zhao, and Xiaowen Chu. Irs: A large naturalis- tic indoor robotics stereo dataset to train deep models for disparity and surface normal estimation, 2021. 2
2021
-
[45]
Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025. 2, 3, 6
-
[46]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5261–5271, 2025. 1, 2, 4, 6
2025
-
[47]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546,
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697– 20709, 2024. 3
2024
-
[49]
Tartanair: A dataset to push the limits of visual slam.2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Se- bastian Scherer. Tartanair: A dataset to push the limits of visual slam.2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020. 2
2020
-
[50]
Croco: Self-supervised pre-training for 3d vision tasks by cross-view completion.Advances in Neural Information Processing Systems, 35:3502–3516, 2022
Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Ro- main Br´egier, Yohann Cabon, Vaibhav Arora, Leonid Ants- feld, Boris Chidlovskii, Gabriela Csurka, and J ´erˆome Re- vaud. Croco: Self-supervised pre-training for 3d vision tasks by cross-view completion.Advances in Neural Information Processing Systems, 35:3502–3516, 2022. 3
2022
-
[51]
Croco v2: Improved cross-view completion pre- training for stereo matching and optical flow
Philippe Weinzaepfel, Thomas Lucas, Vincent Leroy, Yohann Cabon, Vaibhav Arora, Romain Br ´egier, Gabriela Csurka, Leonid Antsfeld, Boris Chidlovskii, and J ´erˆome Revaud. Croco v2: Improved cross-view completion pre- training for stereo matching and optical flow. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 17969–17...
2023
-
[52]
Aggregated residual transformations for deep neural networks
Saining Xie, Ross Girshick, Piotr Doll ´ar, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1492–1500,
-
[53]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935,
-
[54]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10371–10381, 2024. 1, 3, 6
2024
-
[55]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 1, 3, 6
2024
-
[56]
Learning to recover 3d scene shape from a single image
Wei Yin, Jianming Zhang, Oliver Wang, Simon Niklaus, Long Mai, Simon Chen, and Chunhua Shen. Learning to recover 3d scene shape from a single image. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 204–213, 2021. 3
2021
-
[57]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9043–9053, 2023. 1, 3
2023
-
[58]
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jam- pani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming- Hsuan Yang. Monst3r: A simple approach for estimat- ing geometry in the presence of motion.arXiv preprint arXiv:2410.03825, 2024. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Harley, Bokui Shen, Gordon Wet- zstein, and Leonidas J
Yang Zheng, Adam W. Harley, Bokui Shen, Gordon Wet- zstein, and Leonidas J. Guibas. Pointodyssey: A large-scale synthetic dataset for long-term point tracking. InICCV,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.