CollectionLoRA: Collecting 50 Effects in 1 LoRA via Multi-Teacher On-Policy Distillation
Pith reviewed 2026-06-29 22:32 UTC · model grok-4.3
The pith
A single LoRA can absorb concepts from up to 50 separate effect adapters plus few-step generation without interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
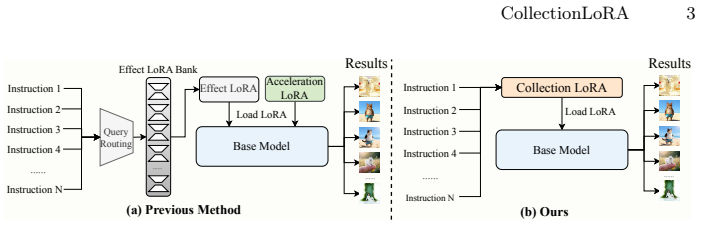
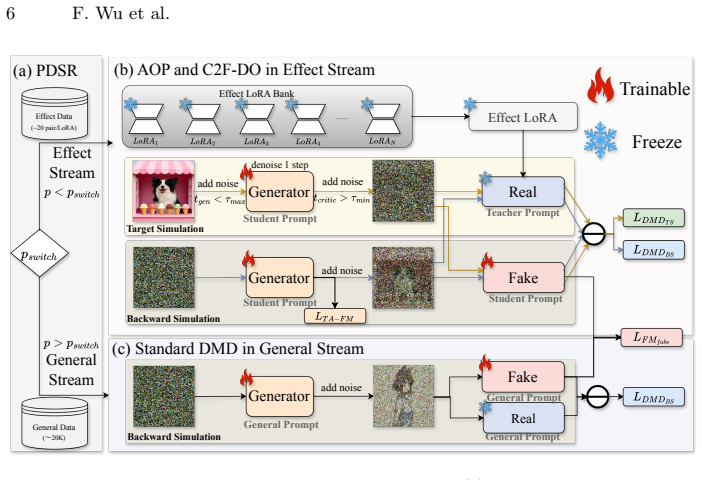
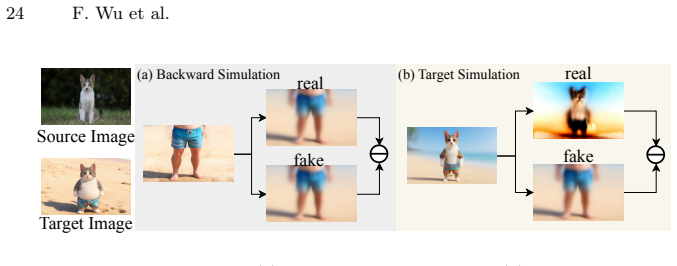
CollectionLoRA is a multi-teacher on-policy distillation framework capable of distilling the concepts of up to 50 different effect LoRAs along with few-step generation capabilities into a single LoRA. This fundamentally resolves the feature interference issue and significantly reduces deployment costs. Specifically, the method introduces a Probabilistic Dual-Stream Routing mechanism that enables the model to randomly switch between data sources during training, an Asymmetric Orthogonal Prompting strategy to achieve concept isolation within the prompt space, and a Coarse-to-Fine Distillation Objective to mitigate the distribution gap between the teacher and student models.
What carries the argument
Multi-teacher on-policy distillation using Probabilistic Dual-Stream Routing to switch data sources, Asymmetric Orthogonal Prompting for concept isolation, and Coarse-to-Fine Distillation Objective to close teacher-student gaps.
If this is right
- One adapter replaces many separate effect LoRAs, lowering storage and loading overhead during deployment.
- Concept fidelity stays comparable to or better than the independent teacher models.
- Few-step generation is retained inside the same adapter without cascading separate acceleration modules.
- Random switching between data sources improves generalization on prompts outside the training set.
Where Pith is reading between the lines
- The same distillation pattern could be tried on adapters for tasks other than visual effects, such as style or subject control.
- Production systems that switch models frequently might see lower latency once multiple capabilities live in one file.
- If the isolation mechanisms hold, the approach could be tested with more than 50 effects to check scaling limits.
Load-bearing premise
The three introduced components together suffice to isolate concepts and close the teacher-student distribution gap without requiring post-hoc data filtering or hyperparameter choices that affect the reported fidelity gains.
What would settle it
A side-by-side test of the single LoRA against the original separate teachers on prompts that request two or more effects at once, checking whether concept bleeding or quality drop appears in the outputs.
Figures
















read the original abstract
Customized image editing aims to equip pre-trained diffusion models with specific visual effects using limited paired data, typically via Low-Rank Adaptation (LoRA). As the number of desired effects grows, storing and dynamically loading numerous these effect LoRAs significantly increases deployment overhead. Furthermore, current pipelines typically cascade these effect LoRAs with acceleration modules for fast generation, which triggers severe parameter interference and results in concept bleeding and style degradation. We propose CollectionLoRA, a multi-teacher on-policy distillation framework capable of distilling the concepts of up to 50 different effect LoRAs along with few-step generation capabilities into a single LoRA. This fundamentally resolves the feature interference issue and significantly reduces deployment costs. Specifically, the method introduces (i) a Probabilistic Dual-Stream Routing mechanism that enables the model to randomly switch between data sources during training, effectively enhancing its generalization in unseen scenarios; (ii) an Asymmetric Orthogonal Prompting strategy to achieve concept isolation within the prompt space; (iii) a Coarse-to-Fine Distillation Objective to mitigate the distribution gap between the teacher and student models. Extensive evaluations show that CollectionLoRA distills all customized effects and few-step generation into a single LoRA, reducing deployment overhead while achieving concept fidelity comparable to or better than independently trained teacher models. Code: https://github.com/Qwen-Applications/CollectionLoRA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CollectionLoRA, a multi-teacher on-policy distillation method that consolidates concepts from up to 50 effect-specific LoRAs plus few-step generation into one LoRA for customized image editing in diffusion models. It introduces Probabilistic Dual-Stream Routing to improve generalization via random data-source switching, Asymmetric Orthogonal Prompting for prompt-space concept isolation, and a Coarse-to-Fine Distillation Objective to reduce teacher-student distribution gaps. The central claim is that these components together eliminate feature interference from cascaded LoRAs, achieve fidelity comparable or superior to separate teacher models, and reduce deployment overhead.
Significance. If the empirical support holds, the work would provide a concrete engineering route to scaling multi-effect customization without multiplicative storage or interference costs, which is a practical bottleneck in LoRA-based diffusion pipelines. The on-policy multi-teacher framing and the three listed mechanisms constitute a targeted contribution to parameter-efficient adaptation at scale.
major comments (2)
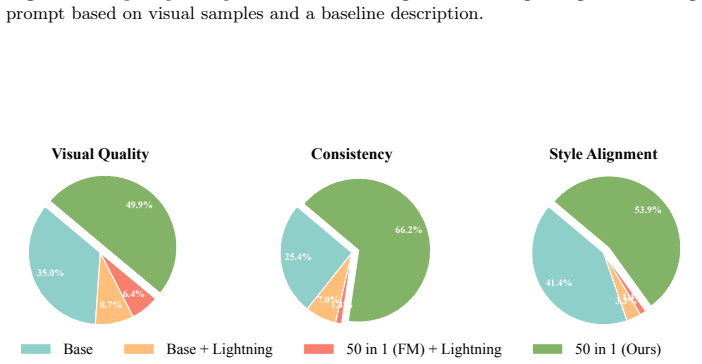
- [Abstract] Abstract: the assertion that 'extensive evaluations show' comparable or better fidelity and successful distillation of 50 effects supplies no metrics, baselines, dataset details, ablation tables, or quantitative results, leaving the central claim without visible load-bearing evidence.
- [Method] Method (components i–iii): the claim that Probabilistic Dual-Stream Routing, Asymmetric Orthogonal Prompting, and Coarse-to-Fine Distillation Objective are jointly sufficient to isolate 50 concepts and close the teacher-student gap without post-hoc filtering or hyperparameter regimes that mask interference is asserted but not demonstrated by any reported ablation or scaling experiment at the target scale.
minor comments (1)
- [Abstract] Abstract: 'numerous these effect LoRAs' is grammatically awkward and should be rephrased.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive evaluations show' comparable or better fidelity and successful distillation of 50 effects supplies no metrics, baselines, dataset details, ablation tables, or quantitative results, leaving the central claim without visible load-bearing evidence.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. The full manuscript contains detailed metrics, baselines, dataset descriptions, and ablation tables in the Experiments section. We will revise the abstract to incorporate key quantitative results (e.g., fidelity metrics and comparisons to teacher models) while preserving its concise nature. revision: yes
-
Referee: [Method] Method (components i–iii): the claim that Probabilistic Dual-Stream Routing, Asymmetric Orthogonal Prompting, and Coarse-to-Fine Distillation Objective are jointly sufficient to isolate 50 concepts and close the teacher-student gap without post-hoc filtering or hyperparameter regimes that mask interference is asserted but not demonstrated by any reported ablation or scaling experiment at the target scale.
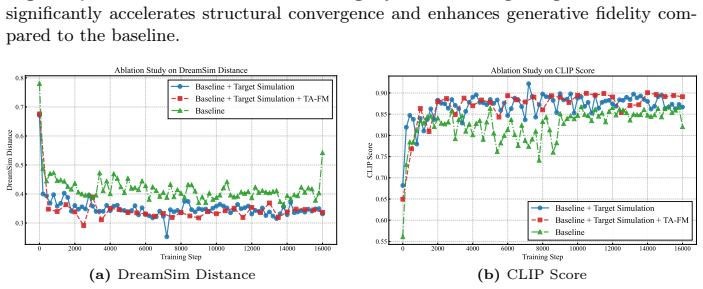
Authors: The manuscript reports ablation studies isolating the contribution of each component and scaling results up to 50 effects. However, we acknowledge that more explicit joint ablations and scaling curves at the exact 50-effect target, with controls for post-hoc filtering, would better demonstrate sufficiency. We will add these expanded experiments and analyses in the revised manuscript. revision: partial
Circularity Check
No circularity: framework claims rest on independent components and evaluations, not self-definition or fitted inputs
full rationale
The paper introduces CollectionLoRA as a new multi-teacher on-policy distillation method with three explicitly named components (Probabilistic Dual-Stream Routing, Asymmetric Orthogonal Prompting, Coarse-to-Fine Distillation Objective). No equations appear in the abstract or description, no parameters are described as fitted then relabeled as predictions, and no self-citations or uniqueness theorems are invoked to justify the central claims. The performance assertions are tied to 'extensive evaluations' rather than reducing by construction to the inputs or prior author work. This satisfies the criteria for a self-contained engineering proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
arXiv preprint arXiv:2511.20549 (2025)
Chen, G., Huang, S., Liu, K., Zhu, J., Qu, X., Chen, P., Cheng, Y., Sun, Y.: Flash- dmd: Towards high-fidelity few-step image generation with efficient distillation and joint reinforcement learning. arXiv preprint arXiv:2511.20549 (2025)
- [3]
-
[4]
aitookit Contributors: aitookit.https://github.com/ostris/ai-toolkit(2025)
2025
-
[5]
Contributors, L.: Lightx2v: Light video generation inference framework.https: //github.com/ModelTC/lightx2v(2025)
2025
-
[6]
DeepSeek-AI: Deepseek-v4-pro model card.https://huggingface.co/deepseek- ai/DeepSeek-V4-Pro(2026), accessed: 2026-05-04
2026
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[9]
Fang, Z., Huang, W., Zeng, Y., Zhao, Y., Chen, S., Feng, K., Lin, Y., Chen, L., Chen, Z., Cao, S., Zhao, F.: Flow-opd: On-policy distillation for flow matching models (2026),https://arxiv.org/abs/2605.08063
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Fu,S.,Tamir,N.,Sundaram,S.,Chai,L.,Zhang,R.,Dekel,T.,Isola,P.:Dreamsim: Learning new dimensions of human visual similarity using synthetic data (2023), https://arxiv.org/abs/2306.09344
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. arXiv preprint arXiv:2208.01618 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Gu, Y., Fang, G., Jiang, Y., Mao, W., Han, S., Cai, H., Shou, M.Z.: Anyflow: Any- step video diffusion model with on-policy flow map distillation (2026),https: //arxiv.org/abs/2605.13724
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Gu, Y., Dong, L., Wei, F., Huang, M.: Minillm: On-policy distillation of large language models (2026),https://arxiv.org/abs/2306.08543
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Guo,H.,Zeng,B.,Song,Y.,Zhang,W.,Liu,J.,Zhang,C.:Any2anytryon:Leverag- ing adaptive position embeddings for versatile virtual clothing tasks. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 19085– 19096 (2025)
2025
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models (2021),https://arxiv. org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [16]
-
[17]
arXiv preprint arXiv:2502.14397 (2025) 18 F
Huang, S., Song, Y., Zhang, Y., Guo, H., Wang, X., Shou, M.Z., Liu, J.: Photodoo- dle: Learning artistic image editing from few-shot pairwise data. arXiv preprint arXiv:2502.14397 (2025) 18 F. Wu et al
-
[18]
Jiang, D., Jin, X., Liu, D., Wang, Z., Zheng, M., Du, R., Yang, X., Wu, Q., Li, Z., Gao, P., Yang, H., Hoi, S.: D-opsd: On-policy self-distillation for continuously tuningstep-distilleddiffusionmodels(2026),https://arxiv.org/abs/2605.05204
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
URLhttps://doi.org/10.48550/arXiv.2511.13649
Jiang, D., Liu, D., Wang, Z., Wu, Q., Li, L., Li, H., Jin, X., Liu, D., Li, Z., Zhang, B., et al.: Distribution matching distillation meets reinforcement learning. arXiv preprint arXiv:2511.13649 (2025)
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kumari, N., Zhang, B., Zhang, R., Shechtman, E., Zhu, J.Y.: Multi-concept cus- tomization of text-to-image diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1931–1941 (2023)
1931
-
[21]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[22]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
2025
-
[23]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Li, Y., Zuo, Y., He, B., Zhang, J., Xiao, C., Qian, C., Yu, T., ang Gao, H., Yang, W., Liu, Z., Ding, N.: Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe (2026),https://arxiv.org/abs/2604. 13016
2026
-
[25]
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling (2023),https://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Liu, D., Gao, P., Liu, D., Du, R., Li, Z., Wu, Q., Jin, X., Cao, S., Zhang, S., Li, H., et al.: Decoupled dmd: Cfg augmentation as the spear, distribution matching as the shield. arXiv preprint arXiv:2511.22677 (2025)
-
[27]
In: AAAI
Liu, M., Ma, Y., Yang, Z., Dan, J., Yu, Y., Zhao, Z., Hu, Z., Liu, B., Fan, C.: Llm4gen: Leveraging semantic representation of llms for text-to-image generation. In: AAAI. pp. 5523–5531 (2025)
2025
-
[28]
In: CVPR
Liu, M., She, D., Pang, J., Huang, Q., Ying, J., He, W., Hou, Y., Fu, S.: Tfcus- tom: Customized image generation with time-aware frequency feature guidance. In: CVPR. pp. 2714–2723 (2025)
2025
-
[29]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency mod- els: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Mou, C., Wu, Y., Wu, W., Guo, Z., Zhang, P., Cheng, Y., Luo, Y., Ding, F., Zhang, S., Li, X., et al.: Dreamo: A unified framework for image customization. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–12 (2025)
2025
-
[31]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[32]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[34]
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth:Finetuningtext-to-imagediffusionmodelsforsubject-drivengeneration.In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 22500–22510 (2023) CollectionLoRA 19
2023
-
[35]
In: ICLR (2026)
She, D., Fu, S., Liu, M., Jin, Q., Wang, H., Liu, M., Jiang, J.: Mosaic: Multi-subject personalized generation via correspondence-aware alignment and disentanglement. In: ICLR (2026)
2026
-
[36]
In: European Conference on Computer Vision
Song, K., Zhu, Y., Liu, B., Yan, Q., Elgammal, A., Yang, X.: Moma: Multimodal llm adapter for fast personalized image generation. In: European Conference on Computer Vision. pp. 117–132. Springer (2024)
2024
-
[37]
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models (2023)
2023
- [38]
-
[39]
Team, C., Xiao, B., Xia, B., Yang, B., Gao, B., Shen, B., Zhang, C., He, C., Lou, C., Luo, F., Wang, G., Xie, G., Zhang, H., Lv, H., Li, H., Chen, H., Xu, H., Zhang, H., Liu, H., Duo, J., Wei, J., Xiao, J., Dong, J., Shi, J., Hu, J., Bao, K., Zhou, K., Li, L., Zhao, L., Zhang, L., Li, P., Chen, Q., Liu, S., Yu, S., Cao, S., Chen, S., Yu, S., Liu, S., Zhou...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Advances in neural information processing systems37, 83951–84009 (2024)
Wang, F.Y., Huang, Z., Bergman, A., Shen, D., Gao, P., Lingelbach, M., Sun, K., Bian, W., Song, G., Liu, Y., et al.: Phased consistency models. Advances in neural information processing systems37, 83951–84009 (2024)
2024
-
[41]
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Wang, Q., Bai, X., Wang, H., Qin, Z., Chen, A., Li, H., Tang, X., Hu, Y.: Instantid: Zero-shot identity-preserving generation in seconds. arXiv preprint arXiv:2401.07519 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wei, Y., Zhang, Y., Ji, Z., Bai, J., Zhang, L., Zuo, W.: Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 15943–15953 (2023)
2023
-
[44]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
Wu, K., Jiang, S., Ku, M., Nie, P., Liu, M., Chen, W.: Editreward: A human- aligned reward model for instruction-guided image editing (2026),https://arxiv. org/abs/2509.26346
-
[47]
arXiv preprint arXiv:2310.08580 (2023)
Xie, Y., Jampani, V., Zhong, L., Sun, D., Jiang, H.: Omnicontrol: Control any joint at any time for human motion generation. arXiv preprint arXiv:2310.08580 (2023)
-
[48]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, 20 F. Wu et al. J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Yang, W., Liu, W., Xie, R., Yang, K., Yang, S., Lin, Y.: Learning beyond teacher: Generalized on-policy distillation with reward extrapolation (2026),https:// arxiv.org/abs/2602.12125
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Advances in neural information processing systems37, 47455–47487 (2024)
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024)
2024
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6613– 6623 (2024)
2024
-
[53]
Advances in Neural Information Processing Systems37, 111000–111021 (2024)
Zhai, Y., Lin, K., Yang, Z., Li, L., Wang, J., Lin, C.C., Doermann, D., Yuan, J., Wang, L.: Motion consistency model: Accelerating video diffusion with disentan- gled motion-appearance distillation. Advances in Neural Information Processing Systems37, 111000–111021 (2024)
2024
-
[54]
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M., Shum, H.Y.: Dino: Detr with improved denoising anchor boxes for end-to-end object detection (2022), https://arxiv.org/abs/2203.03605
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[55]
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models (2023),https://arxiv.org/abs/2302.05543
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Template Source Image
Zhang, Y., Yuan, Y., Song, Y., Wang, H., Liu, J.: Easycontrol: Adding efficient and flexible control for diffusion transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19513–19524 (2025) CollectionLoRA 21 Overview of Supplementary Material Thissupplementarydocumentprovidescomprehensivetechnicaldetails,in-depth theo...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.