Binding Visual Features Point by Point
Pith reviewed 2026-06-29 22:54 UTC · model grok-4.3
The pith
Training vision language models to point to objects via text induces an internal serial visual search routine that binds features and generalizes to new tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Learning to point-via-text induces an internal visual search routine in vision language models, and pointing behavior generalizes to new tasks via fine-tuning. This eliminates binding errors and enables compositional generalization, providing evidence that serial processing solves the binding problem for these models in the same way it does for biological vision.
What carries the argument
The induced internal visual search routine, created by training to output pointing coordinates via text, which processes objects sequentially to bind their features without interference.
If this is right
- Pointing training enables accurate feature binding in multi-object scenes by creating a serial processing step.
- Fine-tuning the pointing behavior transfers to new tasks while removing binding errors.
- Compositional generalization improves once the model adopts the serial routine.
- Serial processing serves as a direct analog to human visual attention for solving binding in artificial models.
Where Pith is reading between the lines
- The same pointing-induced routine might be tested in other multimodal architectures to see if it produces similar binding improvements without task-specific fine-tuning.
- This approach could be extended to test whether models can learn to point to abstract or relational features rather than just spatial locations.
- If the routine generalizes broadly, it might reduce the need for separate object detection modules in vision-language pipelines.
Load-bearing premise
That the gains in performance and generalization come specifically from the induced serial search routine rather than from other side-effects of the pointing training or fine-tuning.
What would settle it
A demonstration that models achieve equivalent binding accuracy and generalization after pointing training but without any evidence of sequential object processing would falsify the central claim.
Figures



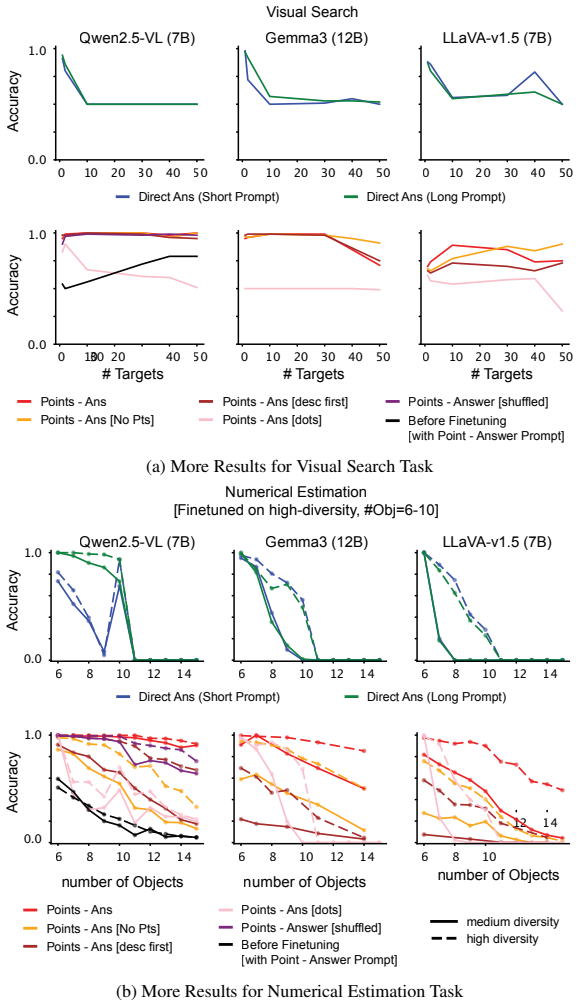
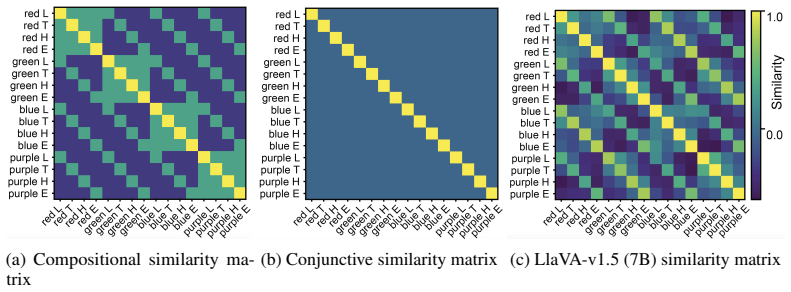
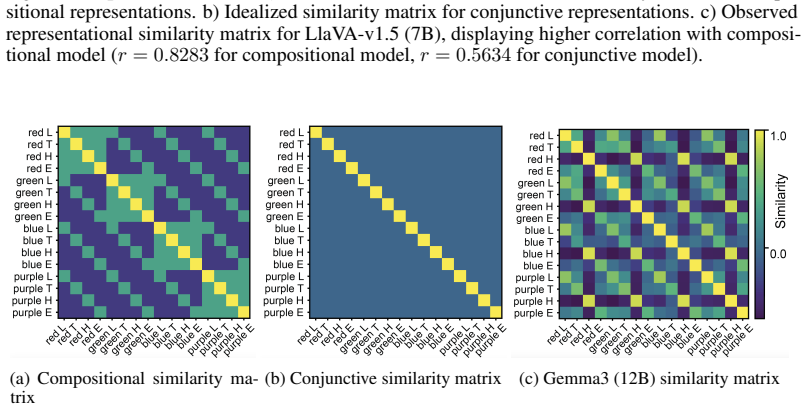
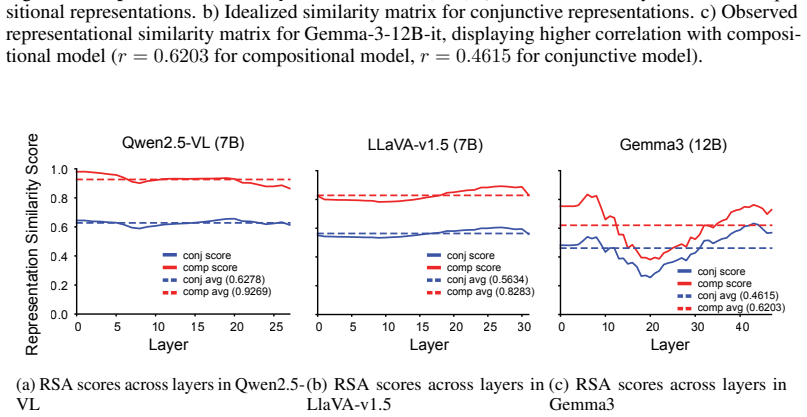
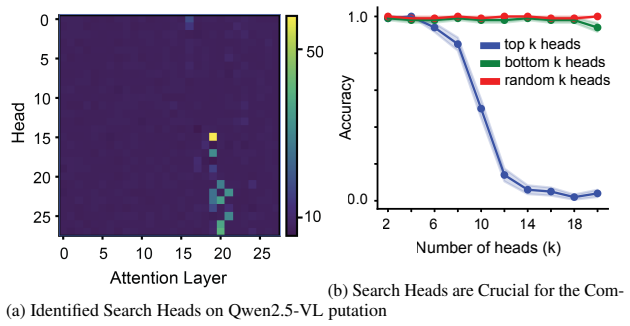
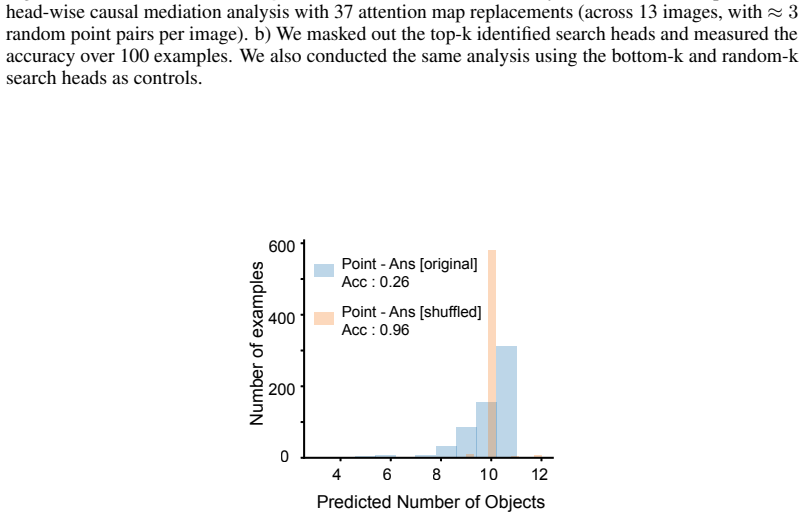
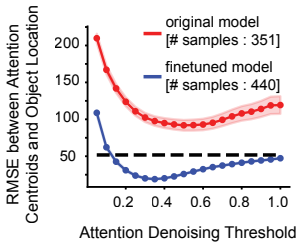
read the original abstract
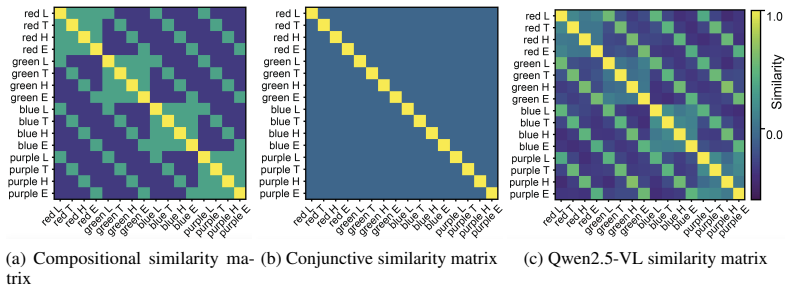
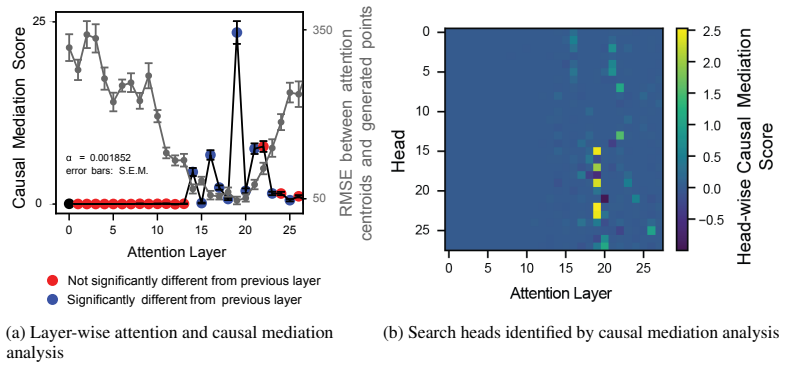
Despite success on standard benchmarks, vision language models display persistent failures on tasks involving processing of multi-object scenes, including many tasks that are relatively easy for humans. Recent work has found that these failures may stem from a basic inability to accurately bind object features in-context, a challenge that is referred to as the "binding problem" in cognitive science and neuroscience. The human visual system is thought to solve this binding problem via serial processing, attending to individual objects one at a time so as to avoid interference from other objects. Recent work has proposed "pointing" -- the use of explicit spatial coordinates to refer to objects -- as an analogous solution for vision language models, and found that it improves performance on challenging multi-object tasks. However, it is unclear $\textit{why}$ (i.e., on a mechanistic or representational level) this approach improves performance, and how directly this relates to serial processing in human vision. Here, we investigate this question. We find that learning to point-via-text induces an internal visual search routine, and we characterize the mechanisms that support this procedure. We also find that pointing behavior can be generalized to new tasks via fine-tuning, and that doing so eliminates binding errors and enables compositional generalization. These results provide a proof-of-principle that serial processing can solve the binding problem for vision language models just as it does for biological vision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training vision-language models to point to objects via text induces an internal visual search routine analogous to human serial attention. This routine is said to solve the binding problem in multi-object scenes; the pointing behavior generalizes via fine-tuning to new tasks, eliminating binding errors and enabling compositional generalization, providing a proof-of-principle that serial processing can address binding failures in VLMs as it does in biological vision.
Significance. If the mechanistic claims hold after proper isolation of the search routine, the work would be significant for linking cognitive-science concepts of serial processing to practical VLM improvements on multi-object tasks, offering a route to compositional generalization without relying solely on scale.
major comments (2)
- [Abstract] Abstract: the central claim that learning to point-via-text induces a serial visual search routine whose mechanisms then eliminate binding errors requires evidence that gains arise specifically from the induced routine rather than side-effects of the training objective or fine-tuning (e.g., altered attention statistics or task-specific adaptation). No such isolating ablation or control is described.
- [Abstract] Abstract: the assertion that pointing behavior generalizes via fine-tuning to eliminate binding errors and enable compositional generalization is load-bearing for the proof-of-principle conclusion, yet the abstract provides no quantitative results, controls, or comparisons that would allow assessment of whether alternative explanations were ruled out.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that the abstract should more explicitly reference the isolating experiments and quantitative results from the full manuscript to support the claims about the serial search routine and its generalization effects. We will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that learning to point-via-text induces a serial visual search routine whose mechanisms then eliminate binding errors requires evidence that gains arise specifically from the induced routine rather than side-effects of the training objective or fine-tuning (e.g., altered attention statistics or task-specific adaptation). No such isolating ablation or control is described.
Authors: The full manuscript includes targeted ablations and controls that isolate the effects of the pointing-induced serial search routine. These compare the pointing model against fine-tuned baselines without the pointing objective, as well as analyses showing that serial attention patterns and binding improvements emerge specifically from the pointing training rather than general task adaptation or altered attention statistics. We will revise the abstract to briefly reference these isolating controls. revision: yes
-
Referee: [Abstract] Abstract: the assertion that pointing behavior generalizes via fine-tuning to eliminate binding errors and enable compositional generalization is load-bearing for the proof-of-principle conclusion, yet the abstract provides no quantitative results, controls, or comparisons that would allow assessment of whether alternative explanations were ruled out.
Authors: The manuscript provides quantitative results on binding error reduction and compositional generalization after fine-tuning, including direct comparisons to non-pointing fine-tuned controls that help rule out alternative explanations such as generic adaptation. We will update the abstract to include key quantitative highlights and note the relevant controls for better assessment of the claims. revision: yes
Circularity Check
No circularity: empirical claims with no derivation chain or self-referential fitting
full rationale
The paper presents experimental results on vision-language models, claiming that pointing-via-text training induces an internal search routine and enables generalization. No equations, first-principles derivations, or fitted parameters are described in the provided abstract or context. The central claims are empirical observations from training and fine-tuning procedures, not reductions of outputs to inputs by construction. No self-citation load-bearing steps or ansatz smuggling are present. The derivation chain is absent, so no circularity can be identified.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Object- centric binding in contrastive language-image pretraining, 2025a
Rim Assouel, Pietro Astolfi, Florian Bordes, Michal Drozdzal, and Adriana Romero-Soriano. Object- centric binding in contrastive language-image pretraining, 2025a. URL https://arxiv.org/ abs/2502.14113. Rim Assouel, Declan Campbell, Yoshua Bengio, and Taylor Webb. Visual symbolic mechanisms: Emergent symbol processing in vision language models, 2025b. URL...
-
[2]
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang. Ground-r1: Incen- tivizing grounded visual reasoning via reinforcement learning.arXiv preprint arXiv:2505.20272,
-
[3]
arXiv preprint arXiv:2109.10852 , year=
Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection.arXiv preprint arXiv:2109.10852,
-
[4]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Moham- madreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models.arXiv preprint arXiv:2409.17146,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Shuhao Fu, Andrew Jun Lee, Anna Wang, Ida Momennejad, Trevor Bihl, Hongjing Lu, and Taylor W Webb. Evaluating compositional scene understanding in multimodal generative models.arXiv preprint arXiv:2503.23125,
-
[6]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2508.05776 , title =
Thomas L Griffiths, Brenden M Lake, R Thomas McCoy, Ellie Pavlick, and Taylor W Webb. Whither symbols in the era of advanced neural networks?arXiv preprint arXiv:2508.05776,
-
[8]
Daniel Kahneman.Thinking, Fast and Slow
URL https: //arxiv.org/abs/2506.22146. Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, New York,
-
[9]
Marco Nurisso, Jesseba Fernando, Raj Deshpande, Alan Perotti, Raja Marjieh, Steven M Frankland, Richard L Lewis, Taylor W Webb, Declan Campbell, Francesco Vaccarino, et al. Bound by semanticity: universal laws governing the generalization-identification tradeoff.arXiv preprint arXiv:2506.14797,
-
[10]
OpenAI et al. Gpt-4 technical report, 2024a. URLhttps://arxiv.org/abs/2303.08774. OpenAI et al. Openai o1 system card, 2024b. Judea Pearl. Direct and indirect effects. InProbabilistic and causal inference: the works of Judea Pearl, pages 373–392
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URLhttps://arxiv.org/abs/2407.06581. Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with clip latents,
-
[12]
URL https://arxiv.org/abs/2204. 06125. 11 Sunayana Rane, Alexander Ku, Jason Michael Baldridge, Ian Tenney, Thomas L. Griffiths, and Been Kim. Can generative multimodal models count to ten? InICLR 2024 Workshop on Representational Alignment,
2024
-
[13]
Grounded Reinforcement Learning for Visual Reasoning
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J Tarr, Aviral Kumar, and Katerina Fragkiadaki. Grounded reinforcement learning for visual reasoning.arXiv preprint arXiv:2505.23678,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
doi: 10.48550/arXiv.2408.03314. Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Can- dace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03314
-
[16]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Inter- pretability in the wild: a circuit for indirect object identification in gpt-2 small.arXiv preprint arXiv:2211.00593,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Taylor Webb, Shanka Subhra Mondal, and Ida Momennejad. Improving planning with large language models: A modular agentic architecture.arXiv preprint arXiv:2310.00194,
-
[18]
Yukang Yang, Declan Campbell, Kaixuan Huang, Mengdi Wang, Jonathan Cohen, and Taylor Webb. Emergent symbolic mechanisms support abstract reasoning in large language models.arXiv preprint arXiv:2502.20332,
-
[19]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.arXiv preprint arXiv:2305.10601,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
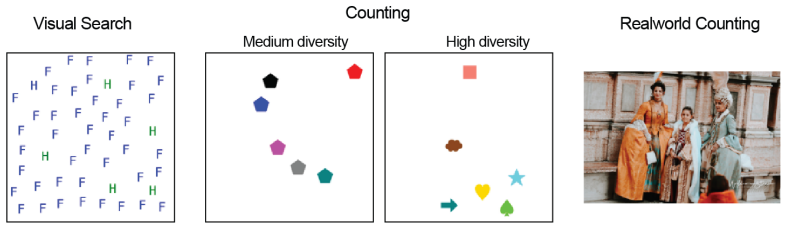
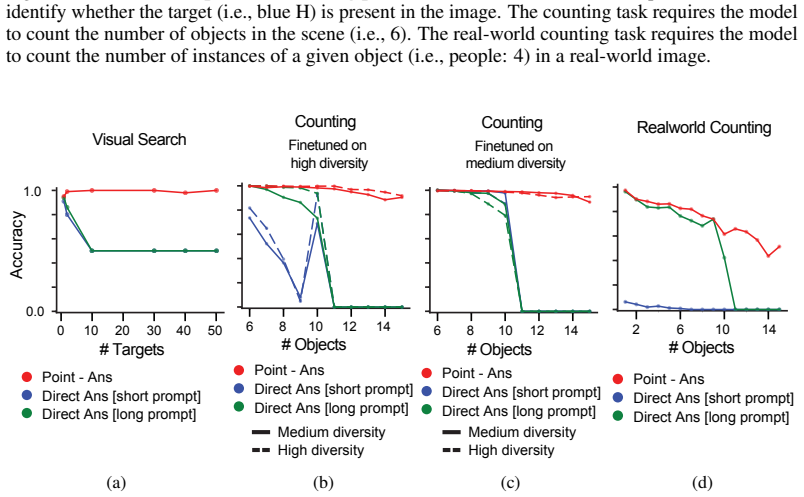
We supervised fine-tuned Qwen2.5-VL on 2000 scenes (e.g., Figure 5: Visual Search) using the corresponding prompt–answer pairs shown in Boxes 2 and
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.