Test-Time Self-Adaptive Conditioning for Stable Audio-Driven Talking-Head Generation
Pith reviewed 2026-06-29 22:34 UTC · model grok-4.3
The pith
A single test-time adaptation step using the generator's own outputs refines the conditioning reference and stabilizes identity and motion in audio-driven talking-head videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
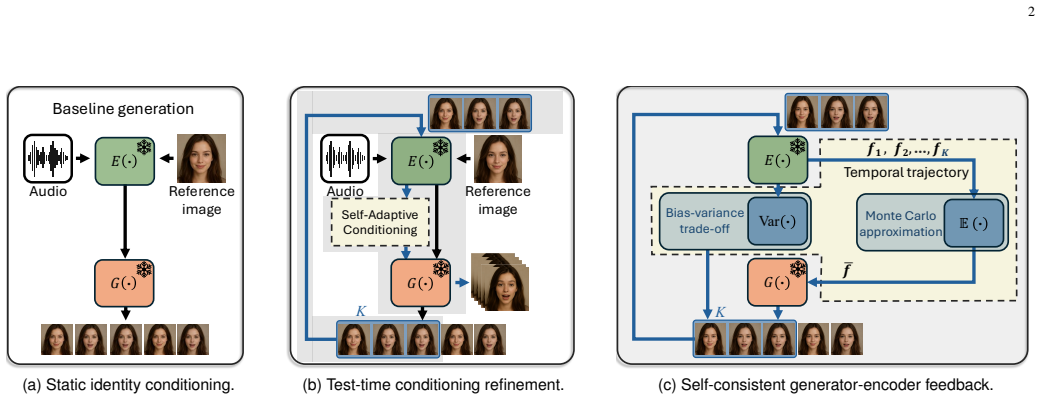
By feeding the generator's outputs back through its encoder, a single adaptation step constructs a refined conditioning representation that approximates the fixed point of the generator-encoder composition. This fixed point aligns more closely with the temporal dynamics of the synthesized sequence, reducing variance in identity and motion features while improving generative stability under mild Lipschitz assumptions on the composition.
What carries the argument
The feedback loop that composes the pretrained generator with its encoder to derive a sequence-aligned conditioning signal from the generator's own outputs in one step.
If this is right
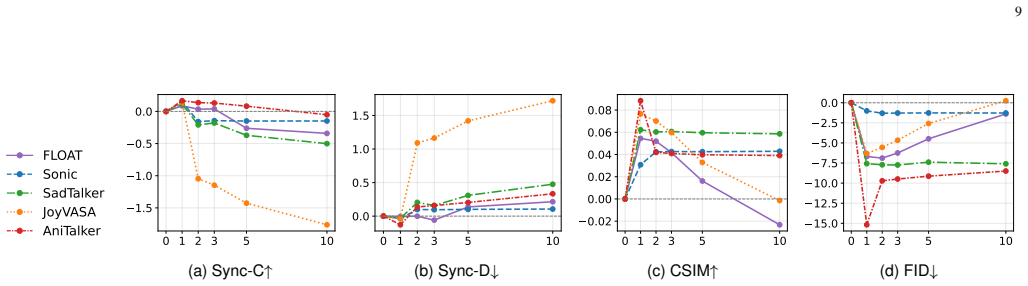
- Identity preservation and temporal coherence improve on existing benchmark datasets for multiple pretrained generators.
- Lip-sync accuracy and perceptual fidelity increase without retraining, gradient updates, or additional data.
- The method applies model-agnostically to any pretrained talking-head generator.
- A principled bias-variance tradeoff controls the strength of the adaptation.
Where Pith is reading between the lines
- The same feedback construction could be tested on other conditional video tasks where a static reference mismatches evolving outputs.
- Extending the one-step update to a few iterations might further reduce residual drift if inference budget permits.
- Evaluating the approach on sequences much longer than current benchmarks would test whether the approximated equilibrium persists over extended time.
Load-bearing premise
The generator-encoder composition forms a feedback loop whose fixed point can be reached in one step and that this fixed point improves alignment with the true temporal dynamics of the target sequence.
What would settle it
If applying the single adaptation step increases measured identity drift or temporal inconsistency on standard benchmark videos relative to the static-reference baseline, the stability claim is falsified.
Figures



read the original abstract
Audio-driven talking-head generation has achieved remarkable progress with recent models such as AniTalker, FLOAT, and Sonic. Despite their success, most existing approaches rely on a single static reference image to condition the entire video generation process at inference stage. This static conditioning paradigm often creates a mismatch between fixed identity features and dynamically evolving facial motion, leading to identity drift, temporal inconsistency, and degraded perceptual quality. We introduce Test-Time Self-Adaptive Conditioning (TT-SAC), a parameter-free inference framework that enables pretrained talking-head generators to adapt their conditioning representations during inference without retraining, gradient updates, or additional supervision. Instead of treating the reference portrait as immutable, TT-SAC composes the generator with its encoder in a feedback loop: the generator's own outputs are re-encoded to construct a refined conditioning representation that better aligns with the temporal dynamics of the synthesized sequence. A single adaptation step approximates a self-consistent equilibrium of the generative process, stabilizing identity and motion across time. We further provide theoretical analysis showing that test-time conditioning adaptation reduces feature variance and improves generative stability under mild Lipschitz assumptions, while exhibiting a principled bias-variance tradeoff that governs the optimal strength of adaptation. Extensive experiments on state-of-the-art talking-head generators and benchmark datasets demonstrate consistent improvements in lip-sync accuracy, temporal coherence, identity preservation, and perceptual fidelity. TT-SAC offers a model-agnostic and training-free strategy for enhancing generative video models, establishing test-time conditioning adaptation as an effective mechanism for stabilizing audio-driven portrait animation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Test-Time Self-Adaptive Conditioning (TT-SAC), a parameter-free, training-free inference framework for audio-driven talking-head generation. It composes a pretrained generator with its encoder in a feedback loop so that the generator's outputs are re-encoded to produce a refined conditioning representation; a single adaptation step is claimed to approximate a self-consistent equilibrium that stabilizes identity and motion. The manuscript supplies a theoretical argument that this reduces feature variance under mild Lipschitz assumptions while exhibiting a bias-variance tradeoff, and reports empirical gains in lip-sync accuracy, temporal coherence, identity preservation, and perceptual quality across state-of-the-art generators and benchmark datasets.
Significance. If the one-step fixed-point claim can be supported by an explicit contraction analysis and the empirical results prove reproducible with proper controls, TT-SAC would constitute a general, model-agnostic technique for improving temporal stability in conditional video generators without retraining or additional data.
major comments (3)
- [Abstract] Abstract (theoretical analysis paragraph): the claim that 'a single adaptation step approximates a self-consistent equilibrium' under 'mild Lipschitz assumptions' is not accompanied by any contraction-mapping bound, residual analysis, or condition on the Lipschitz constant L that would guarantee sufficient accuracy after one iteration; without such a bound the observed stabilization may reduce to simple feature averaging rather than equilibrium properties.
- [Abstract] Abstract: the method is repeatedly described as 'parameter-free,' yet the same paragraph states that adaptation strength is governed by a 'principled bias-variance tradeoff' that determines its 'optimal strength'; this internal tension must be resolved by showing either that the strength is derived without any free parameter or that it is fixed by a universal rule independent of the test sequence.
- [Abstract] Abstract (experiments paragraph): no error bars, statistical tests, dataset cardinalities, or verification that adaptation strength was not selected post-hoc on the evaluation sets are supplied, so the reported 'consistent improvements' cannot be assessed for reliability or generality.
minor comments (1)
- [Abstract] Abstract: the models AniTalker, FLOAT, and Sonic are named but the manuscript should confirm that full bibliographic references appear in the reference list.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, offering clarifications and committing to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (theoretical analysis paragraph): the claim that 'a single adaptation step approximates a self-consistent equilibrium' under 'mild Lipschitz assumptions' is not accompanied by any contraction-mapping bound, residual analysis, or condition on the Lipschitz constant L that would guarantee sufficient accuracy after one iteration; without such a bound the observed stabilization may reduce to simple feature averaging rather than equilibrium properties.
Authors: We agree that an explicit contraction-mapping bound and residual analysis would strengthen the one-step approximation claim. Our current theoretical argument establishes variance reduction under Lipschitz continuity but does not supply a quantitative bound on the residual after a single iteration. In the revised manuscript we will add this analysis, deriving a bound on the approximation error conditioned on L. revision: yes
-
Referee: [Abstract] Abstract: the method is repeatedly described as 'parameter-free,' yet the same paragraph states that adaptation strength is governed by a 'principled bias-variance tradeoff' that determines its 'optimal strength'; this internal tension must be resolved by showing either that the strength is derived without any free parameter or that it is fixed by a universal rule independent of the test sequence.
Authors: The designation 'parameter-free' denotes the absence of any learned parameters, retraining, or test-time optimization. The bias-variance tradeoff is used only to derive a single fixed strength value that is applied uniformly to every test sequence; this value is independent of individual data and chosen once from the theoretical analysis. We will revise the abstract to state this explicitly and remove any implication of per-sequence optimization. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): no error bars, statistical tests, dataset cardinalities, or verification that adaptation strength was not selected post-hoc on the evaluation sets are supplied, so the reported 'consistent improvements' cannot be assessed for reliability or generality.
Authors: We concur that these reporting elements are necessary. The revised version will add error bars from multiple random seeds, paired statistical tests, explicit dataset cardinalities, and a statement confirming that the adaptation strength was fixed a priori from the theoretical analysis and never tuned on the evaluation sets. revision: yes
Circularity Check
No circularity; adaptation and equilibrium approximation defined independently of claimed stability gains
full rationale
The paper explicitly defines TT-SAC as a parameter-free composition of generator and encoder into a one-step feedback loop that approximates equilibrium, then separately claims (under mild Lipschitz assumptions) that this reduces feature variance and exhibits a bias-variance tradeoff. No equations, self-citations, or fitted parameters are shown that would make the reported stabilization or alignment with temporal dynamics equivalent to the input definitions by construction. The derivation chain is self-contained; the one-step approximation is presented as an empirical mechanism rather than a tautological renaming or load-bearing self-reference.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptation strength
axioms (1)
- domain assumption mild Lipschitz assumptions on the generator-encoder composition
Reference graph
Works this paper leans on
-
[1]
First order motion model for image animation,
A. Siarohin, S. Lathuili `ere, S. Tulyakov, E. Ricci, and N. Sebe, “First order motion model for image animation,” inAdvances in Neural Information Processing Systems, 2019, pp. 7135–7145
2019
-
[2]
Hierarchical cross-modal talking face generation with dynamic pixel-wise loss,
L. Chen, R. K. Maddox, Z. Duan, and C. Xu, “Hierarchical cross-modal talking face generation with dynamic pixel-wise loss,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7832–7841
2019
-
[3]
A lip sync expert is all you need for speech to lip generation in the wild,
K. Prajwal, R. Mukhopadhyay, V . P. Namboodiri, and C. Jawahar, “A lip sync expert is all you need for speech to lip generation in the wild,” in Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 484–492
2020
-
[4]
Hallo: Hierarchical audio-driven visual synthesis for portrait image animation,
M. Xu, H. Li, Q. Su, H. Shang, L. Zhang, C. Liu, J. Wang, Y . Yao, and S. Zhu, “Hallo: Hierarchical audio-driven visual synthesis for portrait image animation,”arXiv preprint arXiv:2406.08801, 2024
-
[5]
Hallo2: Long-duration and high-resolution audio-driven portrait image animation,
J. Cui, H. Li, Y . Yao, H. Zhu, H. Shang, K. Cheng, H. Zhou, S. Zhu, and J. Wang, “Hallo2: Long-duration and high-resolution audio-driven portrait image animation,”arXiv preprint arXiv:2410.07718, 2024
-
[6]
Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer,
J. Cui, H. Li, Y . Zhan, H. Shang, K. Cheng, Y . Ma, S. Mu, H. Zhou, J. Wang, and S. Zhu, “Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 21 086–21 095
2025
-
[7]
J. Cui, Y . Chen, M. Xu, H. Shang, Y . Chen, Y . Zhan, Z. Dong, Y . Yao, J. Wang, and S. Zhu, “Hallo4: High-fidelity dynamic portrait animation via direct preference optimization and temporal motion modulation,” arXiv preprint arXiv:2505.23525, 2025
-
[8]
H. Cheng, L. Lin, C. Liu, P. Xia, P. Hu, J. Ma, J. Du, and J. Pan, “Dawn: Dynamic frame avatar with non-autoregressive diffusion framework for talking head video generation,”arXiv preprint arXiv:2410.13726, 2024
-
[9]
Aniportrait: Audio-driven synthesis of photorealistic portrait animation,
H. Wei, Z. Yang, and Z. Wang, “Aniportrait: Audio-driven synthesis of photorealistic portrait animation,”arXiv preprint arXiv:2403.17694, 2024
-
[10]
Liveportrait: Efficient portrait animation with stitching and retargeting control,
J. Guo, D. Zhang, X. Liu, Z. Zhong, Y . Zhang, P. Wan, and D. Zhang, “Liveportrait: Efficient portrait animation with stitching and retargeting control,”arXiv preprint arXiv:2407.03168, 2024
-
[11]
Vasa-1: Lifelike audio-driven talking faces generated in real time,
S. Xu, G. Chen, Y .-X. Guo, J. Yang, C. Li, Z. Zang, Y . Zhang, X. Tong, and B. Guo, “Vasa-1: Lifelike audio-driven talking faces generated in real time,” inAdvances in Neural Information Processing Systems, 2024, pp. 660–684
2024
-
[12]
Talking-head generation in practice,
Z. Zhang, L. Wang, Y . Gao, and Y . Zhang, “Talking-head generation in practice,” inThe Second International Workshop on Transformative Insights in Multifaceted Evaluation at The Web Conference 2026, 2026. [Online]. Available: https://openreview.net/forum?id=ns3TgZYQTZ
2026
-
[13]
Sadtalker: Learning realistic 3d motion coefficients for styl- ized audio-driven single image talking face animation,
W. Zhang, X. Cun, X. Wang, Y . Zhang, X. Shen, Y . Guo, Y . Shan, and F. Wang, “Sadtalker: Learning realistic 3d motion coefficients for styl- ized audio-driven single image talking face animation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 8652–8661
2023
-
[14]
Anitalker: animate vivid and diverse talking faces through identity- decoupled facial motion encoding,
T. Liu, F. Chen, S. Fan, C. Du, Q. Chen, X. Chen, and K. Yu, “Anitalker: animate vivid and diverse talking faces through identity- decoupled facial motion encoding,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 6696–6705
2024
-
[15]
Float: Generative motion latent flow match- ing for audio-driven talking portrait,
T. Ki, D. Min, and G. Chae, “Float: Generative motion latent flow match- ing for audio-driven talking portrait,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 14 699–14 710
2025
-
[16]
Sonic: Shifting focus to global audio perception in portrait animation,
X. Ji, X. Hu, Z. Xu, J. Zhu, C. Lin, Q. He, J. Zhang, D. Luo, Y . Chen, Q. Linet al., “Sonic: Shifting focus to global audio perception in portrait animation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 193–203
2025
-
[17]
ObamaNet: Photo-realistic lip-sync from text
R. Kumar, J. Sotelo, K. Kumar, A. De Brebisson, and Y . Ben- gio, “Obamanet: Photo-realistic lip-sync from text,”arXiv preprint arXiv:1801.01442, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Deep video portraits,
H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Niessner, P. P ´erez, C. Richardt, M. Zollh¨ofer, and C. Theobalt, “Deep video portraits,”ACM transactions on graphics (TOG), vol. 37, no. 4, pp. 1–14, 2018
2018
-
[19]
Syn- thesizing obama: learning lip sync from audio,
S. Suwajanakorn, S. M. Seitz, and I. Kemelmacher-Shlizerman, “Syn- thesizing obama: learning lip sync from audio,”ACM Transactions on Graphics (ToG), vol. 36, no. 4, pp. 1–13, 2017
2017
-
[20]
Audio-driven facial animation by joint end-to-end learning of pose and emotion,
T. Karras, T. Aila, S. Laine, A. Herva, and J. Lehtinen, “Audio-driven facial animation by joint end-to-end learning of pose and emotion,”ACM Transactions on Graphics (ToG), vol. 36, no. 4, pp. 1–12, 2017
2017
-
[21]
Out of time: automated lip sync in the wild,
J. S. Chung and A. Zisserman, “Out of time: automated lip sync in the wild,” inAsian Conference on Computer Vision, 2016, pp. 251–263
2016
-
[22]
Speech-Driven Facial Reenactment Using Conditional Generative Adversarial Networks
S. A. Jalalifar, H. Hasani, and H. Aghajan, “Speech-driven facial reenactment using conditional generative adversarial networks,”arXiv preprint arXiv:1803.07461, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Audio-driven talking face video generation with learning-based personalized head pose,
R. Yi, Z. Ye, J. Zhang, H. Bao, and Y .-J. Liu, “Audio-driven talking face video generation with learning-based personalized head pose,”arXiv preprint arXiv:2002.10137, 2020
-
[24]
Face2face: Real-time face capture and reenactment of rgb videos,
J. Thies, M. Zollhofer, M. Stamminger, C. Theobalt, and M. Nießner, “Face2face: Real-time face capture and reenactment of rgb videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 2387–2395
2016
-
[25]
One-shot free-view neural talking-head synthesis for video conferencing,
T.-C. Wang, A. Mallya, and M.-Y . Liu, “One-shot free-view neural talking-head synthesis for video conferencing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 039–10 049
2021
-
[26]
Dreamtalk: When emotional talking head generation meets diffusion probabilistic models,
Y . Ma, S. Zhang, J. Wang, X. Wang, Y . Zhang, and Z. Deng, “Dreamtalk: When emotional talking head generation meets diffusion probabilistic models,”arXiv preprint arXiv:2312.09767, 2023. 12
-
[27]
Fantasytalking: Realistic talking portrait generation via coher- ent motion synthesis,
M. Wang, Q. Wang, F. Jiang, Y . Fan, Y . Zhang, Y . Qi, K. Zhao, and M. Xu, “Fantasytalking: Realistic talking portrait generation via coher- ent motion synthesis,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9891–9900
2025
-
[28]
Let them talk: Audio-driven multi-person conversational video generation,
Z. Kong, F. Gao, Y . Zhang, Z. Kang, X. Wei, X. Cai, G. Chen, and W. Luo, “Let them talk: Audio-driven multi-person conversational video generation,”arXiv preprint arXiv:2505.22647, 2025
-
[29]
Playmate: Flexible control of portrait animation via 3d-implicit space guided diffusion,
X. Ma, J. Cai, Y . Guan, S. Huang, Q. Zhang, and S. Zhang, “Playmate: Flexible control of portrait animation via 3d-implicit space guided diffusion,”arXiv preprint arXiv:2502.07203, 2025
-
[30]
Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions,
Z. Chen, J. Cao, Z. Chen, Y . Li, and C. Ma, “Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 2403–2410
2025
-
[31]
Megaportraits: One-shot megapixel neural head avatars,
N. Drobyshev, J. Chelishev, T. Khakhulin, A. Ivakhnenko, V . Lempitsky, and E. Zakharov, “Megaportraits: One-shot megapixel neural head avatars,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 2663–2671
2022
-
[32]
Disentangle identity, cooperate emotion: Correlation-aware emotional talking portrait generation,
W. Tan, C. Lin, C. Xu, F. Xu, X. Hu, X. Ji, J. Zhu, C. Wang, and Y . Fu, “Disentangle identity, cooperate emotion: Correlation-aware emotional talking portrait generation,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9987–9995
2025
-
[33]
Learnable expansion of graph operators for multi-modal feature fusion,
D. Ding, L. Wang, L. Zhu, T. Gedeon, and P. Koniusz, “Learnable expansion of graph operators for multi-modal feature fusion,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=SMZqIOSdlN
2025
-
[34]
Multimodal fusion for talking face generation utilizing speech-related facial action units,
Z. Liu, X. Liu, S. Chen, J. Liu, L. Wang, and C. Bi, “Multimodal fusion for talking face generation utilizing speech-related facial action units,”ACM Transactions on Multimedia Computing, Communications and Applications, vol. 20, no. 9, pp. 1–24, 2024
2024
-
[35]
Stylesync: High-fidelity generalized and personalized lip sync in style-based generator,
J. Guan, Z. Zhang, H. Zhou, T. Hu, K. Wang, D. He, H. Feng, J. Liu, E. Ding, Z. Liuet al., “Stylesync: High-fidelity generalized and personalized lip sync in style-based generator,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1505–1515
2023
-
[36]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, 2020, pp. 6840– 6851
2020
-
[37]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[38]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,” inAdvances in Neural Information Processing Systems, 2022, pp. 5775–5787
2022
-
[40]
The monte carlo method,
N. Metropolis and S. Ulam, “The monte carlo method,”Journal of the American statistical association, vol. 44, no. 247, pp. 335–341, 1949
1949
-
[41]
Sur les op ´erations dans les ensembles abstraits et leur application aux ´equations int´egrales,
S. Banach, “Sur les op ´erations dans les ensembles abstraits et leur application aux ´equations int´egrales,”Fundamenta mathematicae, vol. 3, no. 1, pp. 133–181, 1922
1922
-
[42]
The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,
S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,”PloS one, vol. 13, no. 5, p. e0196391, 2018
2018
-
[43]
Celebv-hq: A large-scale video facial attributes dataset,
H. Zhu, W. Wu, W. Zhu, L. Jiang, S. Tang, L. Zhang, Z. Liu, and C. C. Loy, “Celebv-hq: A large-scale video facial attributes dataset,” in European Conference on Computer Vision, 2022, pp. 650–667
2022
-
[44]
X. Cao, G. Wang, S. Shi, J. Zhao, Y . Yao, J. Fei, and M. Gao, “Joy- vasa: portrait and animal image animation with diffusion-based audio- driven facial dynamics and head motion generation,”arXiv preprint arXiv:2411.09209, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Rethinking fid: Towards a better evaluation metric for image generation,
S. Jayasumana, S. Ramalingam, A. Veit, D. Glasner, A. Chakrabarti, and S. Kumar, “Rethinking fid: Towards a better evaluation metric for image generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9307–9315
2024
-
[46]
Towards Accurate Generative Models of Video: A New Metric & Challenges
T. Unterthiner, S. Van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly, “Towards accurate generative models of video: A new metric & challenges,”arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4690–4699
2019
-
[48]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 586–595
2018
-
[49]
Omniavatar: Efficient audio-driven avatar video generation with adaptive body animation,
Q. Gan, R. Yang, J. Zhu, S. Xue, and S. Hoi, “Omniavatar: Efficient audio-driven avatar video generation with adaptive body animation,” arXiv preprint arXiv:2506.18866, 2025. Zhicheng Zhangis a Ph.D. student at the University of New South Wales (UNSW), Australia, supervised by Dr. Yu Zhang (2024-present). He received his M.S. from The University of Queens...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.